Overview
Does an idiom's distribution over contexts concentrate more than either component word can explain alone — the operational signature of synergy? This report sweeps 5 base LMs × two scoring reductions × two context-modes (20 configs), over the idiom dataset and a parallel literal-VP (non-idiom) dataset.
| axis | values |
|---|---|
| models | gemma-2-9b, Qwen3-8B-Base, Qwen3-8B, Llama-3.1-8B (bf16) + gpt2 baseline (fp32) |
| reduction | geo (length-normalized per-token prob) · joint (full sentence prob) |
| context-mode | medial (canonical) · full (incl. final-position) |
| datasets | idiom (18 phrases) vs non-idiom (18 phrases) |
+inf whenever a phrase has a compositional context (reference only).
Start with How to read the magnitudes.How to read these magnitudes
Every quantity is an average over an idiom's contexts. For one context \(c\):
\(p(c)\) = LM score of the idiom there; \(q,r\) = scores of the verb-/noun-literal pools, and
\(m=\max(q,r)\) is the better single word. Synergy (the whole point) = the idiom is
more concentrated than either word alone, i.e. \(p>m\). Full version:
INTERPRETATION.md.
Step by step
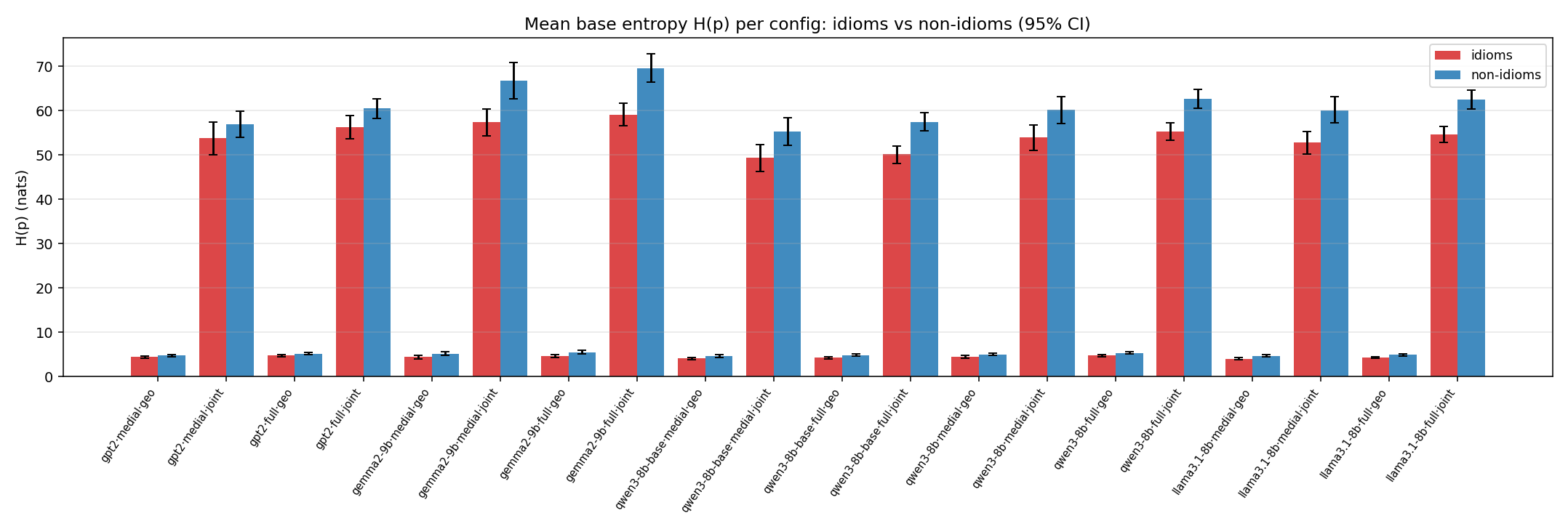
- \(H(p)\) — base entropy, \(\operatorname{mean}(-\log p)\). ↓ smaller = idiom more concentrated. Idioms are lower than literal VPs everywhere.
- \(H_u\) — \(\operatorname{mean}(-\log\min\{p,m\}) = \operatorname{mean}\max(-\log p,-\log m)\), the "covered" part. Always \(\ge H(p)\); read it through the ratio.
- \(H_u/H(p)\) — THE headline. ↑ bigger = MORE synergy. \(=1\) means no more concentrated than the best word; \(>1\) means synergy. Idioms \(>\) non-idioms in every config.
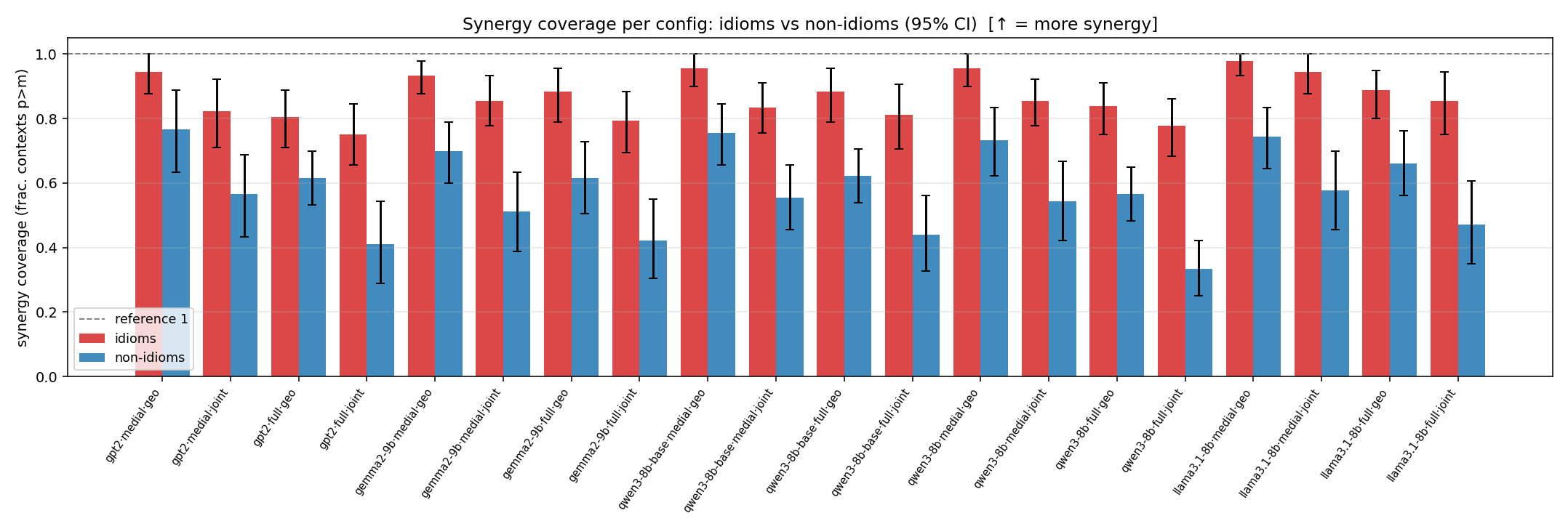
- syn_frac — fraction of contexts with \(p>m\), in \([0,1]\). ↑ bigger = MORE synergy. The plain-English "how idiomatic", and exactly "how many contexts escaped the \(-\log 0\) below".
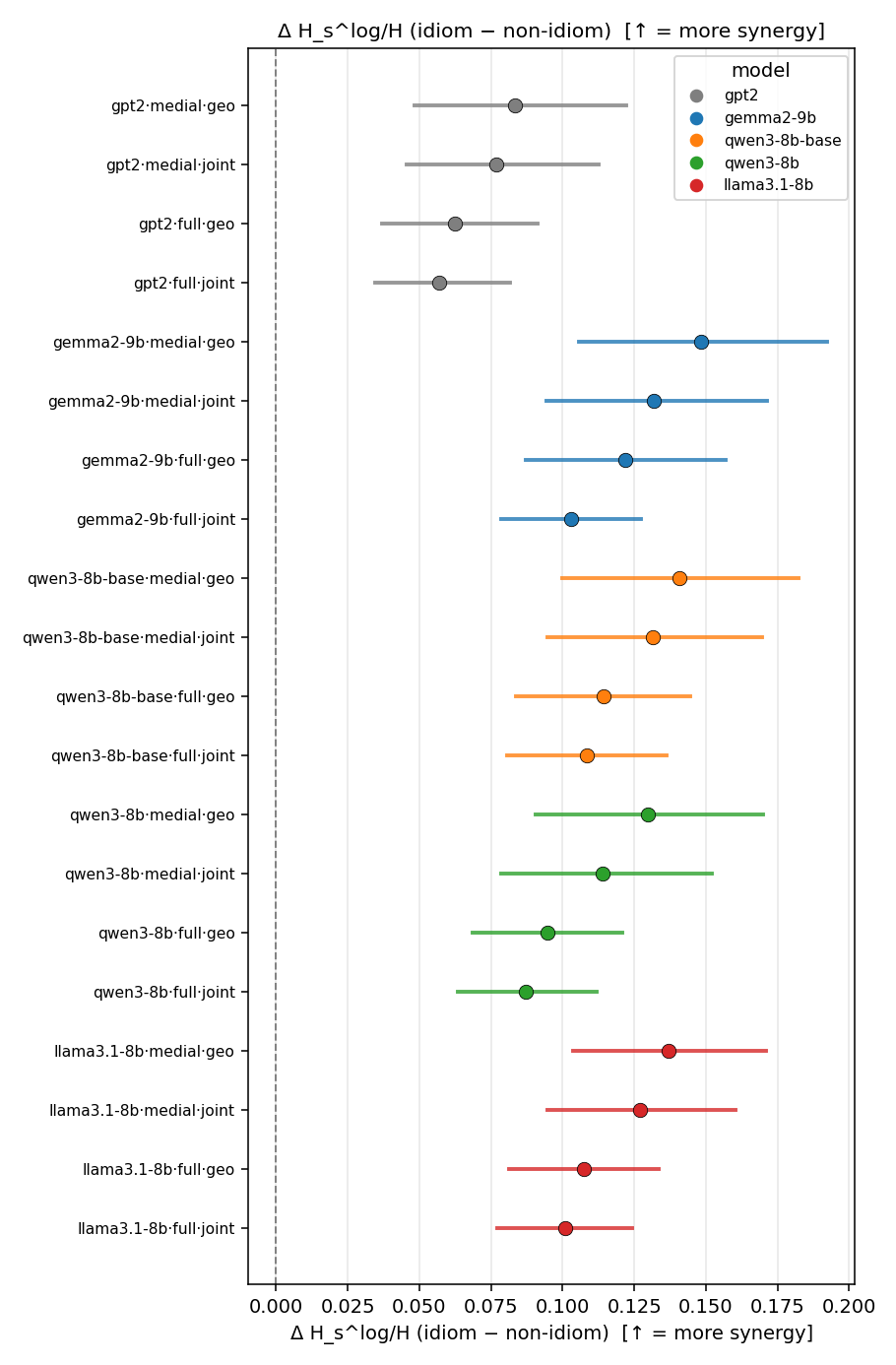
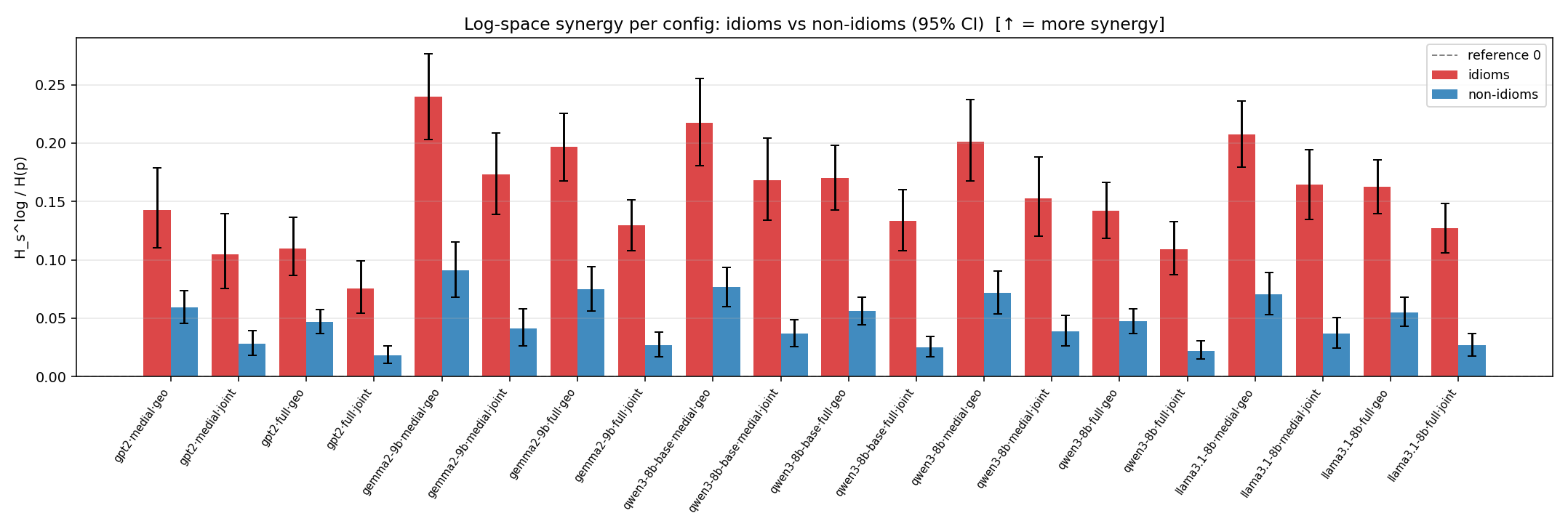
- \(H_s^{\log}\) — \(\operatorname{mean}\max\{0,\ \log p-\log m\}\) = avg surprisal reduction vs the best word. ↑ bigger = MORE synergy, finite always. Recommended magnitude. (Signed twin can go negative.)
- \(H_s\) (original) — \(\operatorname{mean}(-\log\max\{0,p-m\})\). The excess \(p-m\) grows with synergy, but \(-\log\) inverts it: ↓ bigger = LESS synergy, and a single non-synergistic context (\(p\le m\)) makes it \(+\infty\). So \(+\infty\) means "has a compositional context" = less idiomatic. Mostly \(+\infty\) → unusable per-phrase.
- \(H_s^{\mathrm{reg}}\) — same as \(H_s\) but the excess is floored at \(\varepsilon p\) (\(\varepsilon=0.01\)), so a non-synergistic context contributes a large-but-finite penalty instead of \(+\infty\). ↓ bigger = LESS synergy, but now continuous in the number of compositional contexts (1 vs 5 are distinguishable; the original calls both \(+\infty\)).
Direction cheat-sheet
| metric | range | direction | one-liner |
|---|---|---|---|
| \(H(p)\) | \(\ge 0\) | ↓ smaller = more concentrated | how spread the idiom is over contexts |
| \(H_u/H(p)\) | \(\ge 1\) | ↑ bigger = MORE synergy | headline — idiom beyond its best word |
| syn_frac | \([0,1]\) | ↑ bigger = MORE synergy | fraction of contexts that are synergistic |
| \(H_s^{\log}\) (and \(/H\)) | \(\ge 0\) | ↑ bigger = MORE synergy | avg surprisal reduction vs best word (recommended) |
| \(H_s^{\mathrm{reg}}\) (and \(/H\)) | \(\ge H(p)\) / \(\ge 1\) | ↓ bigger = LESS synergy | finite, continuous twin of original \(H_s\) |
| \(H_s\) (orig, and \(/H\)) | \(\ge 0\) or \(+\infty\) | ↓ bigger = LESS synergy | \(+\infty\) ⇔ a compositional context exists (brittle) |
\(H_u/H(p)\), syn_frac, and \(H_s^{\log}\) all point up with synergy — trust those. \(H_s\) and \(H_s^{\mathrm{reg}}\) are surprisals of the excess, so they point down.
Is it just H(p)? — step 1: the identity \(\hat H_u = \hat H(p) + \hat H_s^{\log}\)
\(H(p)\) differs sharply between idioms and non-idioms (idioms lower) and \(H(p)\) sits in the denominator of the headline ratio. So before claiming idioms have more synergy, we must rule out that "idioms have higher \(\hat H_u/\hat H(p)\)" is merely "idioms have smaller \(\hat H(p)\)". This step fixes the exact algebra; step 2 turns it into a test; step 3 reports the numbers.
1 · Setup: population quantities and their estimators
Fix an idiom and let \(p\) be its distribution over contexts. We do not observe \(p\); we observe a finite set of contexts which we treat as an i.i.d. sample \(c_1,\dots,c_N \sim p\). For a context \(c\), \(p(c)\in(0,1]\) is the LM's length-normalized score of the idiom there; \(q(c),r(c)\) are the scores of the verb-/noun-literal pools, and \(m(c):=\max\{q(c),r(c)\}\) is the better single component word (all strictly positive). The surprisal of a score \(x\in(0,1]\) is \(-\log x \ge 0\).
The quantities of interest are population expectations under \(p\) (estimands):
We cannot evaluate these expectations directly, so for each phrase we report the Monte-Carlo estimators — the sample means over the observed contexts. This is why we average:
By the law of large numbers each is consistent and unbiased for its estimand, \(\mathbb{E}\bigl[\hat H(p)\bigr]=H(p)\) (and likewise for \(\hat H_u,\hat H_s^{\log}\)). Everything downstream — the tables, bootstrap CIs and regressions — operates on these per-phrase estimators, and the CIs quantify their sampling error.
2 · Lemma (pointwise) \(-\log\min\{a,b\} = \max(-\log a,\,-\log b)\)
For \(a,b>0\): \(\min\{a,b\}\) is the smaller value and \(-\log\) is strictly decreasing, so the log of the smaller value is the larger surprisal. Hence \(-\log\min\{a,b\} = \max(-\log a,\,-\log b)\). \(\;\blacksquare\)
3 · Theorem \(H_u = H(p) + H_s^{\log}\) (and identically \(\hat H_u = \hat H(p) + \hat H_s^{\log}\))
Apply the Lemma with \(a=p(c)\), \(b=m(c)\), then the elementary identity \(\max(\alpha,\beta)=\alpha+\max(0,\beta-\alpha)\) with \(\alpha=-\log p(c)\), \(\beta=-\log m(c)\). This gives, for every context \(c\) (a deterministic, pointwise statement):
Because it holds pointwise, applying \(\mathbb{E}_{c\sim p}[\cdot]\) to both sides gives the population identity \(H_u = H(p)+H_s^{\log}\); applying the sample mean \(\tfrac1N\sum_i[\cdot]\) gives the same identity for the estimators:
The split is therefore exact at both the population and the estimate level (verified in the data to ~1e-15). Corollary, dividing the estimators by \(\hat H(p)\):
So the headline ratio is exactly \(1\) plus the synergy estimator rescaled by the base-entropy estimator. It is therefore not independent of \(\hat H(p)\) — which is exactly why step 2 is needed.
Is it just H(p)? — step 2: is it a confound, and how we test it
The confound, stated precisely
Let \(D=1\) for idioms, \(0\) for non-idioms. Empirically \(D\) shifts both \(\hat H(p)\) (down) and \(\hat H_u/\hat H(p)\) (up). By the identity in step 1, a group difference in the ratio can come from (i) a larger numerator \(\hat H_s^{\log}\), or (ii) a smaller denominator \(\hat H(p)\), or both. The substantive, theory-backed claim is (i) — the idiom concentrates beyond what its best word predicts. We must isolate (i) from (ii).
Why dividing is not controlling
Forming the ratio does not remove the \(\hat H(p)\) effect. "Controlling for \(\hat H(p)\)" means estimating the group effect at a fixed value of \(\hat H(p)\) — a conditional (partial) effect. A ratio instead rescales by \(\hat H(p)\): for equal absolute synergy, the phrase with smaller \(\hat H(p)\) gets a larger ratio, so the ratio can move purely because the denominator shrank. We therefore test the numerator directly, two ways.
Method A — ANCOVA (partial effect at fixed H(p))
Let phrase \(j\) have estimators \(S_j := \hat H_s^{\log}\) and \(H_j := \hat H(p)\) (from step 1), and \(D_j\in\{0,1\}\). Across the \(2{\times}18\) phrases fit by ordinary least squares:
\(\beta\) is the idiom–nonidiom difference in synergy holding \(H(p)\) fixed. We test \(H_0:\beta=0\) with \(t=\hat\beta/\operatorname{se}(\hat\beta)\), \(\mathrm{df}=n-3\), where \(\operatorname{se}=\sqrt{\bigl[\hat\sigma^2 (X^{\top}X)^{-1}\bigr]_{\beta\beta}}\) and \(\hat\sigma^2=\mathrm{RSS}/\mathrm{df}\). Comparing \(\hat\beta\) to the uncontrolled slope from \(S=\alpha+\beta D\) shows how much of the raw synergy gap \(H(p)\) accounts for. The pooled fit adds model fixed effects (dummies).
Method B — exact decomposition of the ratio gap
With group means \(\bar S_i,\bar S_n,\bar H_i,\bar H_n\), add and subtract \(\bar S_n/\bar H_i\):
The first term is the gap that would remain if both groups shared idioms' \(H(p)\); the second is the gap that would remain if both groups shared non-idioms' synergy. Each term's share of \(\Delta R\) is the % of the ratio gap that source explains.
Caveat — H(p) is partly a mediator
\(H_s^{\log}\) and \(H(p)\) are negatively correlated (more concentrated ⇒ more synergy; see the correlation column in step 3). If low \(H(p)\) is itself a consequence of idiomaticity, then \(H(p)\) is a mediator, not a pure confounder, and the ANCOVA \(\beta\) under-states the total idiom effect. So the controlled \(\beta\) is a conservative lower bound; the true effect lies between it and the uncontrolled slope.
Is it just H(p)? — step 3: results & verdict
Per-config (medial · geo) and pooled across the five models; the two methods are
defined in step 2. All entries are the per-phrase MC estimators from step 1 (group means \(\bar S,\bar H\)
are over phrases). Rerun for any mode/reduction with
python code/confound_check.py --mode MODE --red RED.
Decomposition of the ratio gap (Method B). Per-config group means, the ratio gap ΔR, and the share carried by the synergy numerator vs the H(p) denominator.
| config | H(p) idiom | H(p) non | Hslog idiom | Hslog non | ratio_u idiom | ratio_u non | ΔR | synergy % | H(p) % |
|---|---|---|---|---|---|---|---|---|---|
| gpt2 | 4.405 | 4.733 | 0.597 | 0.268 | 1.143 | 1.059 | +0.0790 | 95% | 5% |
| gemma2-9b | 4.388 | 5.180 | 1.016 | 0.446 | 1.240 | 1.091 | +0.1454 | 89% | 11% |
| qwen3-8b-base | 4.083 | 4.608 | 0.853 | 0.341 | 1.217 | 1.076 | +0.1349 | 93% | 7% |
| qwen3-8b | 4.462 | 5.031 | 0.867 | 0.348 | 1.201 | 1.072 | +0.1251 | 93% | 7% |
| llama3.1-8b | 4.047 | 4.651 | 0.818 | 0.313 | 1.207 | 1.070 | +0.1348 | 93% | 7% |
| POOLED (5 models, +model FE) | 4.277 | 4.840 | 0.830 | 0.343 | 1.202 | 1.074 | +0.1232 | 92% | 8% |
ANCOVA on Hslog (Method A). Idiom coefficient β without and with H(p) as a covariate, the % the effect shrinks when H(p) is controlled, the H(p) slope γ, and the Hslog–H(p) correlation. β stays large and significant at fixed H(p).
| config | β uncontrolled (S ~ D) | β controlled (S ~ D + H(p)) | p (controlled) | shrink | γ = H(p) coef | corr(Hslog, H(p)) |
|---|---|---|---|---|---|---|
| gpt2 | +0.330 | +0.276 | 2e-04 | +16% | -0.164 (p=0.004) | -0.52 |
| gemma2-9b | +0.570 | +0.532 | 4e-06 | +7% | -0.047 (p=0.359) | -0.41 |
| qwen3-8b-base | +0.512 | +0.446 | 7e-07 | +13% | -0.127 (p=0.025) | -0.52 |
| qwen3-8b | +0.519 | +0.431 | 3e-06 | +17% | -0.154 (p=0.011) | -0.57 |
| llama3.1-8b | +0.505 | +0.429 | 1e-07 | +15% | -0.126 (p=0.019) | -0.59 |
| POOLED (5 models, +model FE) | +0.487 | +0.422 | 9e-26 | +13% | -0.115 (p=2e-06) | -0.44 |
Conclusion
Practice. Report the synergy as the additive Hslog = Hu − H(p) and test it with the ANCOVA above (or its non-finite-safe siblings), rather than treating Hu/H(p) as if it controlled for H(p). The ratio is a fine convenience index, but it conflates "more synergy" with "lower base entropy". Rerun with python code/confound_check.py --mode MODE --red RED.
Aggregate plots (across all configs)
Cross-model views combining the per-config results. Click any figure to zoom.
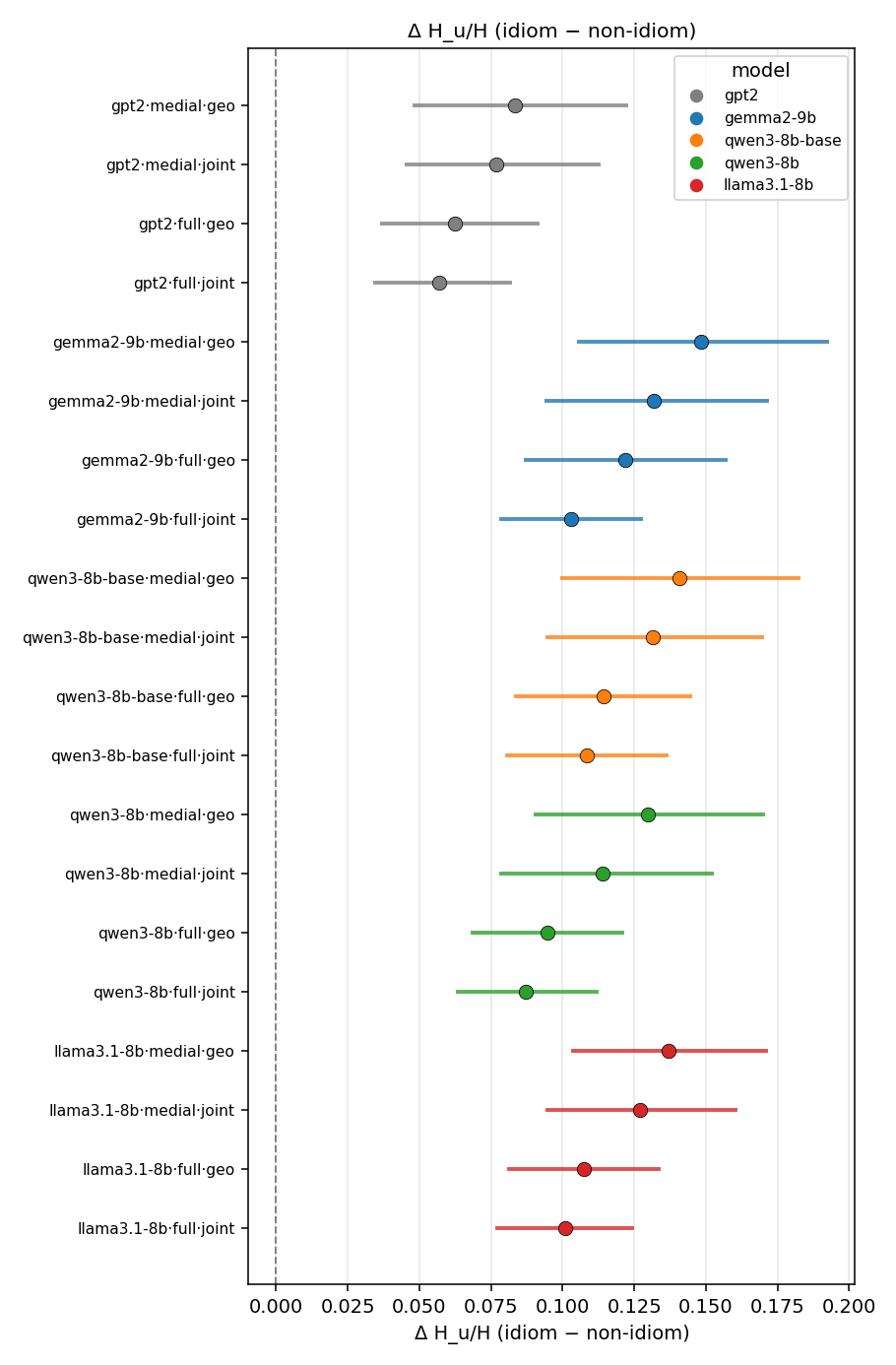
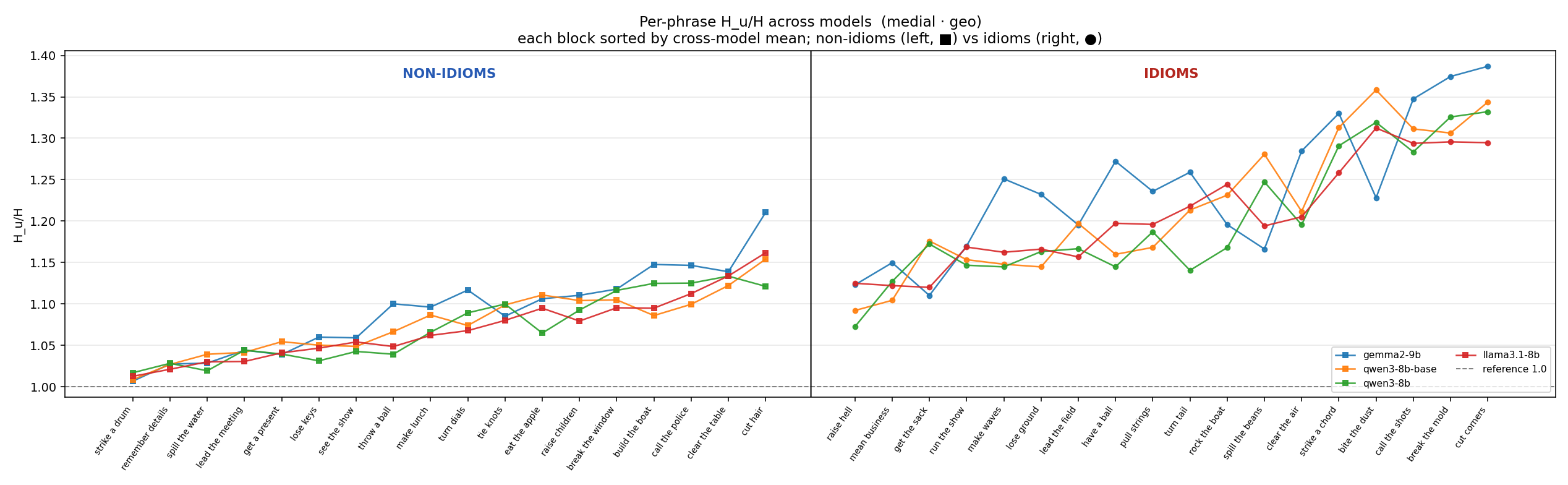
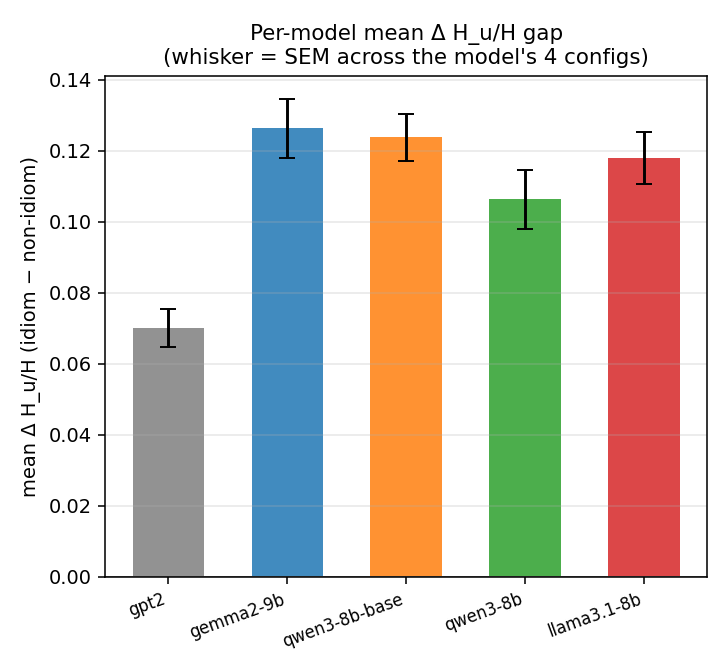
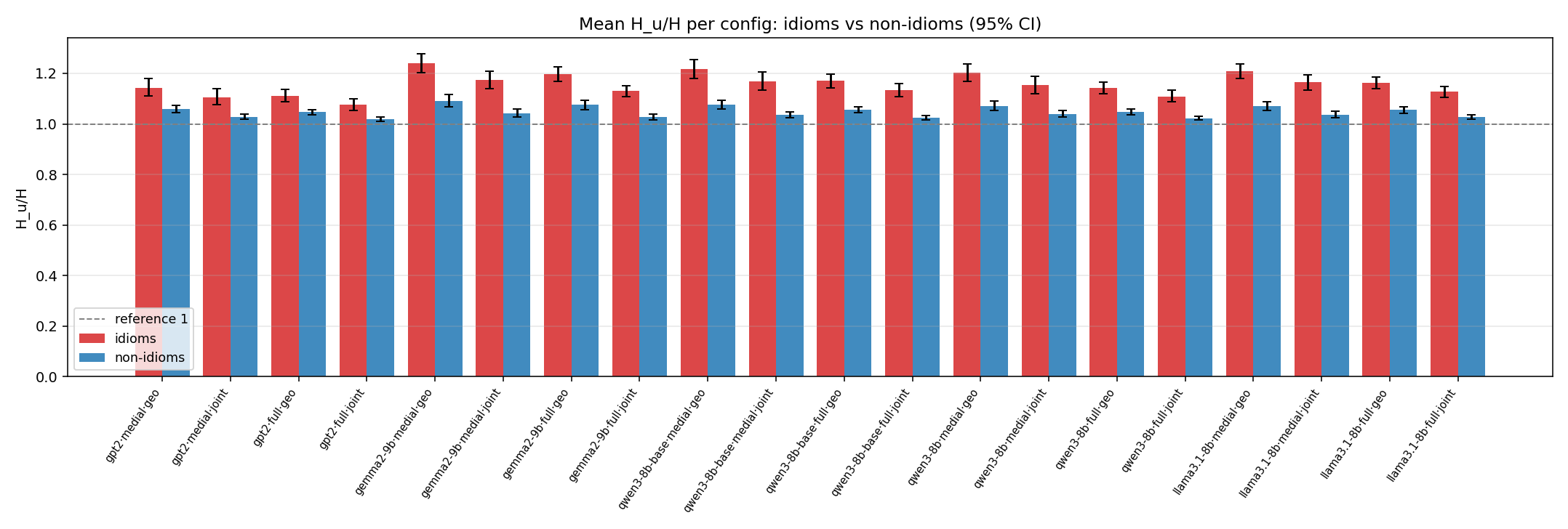
Bootstrap summary tables
Per-config mean for idioms and non-idioms (with finite-phrase count fin/N), and the idiom−nonidiom gap with a 20k-resample independent bootstrap 95% CI. Rows whose CI excludes 0 are shaded and marked ✓.
Hu / H(p)
unique-information ratio (≥ 1). ↑ bigger = MORE synergy — the headline metric
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 1.143 (18/18) | 1.059 (18/18) | 0.084 | [0.048, 0.122] | ✓ |
| gpt2 | medial | joint | 1.105 (18/18) | 1.028 (18/18) | 0.077 | [0.046, 0.113] | ✓ |
| gpt2 | full | geo | 1.110 (18/18) | 1.047 (18/18) | 0.063 | [0.037, 0.091] | ✓ |
| gpt2 | full | joint | 1.075 (18/18) | 1.018 (18/18) | 0.057 | [0.034, 0.082] | ✓ |
| gemma2-9b | medial | geo | 1.240 (18/18) | 1.091 (18/18) | 0.148 | [0.106, 0.192] | ✓ |
| gemma2-9b | medial | joint | 1.173 (18/18) | 1.041 (18/18) | 0.132 | [0.095, 0.171] | ✓ |
| gemma2-9b | full | geo | 1.197 (18/18) | 1.075 (18/18) | 0.122 | [0.087, 0.157] | ✓ |
| gemma2-9b | full | joint | 1.130 (18/18) | 1.027 (18/18) | 0.103 | [0.079, 0.127] | ✓ |
| qwen3-8b-base | medial | geo | 1.217 (18/18) | 1.076 (18/18) | 0.141 | [0.100, 0.182] | ✓ |
| qwen3-8b-base | medial | joint | 1.168 (18/18) | 1.037 (18/18) | 0.132 | [0.095, 0.170] | ✓ |
| qwen3-8b-base | full | geo | 1.170 (18/18) | 1.056 (18/18) | 0.114 | [0.084, 0.145] | ✓ |
| qwen3-8b-base | full | joint | 1.134 (18/18) | 1.025 (18/18) | 0.108 | [0.081, 0.136] | ✓ |
| qwen3-8b | medial | geo | 1.201 (18/18) | 1.072 (18/18) | 0.130 | [0.091, 0.170] | ✓ |
| qwen3-8b | medial | joint | 1.153 (18/18) | 1.039 (18/18) | 0.114 | [0.079, 0.152] | ✓ |
| qwen3-8b | full | geo | 1.142 (18/18) | 1.047 (18/18) | 0.095 | [0.069, 0.121] | ✓ |
| qwen3-8b | full | joint | 1.109 (18/18) | 1.022 (18/18) | 0.087 | [0.064, 0.112] | ✓ |
| llama3.1-8b | medial | geo | 1.207 (18/18) | 1.070 (18/18) | 0.137 | [0.104, 0.171] | ✓ |
| llama3.1-8b | medial | joint | 1.164 (18/18) | 1.037 (18/18) | 0.127 | [0.095, 0.160] | ✓ |
| llama3.1-8b | full | geo | 1.163 (18/18) | 1.055 (18/18) | 0.108 | [0.081, 0.134] | ✓ |
| llama3.1-8b | full | joint | 1.127 (18/18) | 1.027 (18/18) | 0.101 | [0.077, 0.124] | ✓ |
syn_frac
synergy coverage in [0,1] = frac. of contexts with p>m. ↑ bigger = MORE synergy (most intuitive)
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 0.944 (18/18) | 0.767 (18/18) | 0.178 | [0.044, 0.333] | ✓ |
| gpt2 | medial | joint | 0.822 (18/18) | 0.567 (18/18) | 0.256 | [0.089, 0.422] | ✓ |
| gpt2 | full | geo | 0.806 (18/18) | 0.617 (18/18) | 0.189 | [0.061, 0.311] | ✓ |
| gpt2 | full | joint | 0.750 (18/18) | 0.411 (18/18) | 0.339 | [0.178, 0.494] | ✓ |
| gemma2-9b | medial | geo | 0.933 (18/18) | 0.700 (18/18) | 0.233 | [0.122, 0.344] | ✓ |
| gemma2-9b | medial | joint | 0.856 (18/18) | 0.511 (18/18) | 0.344 | [0.200, 0.489] | ✓ |
| gemma2-9b | full | geo | 0.883 (18/18) | 0.617 (18/18) | 0.267 | [0.122, 0.406] | ✓ |
| gemma2-9b | full | joint | 0.794 (18/18) | 0.422 (18/18) | 0.372 | [0.211, 0.522] | ✓ |
| qwen3-8b-base | medial | geo | 0.956 (18/18) | 0.756 (18/18) | 0.200 | [0.100, 0.311] | ✓ |
| qwen3-8b-base | medial | joint | 0.833 (18/18) | 0.556 (18/18) | 0.278 | [0.156, 0.411] | ✓ |
| qwen3-8b-base | full | geo | 0.883 (18/18) | 0.622 (18/18) | 0.261 | [0.139, 0.372] | ✓ |
| qwen3-8b-base | full | joint | 0.811 (18/18) | 0.439 (18/18) | 0.372 | [0.211, 0.522] | ✓ |
| qwen3-8b | medial | geo | 0.956 (18/18) | 0.733 (18/18) | 0.222 | [0.100, 0.333] | ✓ |
| qwen3-8b | medial | joint | 0.856 (18/18) | 0.544 (18/18) | 0.311 | [0.167, 0.456] | ✓ |
| qwen3-8b | full | geo | 0.839 (18/18) | 0.567 (18/18) | 0.272 | [0.150, 0.383] | ✓ |
| qwen3-8b | full | joint | 0.778 (18/18) | 0.333 (18/18) | 0.444 | [0.317, 0.567] | ✓ |
| llama3.1-8b | medial | geo | 0.978 (18/18) | 0.744 (18/18) | 0.233 | [0.122, 0.333] | ✓ |
| llama3.1-8b | medial | joint | 0.944 (18/18) | 0.578 (18/18) | 0.367 | [0.233, 0.500] | ✓ |
| llama3.1-8b | full | geo | 0.889 (18/18) | 0.661 (18/18) | 0.228 | [0.100, 0.350] | ✓ |
| llama3.1-8b | full | joint | 0.856 (18/18) | 0.472 (18/18) | 0.383 | [0.217, 0.533] | ✓ |
Hslog
log-space synergy (nats), finite. ↑ bigger = MORE synergy (recommended magnitude)
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 0.597 (18/18) | 0.268 (18/18) | 0.330 | [0.200, 0.468] | ✓ |
| gpt2 | medial | joint | 5.423 (18/18) | 1.577 (18/18) | 3.847 | [2.358, 5.395] | ✓ |
| gpt2 | full | geo | 0.507 (18/18) | 0.231 (18/18) | 0.276 | [0.168, 0.398] | ✓ |
| gpt2 | full | joint | 4.097 (18/18) | 1.074 (18/18) | 3.023 | [1.895, 4.223] | ✓ |
| gemma2-9b | medial | geo | 1.016 (18/18) | 0.446 (18/18) | 0.570 | [0.404, 0.737] | ✓ |
| gemma2-9b | medial | joint | 9.732 (18/18) | 2.653 (18/18) | 7.079 | [5.042, 9.162] | ✓ |
| gemma2-9b | full | geo | 0.892 (18/18) | 0.389 (18/18) | 0.503 | [0.360, 0.650] | ✓ |
| gemma2-9b | full | joint | 7.526 (18/18) | 1.794 (18/18) | 5.732 | [4.414, 7.031] | ✓ |
| qwen3-8b-base | medial | geo | 0.853 (18/18) | 0.341 (18/18) | 0.512 | [0.376, 0.651] | ✓ |
| qwen3-8b-base | medial | joint | 8.100 (18/18) | 2.004 (18/18) | 6.096 | [4.425, 7.808] | ✓ |
| qwen3-8b-base | full | geo | 0.707 (18/18) | 0.263 (18/18) | 0.444 | [0.334, 0.556] | ✓ |
| qwen3-8b-base | full | joint | 6.563 (18/18) | 1.425 (18/18) | 5.137 | [3.854, 6.416] | ✓ |
| qwen3-8b | medial | geo | 0.867 (18/18) | 0.348 (18/18) | 0.519 | [0.376, 0.662] | ✓ |
| qwen3-8b | medial | joint | 8.056 (18/18) | 2.299 (18/18) | 5.757 | [4.013, 7.577] | ✓ |
| qwen3-8b | full | geo | 0.653 (18/18) | 0.243 (18/18) | 0.410 | [0.302, 0.520] | ✓ |
| qwen3-8b | full | joint | 5.928 (18/18) | 1.361 (18/18) | 4.566 | [3.373, 5.789] | ✓ |
| llama3.1-8b | medial | geo | 0.818 (18/18) | 0.313 (18/18) | 0.505 | [0.390, 0.623] | ✓ |
| llama3.1-8b | medial | joint | 8.584 (18/18) | 2.175 (18/18) | 6.409 | [4.733, 8.116] | ✓ |
| llama3.1-8b | full | geo | 0.686 (18/18) | 0.259 (18/18) | 0.427 | [0.328, 0.530] | ✓ |
| llama3.1-8b | full | joint | 6.876 (18/18) | 1.628 (18/18) | 5.248 | [4.016, 6.479] | ✓ |
Hslog / H(p)
log-space synergy ratio. ↑ bigger = MORE synergy
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 0.143 (18/18) | 0.059 (18/18) | 0.084 | [0.048, 0.122] | ✓ |
| gpt2 | medial | joint | 0.105 (18/18) | 0.028 (18/18) | 0.077 | [0.046, 0.113] | ✓ |
| gpt2 | full | geo | 0.110 (18/18) | 0.047 (18/18) | 0.063 | [0.037, 0.091] | ✓ |
| gpt2 | full | joint | 0.075 (18/18) | 0.018 (18/18) | 0.057 | [0.034, 0.082] | ✓ |
| gemma2-9b | medial | geo | 0.240 (18/18) | 0.091 (18/18) | 0.148 | [0.106, 0.192] | ✓ |
| gemma2-9b | medial | joint | 0.173 (18/18) | 0.041 (18/18) | 0.132 | [0.095, 0.171] | ✓ |
| gemma2-9b | full | geo | 0.197 (18/18) | 0.075 (18/18) | 0.122 | [0.087, 0.157] | ✓ |
| gemma2-9b | full | joint | 0.130 (18/18) | 0.027 (18/18) | 0.103 | [0.079, 0.127] | ✓ |
| qwen3-8b-base | medial | geo | 0.217 (18/18) | 0.076 (18/18) | 0.141 | [0.100, 0.182] | ✓ |
| qwen3-8b-base | medial | joint | 0.168 (18/18) | 0.037 (18/18) | 0.132 | [0.095, 0.170] | ✓ |
| qwen3-8b-base | full | geo | 0.170 (18/18) | 0.056 (18/18) | 0.114 | [0.084, 0.145] | ✓ |
| qwen3-8b-base | full | joint | 0.134 (18/18) | 0.025 (18/18) | 0.108 | [0.081, 0.136] | ✓ |
| qwen3-8b | medial | geo | 0.201 (18/18) | 0.072 (18/18) | 0.130 | [0.091, 0.170] | ✓ |
| qwen3-8b | medial | joint | 0.153 (18/18) | 0.039 (18/18) | 0.114 | [0.079, 0.152] | ✓ |
| qwen3-8b | full | geo | 0.142 (18/18) | 0.047 (18/18) | 0.095 | [0.069, 0.121] | ✓ |
| qwen3-8b | full | joint | 0.109 (18/18) | 0.022 (18/18) | 0.087 | [0.064, 0.112] | ✓ |
| llama3.1-8b | medial | geo | 0.207 (18/18) | 0.070 (18/18) | 0.137 | [0.104, 0.171] | ✓ |
| llama3.1-8b | medial | joint | 0.164 (18/18) | 0.037 (18/18) | 0.127 | [0.095, 0.160] | ✓ |
| llama3.1-8b | full | geo | 0.163 (18/18) | 0.055 (18/18) | 0.108 | [0.081, 0.134] | ✓ |
| llama3.1-8b | full | joint | 0.127 (18/18) | 0.027 (18/18) | 0.101 | [0.077, 0.124] | ✓ |
Hsreg
regularized, finite, continuous H_s (nats). ↑ bigger = LESS synergy
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 5.577 (18/18) | 6.979 (18/18) | -1.401 | [-2.217, -0.628] | ✓ |
| gpt2 | medial | joint | 54.688 (18/18) | 59.067 (18/18) | -4.378 | [-9.102, 0.168] | |
| gpt2 | full | geo | 6.511 (18/18) | 7.884 (18/18) | -1.373 | [-2.109, -0.666] | ✓ |
| gpt2 | full | joint | 57.583 (18/18) | 63.359 (18/18) | -5.776 | [-9.450, -2.116] | ✓ |
| gemma2-9b | medial | geo | 5.199 (18/18) | 7.318 (18/18) | -2.119 | [-2.936, -1.310] | ✓ |
| gemma2-9b | medial | joint | 58.195 (18/18) | 69.151 (18/18) | -10.956 | [-16.106, -5.805] | ✓ |
| gemma2-9b | full | geo | 5.754 (18/18) | 7.903 (18/18) | -2.149 | [-3.012, -1.264] | ✓ |
| gemma2-9b | full | joint | 60.119 (18/18) | 72.350 (18/18) | -12.231 | [-16.562, -7.847] | ✓ |
| qwen3-8b-base | medial | geo | 4.971 (18/18) | 6.767 (18/18) | -1.796 | [-2.479, -1.123] | ✓ |
| qwen3-8b-base | medial | joint | 50.115 (18/18) | 57.523 (18/18) | -7.408 | [-11.787, -3.121] | ✓ |
| qwen3-8b-base | full | geo | 5.519 (18/18) | 7.481 (18/18) | -1.962 | [-2.647, -1.264] | ✓ |
| qwen3-8b-base | full | joint | 51.096 (18/18) | 60.236 (18/18) | -9.140 | [-12.221, -6.128] | ✓ |
| qwen3-8b | medial | geo | 5.333 (18/18) | 7.263 (18/18) | -1.930 | [-2.645, -1.207] | ✓ |
| qwen3-8b | medial | joint | 54.672 (18/18) | 62.461 (18/18) | -7.789 | [-11.858, -3.655] | ✓ |
| qwen3-8b | full | geo | 6.171 (18/18) | 8.137 (18/18) | -1.966 | [-2.650, -1.274] | ✓ |
| qwen3-8b | full | joint | 56.448 (18/18) | 65.905 (18/18) | -9.457 | [-12.559, -6.406] | ✓ |
| llama3.1-8b | medial | geo | 4.818 (18/18) | 6.855 (18/18) | -2.037 | [-2.665, -1.403] | ✓ |
| llama3.1-8b | medial | joint | 53.152 (18/18) | 62.212 (18/18) | -9.060 | [-13.007, -5.224] | ✓ |
| llama3.1-8b | full | geo | 5.510 (18/18) | 7.452 (18/18) | -1.941 | [-2.614, -1.261] | ✓ |
| llama3.1-8b | full | joint | 55.396 (18/18) | 65.059 (18/18) | -9.663 | [-12.739, -6.633] | ✓ |
Hsreg / H(p)
regularized synergy ratio (≥ 1). ↑ bigger = LESS synergy
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 1.264 (18/18) | 1.468 (18/18) | -0.204 | [-0.298, -0.107] | ✓ |
| gpt2 | medial | joint | 1.017 (18/18) | 1.039 (18/18) | -0.022 | [-0.036, -0.008] | ✓ |
| gpt2 | full | geo | 1.365 (18/18) | 1.536 (18/18) | -0.171 | [-0.250, -0.089] | ✓ |
| gpt2 | full | joint | 1.022 (18/18) | 1.048 (18/18) | -0.026 | [-0.038, -0.013] | ✓ |
| gemma2-9b | medial | geo | 1.187 (18/18) | 1.416 (18/18) | -0.228 | [-0.312, -0.137] | ✓ |
| gemma2-9b | medial | joint | 1.012 (18/18) | 1.036 (18/18) | -0.024 | [-0.034, -0.013] | ✓ |
| gemma2-9b | full | geo | 1.234 (18/18) | 1.433 (18/18) | -0.199 | [-0.290, -0.101] | ✓ |
| gemma2-9b | full | joint | 1.017 (18/18) | 1.039 (18/18) | -0.023 | [-0.033, -0.012] | ✓ |
| qwen3-8b-base | medial | geo | 1.216 (18/18) | 1.469 (18/18) | -0.253 | [-0.333, -0.170] | ✓ |
| qwen3-8b-base | medial | joint | 1.016 (18/18) | 1.041 (18/18) | -0.025 | [-0.037, -0.013] | ✓ |
| qwen3-8b-base | full | geo | 1.284 (18/18) | 1.535 (18/18) | -0.250 | [-0.329, -0.162] | ✓ |
| qwen3-8b-base | full | joint | 1.018 (18/18) | 1.047 (18/18) | -0.030 | [-0.042, -0.016] | ✓ |
| qwen3-8b | medial | geo | 1.194 (18/18) | 1.442 (18/18) | -0.248 | [-0.344, -0.151] | ✓ |
| qwen3-8b | medial | joint | 1.013 (18/18) | 1.039 (18/18) | -0.025 | [-0.037, -0.013] | ✓ |
| qwen3-8b | full | geo | 1.303 (18/18) | 1.527 (18/18) | -0.224 | [-0.294, -0.147] | ✓ |
| qwen3-8b | full | joint | 1.019 (18/18) | 1.050 (18/18) | -0.031 | [-0.040, -0.021] | ✓ |
| llama3.1-8b | medial | geo | 1.190 (18/18) | 1.472 (18/18) | -0.282 | [-0.360, -0.196] | ✓ |
| llama3.1-8b | medial | joint | 1.006 (18/18) | 1.035 (18/18) | -0.029 | [-0.040, -0.018] | ✓ |
| llama3.1-8b | full | geo | 1.280 (18/18) | 1.518 (18/18) | -0.239 | [-0.319, -0.150] | ✓ |
| llama3.1-8b | full | joint | 1.013 (18/18) | 1.041 (18/18) | -0.028 | [-0.039, -0.015] | ✓ |
Hu
unique / redundant entropy (nats); ≥ H(p)
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 5.003 (18/18) | 5.001 (18/18) | 0.002 | [-0.352, 0.355] | |
| gpt2 | medial | joint | 59.207 (18/18) | 58.475 (18/18) | 0.732 | [-4.048, 5.556] | |
| gpt2 | full | geo | 5.255 (18/18) | 5.355 (18/18) | -0.100 | [-0.412, 0.204] | |
| gpt2 | full | joint | 60.424 (18/18) | 61.565 (18/18) | -1.141 | [-4.379, 2.284] | |
| gemma2-9b | medial | geo | 5.404 (18/18) | 5.627 (18/18) | -0.222 | [-0.791, 0.346] | |
| gemma2-9b | medial | joint | 67.242 (18/18) | 69.420 (18/18) | -2.179 | [-7.442, 2.991] | |
| gemma2-9b | full | geo | 5.540 (18/18) | 5.896 (18/18) | -0.357 | [-0.832, 0.110] | |
| gemma2-9b | full | joint | 66.644 (18/18) | 71.386 (18/18) | -4.741 | [-8.562, -0.865] | ✓ |
| qwen3-8b-base | medial | geo | 4.935 (18/18) | 4.948 (18/18) | -0.013 | [-0.392, 0.367] | |
| qwen3-8b-base | medial | joint | 57.427 (18/18) | 57.338 (18/18) | 0.089 | [-4.414, 4.643] | |
| qwen3-8b-base | full | geo | 4.981 (18/18) | 5.130 (18/18) | -0.149 | [-0.457, 0.155] | |
| qwen3-8b-base | full | joint | 56.744 (18/18) | 58.946 (18/18) | -2.202 | [-4.842, 0.431] | |
| qwen3-8b | medial | geo | 5.329 (18/18) | 5.379 (18/18) | -0.050 | [-0.412, 0.312] | |
| qwen3-8b | medial | joint | 61.997 (18/18) | 62.510 (18/18) | -0.513 | [-4.777, 3.839] | |
| qwen3-8b | full | geo | 5.370 (18/18) | 5.564 (18/18) | -0.194 | [-0.500, 0.107] | |
| qwen3-8b | full | joint | 61.273 (18/18) | 64.110 (18/18) | -2.837 | [-5.511, -0.111] | ✓ |
| llama3.1-8b | medial | geo | 4.865 (18/18) | 4.964 (18/18) | -0.099 | [-0.438, 0.241] | |
| llama3.1-8b | medial | joint | 61.434 (18/18) | 62.319 (18/18) | -0.885 | [-4.984, 3.254] | |
| llama3.1-8b | full | geo | 4.979 (18/18) | 5.153 (18/18) | -0.174 | [-0.458, 0.110] | |
| llama3.1-8b | full | joint | 61.542 (18/18) | 64.133 (18/18) | -2.591 | [-5.304, 0.151] |
H(p)
base entropy (nats). ↓ smaller = idiom more concentrated
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 4.405 (18/18) | 4.733 (18/18) | -0.327 | [-0.728, 0.068] | |
| gpt2 | medial | joint | 53.784 (18/18) | 56.898 (18/18) | -3.114 | [-7.793, 1.533] | |
| gpt2 | full | geo | 4.748 (18/18) | 5.124 (18/18) | -0.376 | [-0.723, -0.043] | ✓ |
| gpt2 | full | joint | 56.326 (18/18) | 60.490 (18/18) | -4.164 | [-7.626, -0.648] | ✓ |
| gemma2-9b | medial | geo | 4.388 (18/18) | 5.180 (18/18) | -0.792 | [-1.358, -0.227] | ✓ |
| gemma2-9b | medial | joint | 57.510 (18/18) | 66.768 (18/18) | -9.258 | [-14.355, -4.175] | ✓ |
| gemma2-9b | full | geo | 4.648 (18/18) | 5.507 (18/18) | -0.860 | [-1.353, -0.373] | ✓ |
| gemma2-9b | full | joint | 59.119 (18/18) | 69.592 (18/18) | -10.473 | [-14.544, -6.382] | ✓ |
| qwen3-8b-base | medial | geo | 4.083 (18/18) | 4.608 (18/18) | -0.525 | [-0.932, -0.113] | ✓ |
| qwen3-8b-base | medial | joint | 49.327 (18/18) | 55.334 (18/18) | -6.007 | [-10.345, -1.712] | ✓ |
| qwen3-8b-base | full | geo | 4.274 (18/18) | 4.868 (18/18) | -0.593 | [-0.936, -0.254] | ✓ |
| qwen3-8b-base | full | joint | 50.181 (18/18) | 57.521 (18/18) | -7.340 | [-10.174, -4.578] | ✓ |
| qwen3-8b | medial | geo | 4.462 (18/18) | 5.031 (18/18) | -0.569 | [-0.967, -0.165] | ✓ |
| qwen3-8b | medial | joint | 53.941 (18/18) | 60.211 (18/18) | -6.270 | [-10.398, -2.075] | ✓ |
| qwen3-8b | full | geo | 4.717 (18/18) | 5.320 (18/18) | -0.603 | [-0.944, -0.267] | ✓ |
| qwen3-8b | full | joint | 55.345 (18/18) | 62.749 (18/18) | -7.404 | [-10.265, -4.538] | ✓ |
| llama3.1-8b | medial | geo | 4.047 (18/18) | 4.651 (18/18) | -0.604 | [-0.979, -0.235] | ✓ |
| llama3.1-8b | medial | joint | 52.850 (18/18) | 60.144 (18/18) | -7.294 | [-11.182, -3.499] | ✓ |
| llama3.1-8b | full | geo | 4.293 (18/18) | 4.894 (18/18) | -0.601 | [-0.916, -0.294] | ✓ |
| llama3.1-8b | full | joint | 54.666 (18/18) | 62.505 (18/18) | -7.839 | [-10.650, -5.073] | ✓ |
Hs (original)
original synergy entropy (nats); +inf if ANY context non-synergistic (mostly dropped)
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 5.326 (15/18) | 5.892 (8/18) | -0.566 | [-1.133, 0.019] | |
| gpt2 | medial | joint | 54.443 (10/18) | 54.944 (2/18) | -0.501 | [-6.746, 5.519] | |
| gpt2 | full | geo | 5.019 (5/18) | 5.895 (1/18) | -0.876 | [-1.134, -0.686] | ✓ |
| gpt2 | full | joint | 52.454 (4/18) | 56.005 (2/18) | -3.550 | [-10.748, 3.419] | |
| gemma2-9b | medial | geo | 4.882 (13/18) | 5.653 (3/18) | -0.771 | [-1.825, 0.116] | |
| gemma2-9b | medial | joint | 57.353 (10/18) | 57.287 (1/18) | 0.066 | [-3.629, 3.862] | |
| gemma2-9b | full | geo | 4.871 (9/18) | 5.433 (1/18) | -0.562 | [-0.817, -0.283] | ✓ |
| gemma2-9b | full | joint | 59.718 (3/18) | 59.138 (1/18) | 0.580 | [-2.463, 5.771] | |
| qwen3-8b-base | medial | geo | 4.856 (15/18) | 5.746 (4/18) | -0.890 | [-1.497, -0.258] | ✓ |
| qwen3-8b-base | medial | joint | 49.063 (8/18) | — (0/18) | — | — | |
| qwen3-8b-base | full | geo | 4.774 (9/18) | — (0/18) | — | — | |
| qwen3-8b-base | full | joint | 47.830 (5/18) | — (0/18) | — | — | |
| qwen3-8b | medial | geo | 5.162 (15/18) | 5.769 (6/18) | -0.607 | [-1.159, -0.077] | ✓ |
| qwen3-8b | medial | joint | 52.503 (9/18) | 62.247 (1/18) | -9.744 | [-12.984, -6.662] | ✓ |
| qwen3-8b | full | geo | 5.089 (4/18) | — (0/18) | — | — | |
| qwen3-8b | full | joint | 49.996 (2/18) | — (0/18) | — | — | |
| llama3.1-8b | medial | geo | 4.739 (17/18) | 5.582 (5/18) | -0.844 | [-1.472, -0.242] | ✓ |
| llama3.1-8b | medial | joint | 52.826 (15/18) | 57.031 (2/18) | -4.205 | [-9.214, 0.812] | |
| llama3.1-8b | full | geo | 4.960 (8/18) | 5.424 (1/18) | -0.465 | [-0.829, -0.042] | ✓ |
| llama3.1-8b | full | joint | 53.727 (8/18) | 58.867 (2/18) | -5.140 | [-8.788, -1.453] | ✓ |
Hs / H(p) (original)
original synergy ratio; mostly +inf (use H_s^log or syn_frac instead)
| model | mode | reduction | idiom mean (fin/N) | non-idiom mean (fin/N) | Δ idiom−nonidiom | 95% CI | sig |
|---|---|---|---|---|---|---|---|
| gpt2 | medial | geo | 1.211 (15/18) | 1.352 (8/18) | -0.141 | [-0.213, -0.069] | ✓ |
| gpt2 | medial | joint | 1.001 (10/18) | 1.004 (2/18) | -0.003 | [-0.008, 0.001] | |
| gpt2 | full | geo | 1.194 (5/18) | 1.382 (1/18) | -0.188 | [-0.239, -0.152] | ✓ |
| gpt2 | full | joint | 1.000 (4/18) | 1.004 (2/18) | -0.004 | [-0.005, -0.002] | ✓ |
| gemma2-9b | medial | geo | 1.124 (13/18) | 1.302 (3/18) | -0.178 | [-0.414, 0.006] | |
| gemma2-9b | medial | joint | 1.000 (10/18) | 1.000 (1/18) | 0.000 | [-0.000, 0.001] | |
| gemma2-9b | full | geo | 1.148 (9/18) | 1.214 (1/18) | -0.066 | [-0.092, -0.040] | ✓ |
| gemma2-9b | full | joint | 1.000 (3/18) | 1.001 (1/18) | -0.001 | [-0.001, -0.001] | ✓ |
| qwen3-8b-base | medial | geo | 1.177 (15/18) | 1.354 (4/18) | -0.177 | [-0.329, -0.062] | ✓ |
| qwen3-8b-base | medial | joint | 1.001 (8/18) | — (0/18) | — | — | |
| qwen3-8b-base | full | geo | 1.198 (9/18) | — (0/18) | — | — | |
| qwen3-8b-base | full | joint | 1.001 (5/18) | — (0/18) | — | — | |
| qwen3-8b | medial | geo | 1.153 (15/18) | 1.256 (6/18) | -0.103 | [-0.151, -0.054] | ✓ |
| qwen3-8b | medial | joint | 1.002 (9/18) | 1.002 (1/18) | -0.001 | [-0.002, 0.001] | |
| qwen3-8b | full | geo | 1.203 (4/18) | — (0/18) | — | — | |
| qwen3-8b | full | joint | 1.001 (2/18) | — (0/18) | — | — | |
| llama3.1-8b | medial | geo | 1.170 (17/18) | 1.316 (5/18) | -0.146 | [-0.283, -0.039] | ✓ |
| llama3.1-8b | medial | joint | 1.001 (15/18) | 1.001 (2/18) | 0.000 | [-0.000, 0.001] | |
| llama3.1-8b | full | geo | 1.196 (8/18) | 1.321 (1/18) | -0.124 | [-0.159, -0.092] | ✓ |
| llama3.1-8b | full | joint | 1.001 (8/18) | 1.003 (2/18) | -0.002 | [-0.005, 0.000] |
gpt2 — per-config figures
3×9 grid of figure-type × metric (↑syn = bigger means more synergy, ↓syn = bigger means less). Tables scroll horizontally; “— (no finite values)” marks the original Hs/ratio_s where every phrase was +inf. Click to zoom.
gpt2 · medial · geo gpt2__medial__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 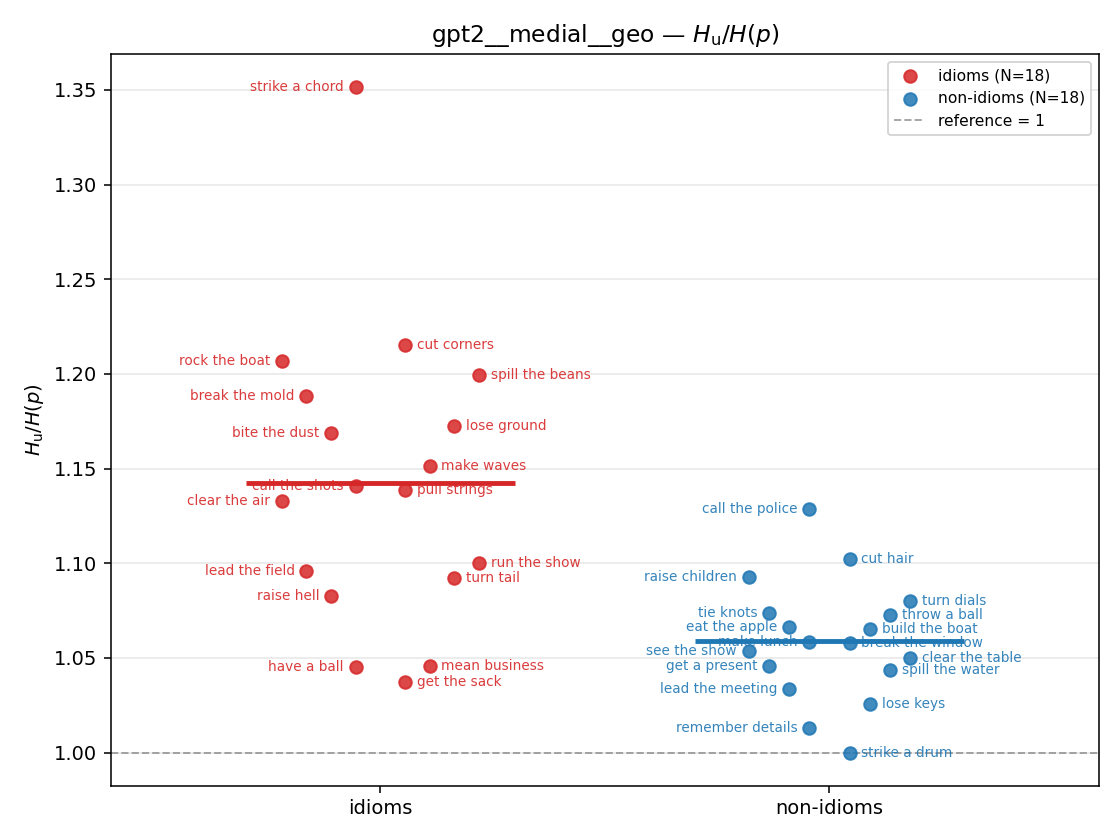 | 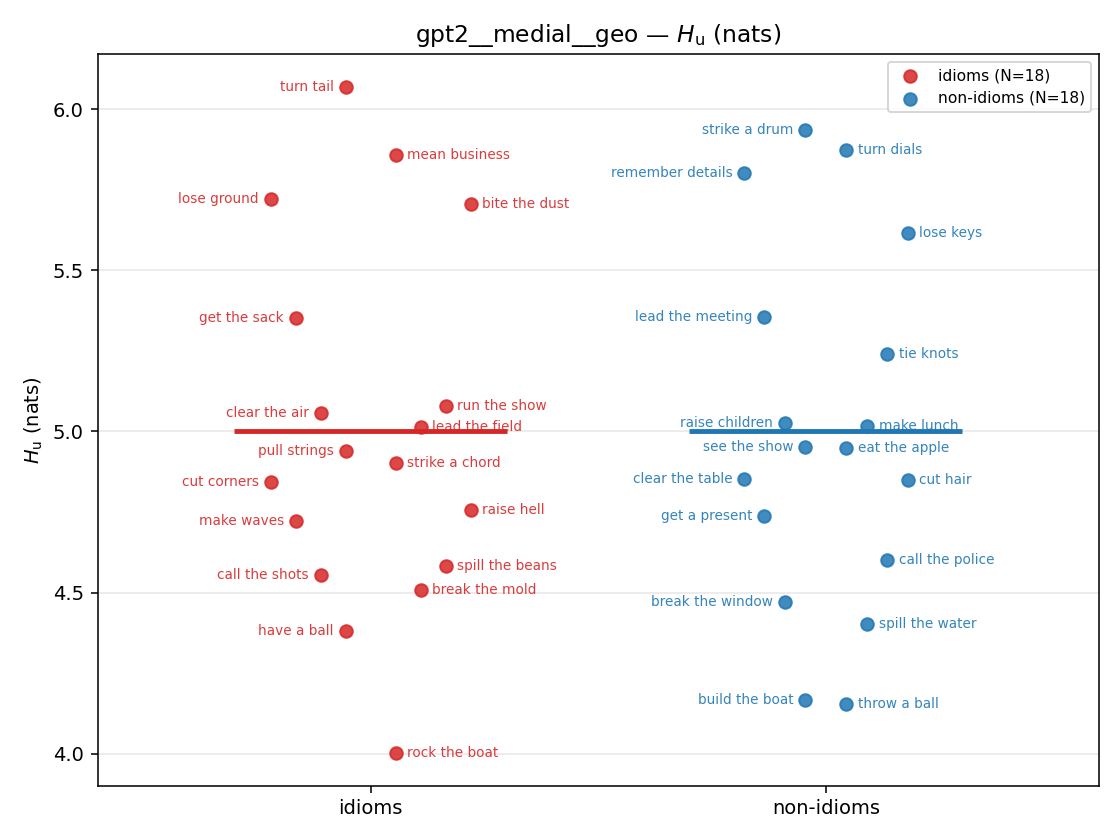 | 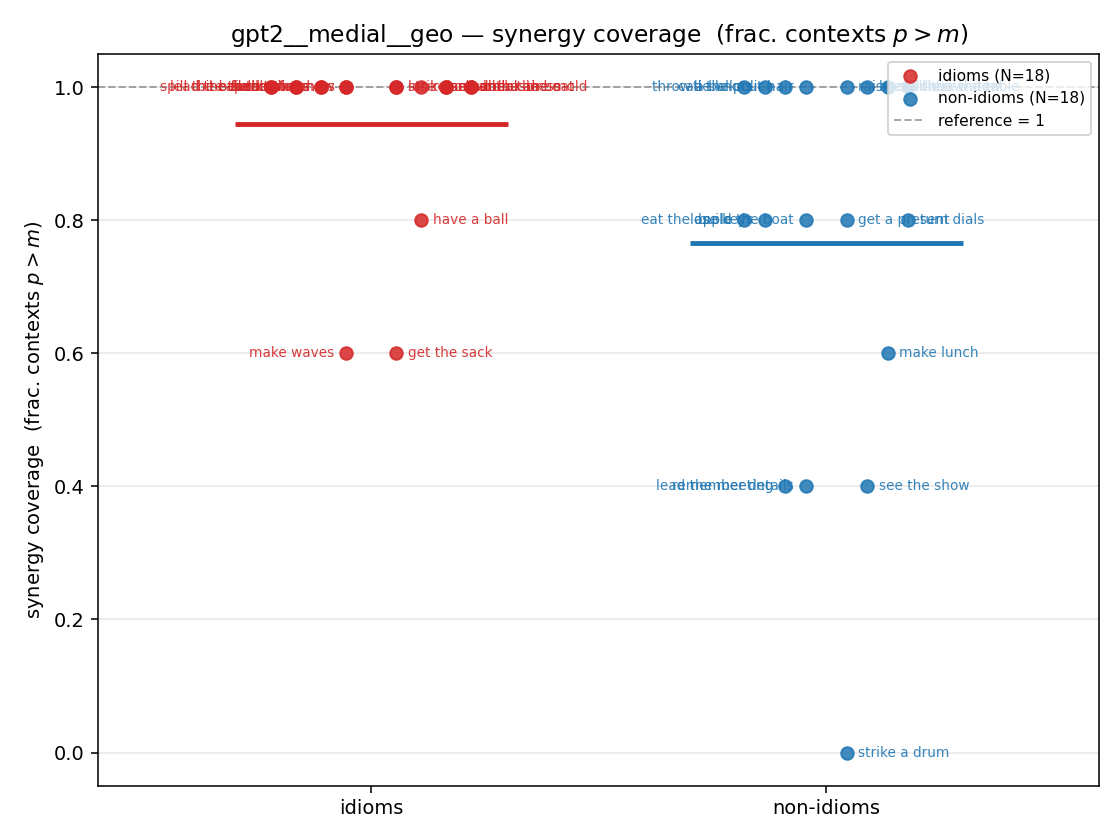 | 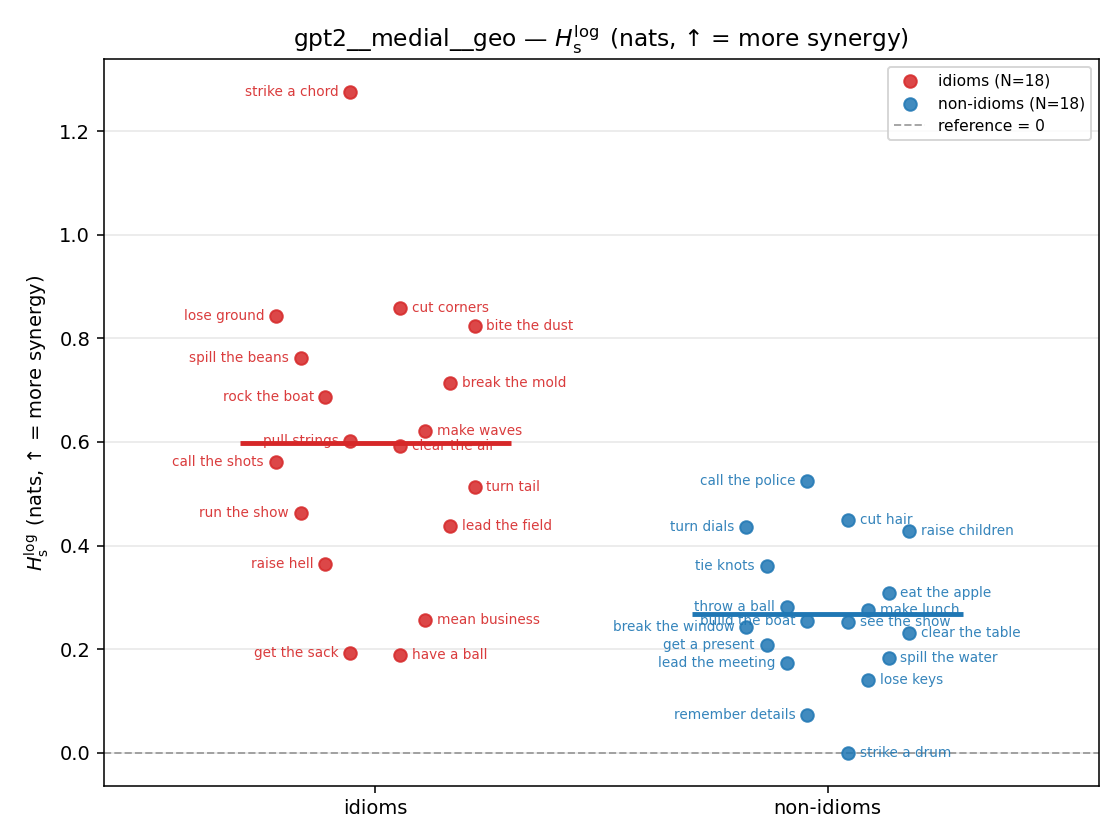 | 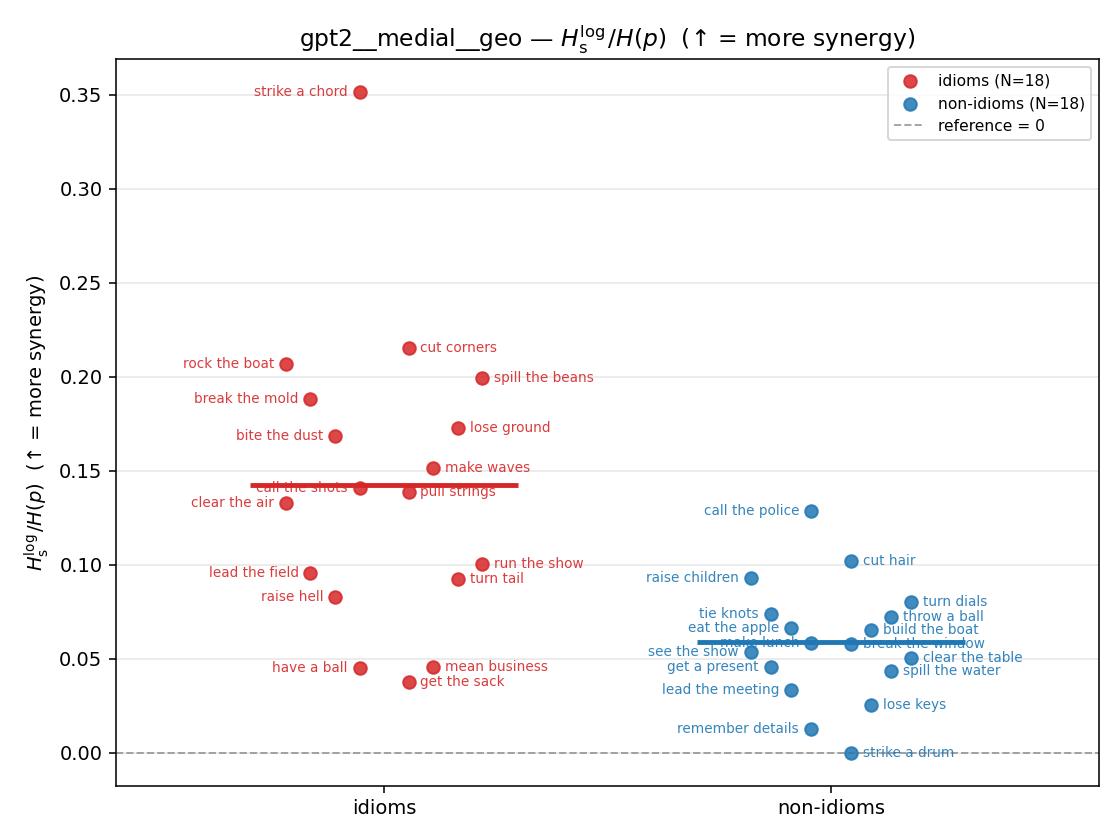 | 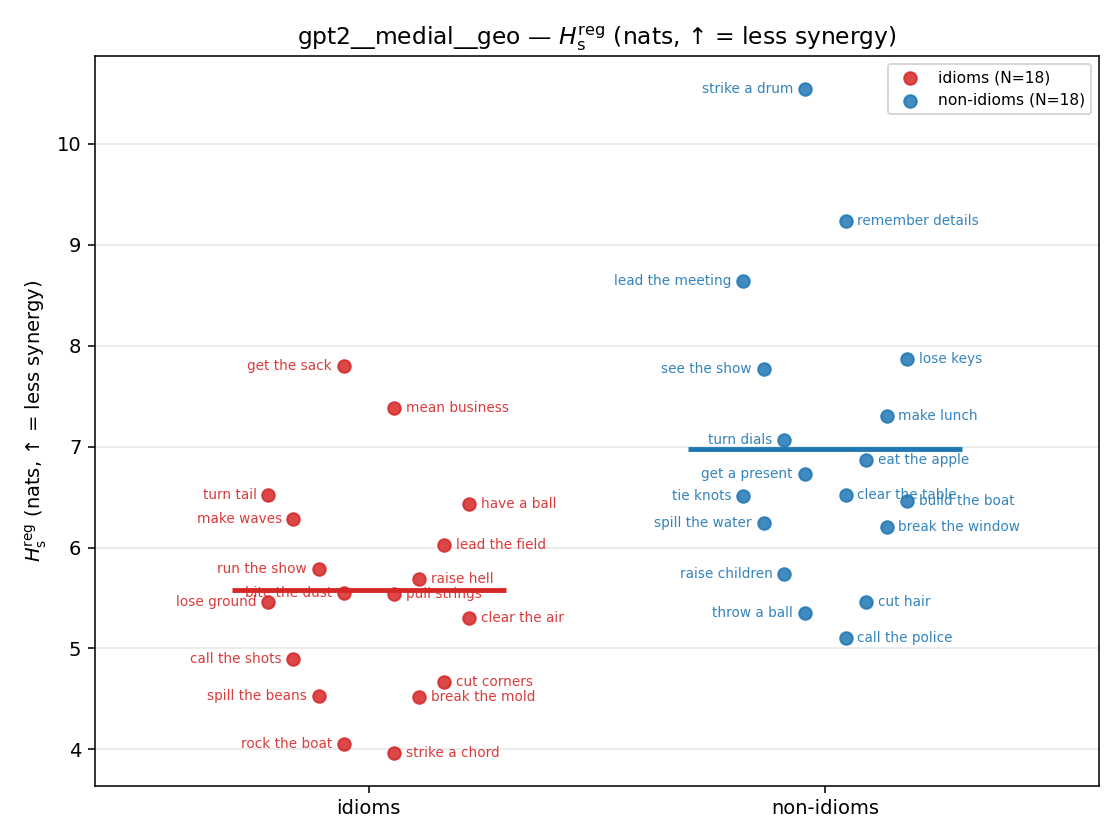 | 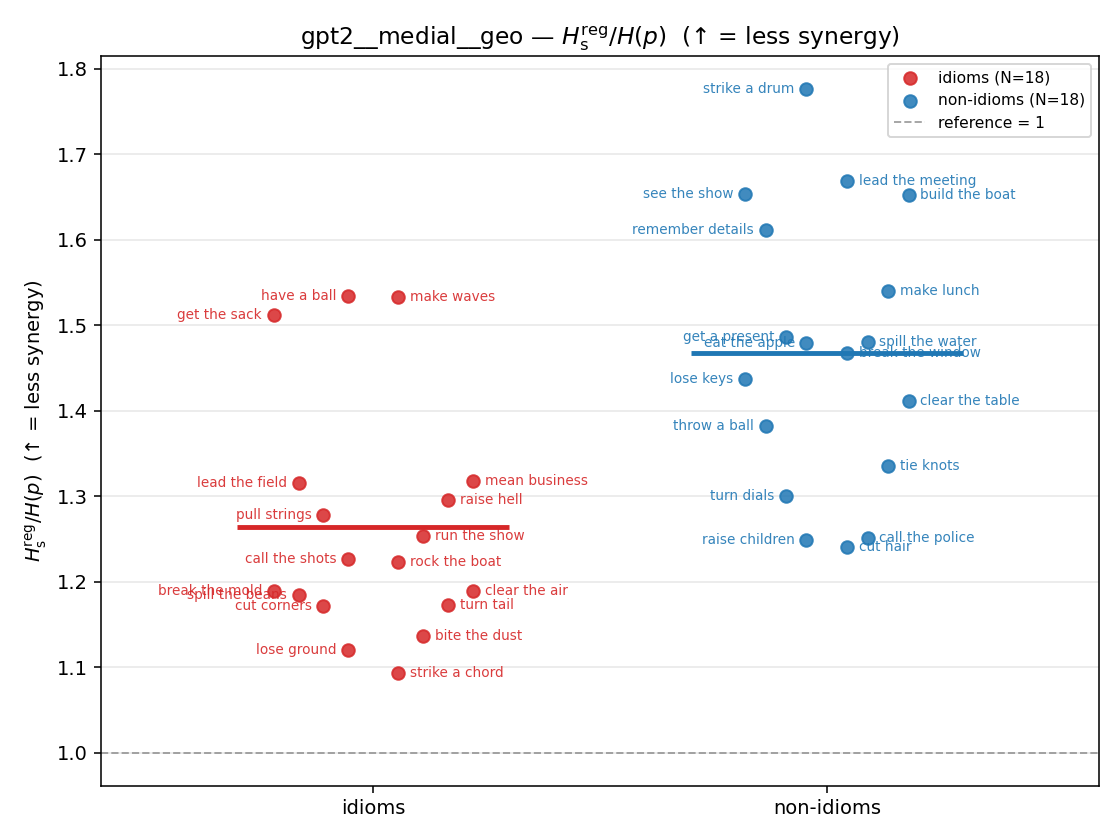 | 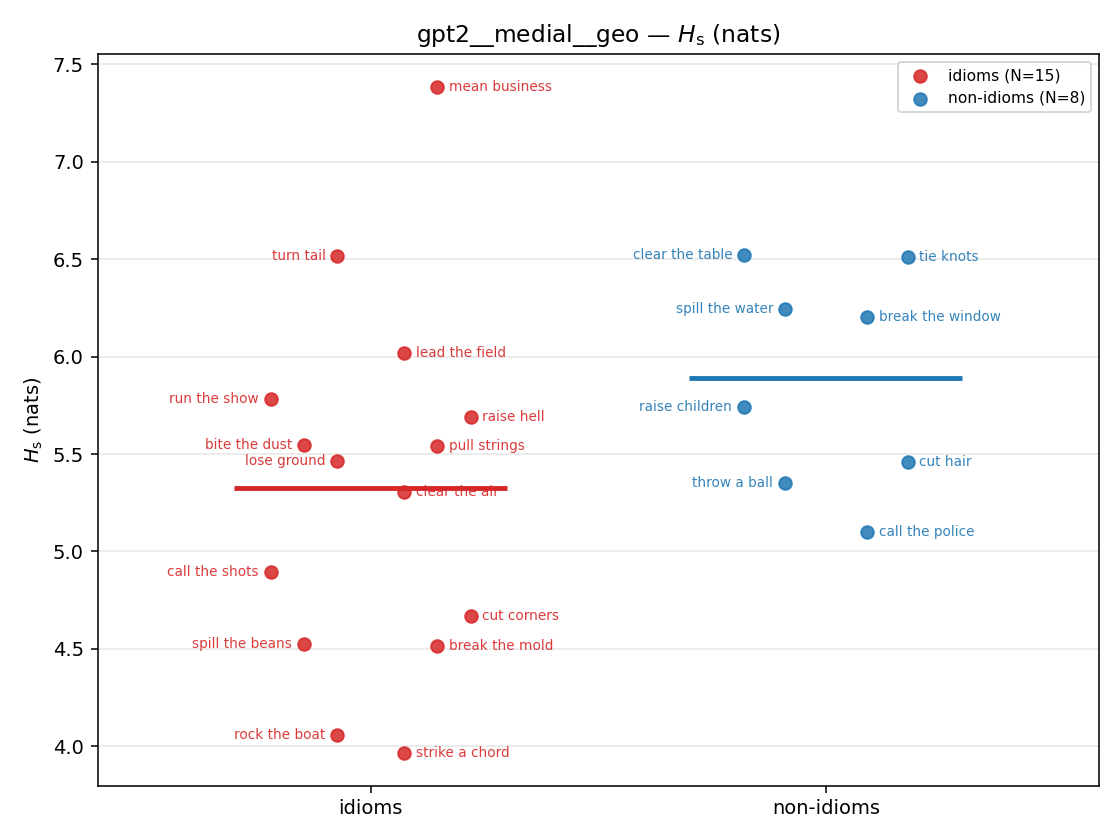 | 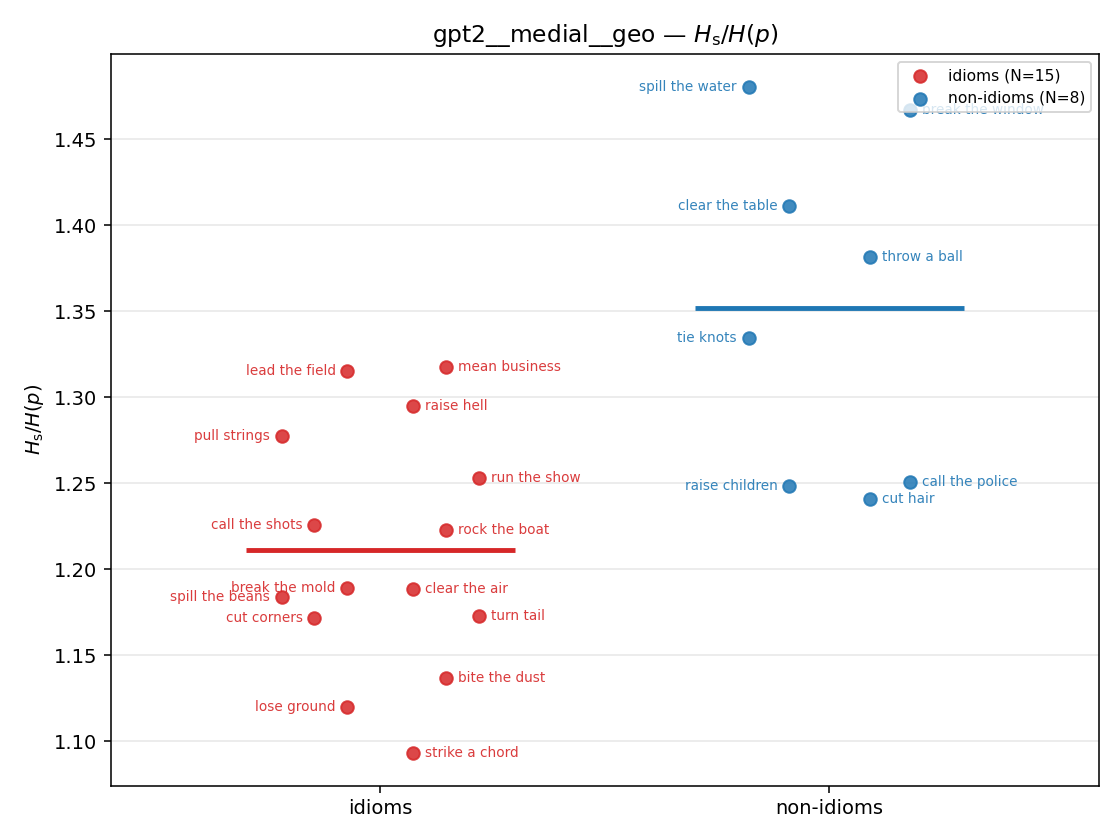 |
| mean ± 95% CI | 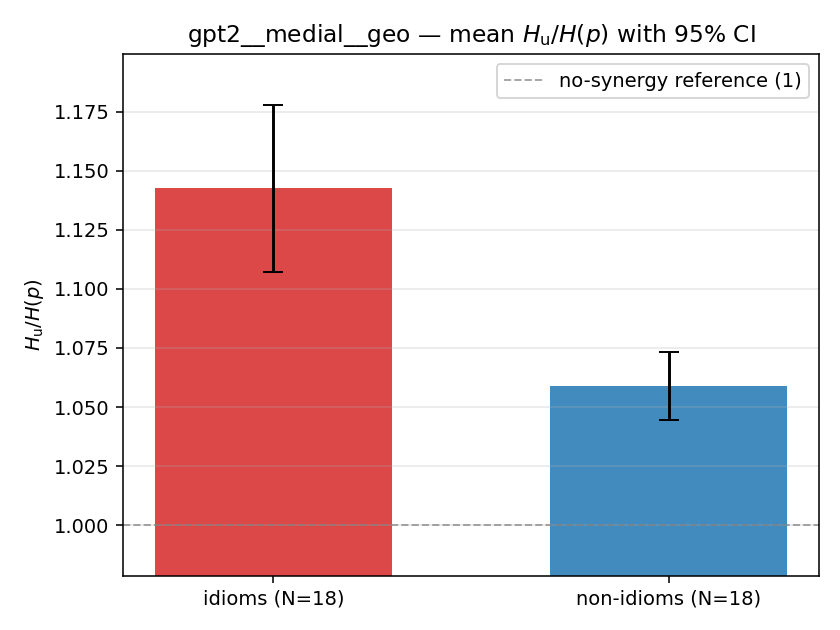 | 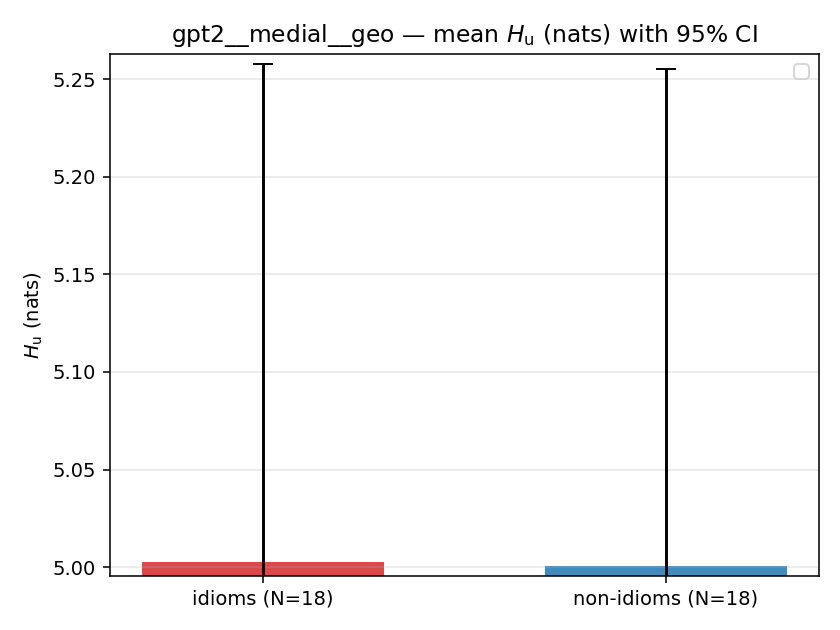 | 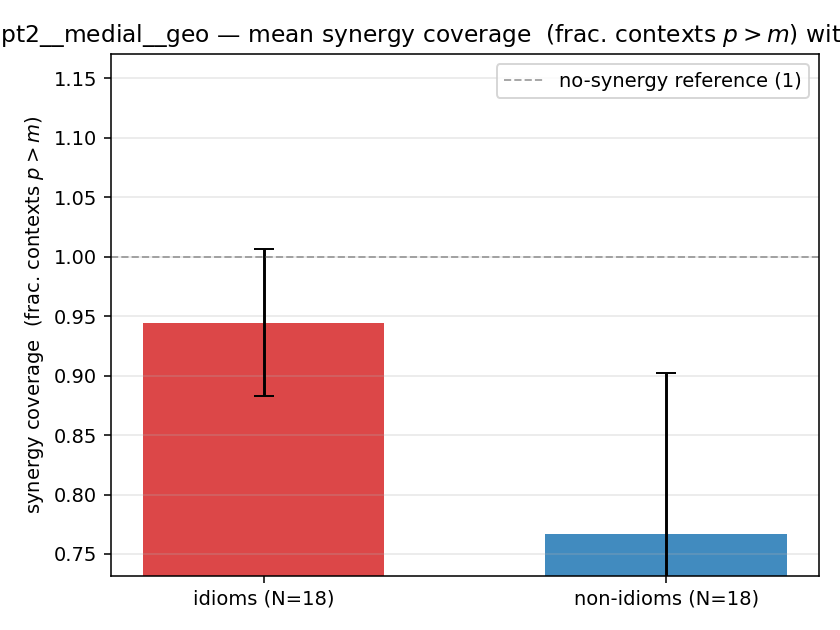 | 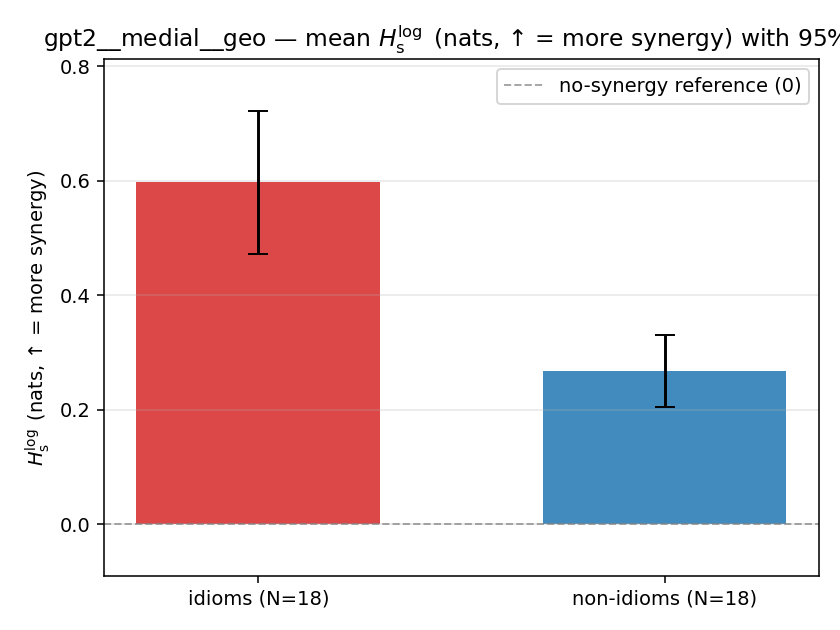 | 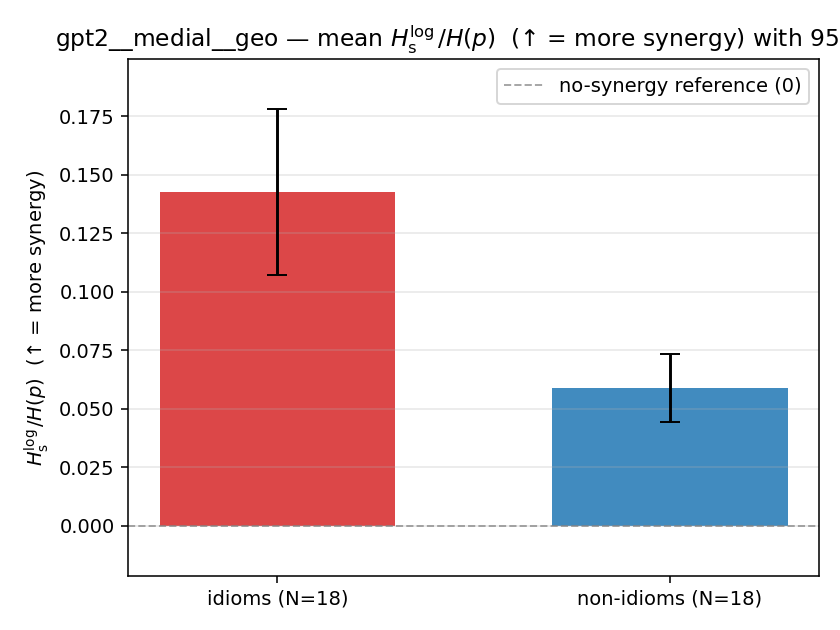 | 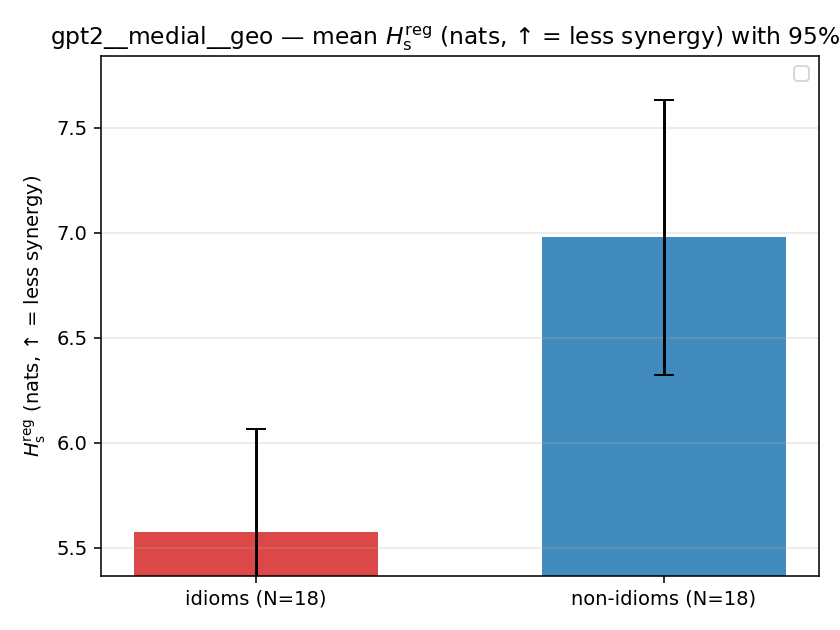 | 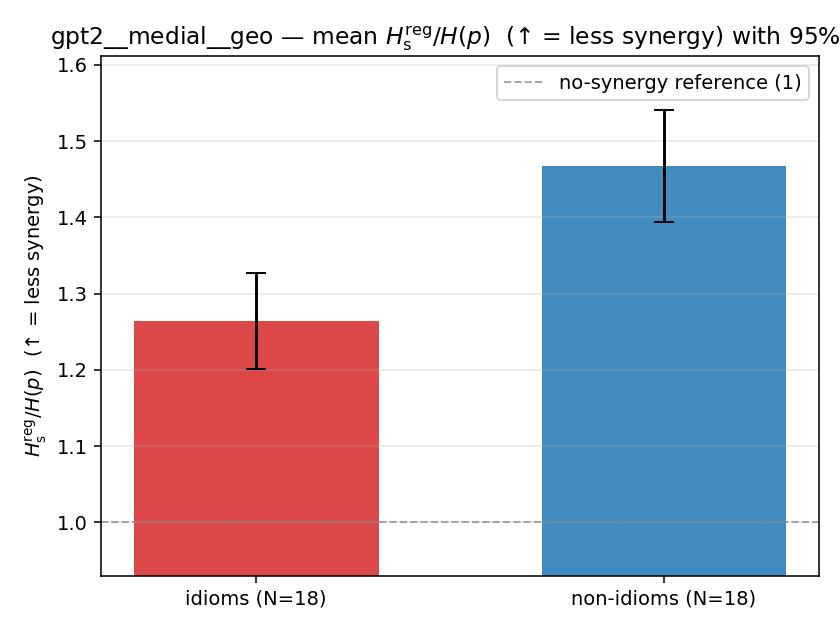 | 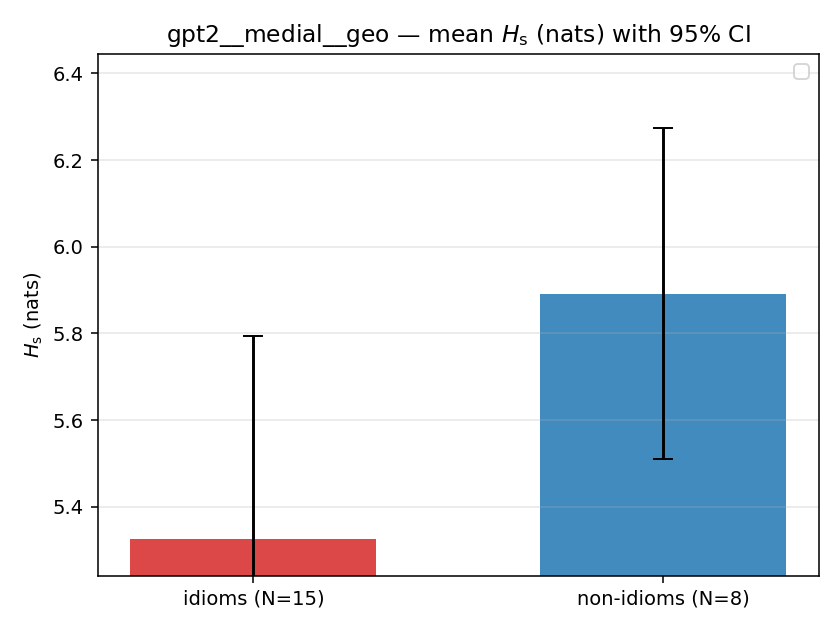 | 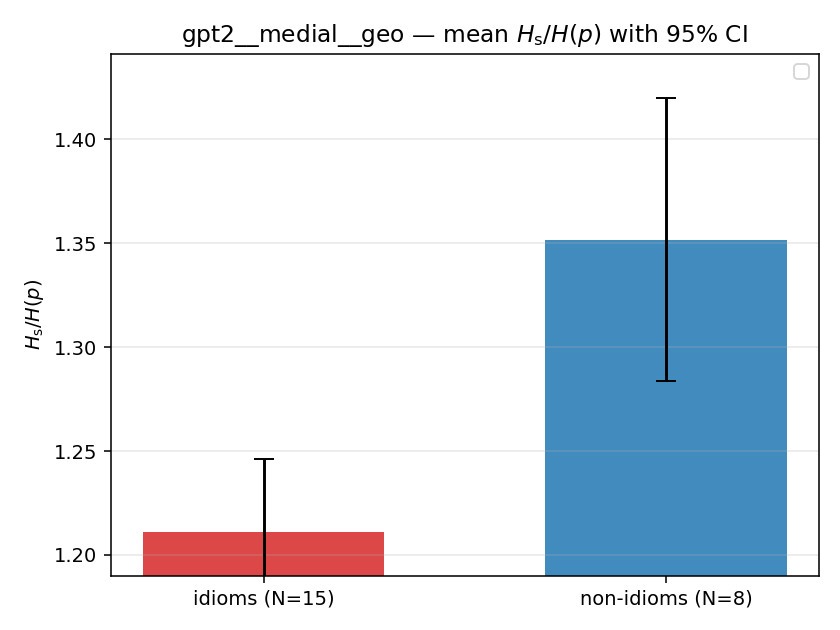 |
| per-idiom (sorted) | 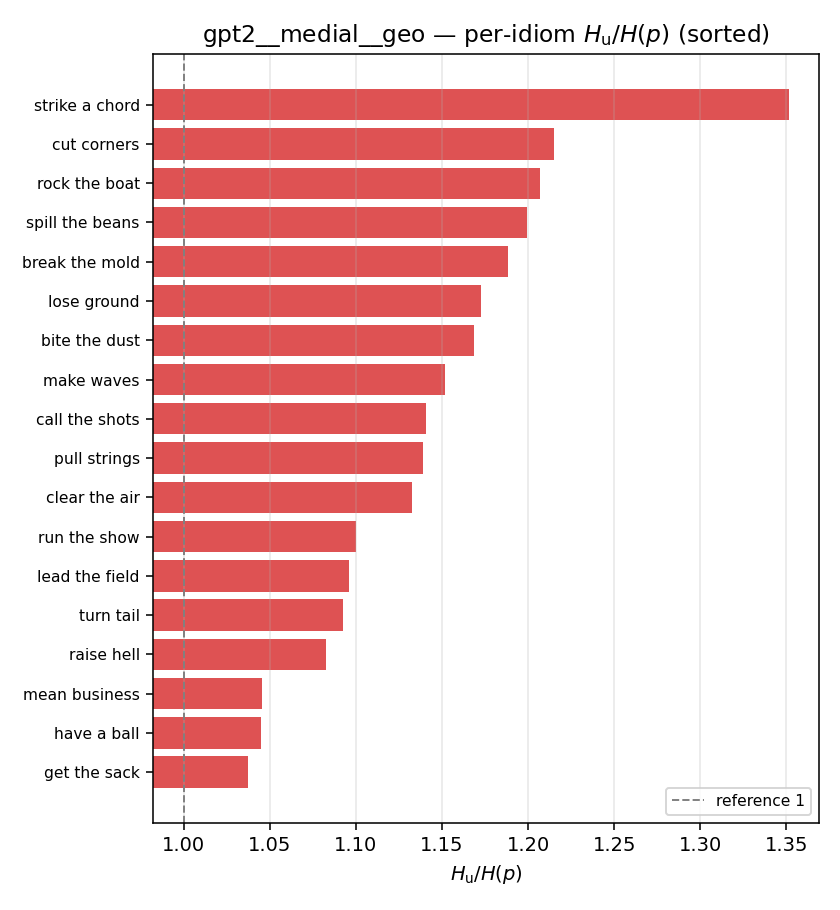 | 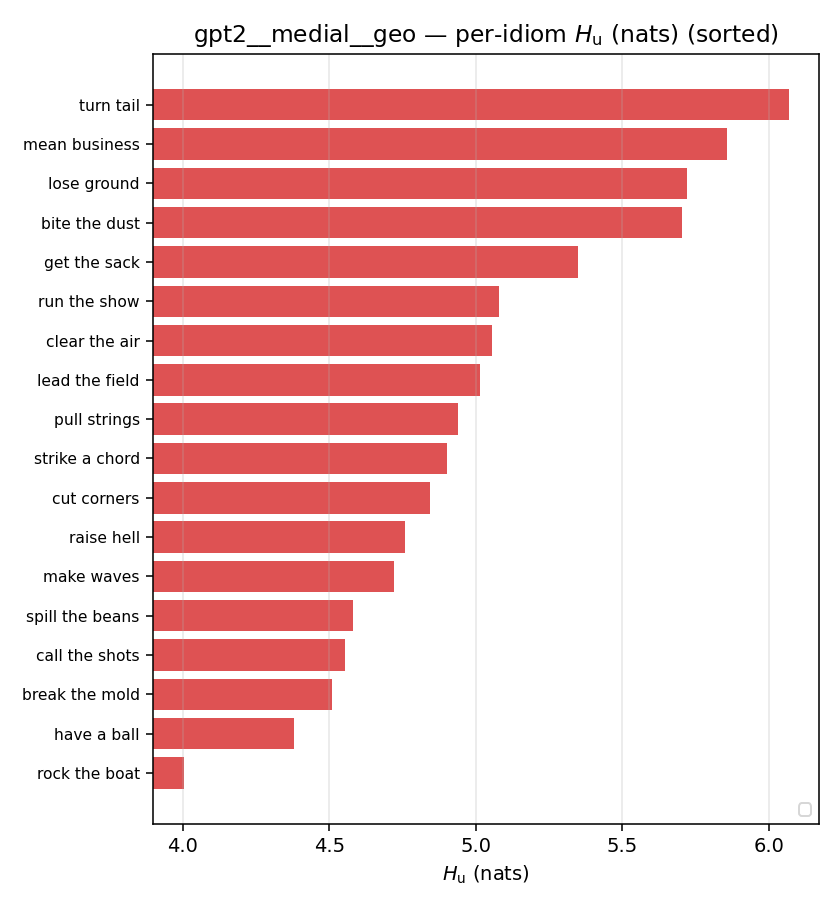 | 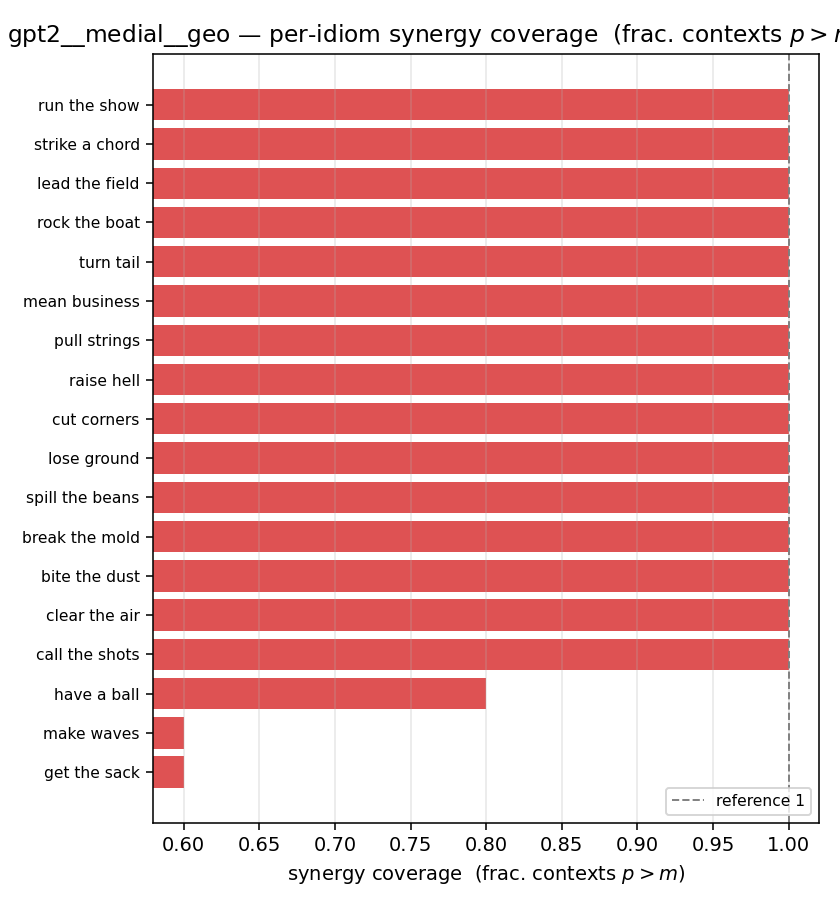 | 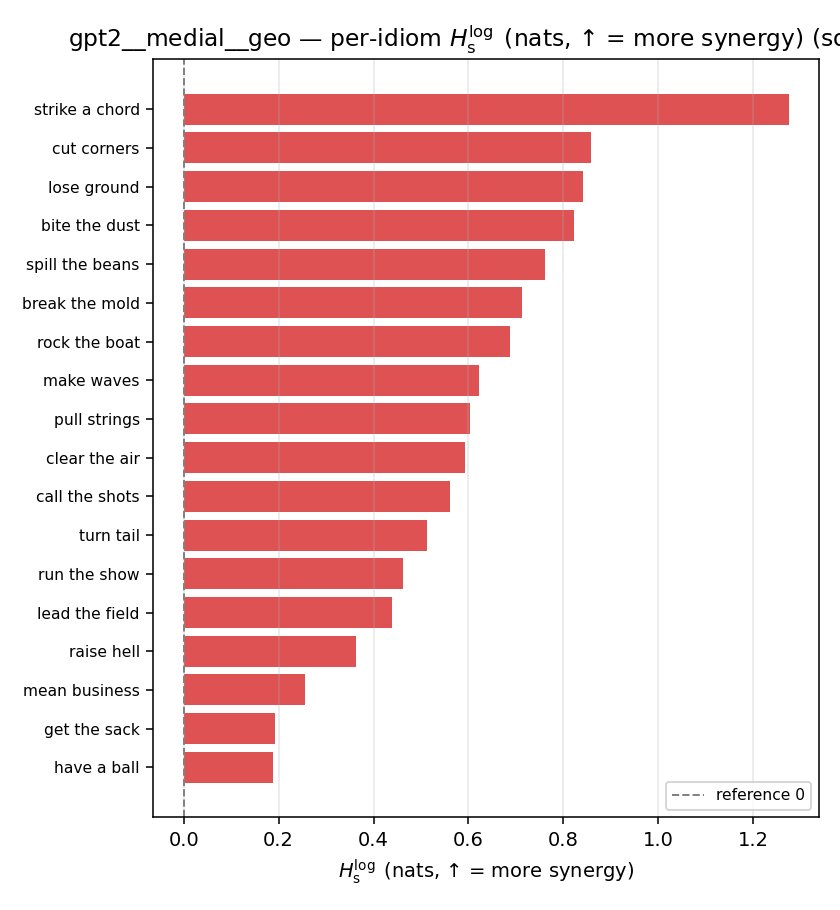 | 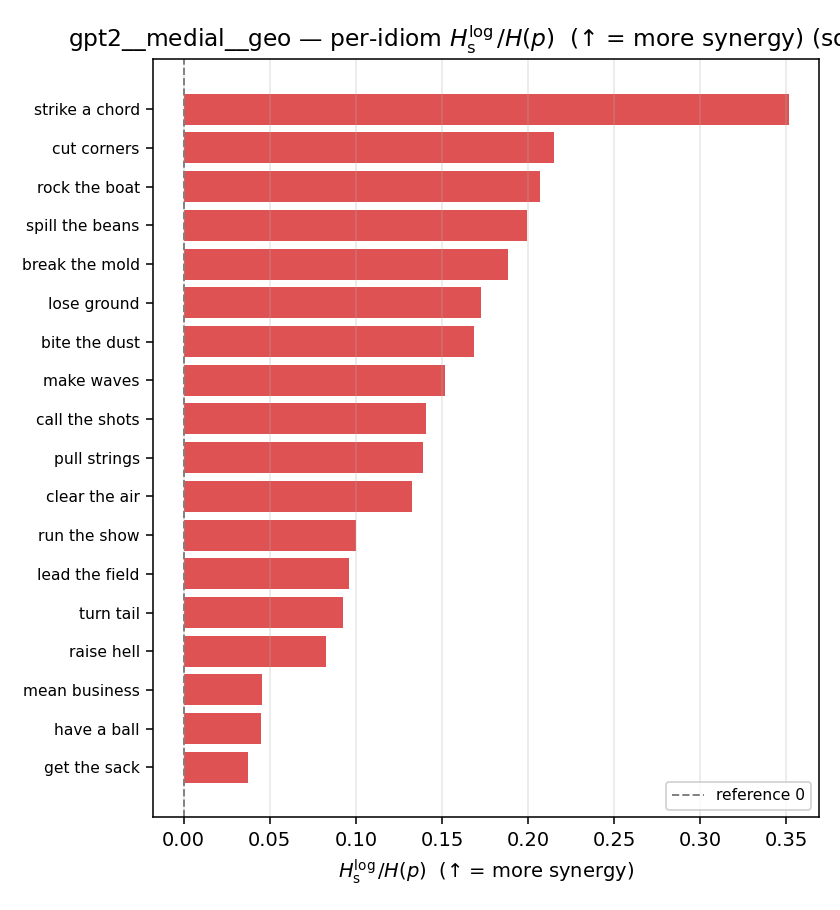 | 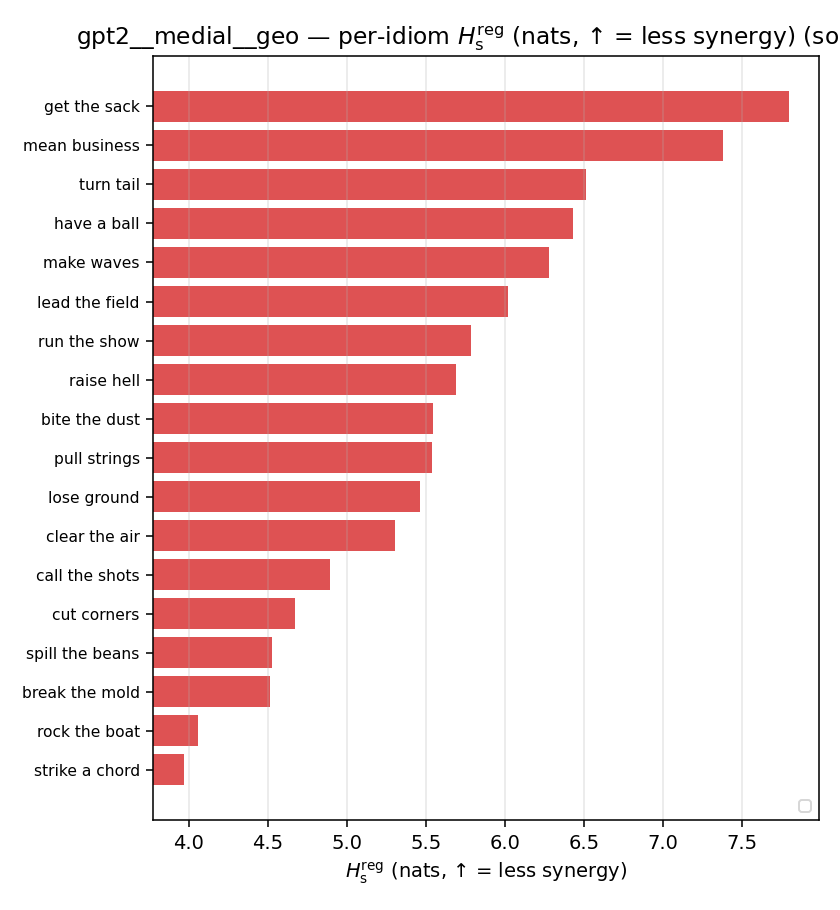 | 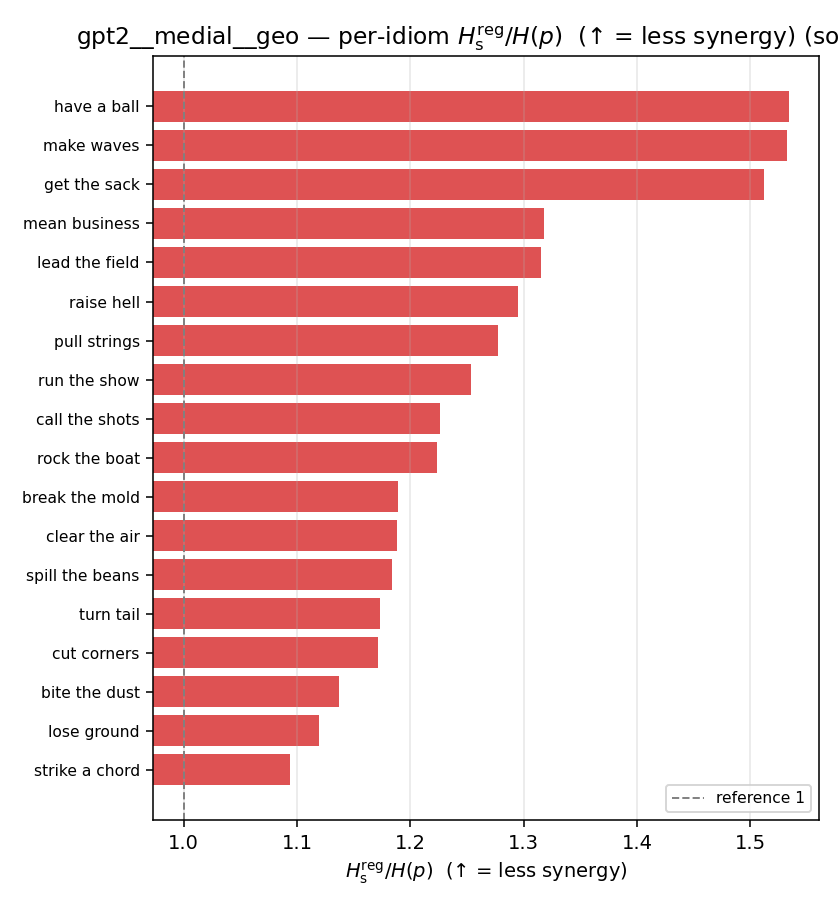 | 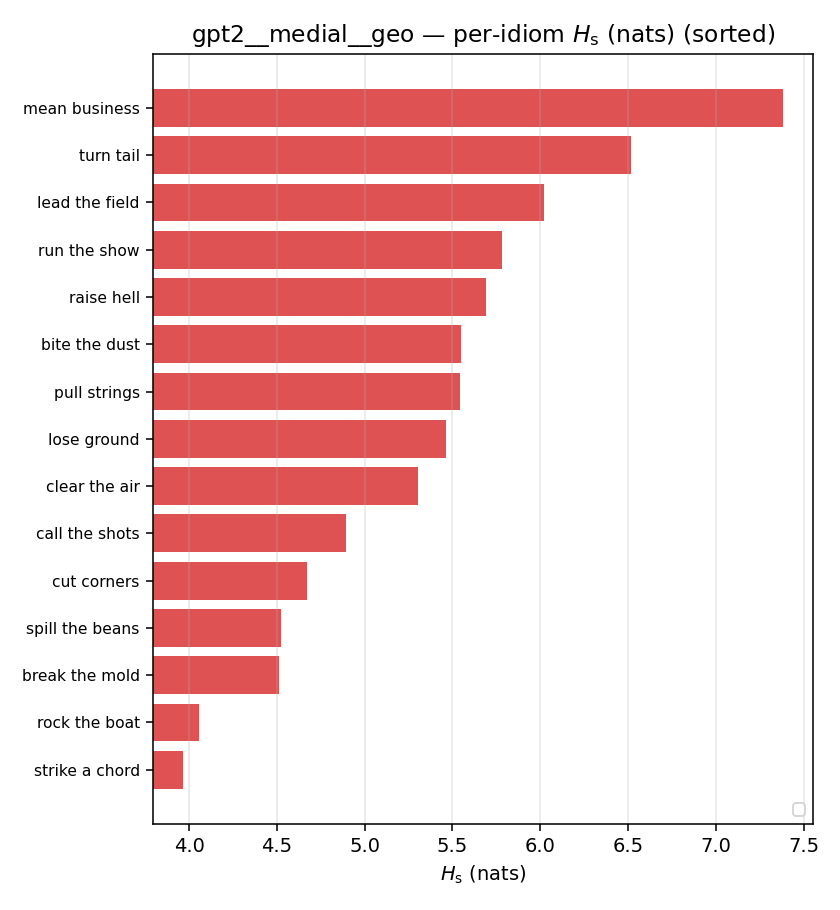 | 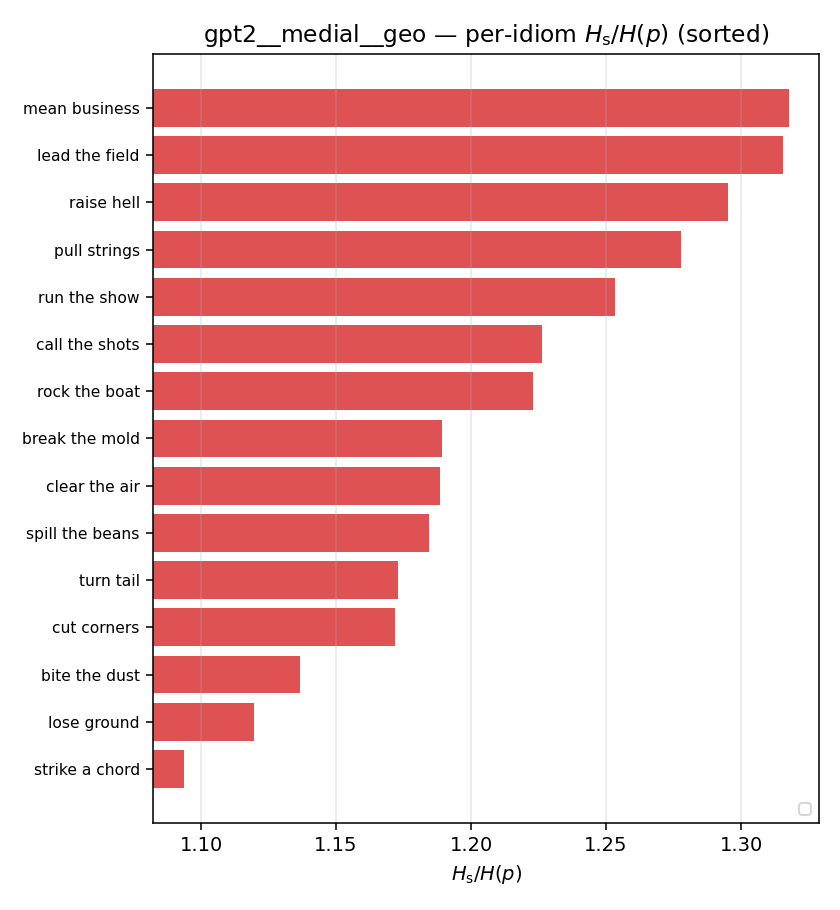 |
gpt2 · medial · joint gpt2__medial__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 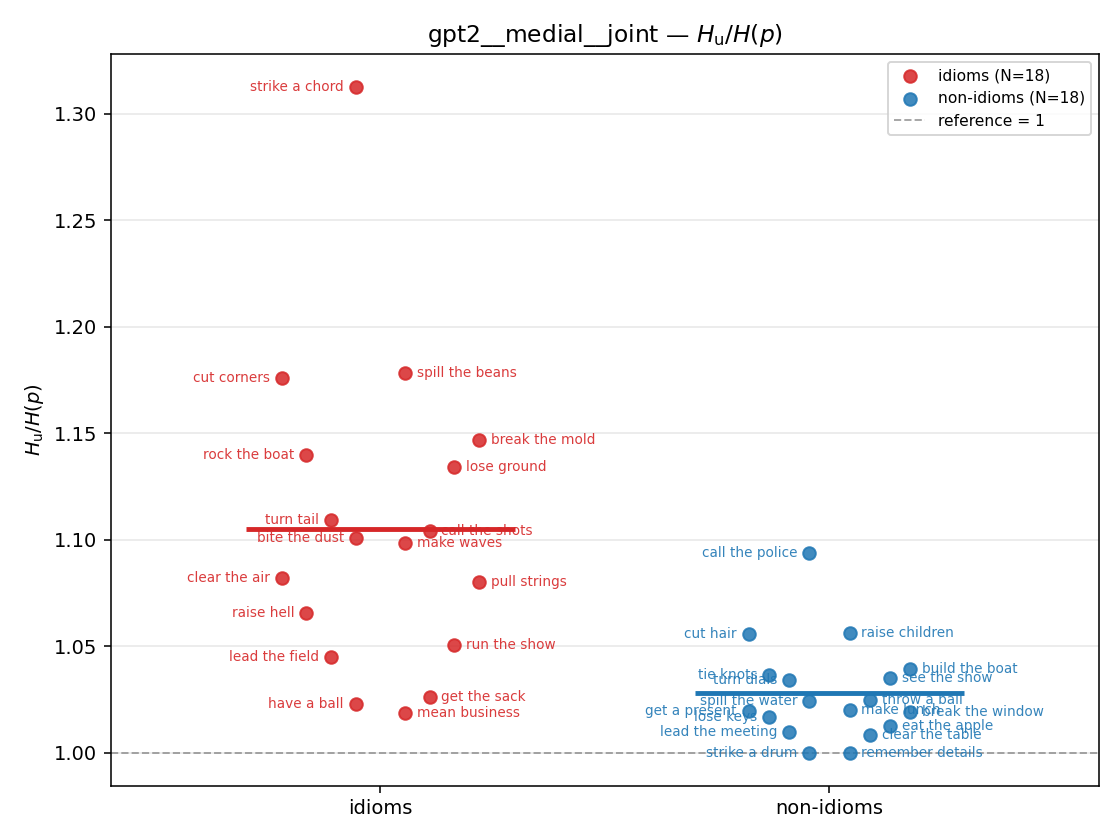 | 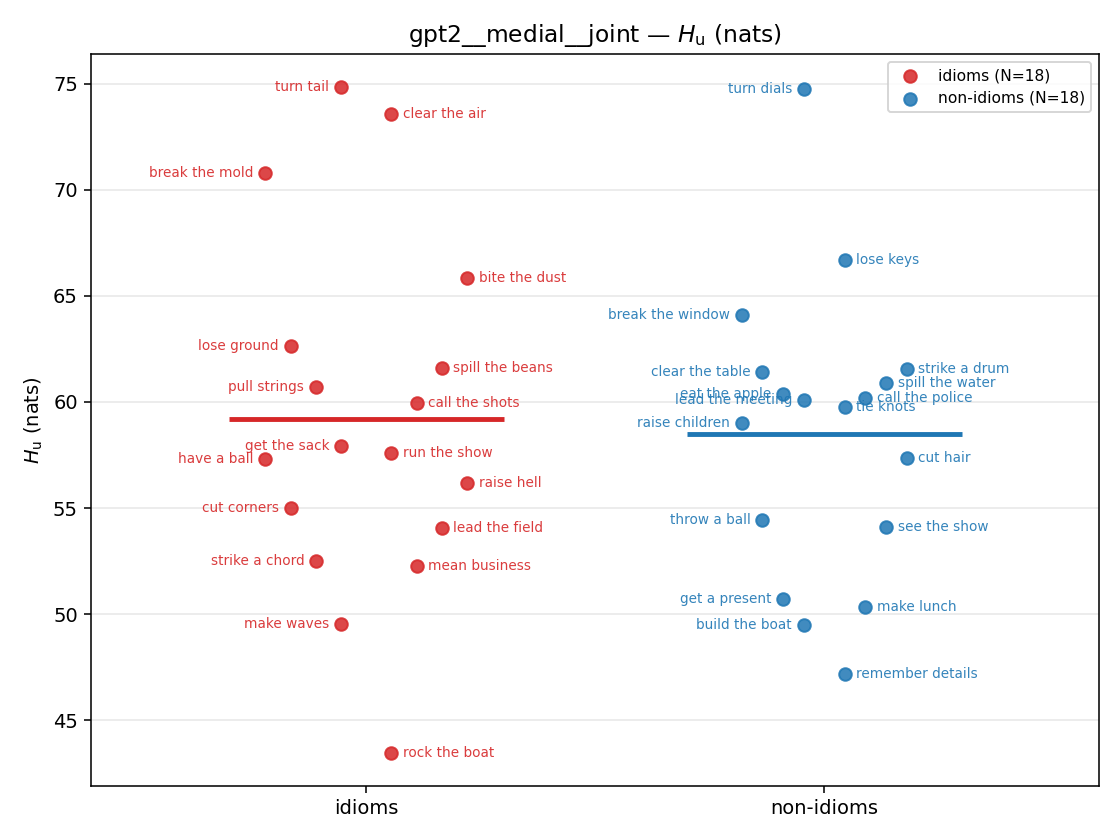 | 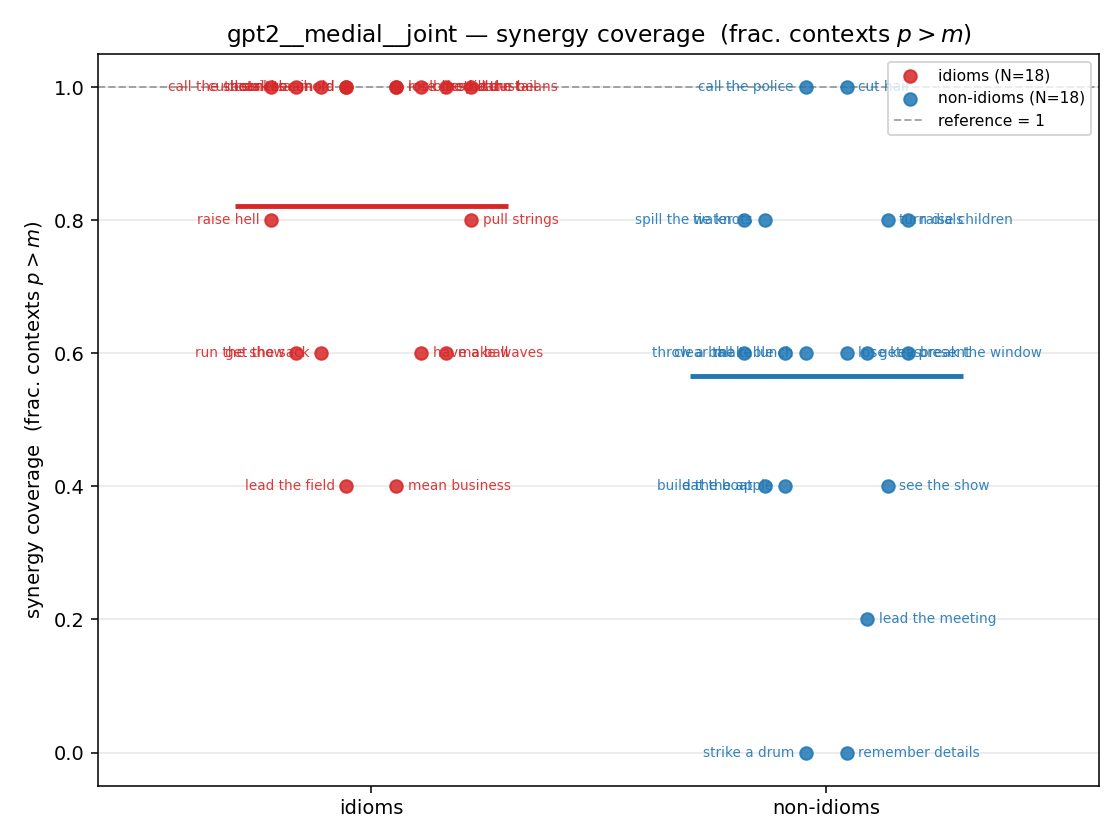 | 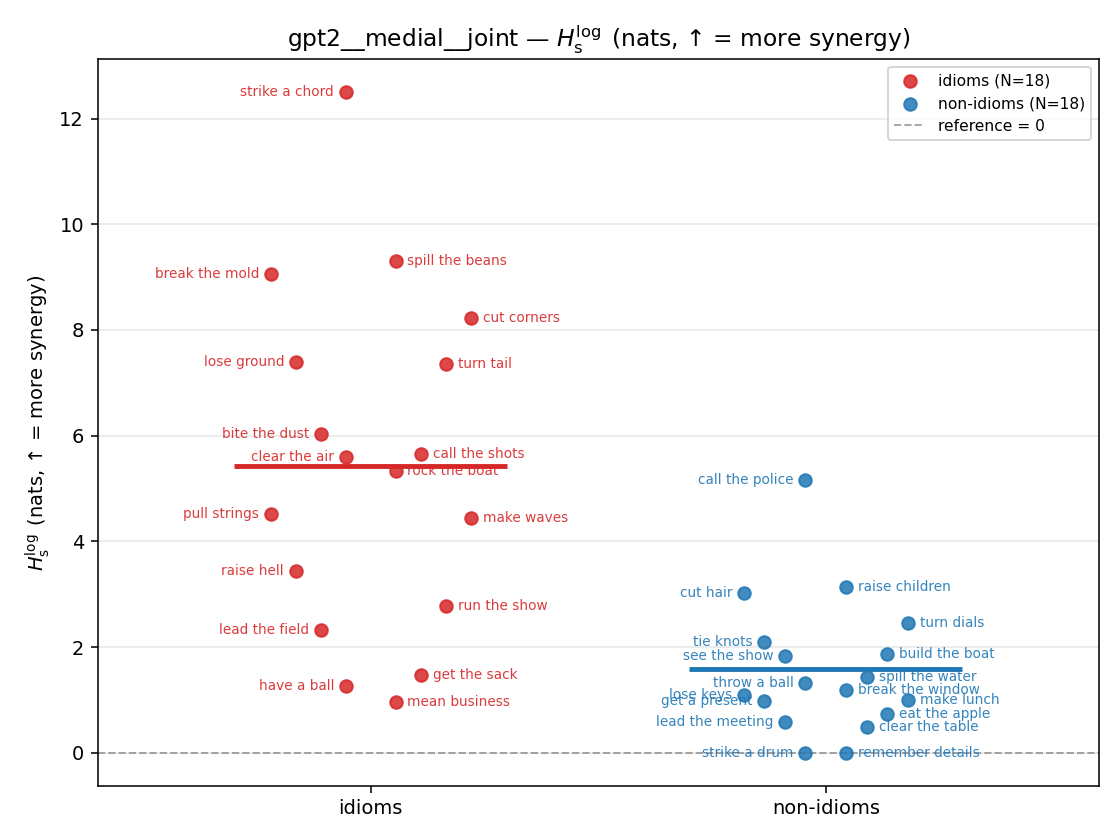 | 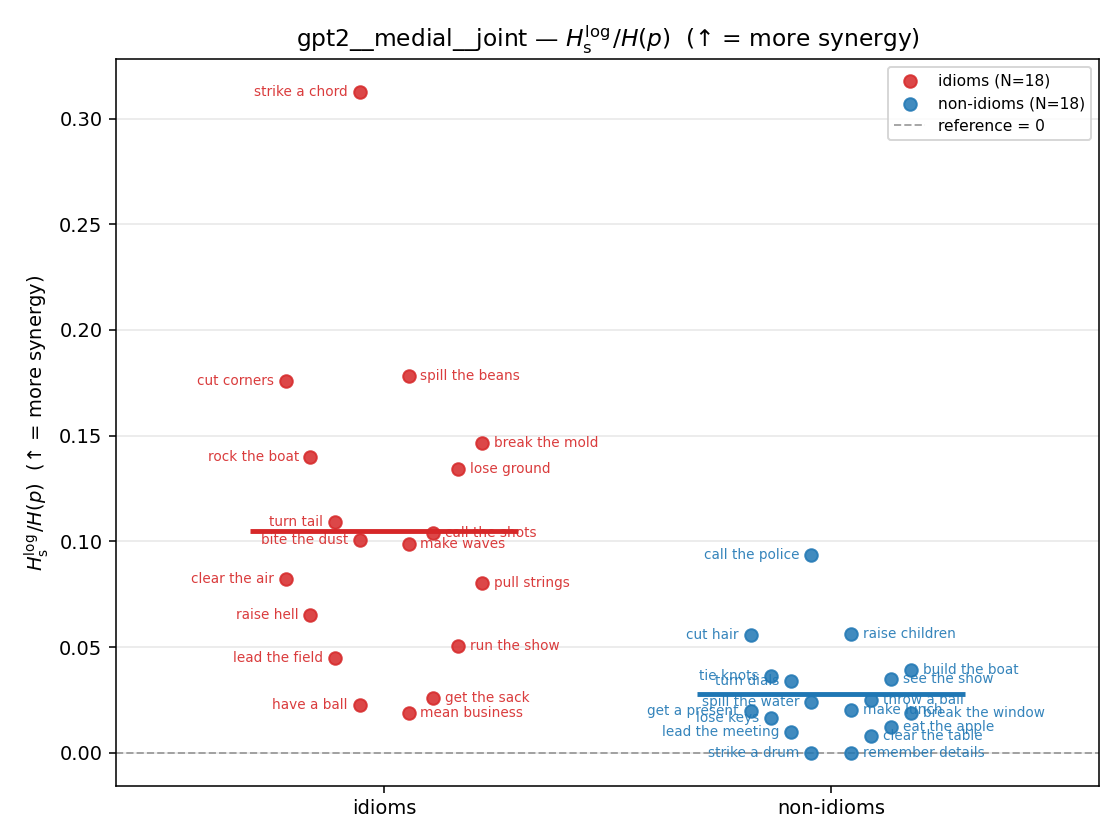 | 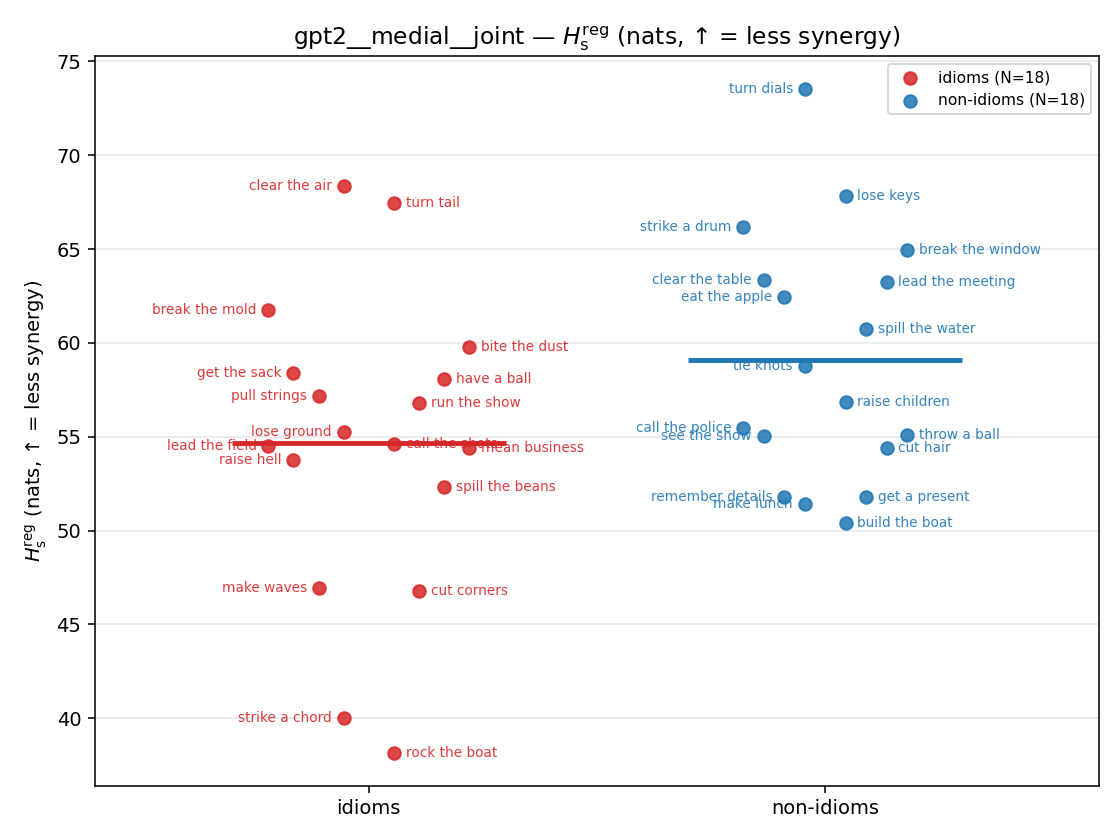 | 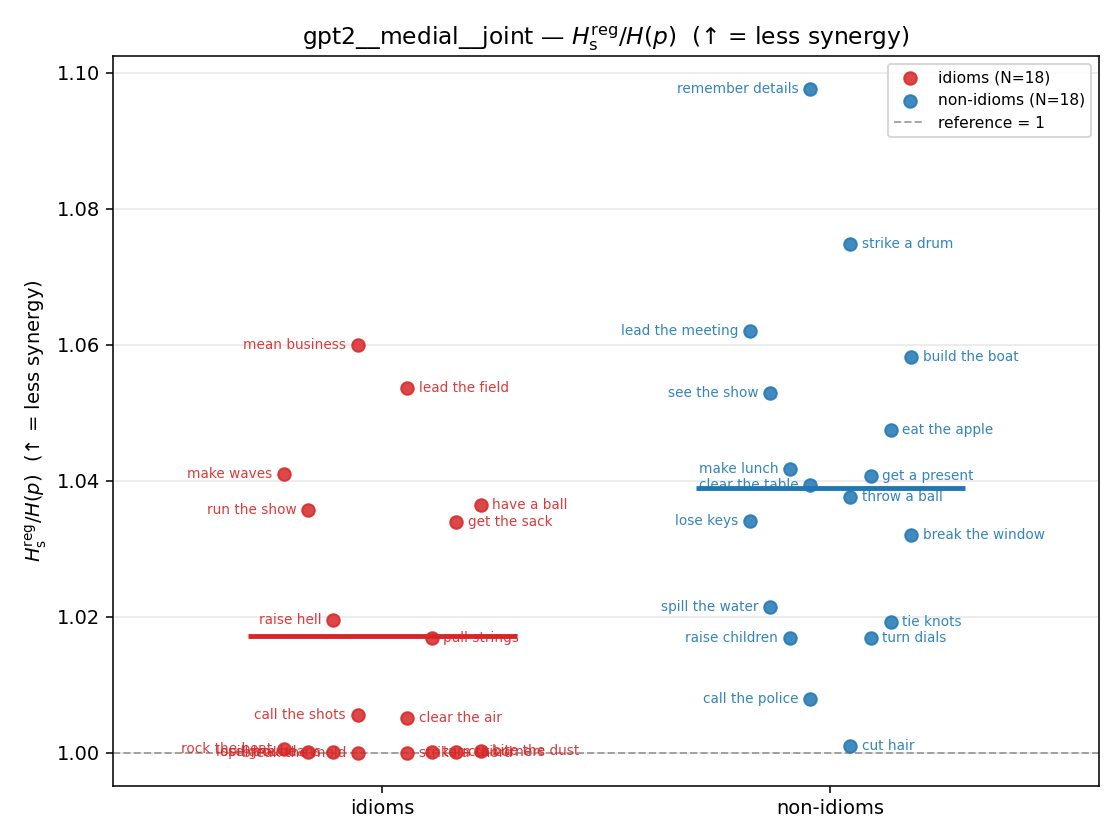 | 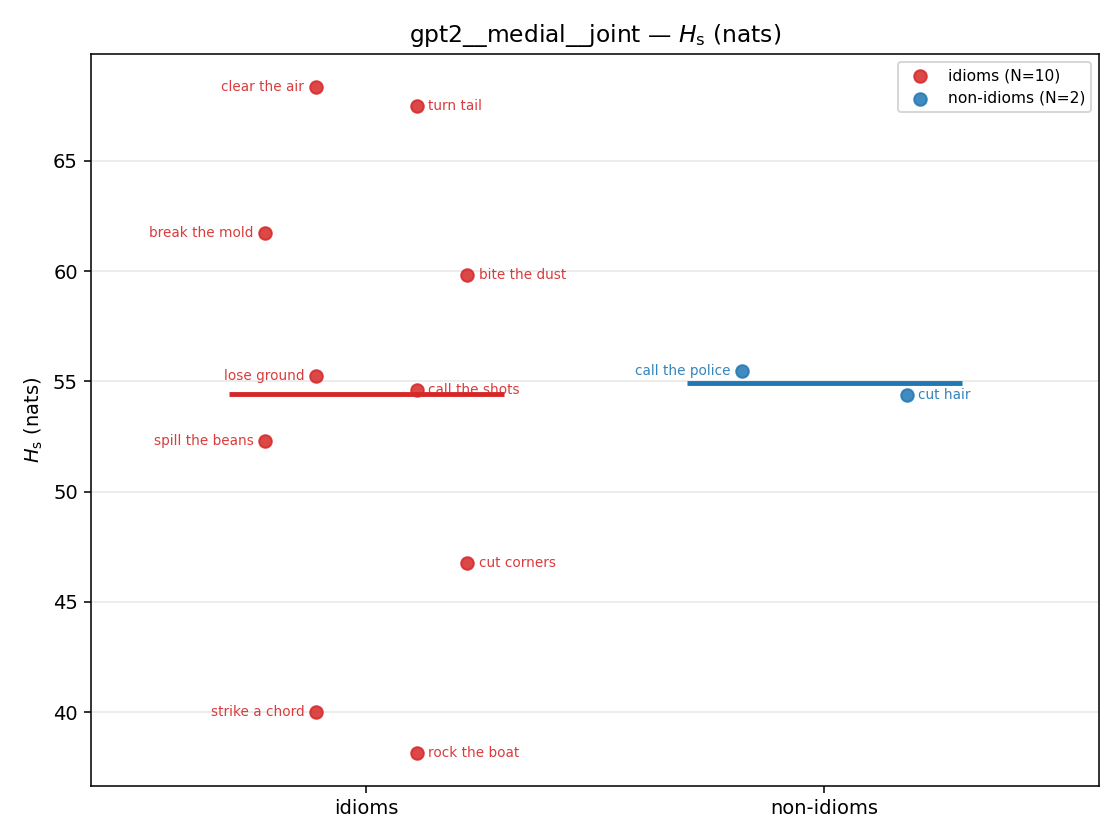 | 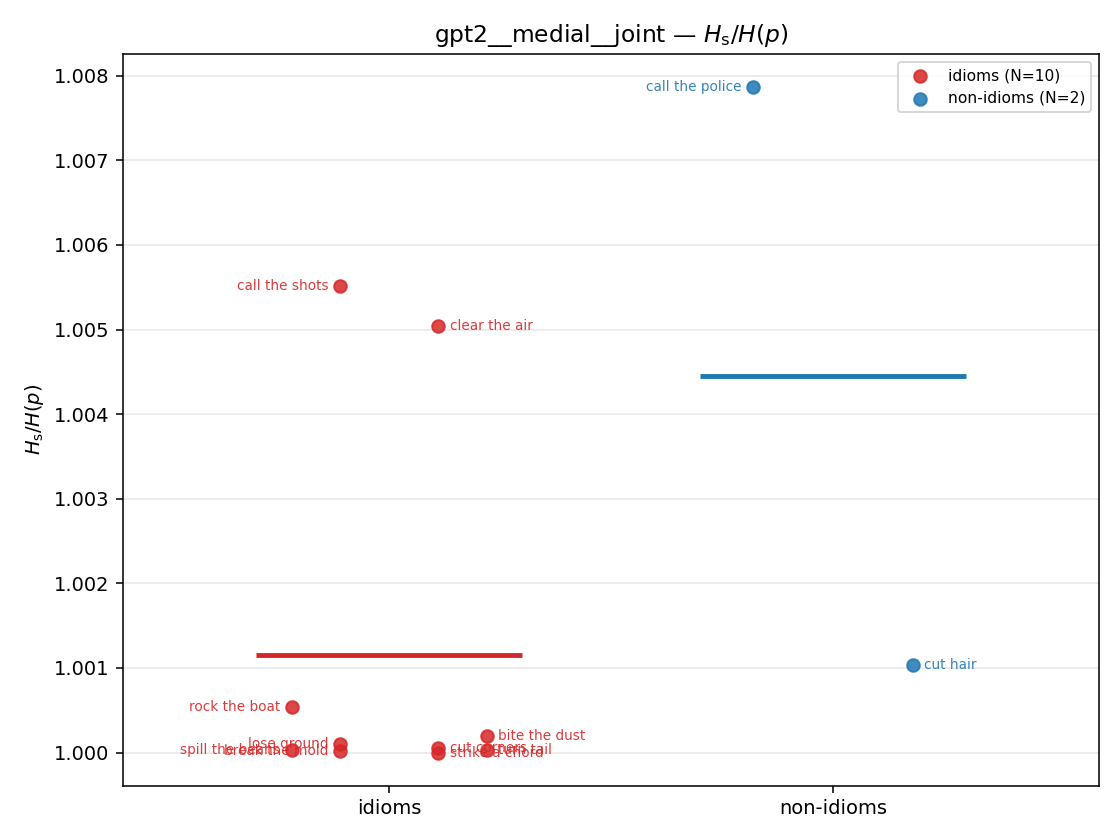 |
| mean ± 95% CI | 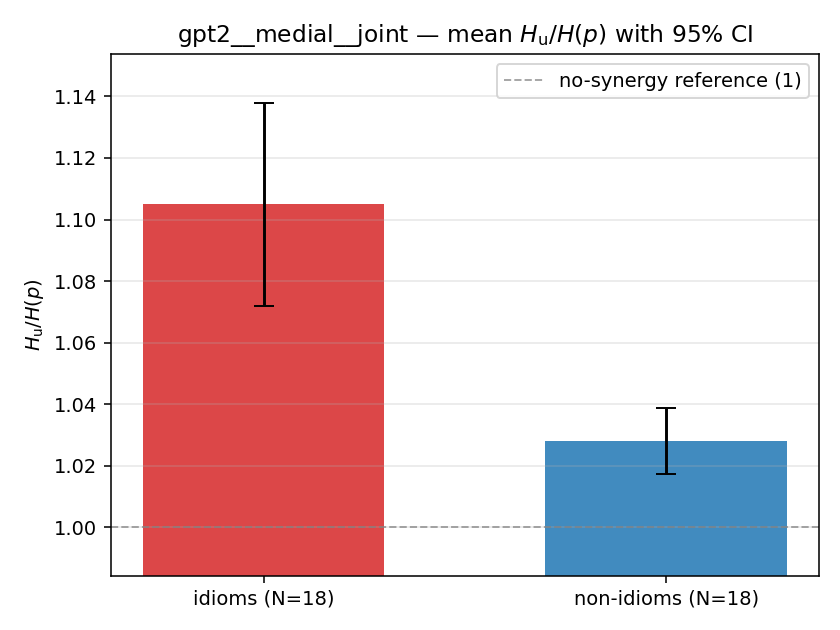 | 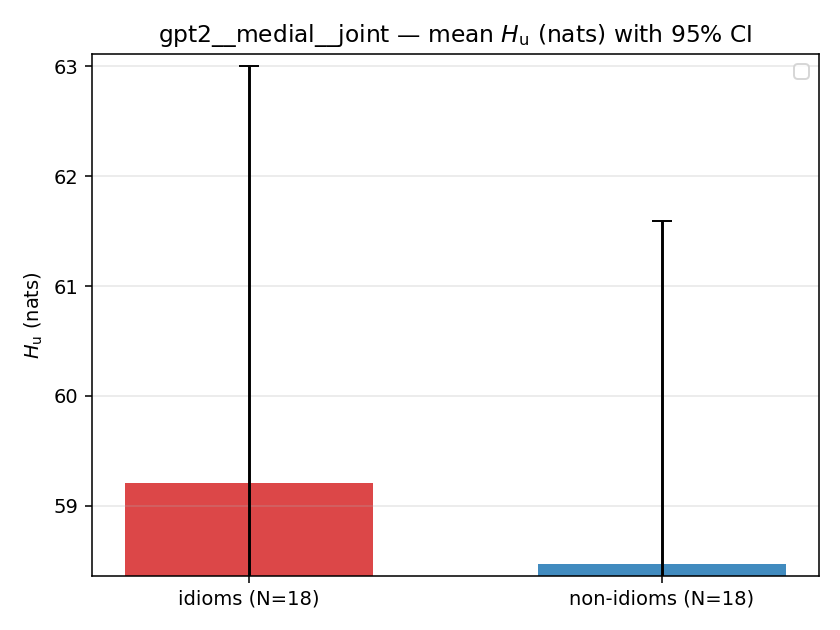 | 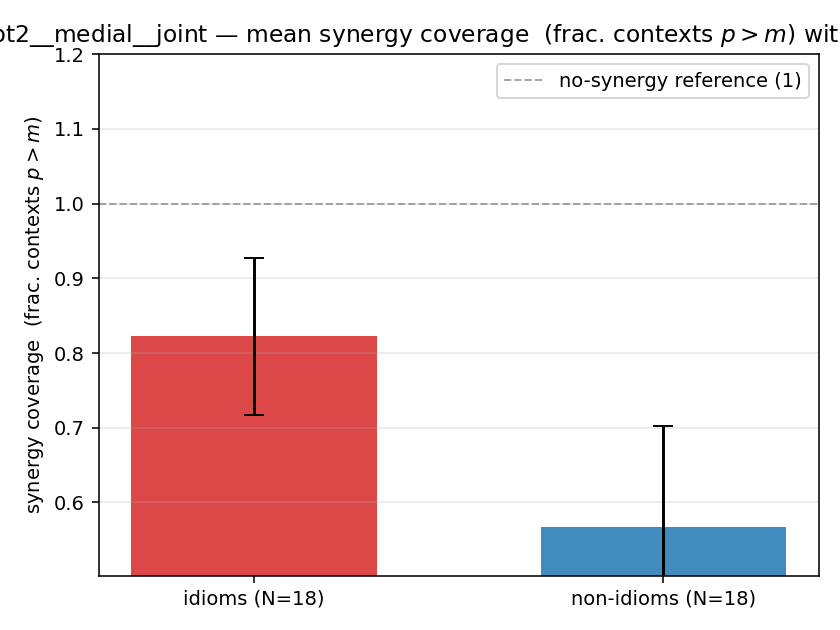 | 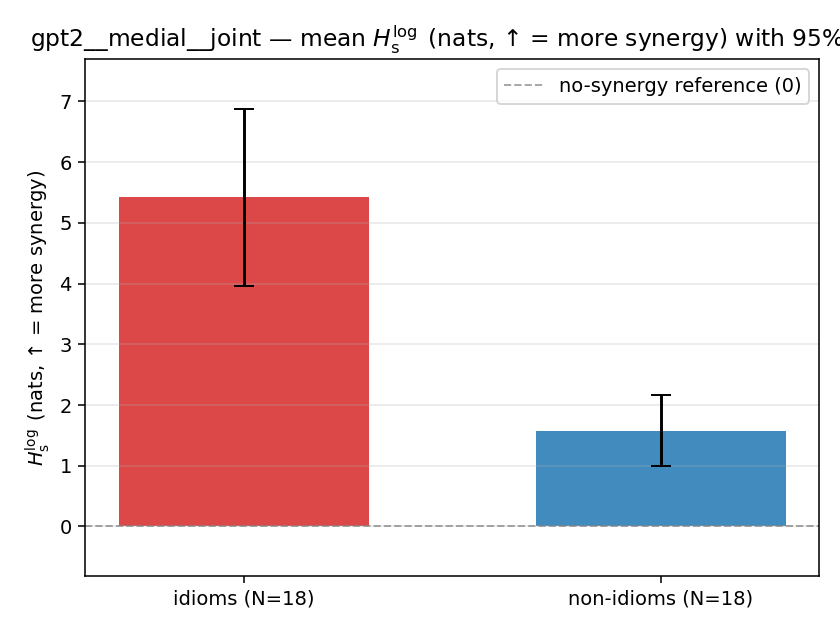 | 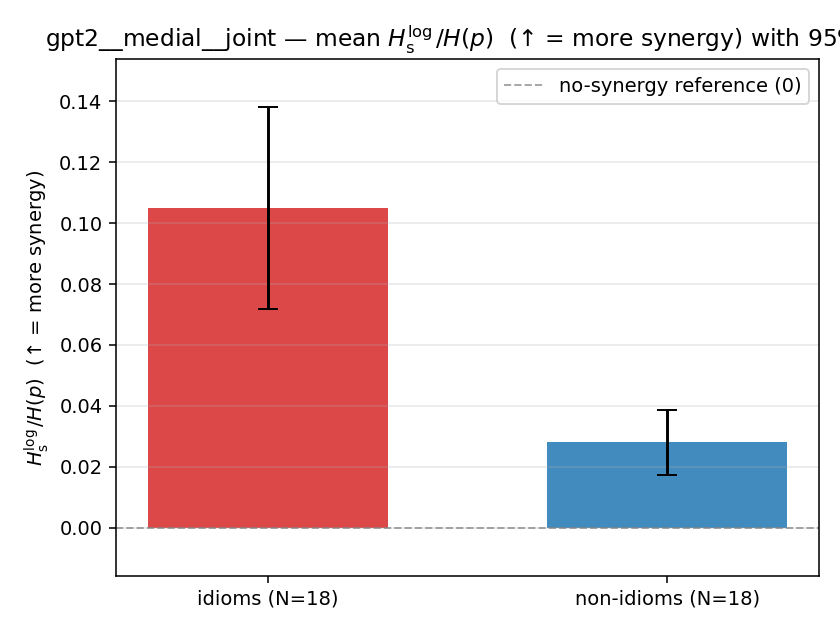 | 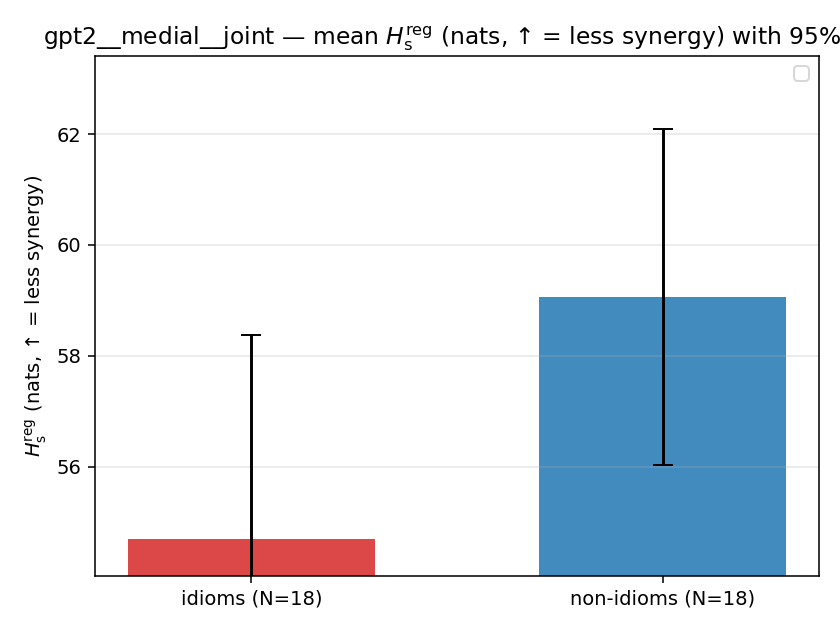 | 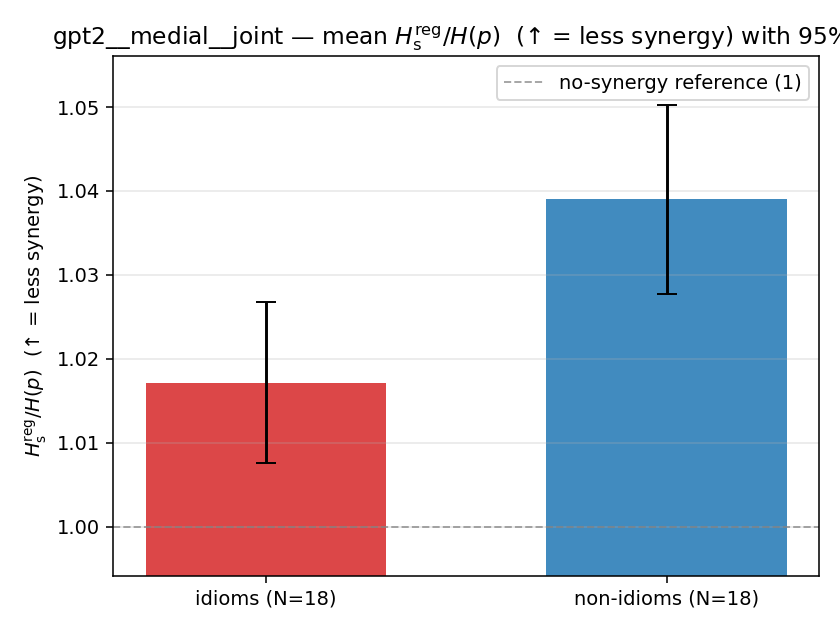 | 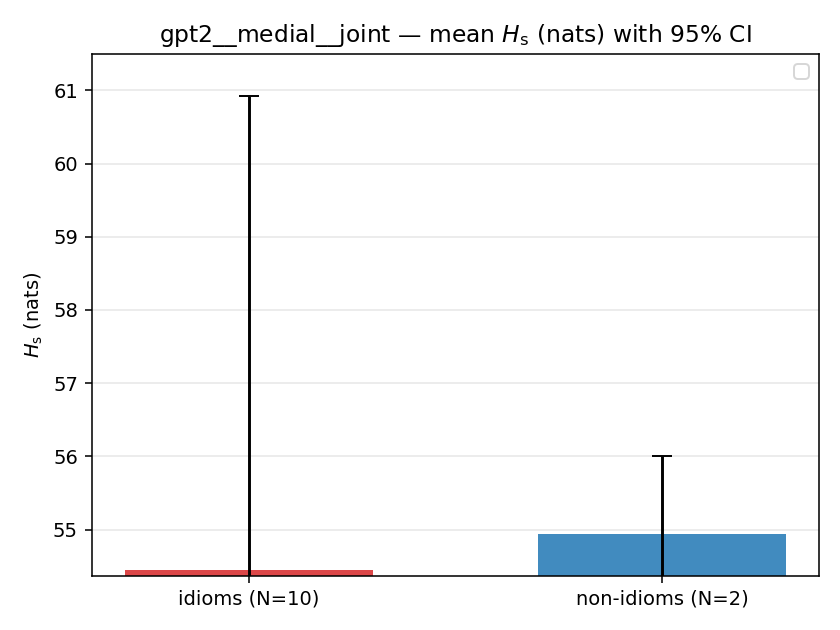 | 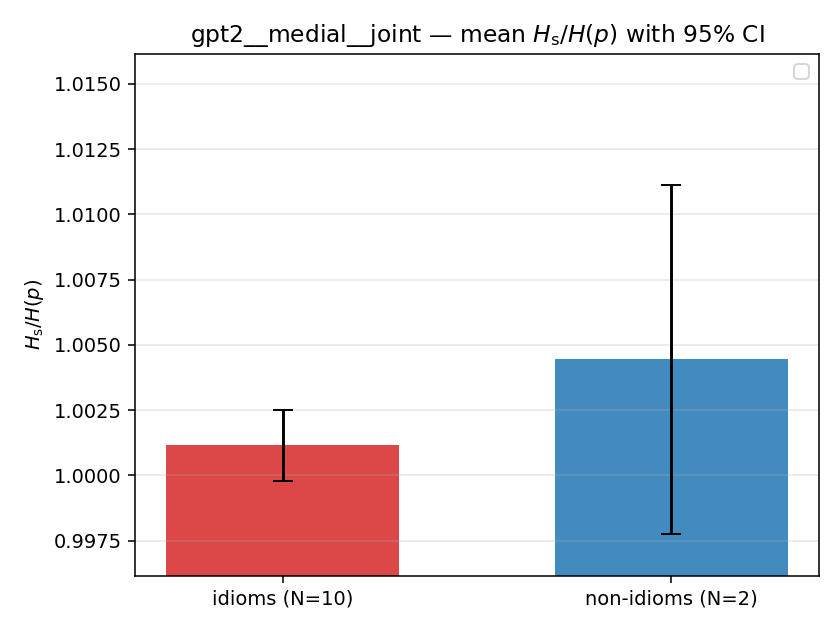 |
| per-idiom (sorted) | 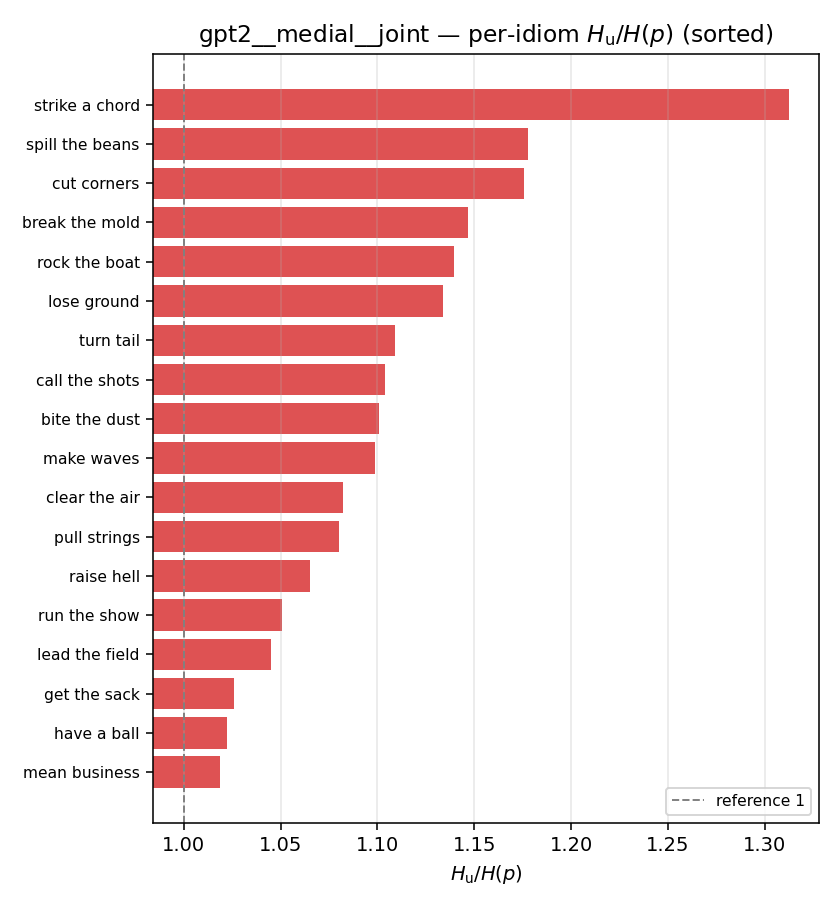 | 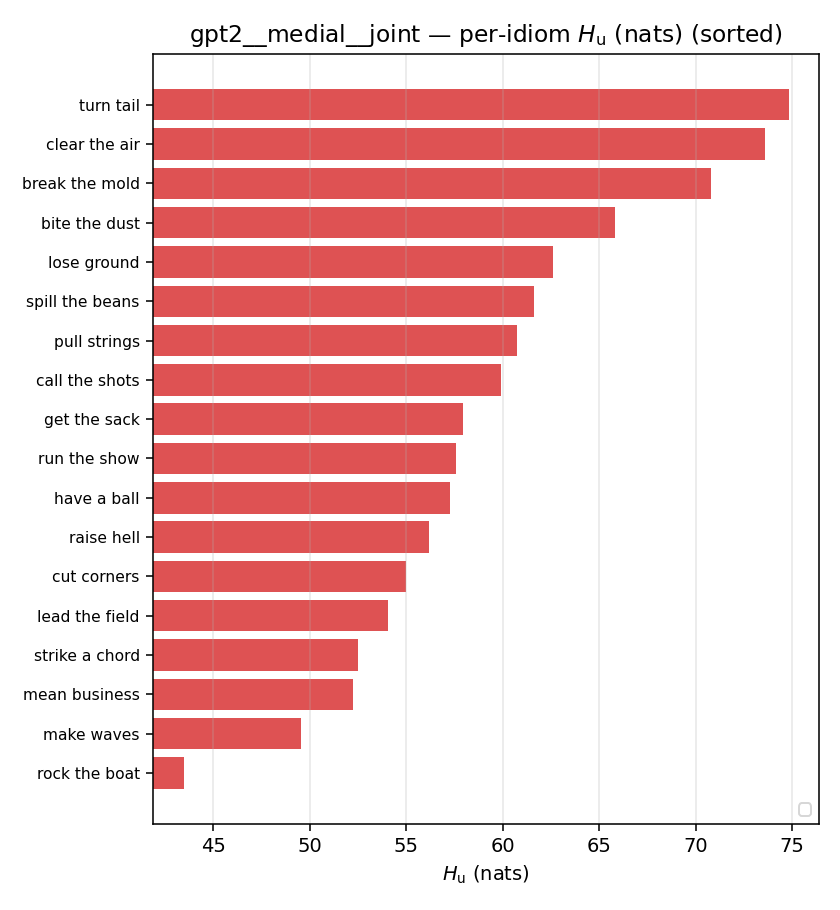 | 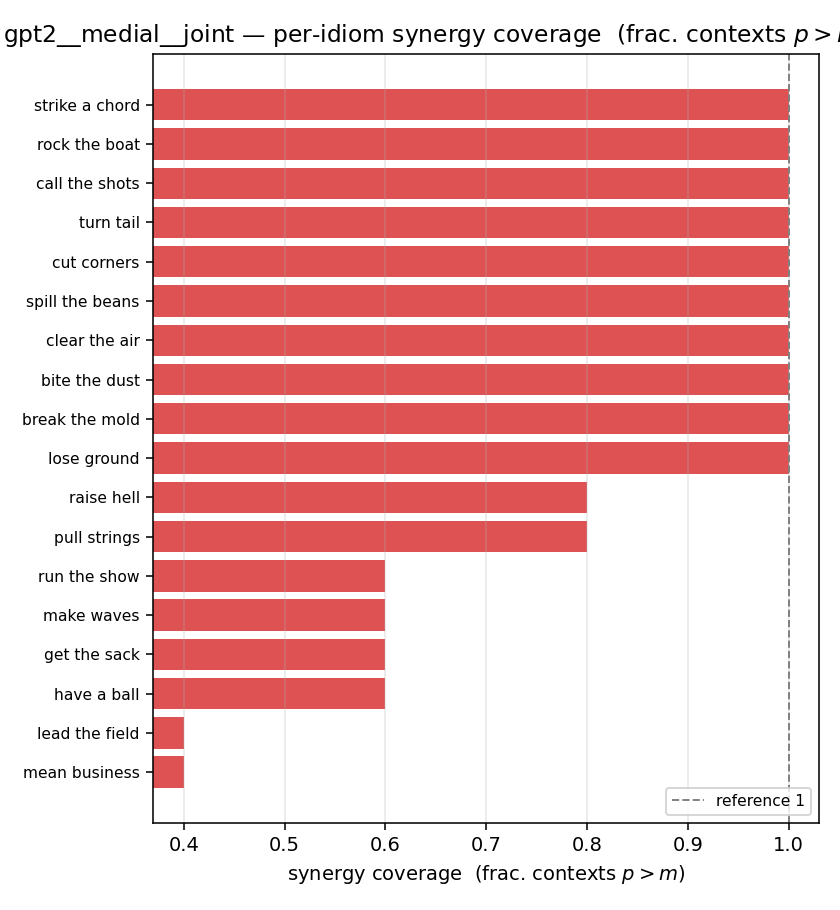 | 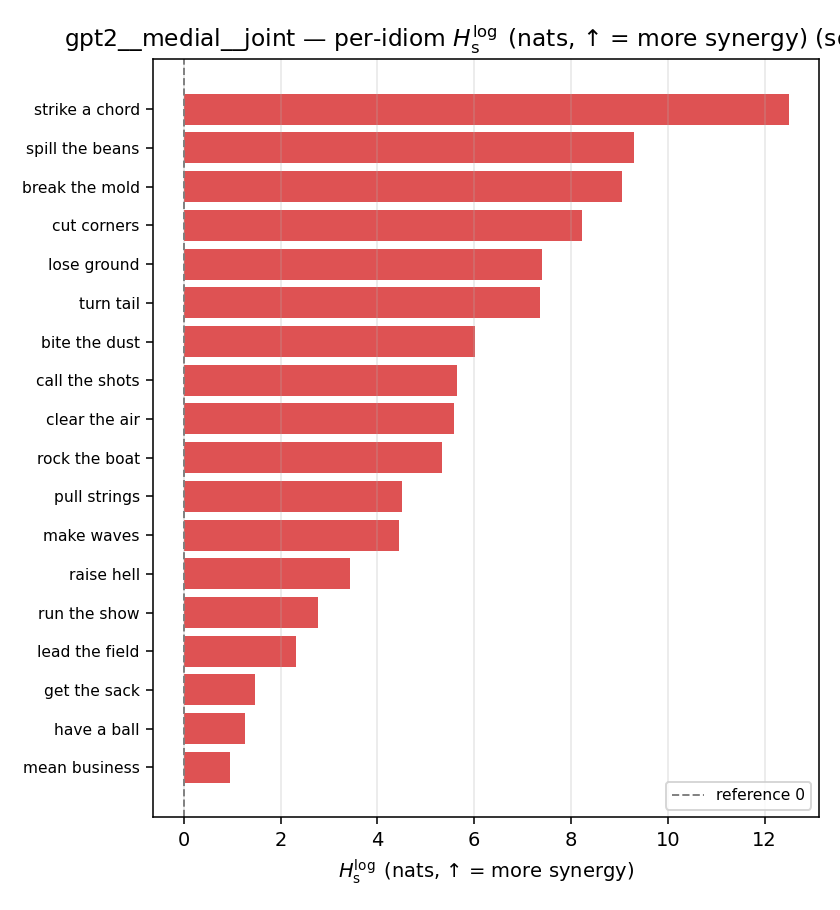 | 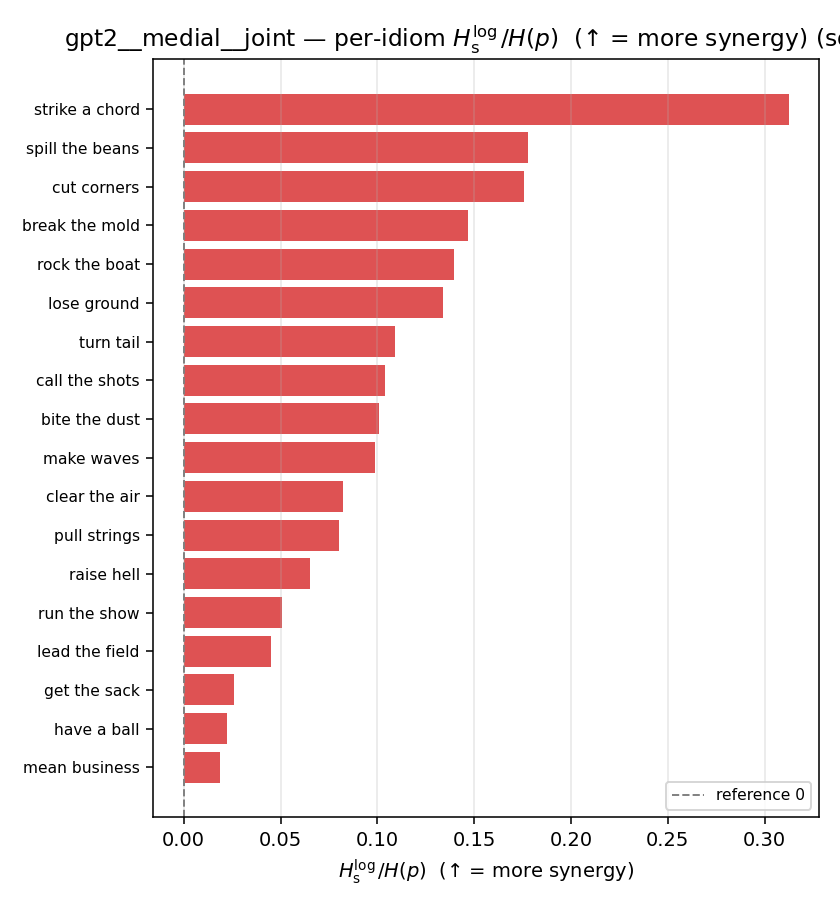 | 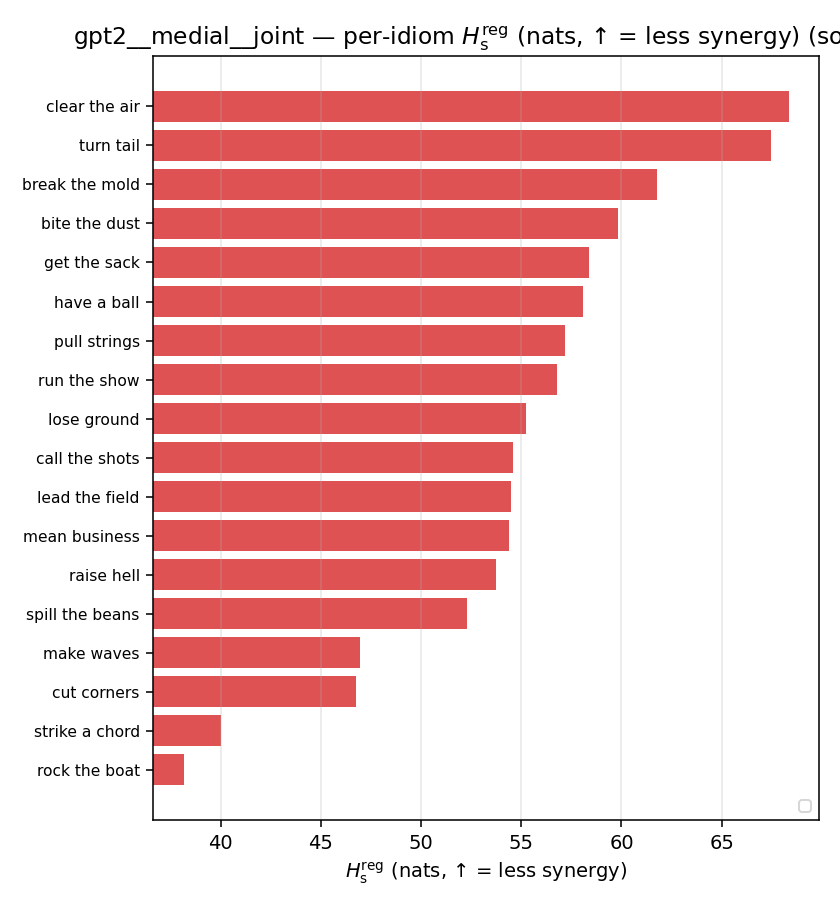 | 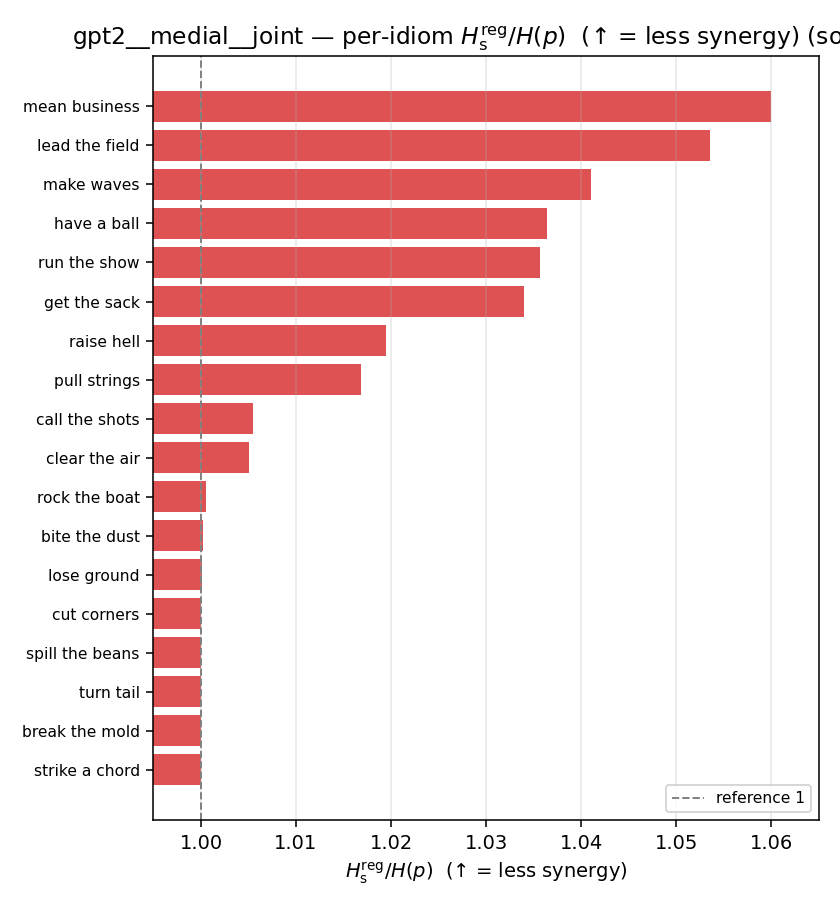 |  |  |
gpt2 · full · geo gpt2__full__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 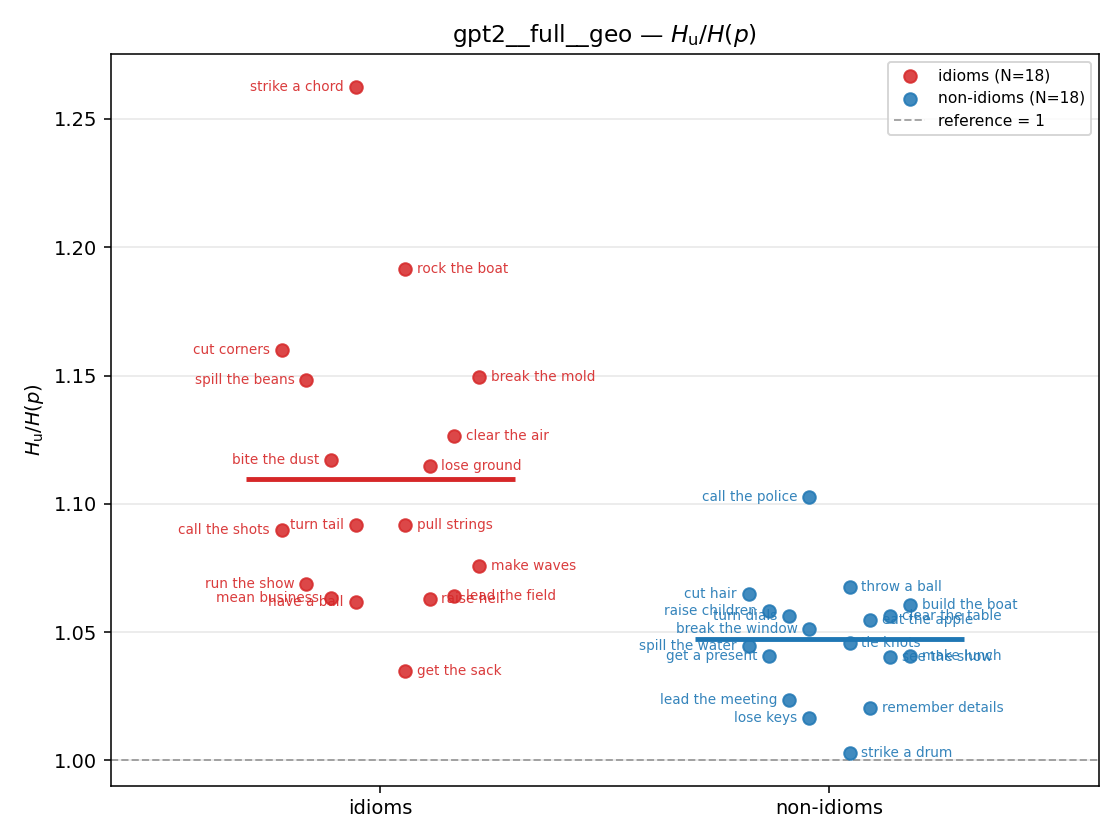 | 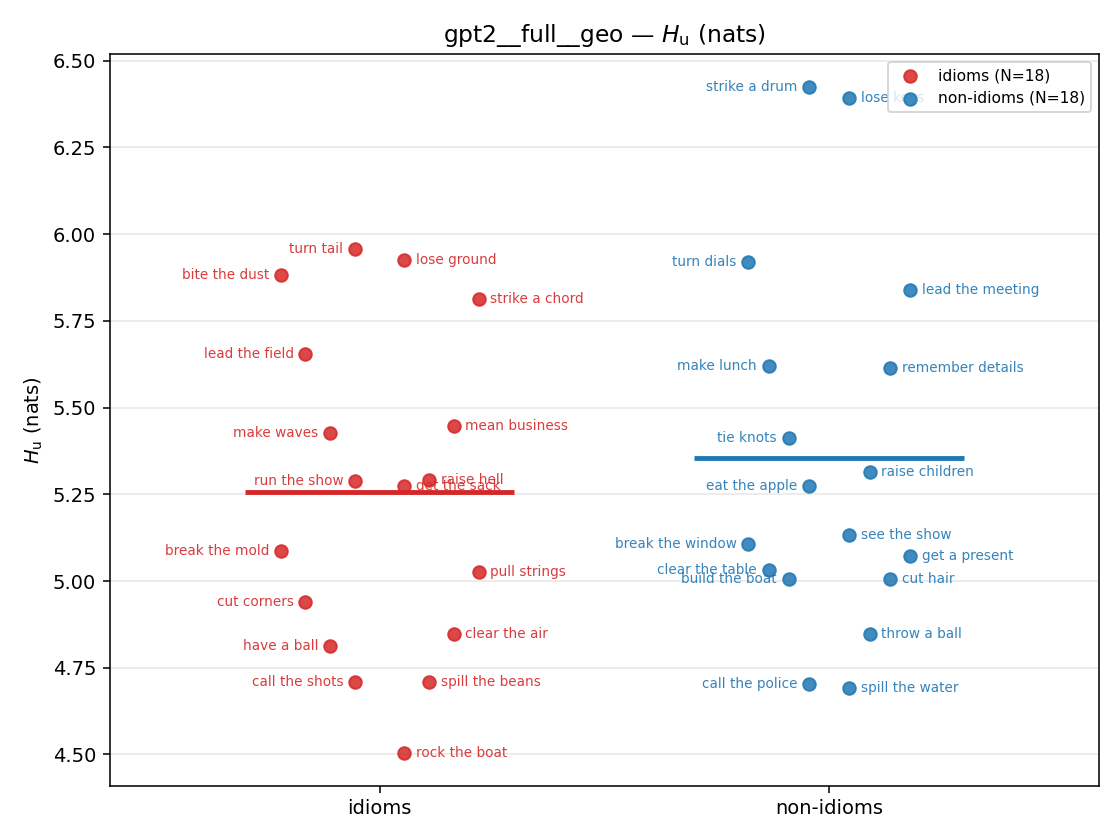 | 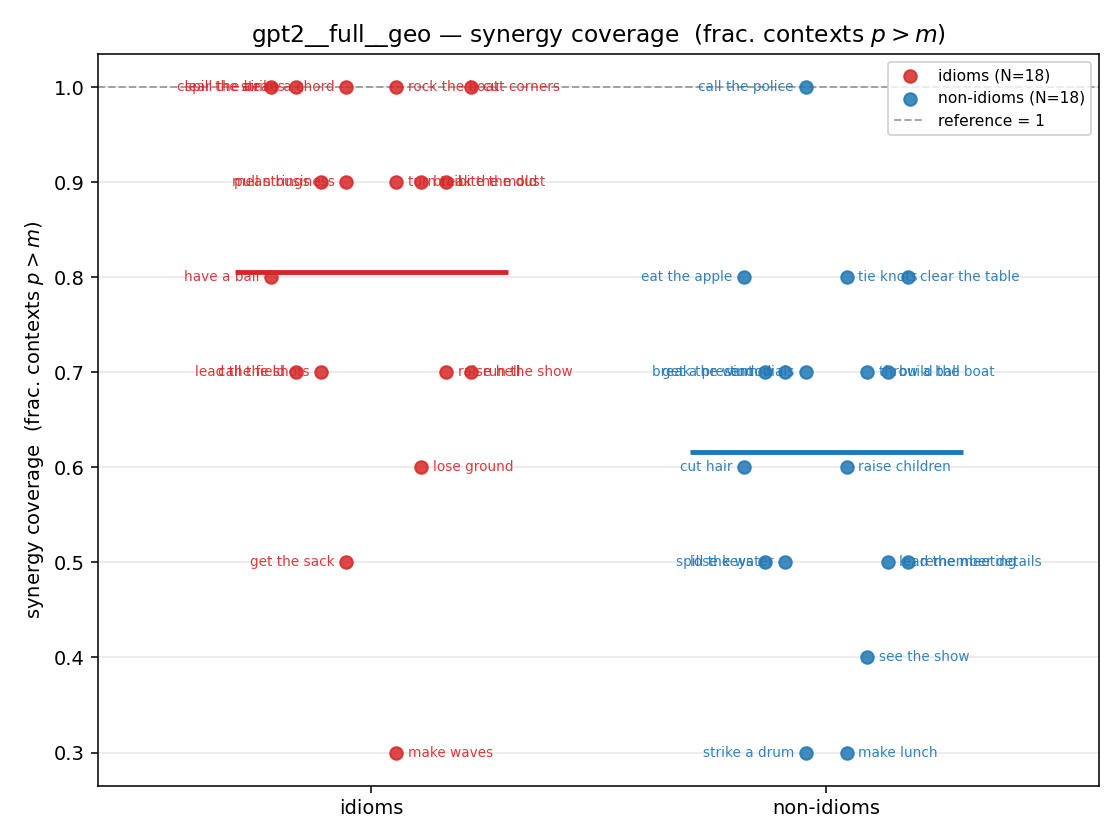 | 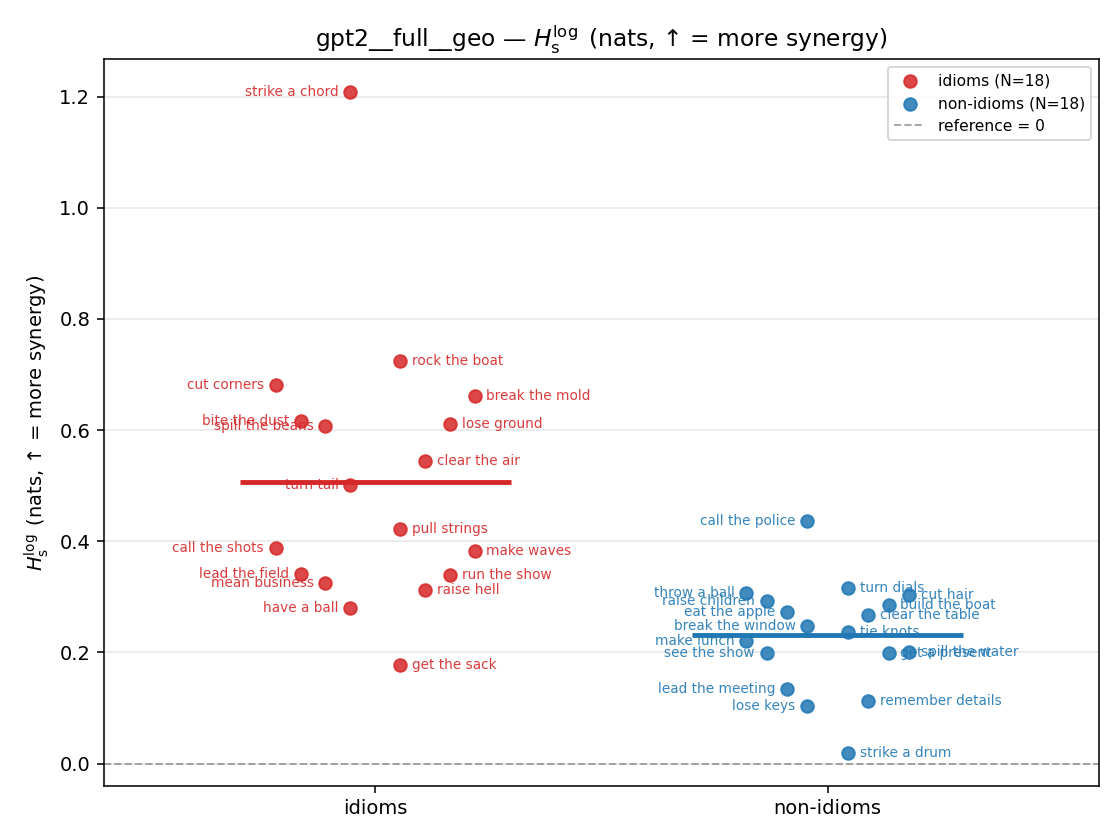 | 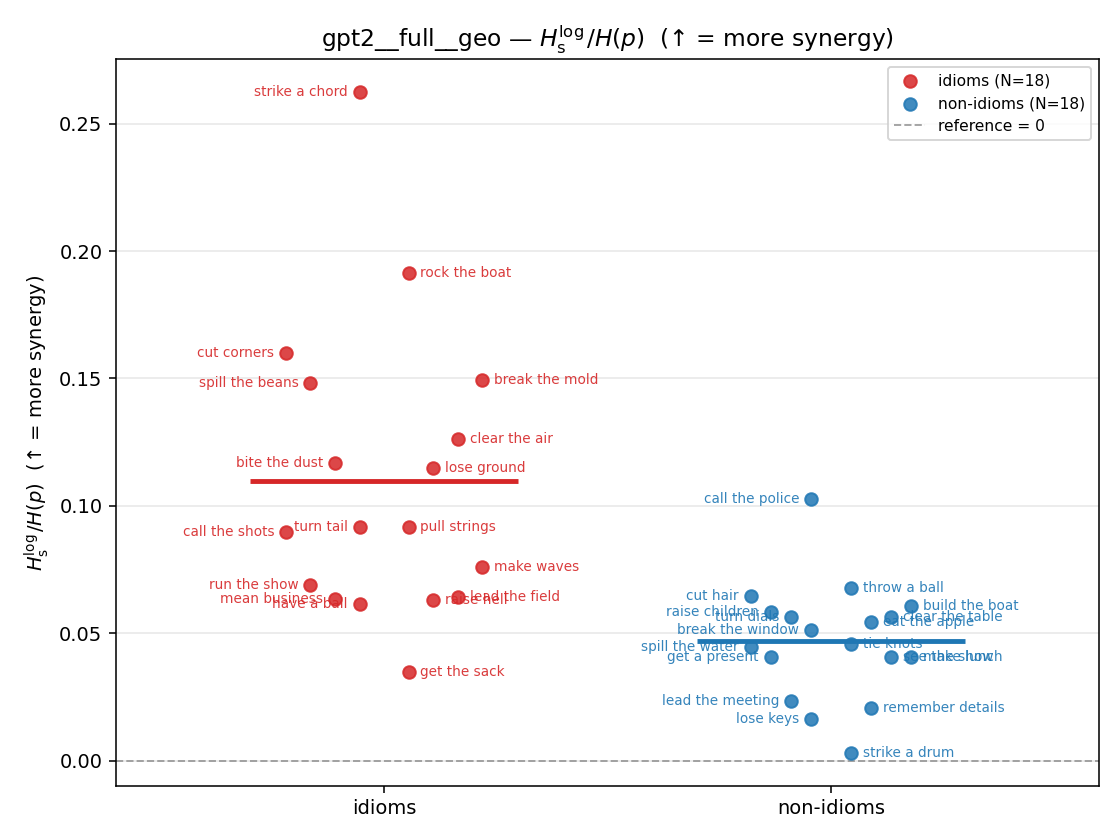 | 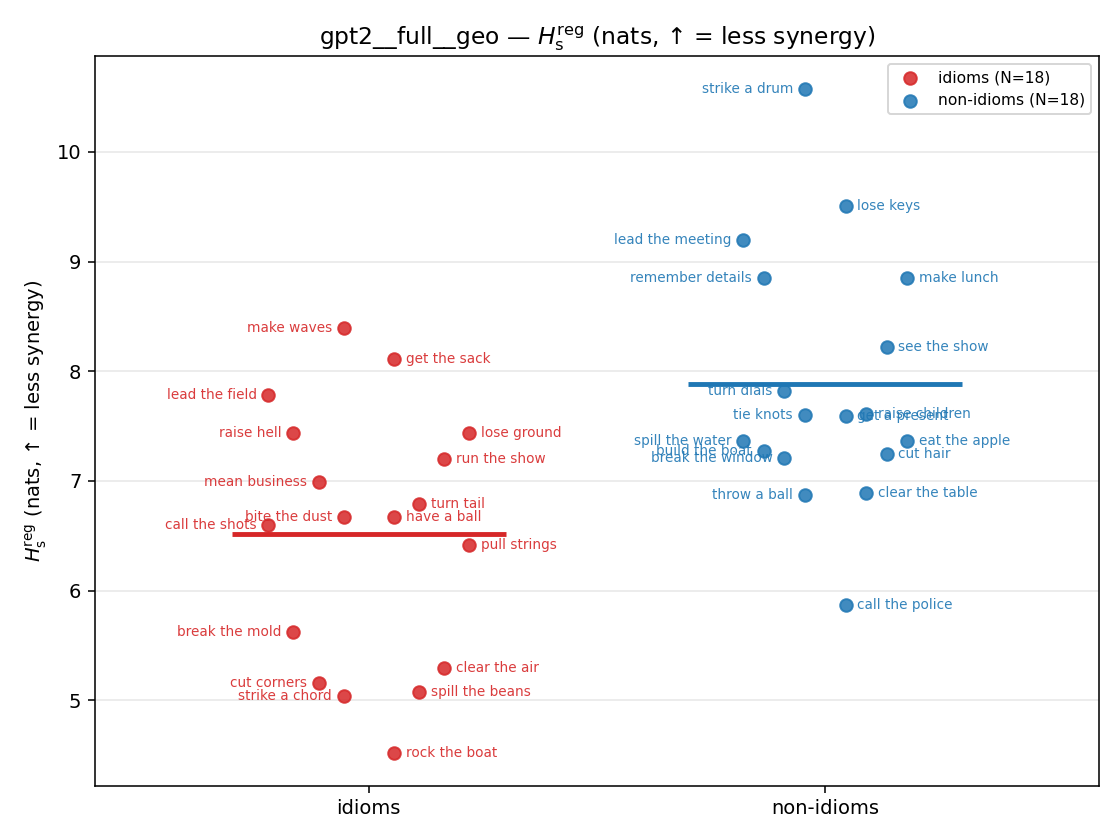 | 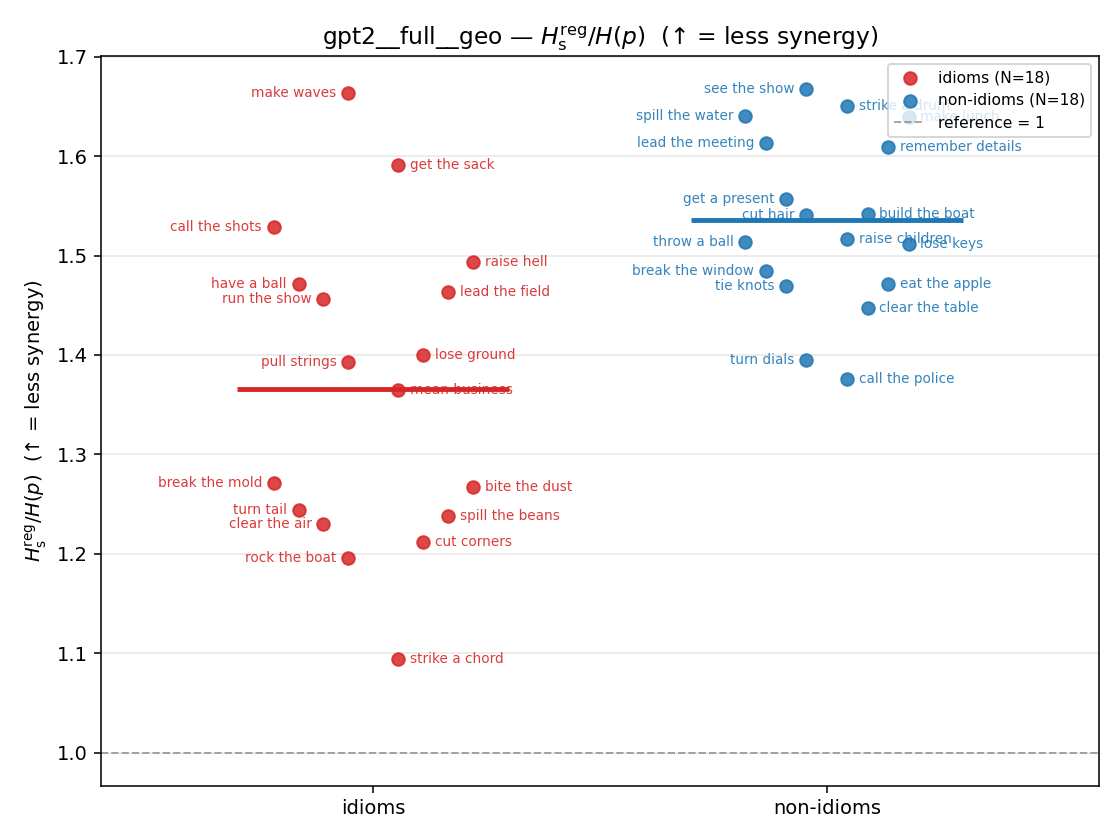 | 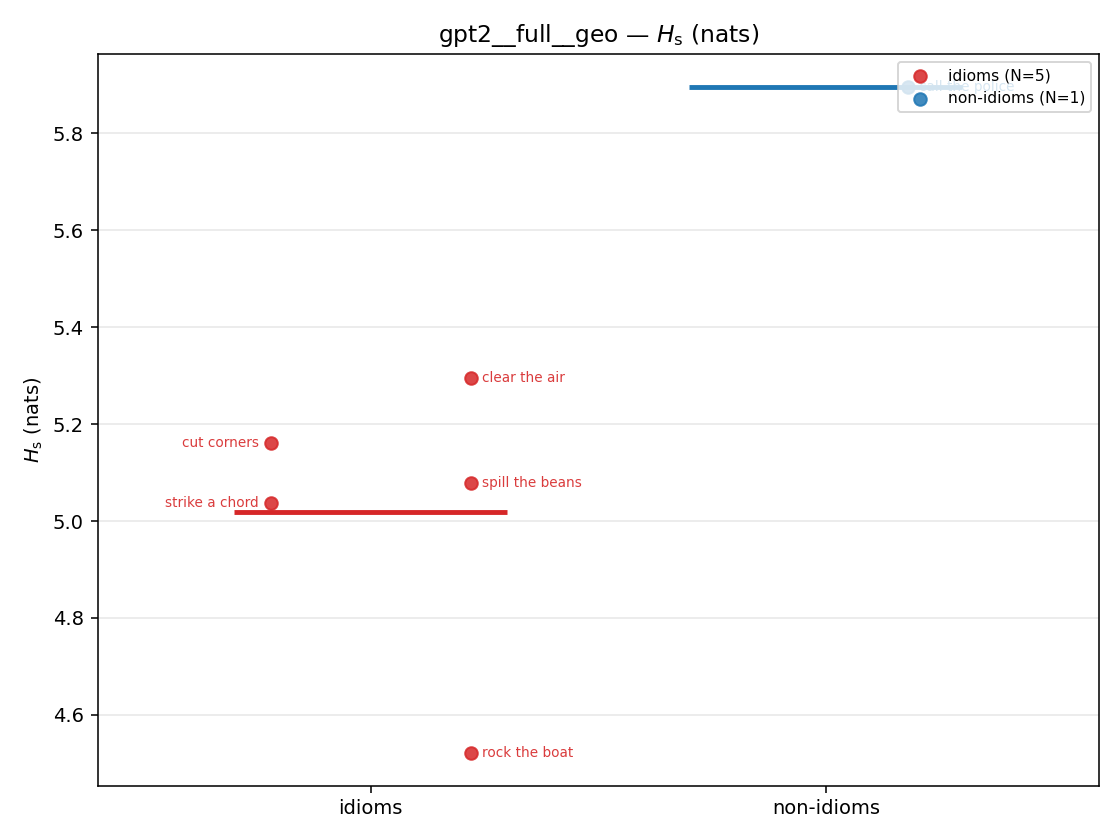 | 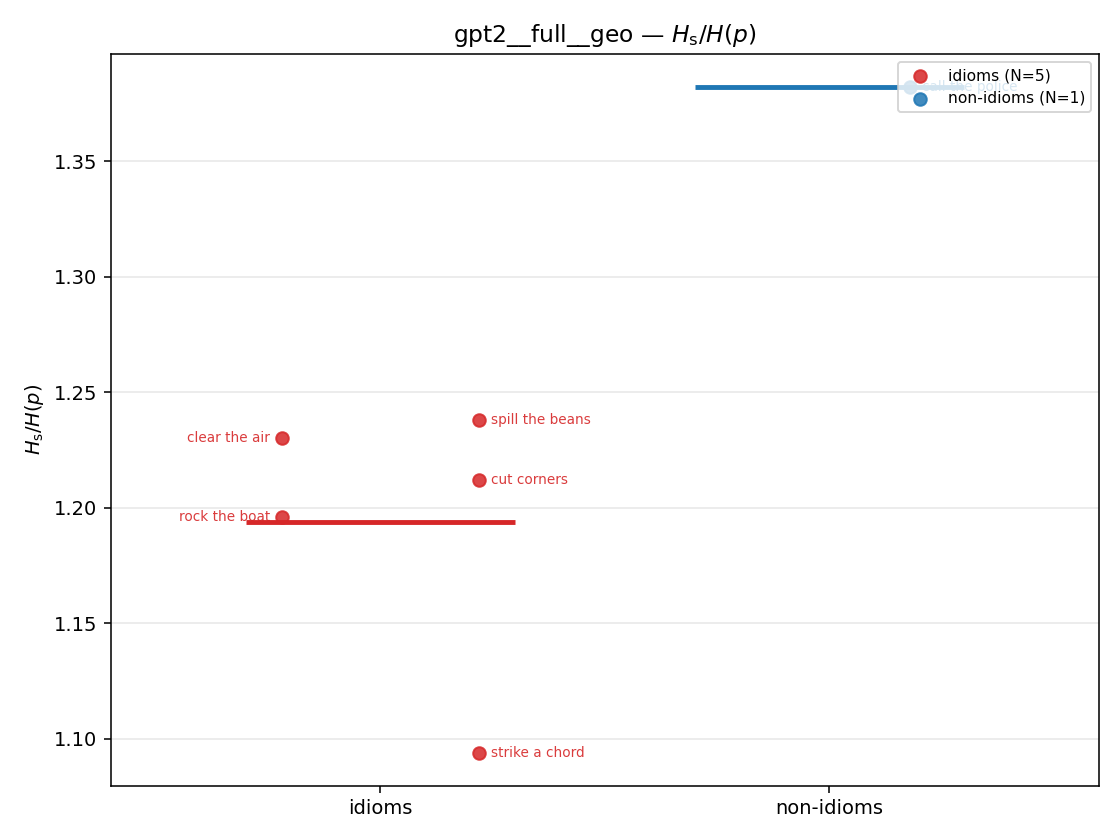 |
| mean ± 95% CI | 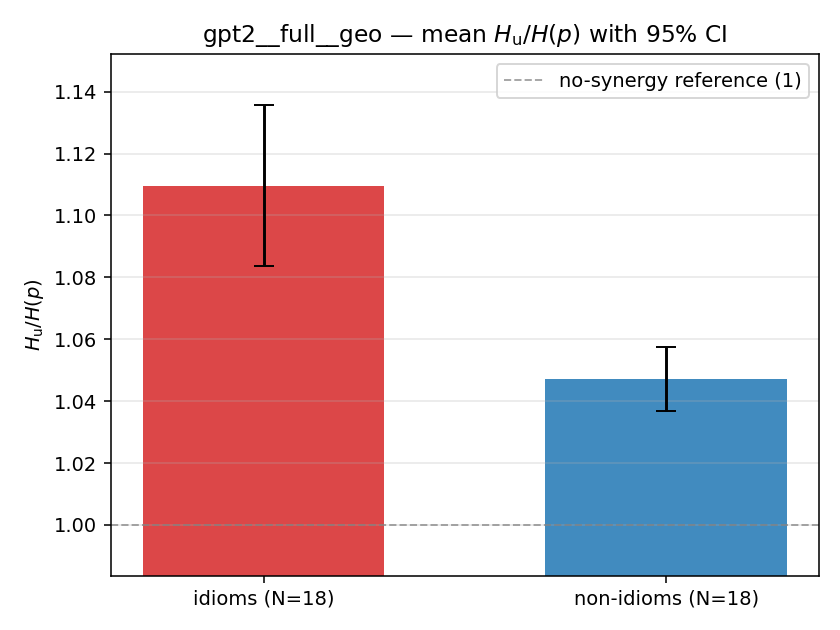 | 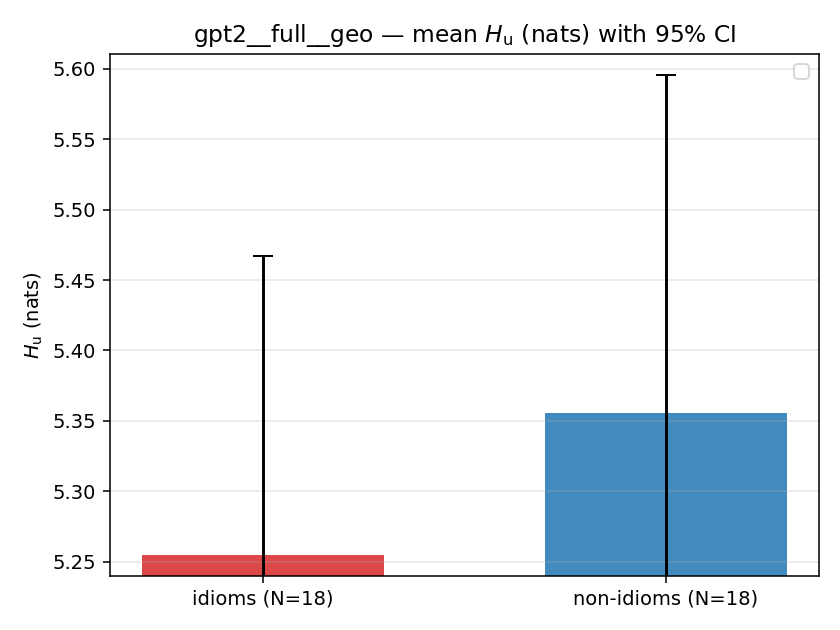 | 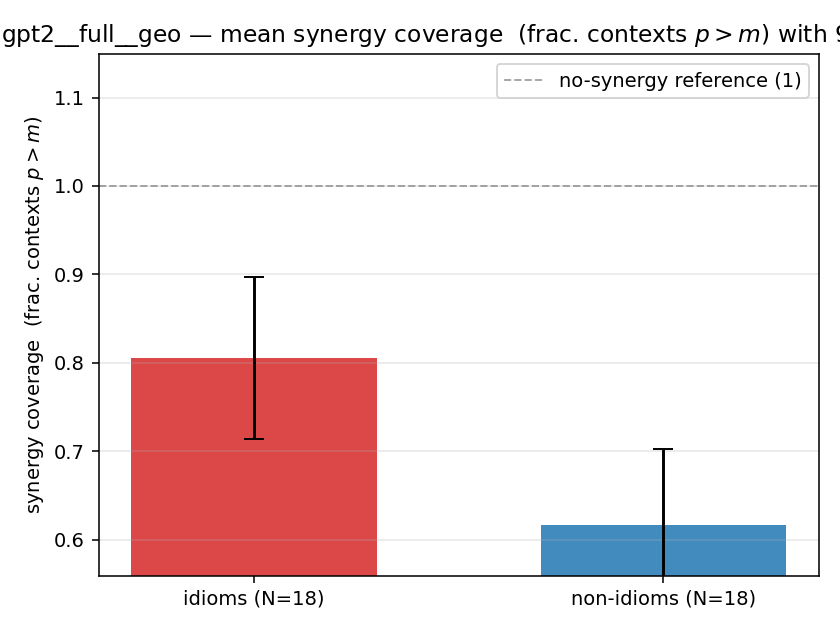 | 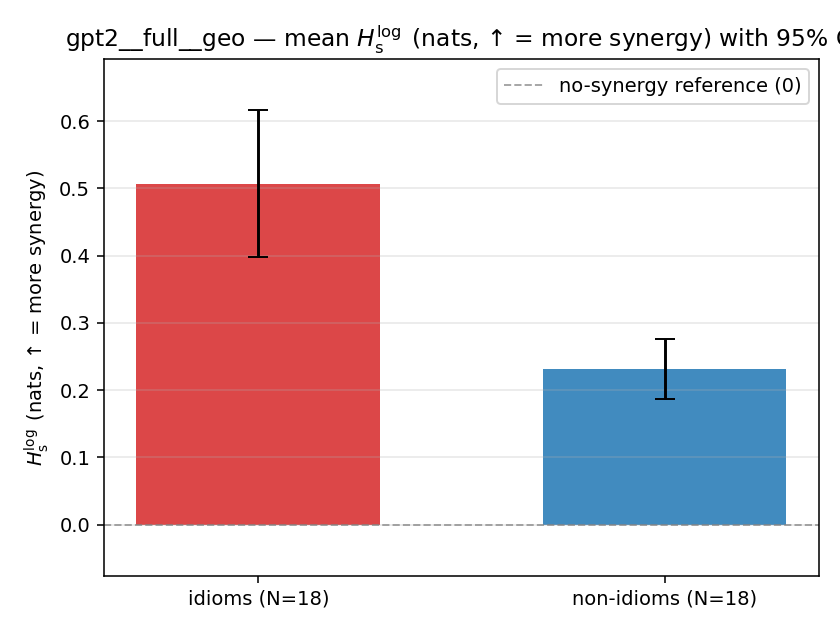 | 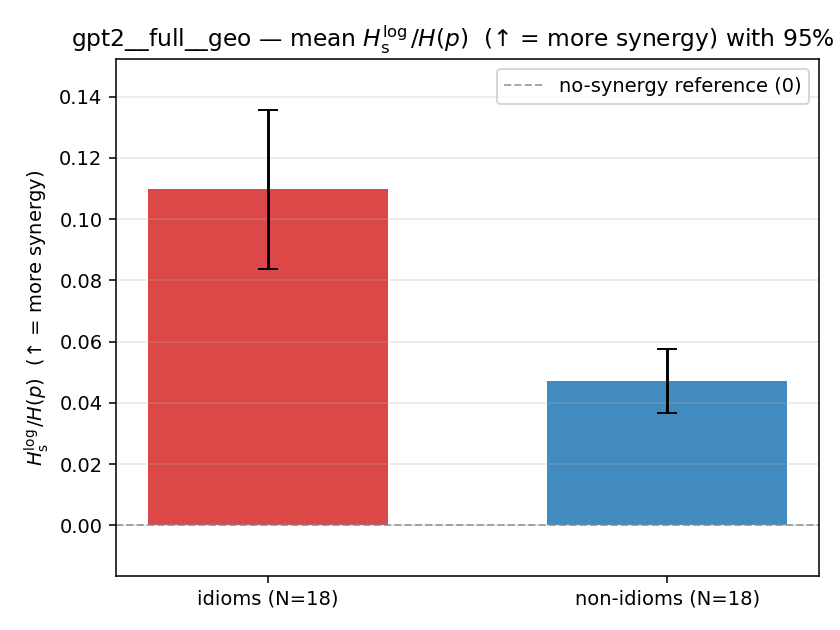 | 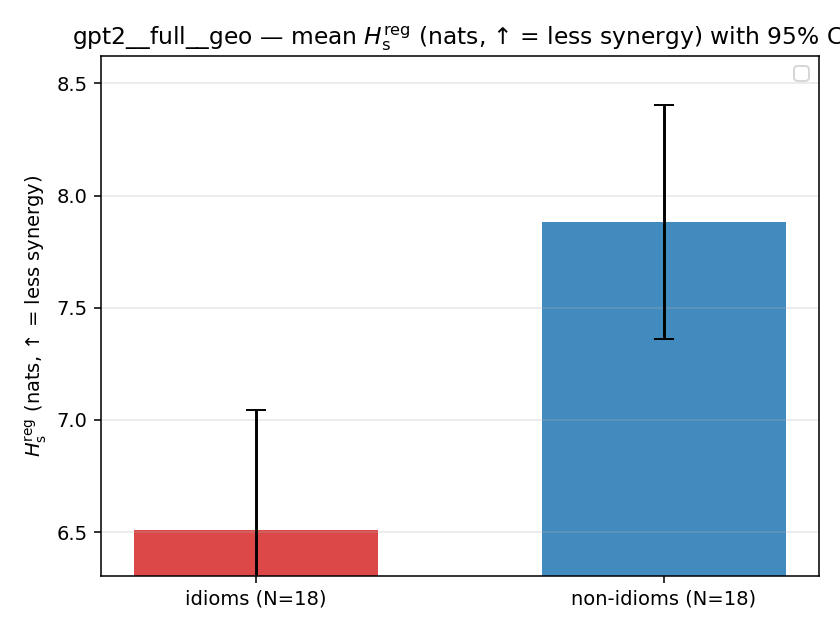 | 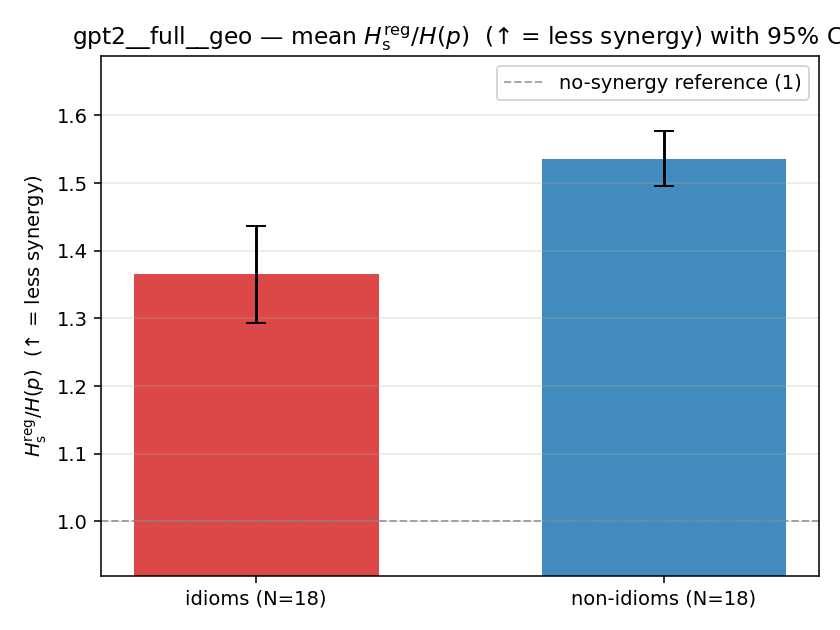 | 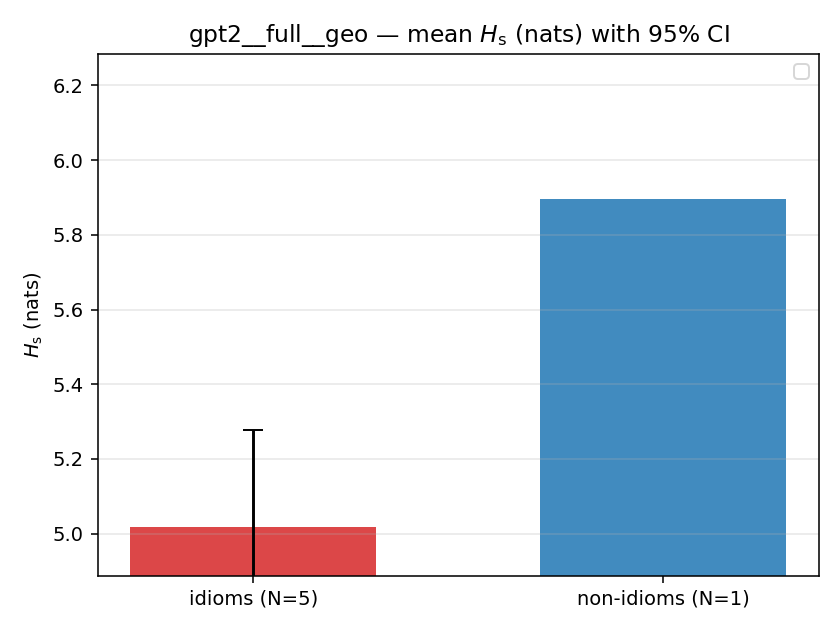 | 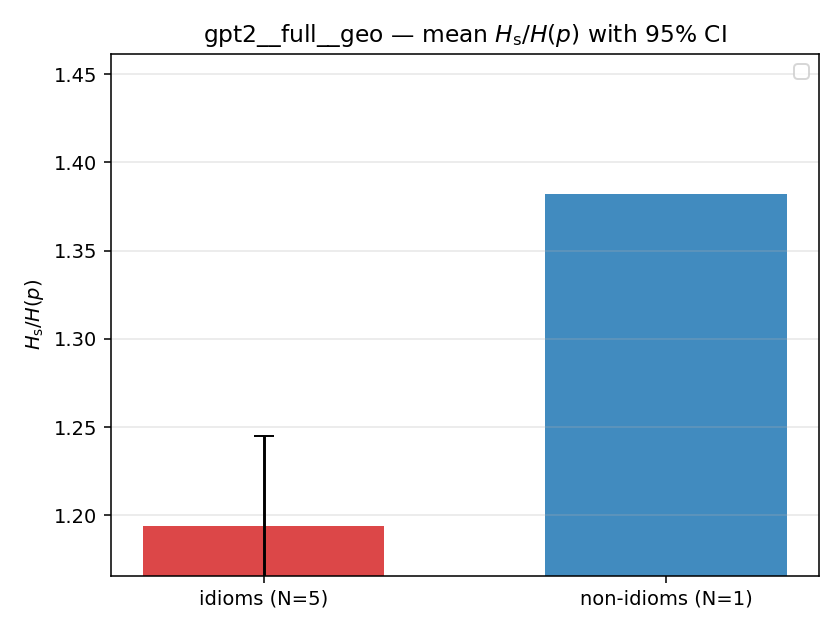 |
| per-idiom (sorted) | 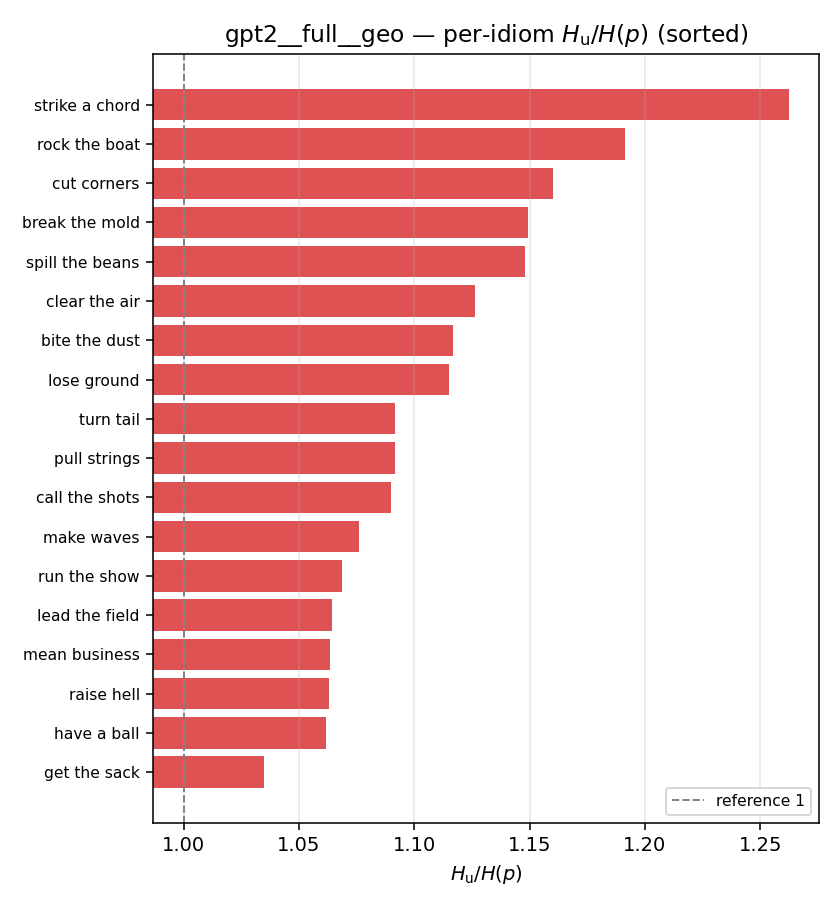 | 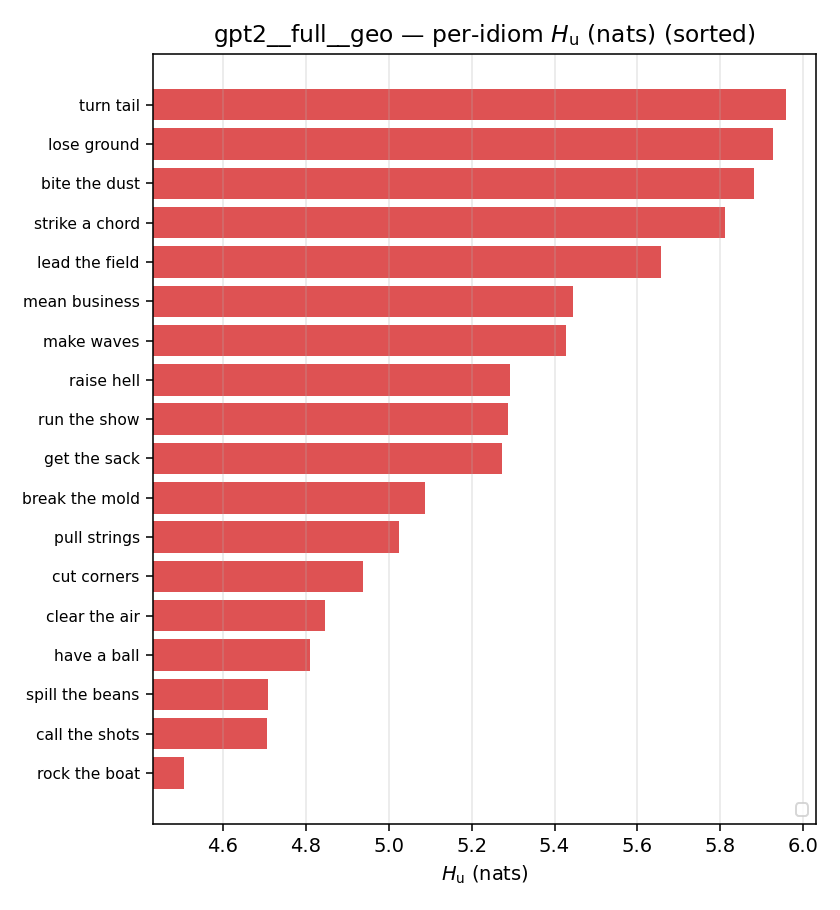 | 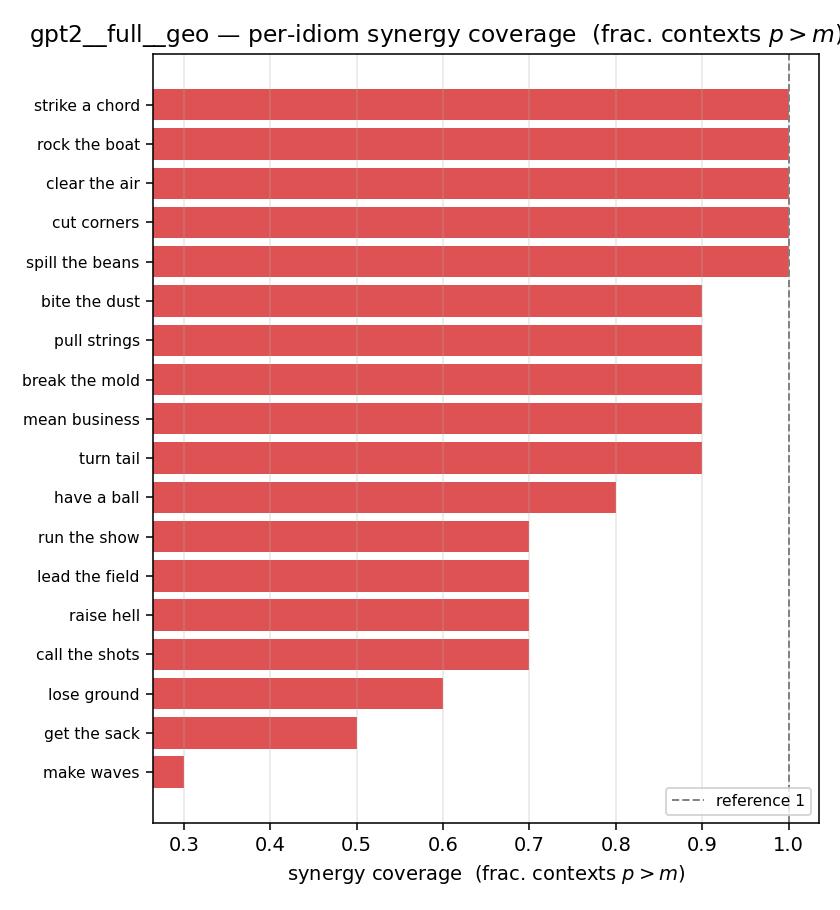 | 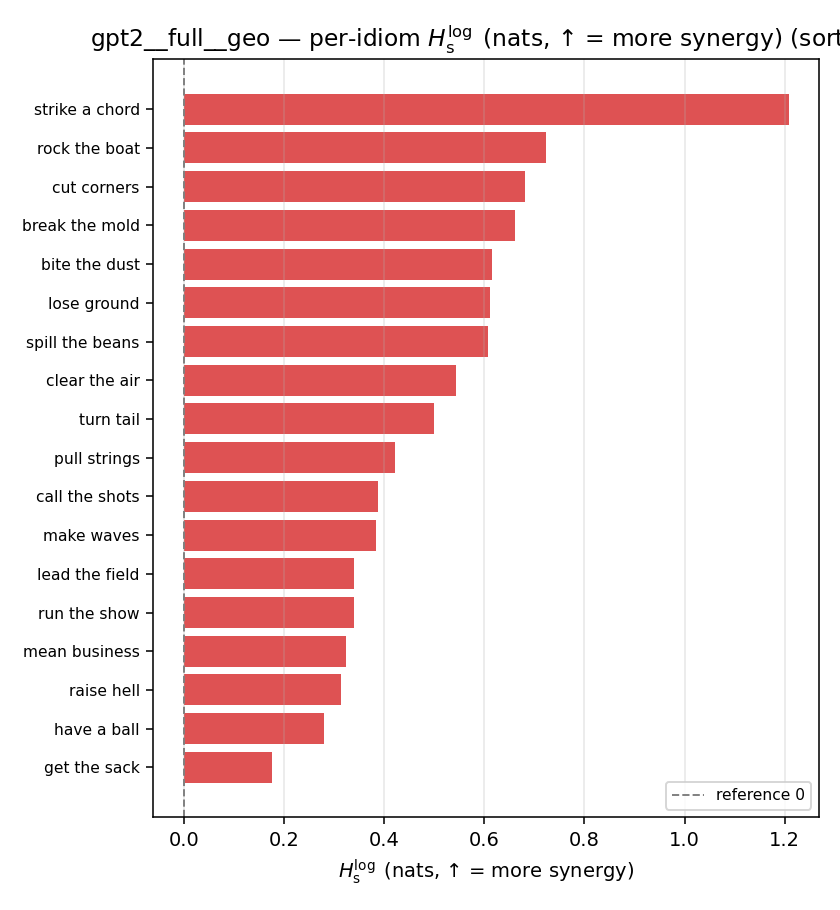 | 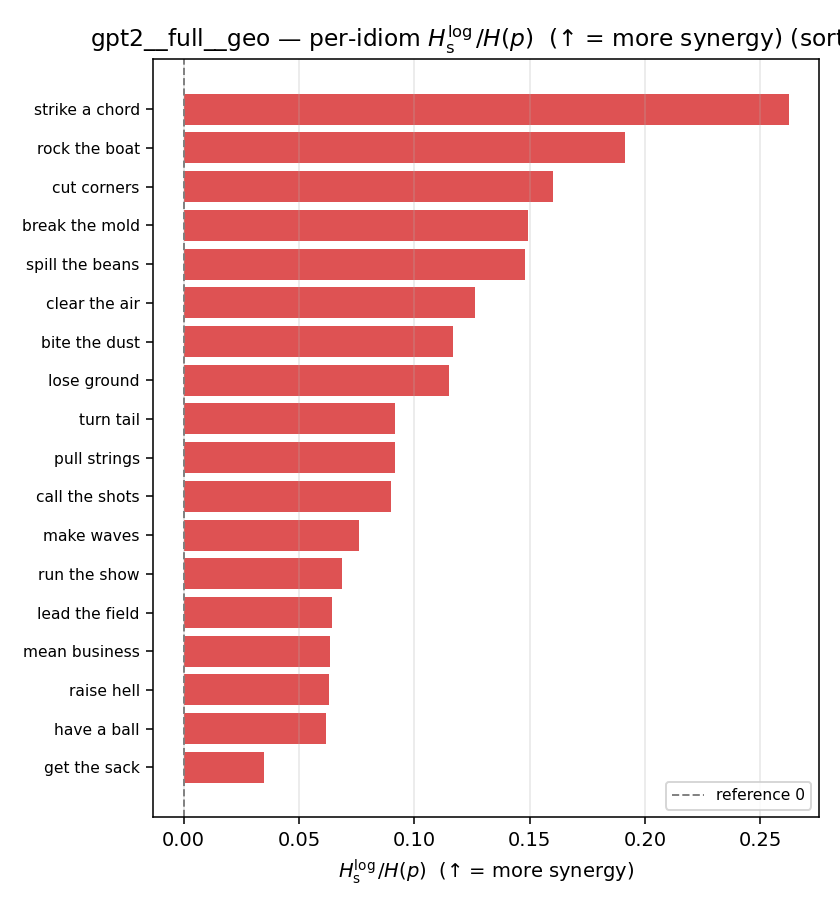 | 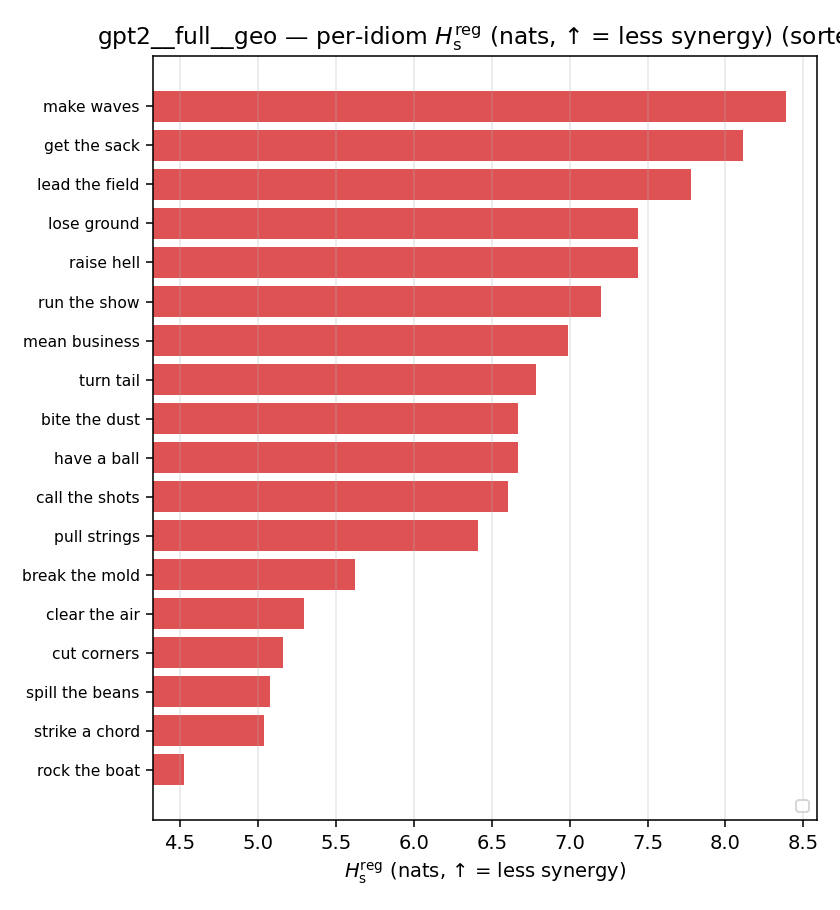 | 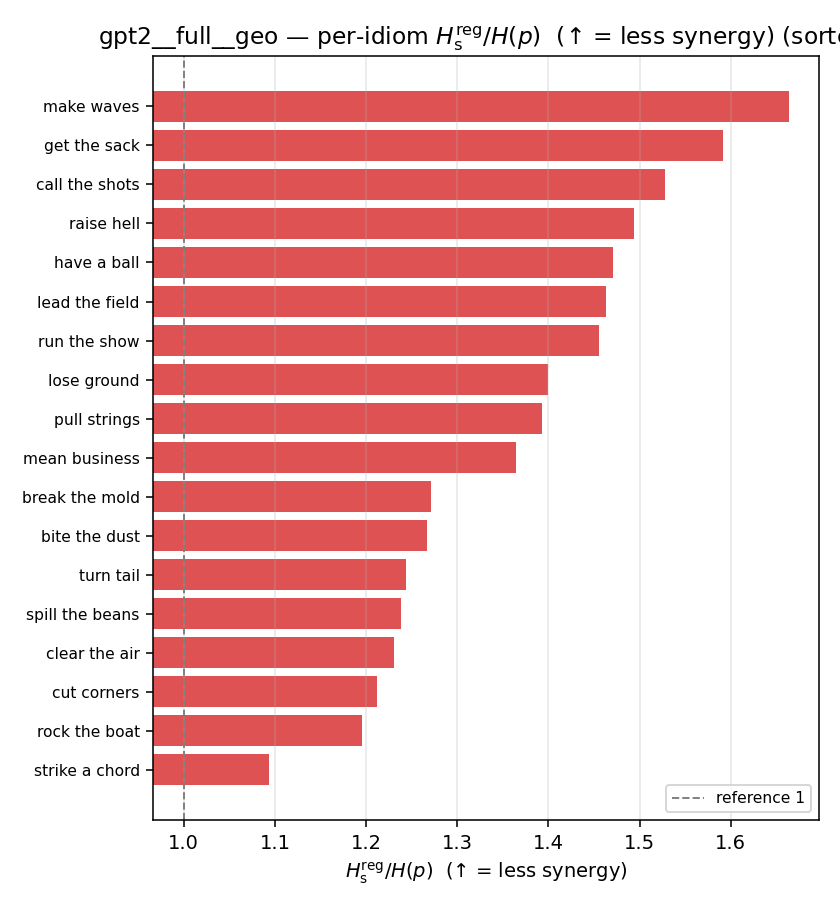 | 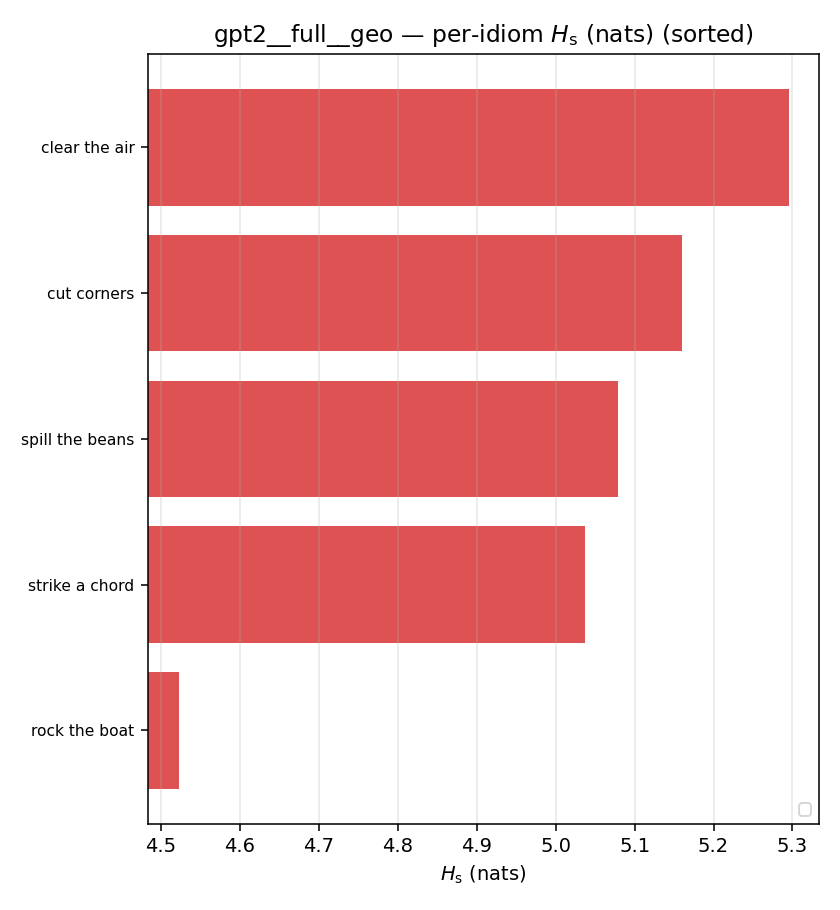 | 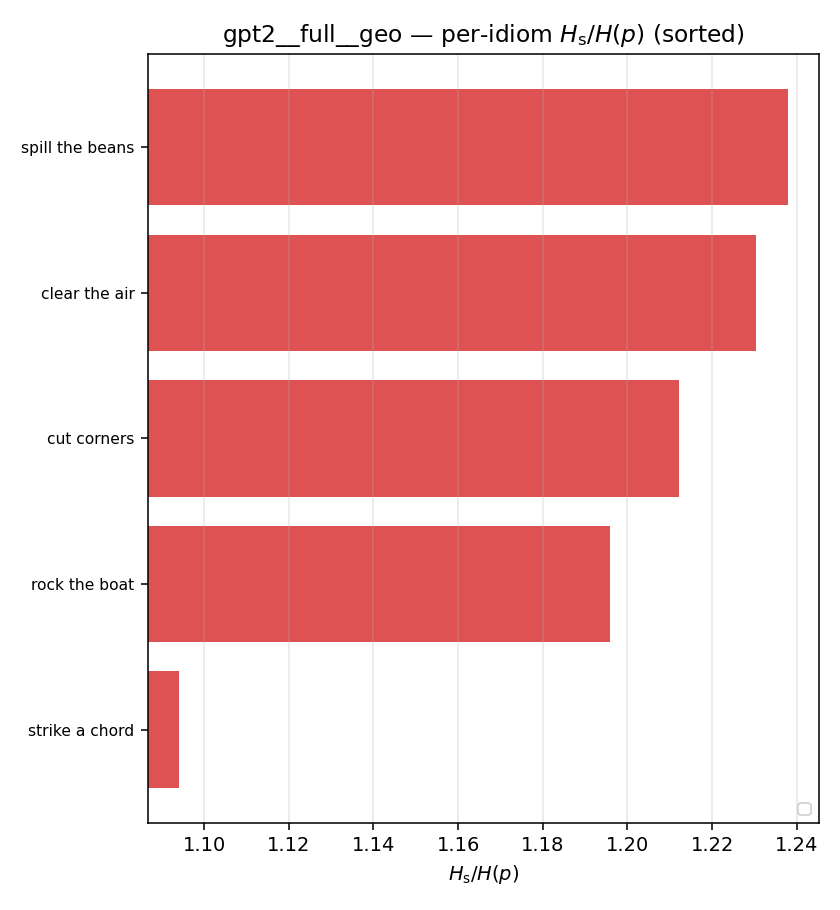 |
gpt2 · full · joint gpt2__full__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 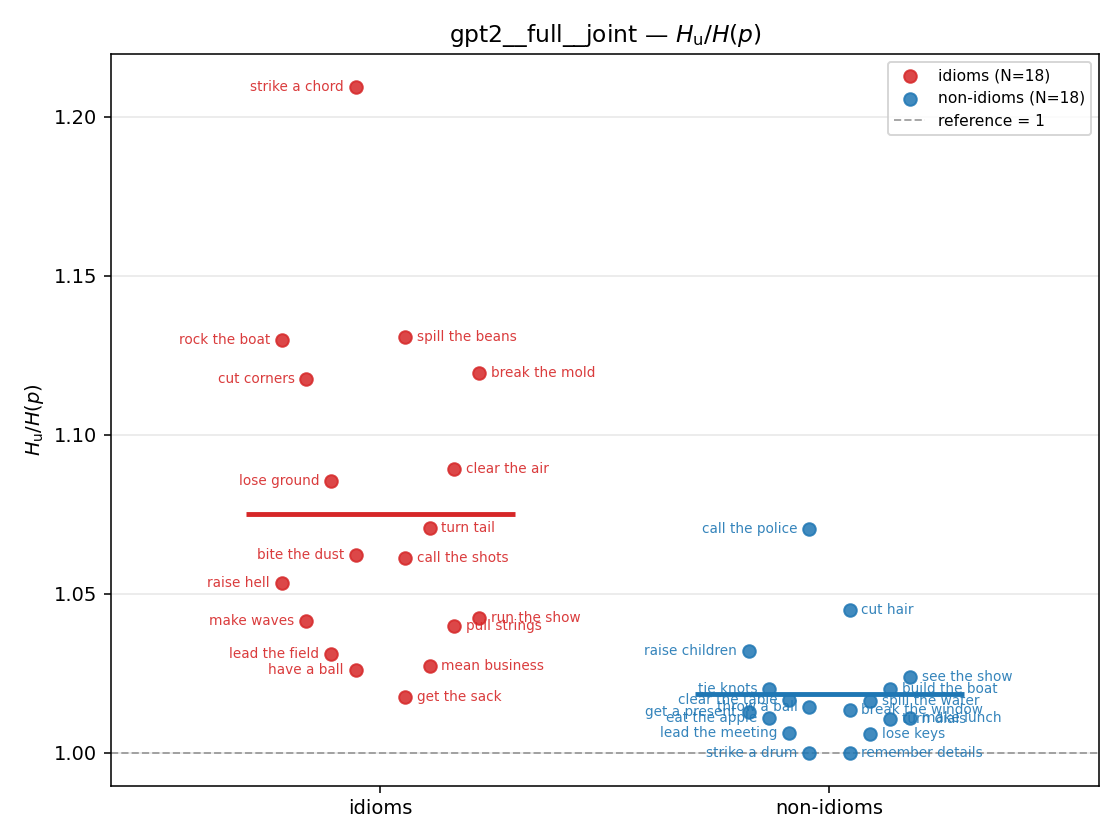 | 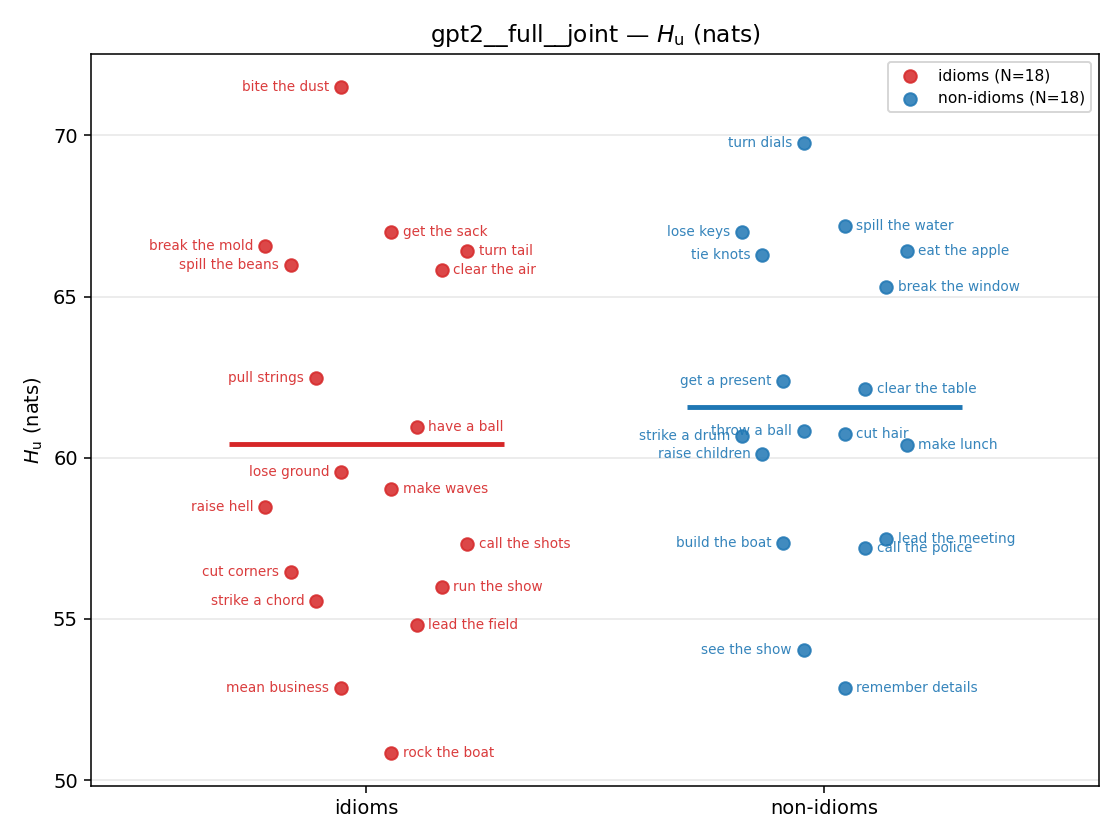 | 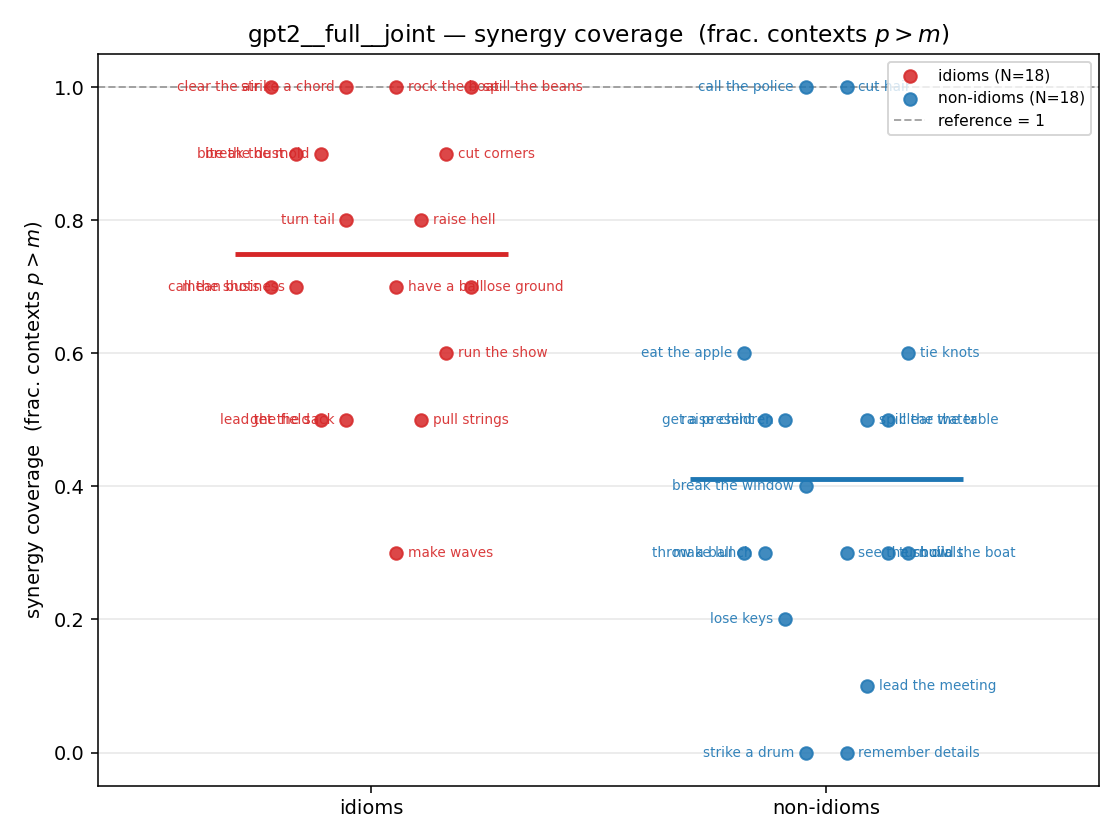 | 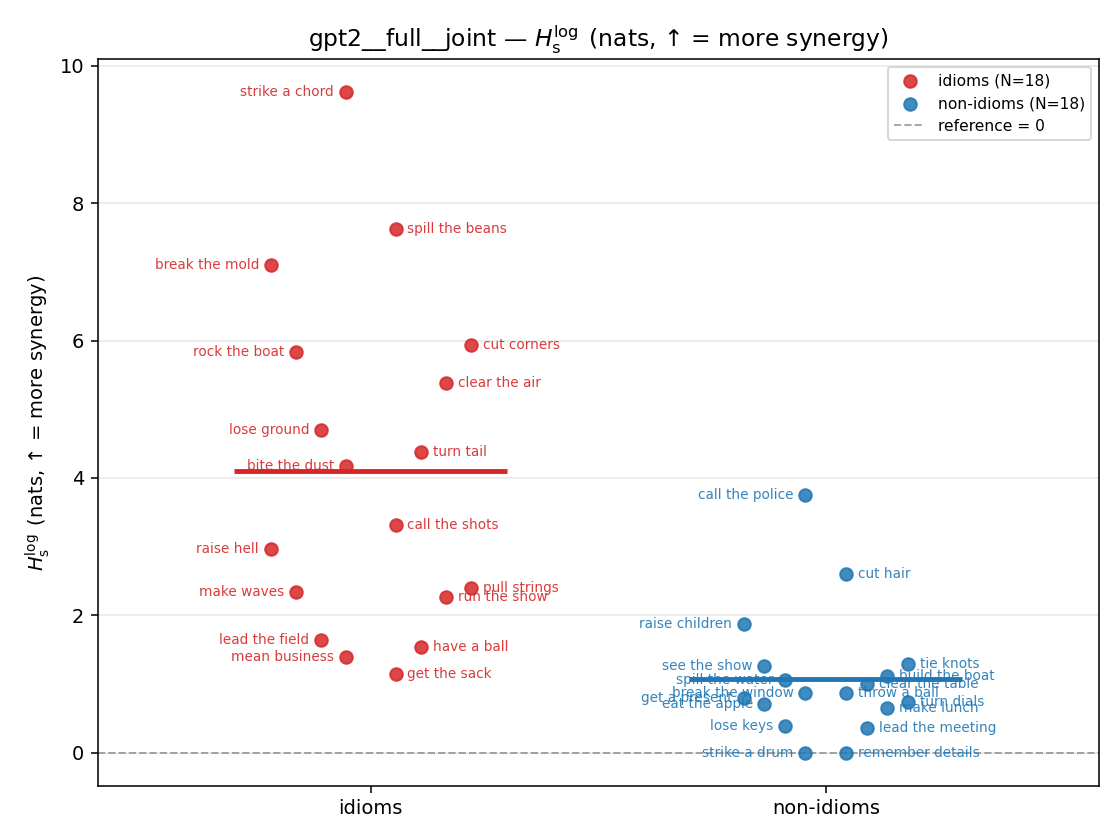 | 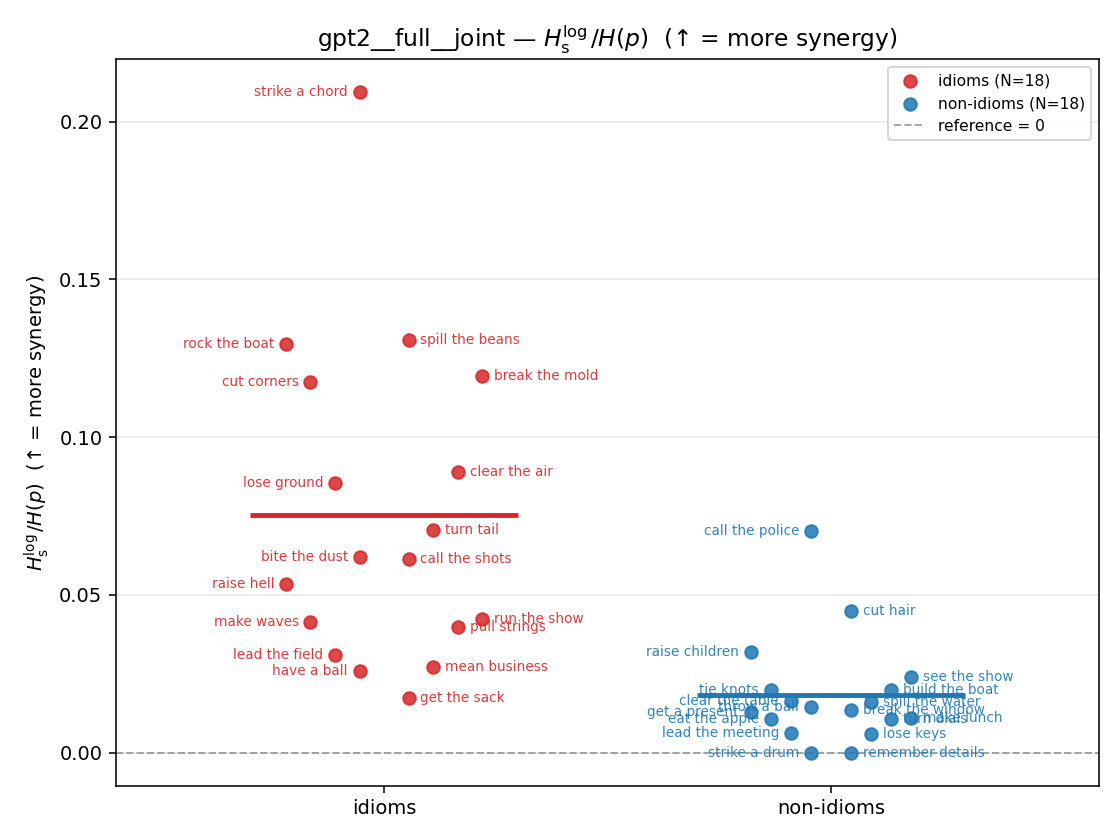 | 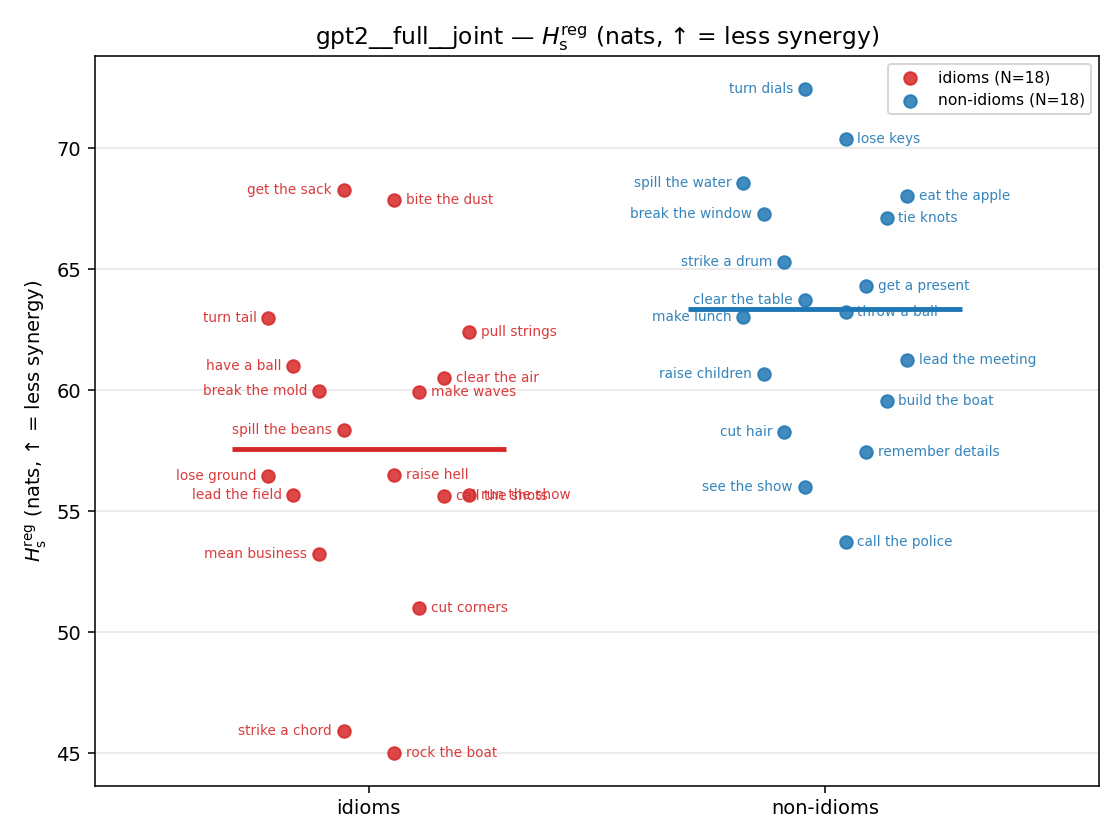 | 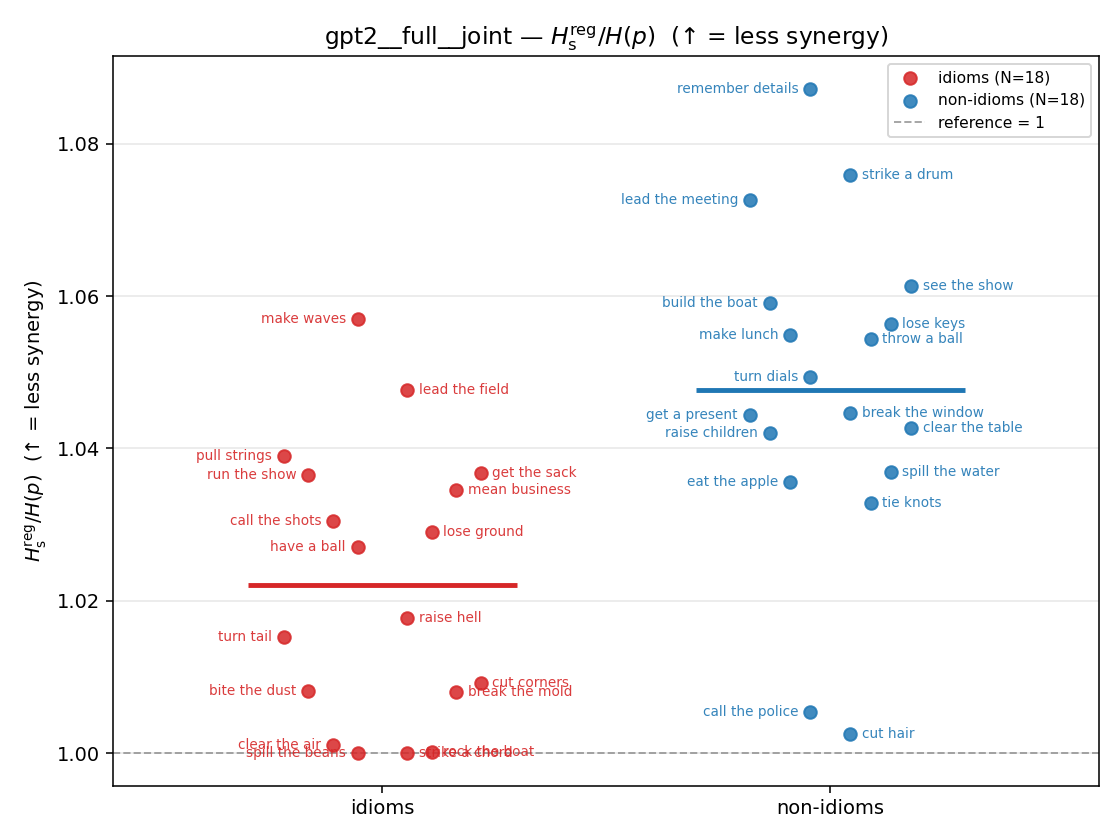 | 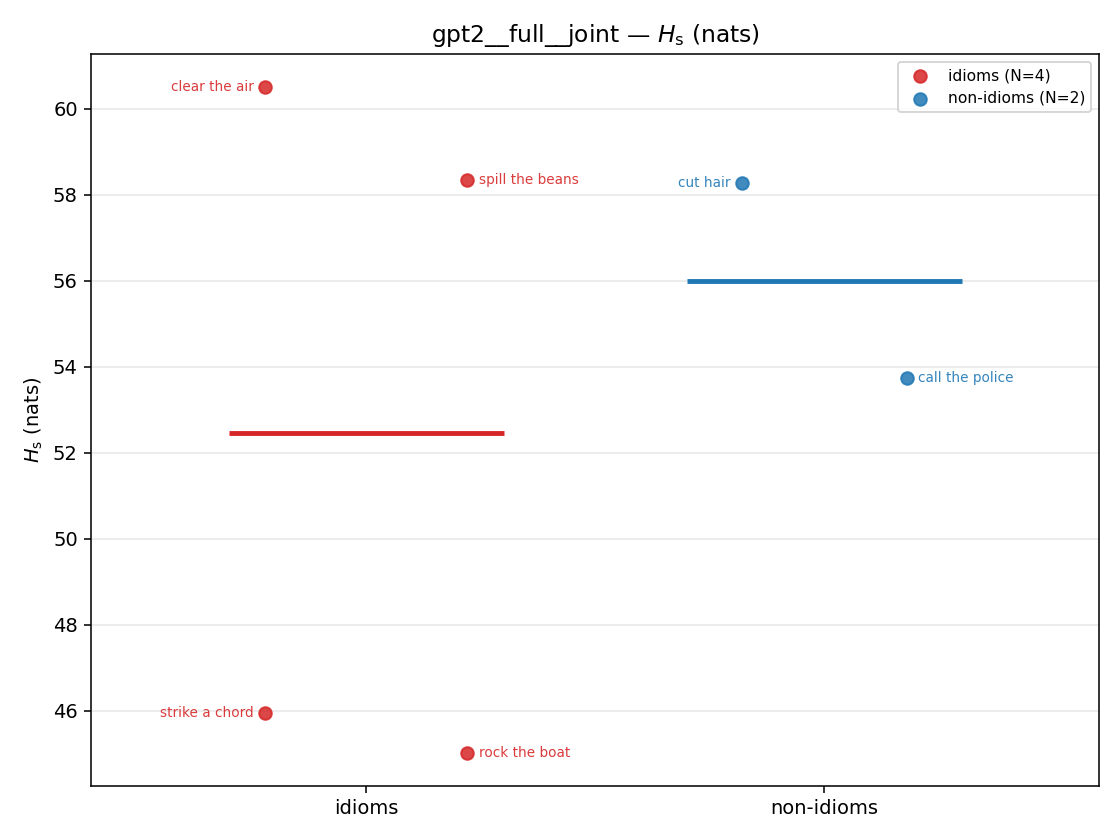 | 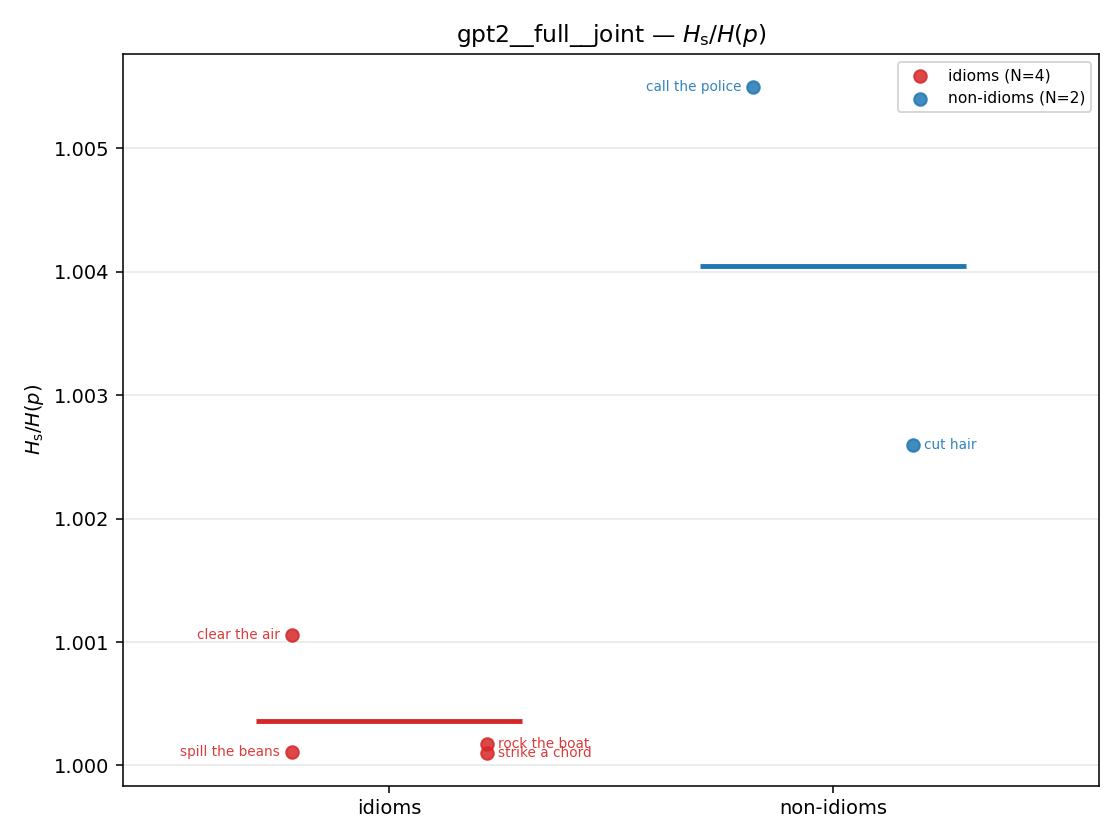 |
| mean ± 95% CI | 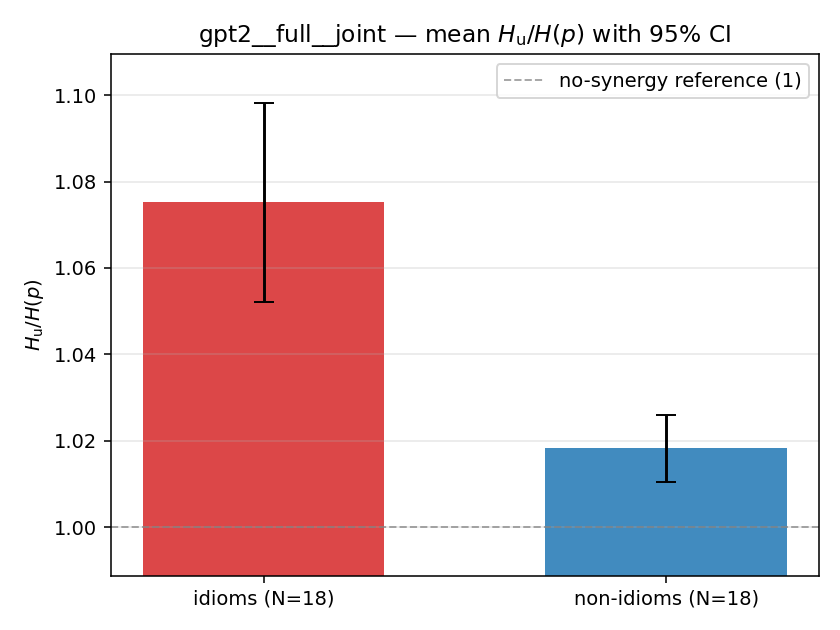 | 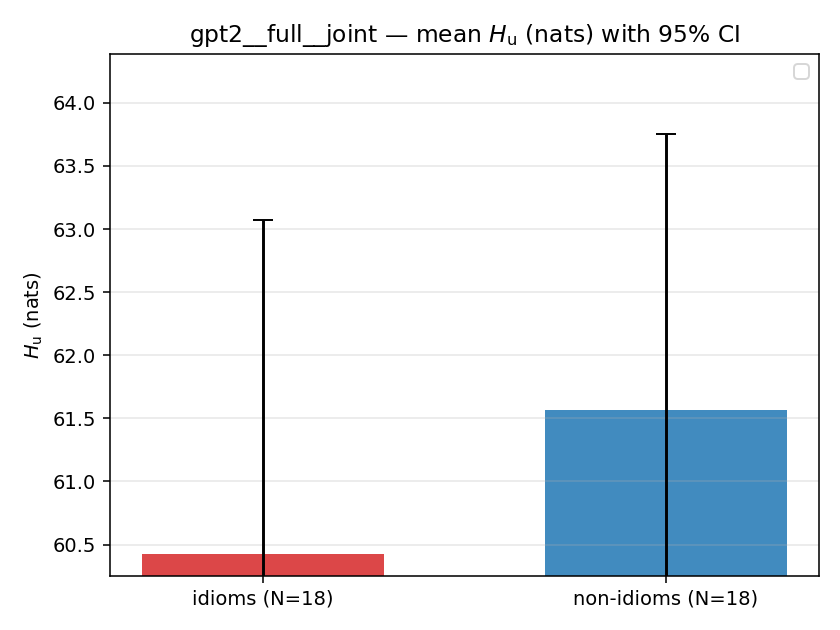 | 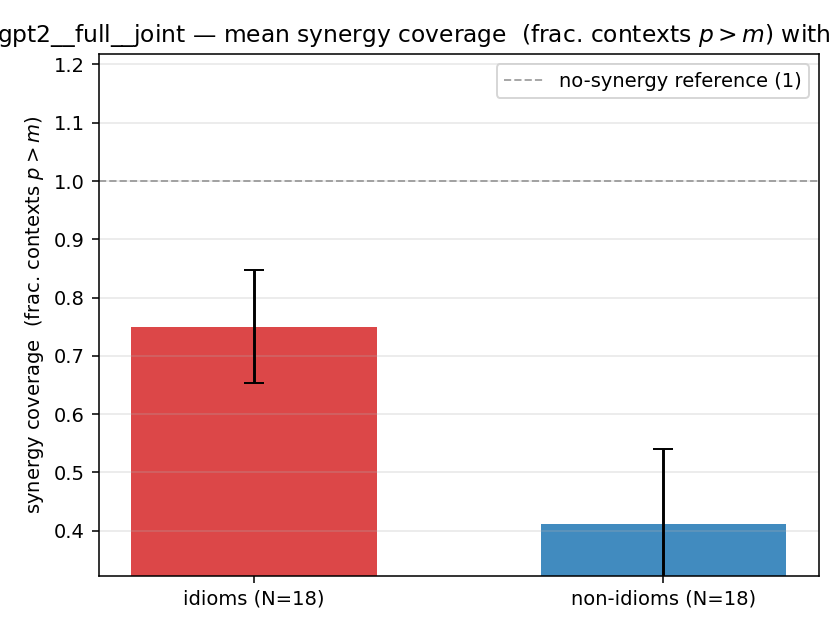 | 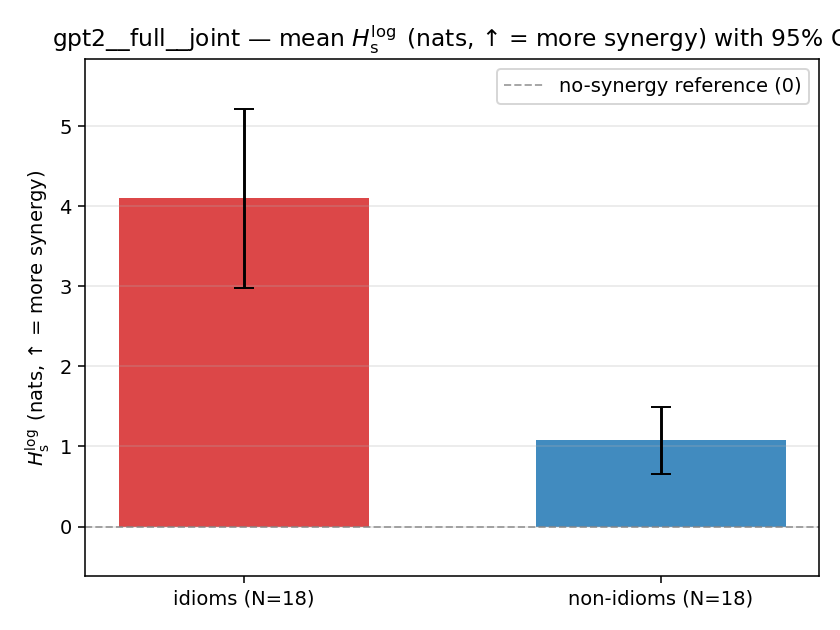 | 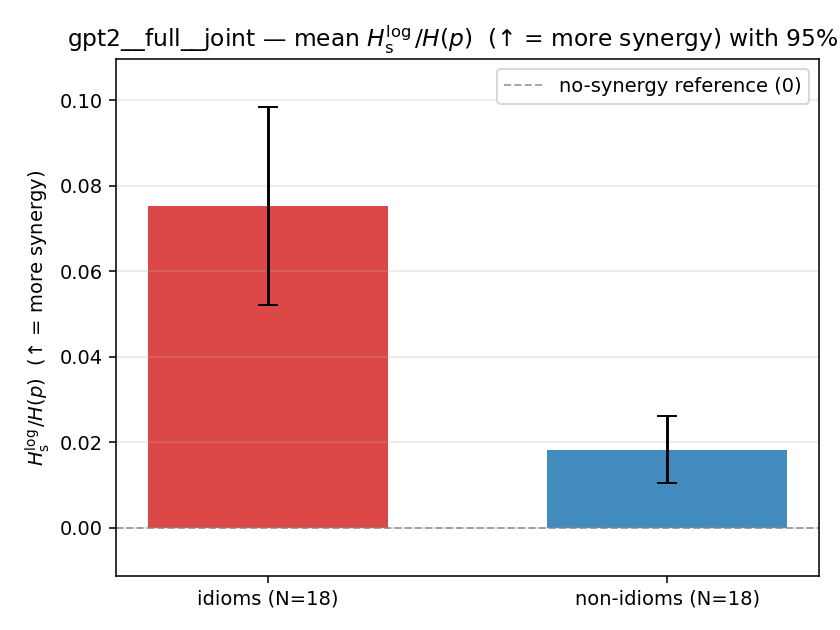 | 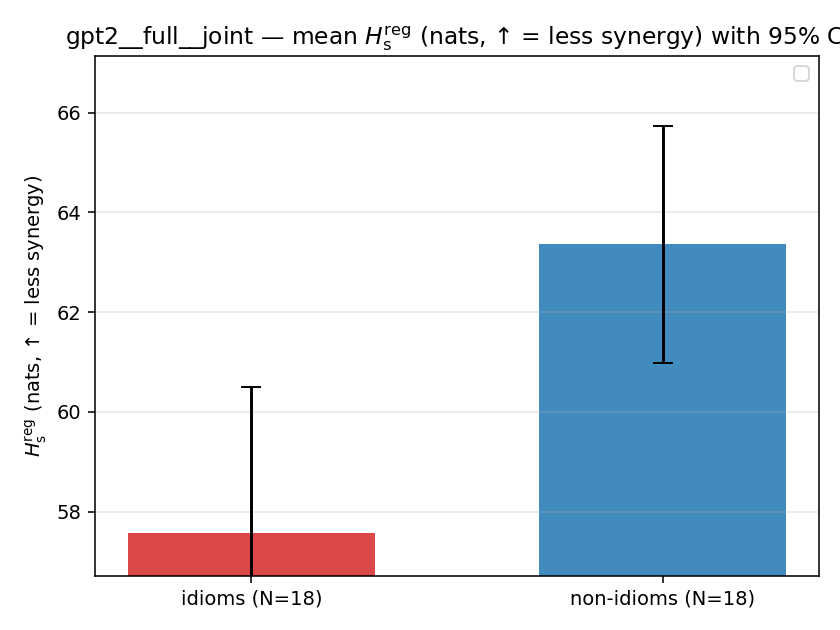 | 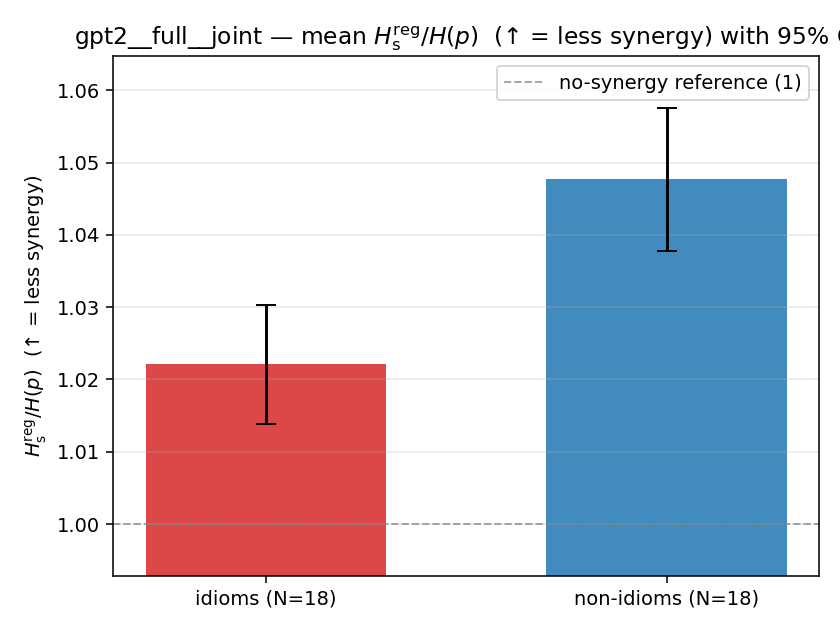 | 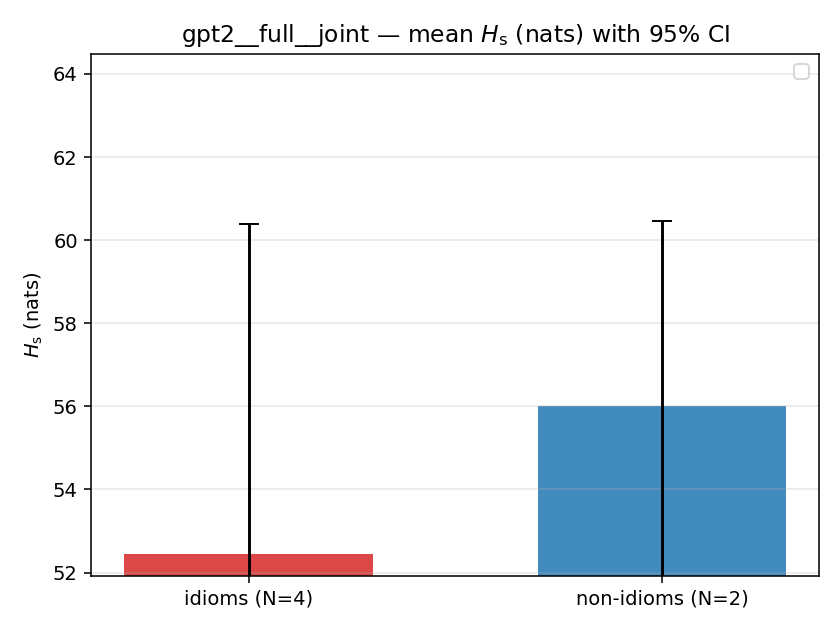 | 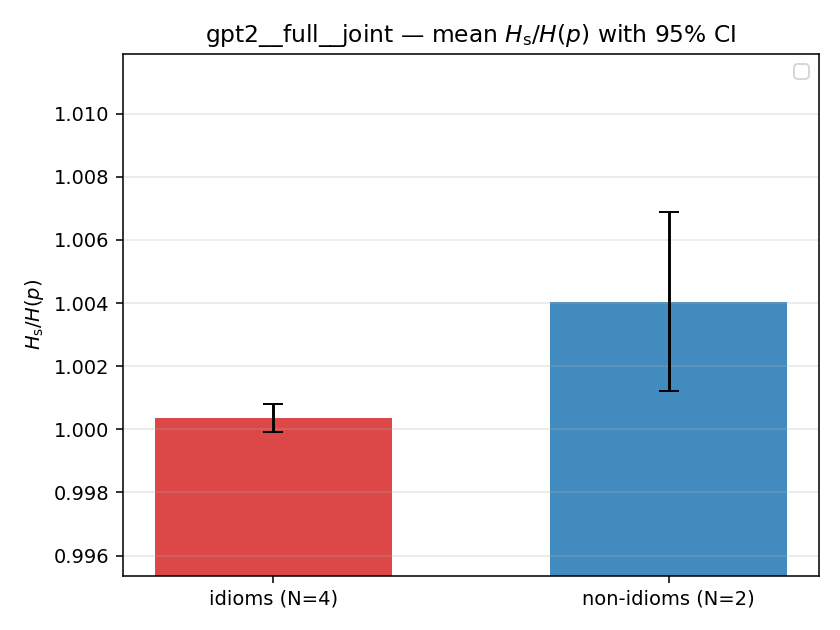 |
| per-idiom (sorted) | 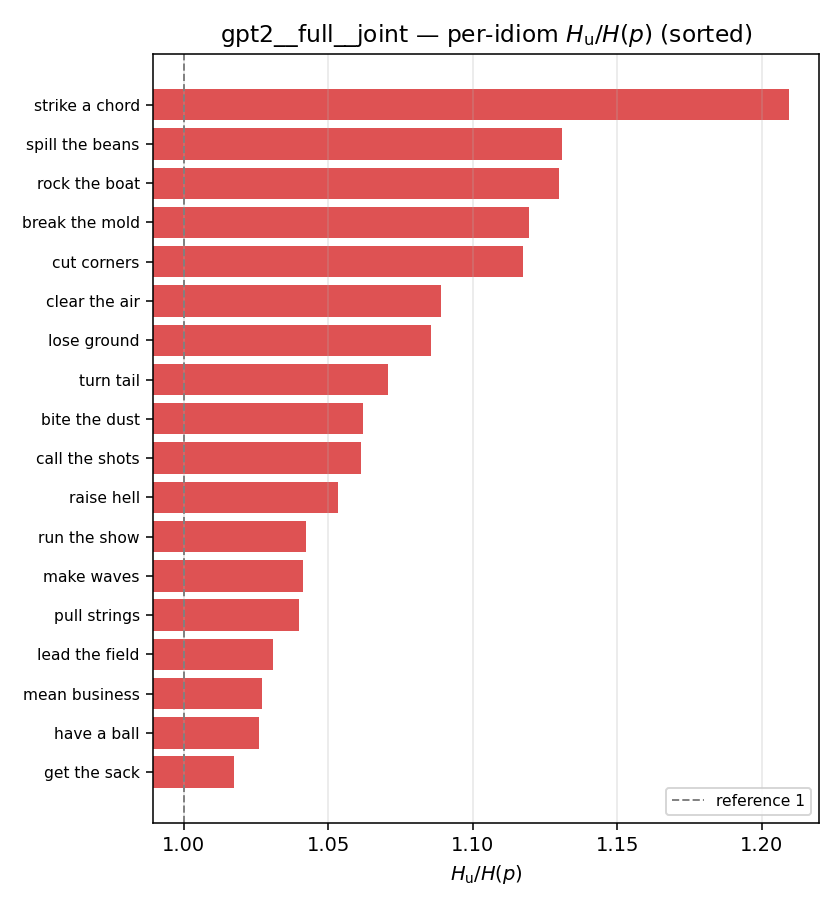 | 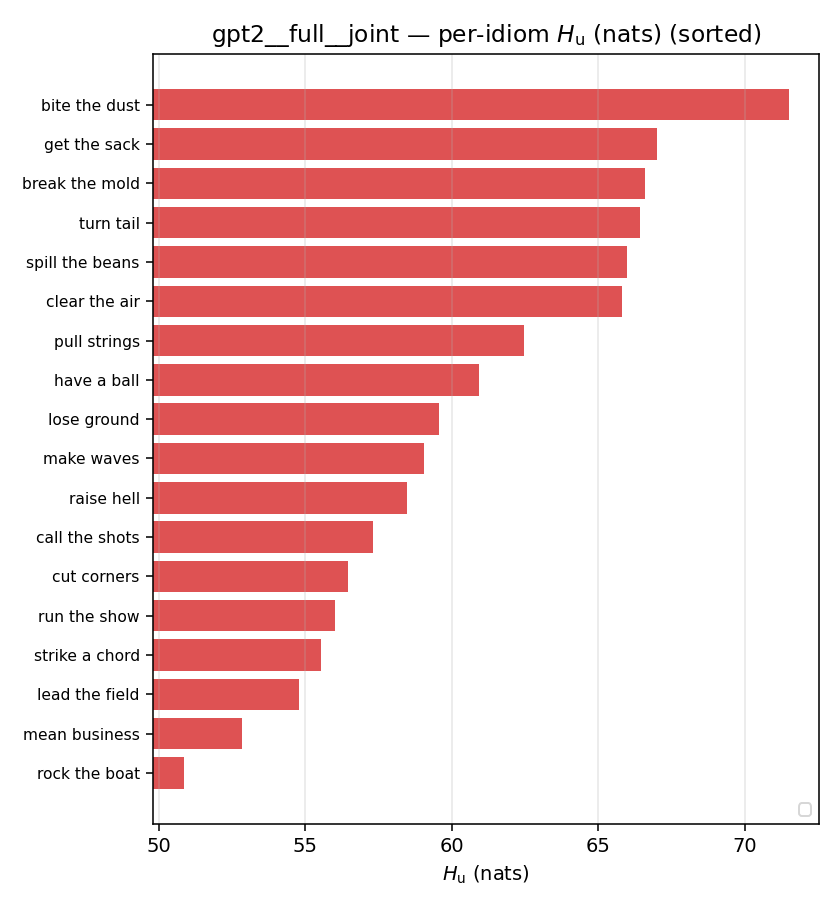 | 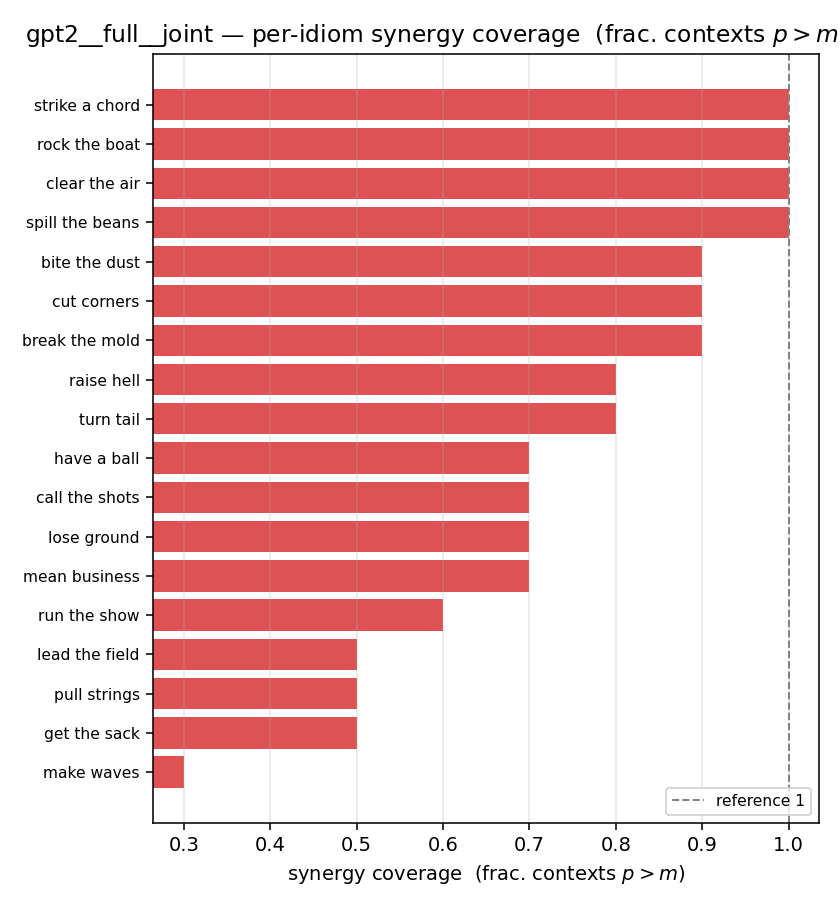 | 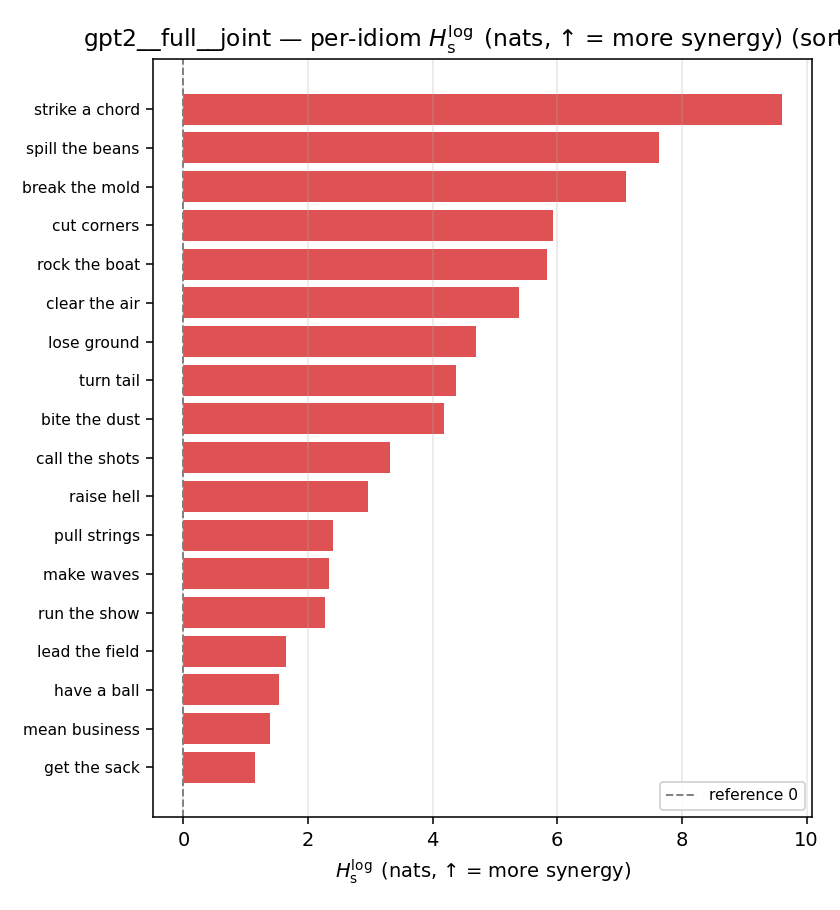 | 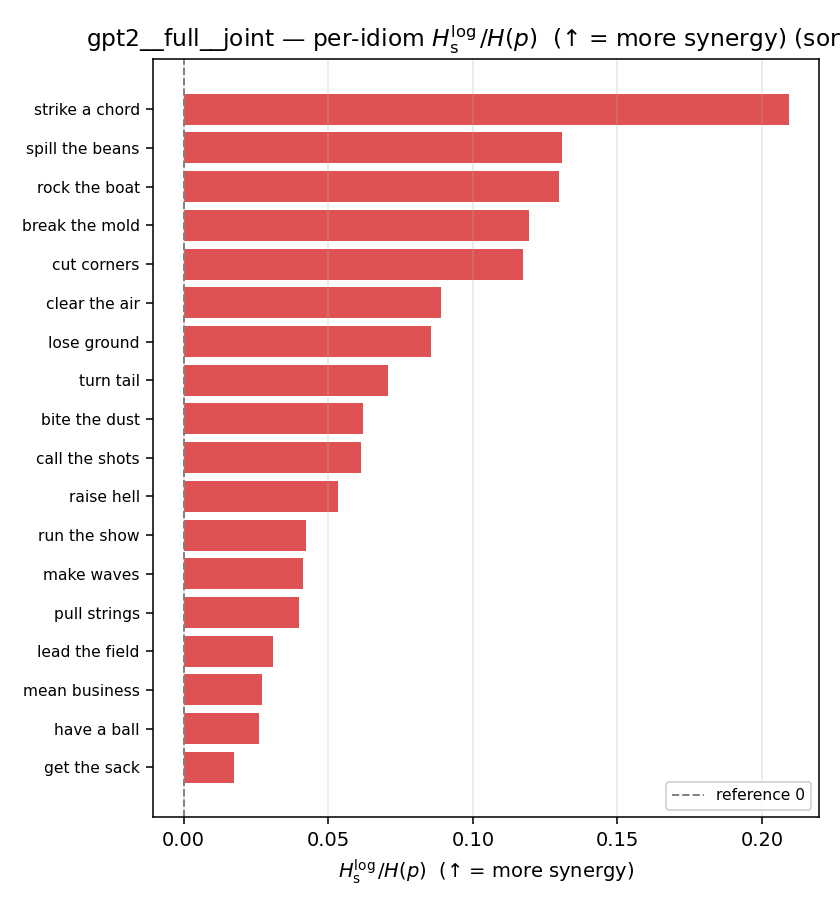 | 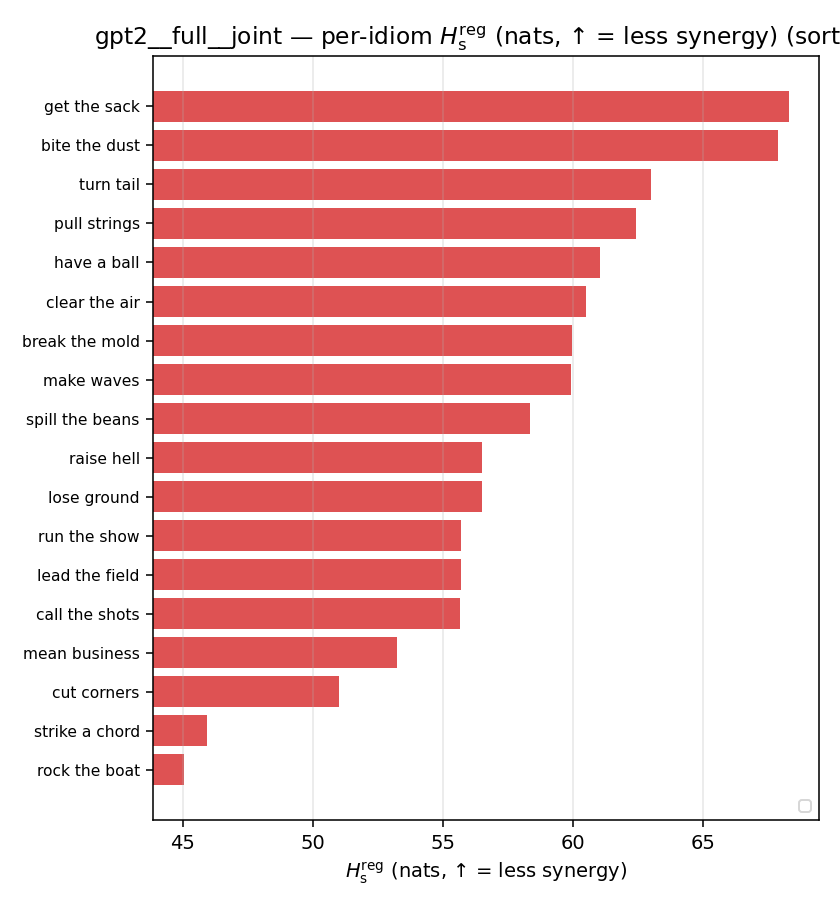 | 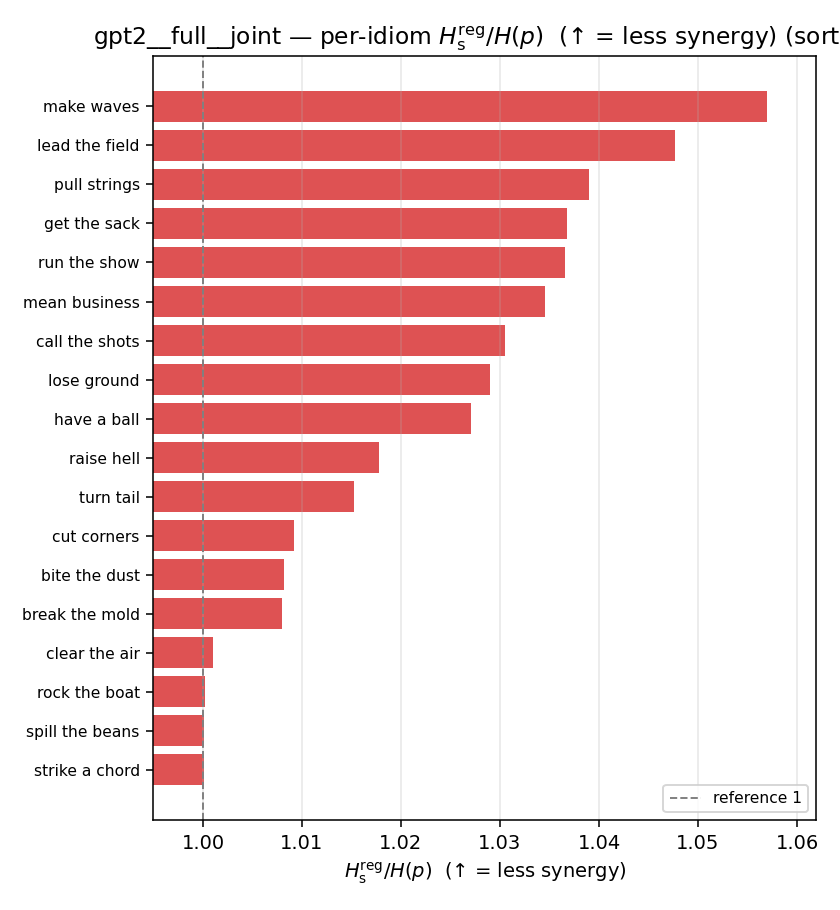 | 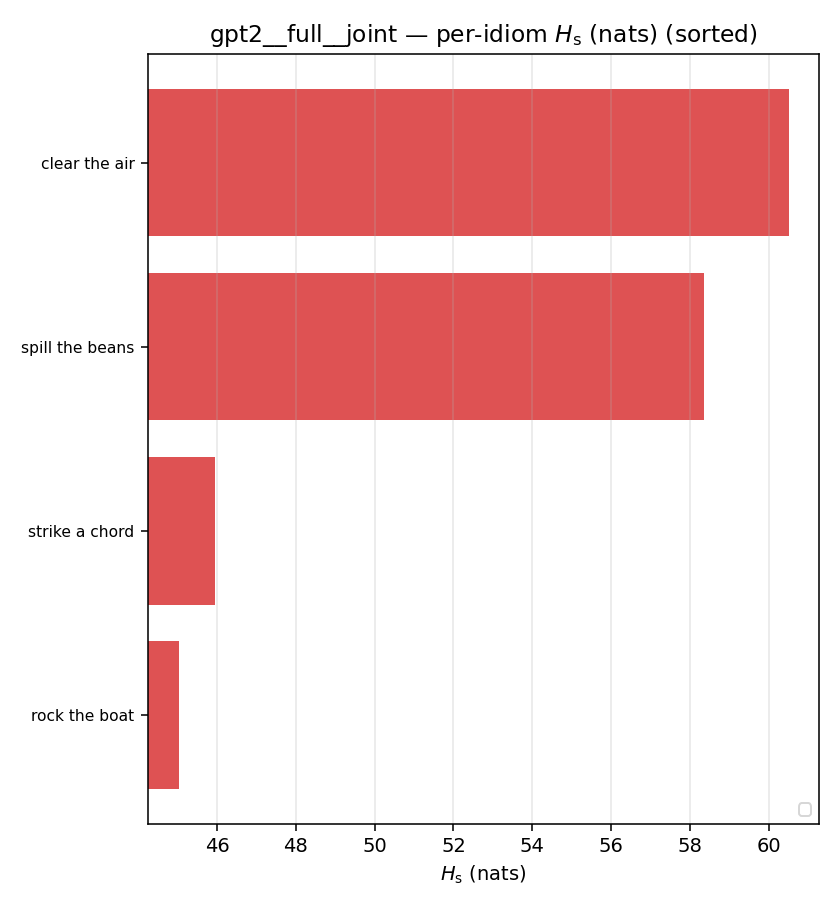 | 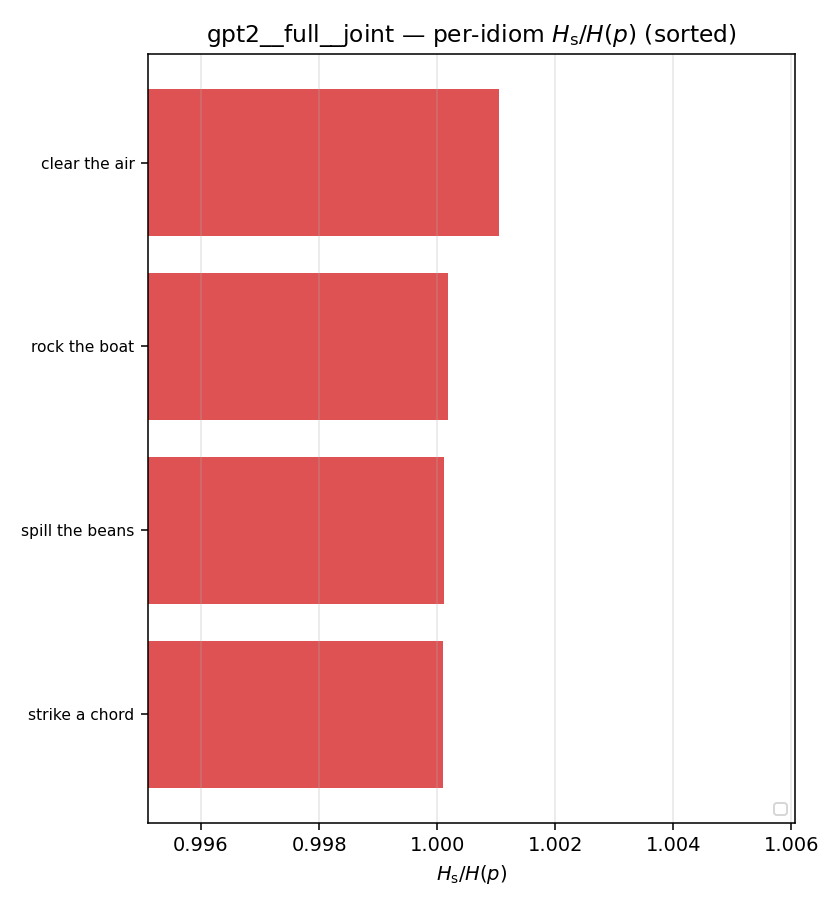 |
gemma2-9b — per-config figures
3×9 grid of figure-type × metric (↑syn = bigger means more synergy, ↓syn = bigger means less). Tables scroll horizontally; “— (no finite values)” marks the original Hs/ratio_s where every phrase was +inf. Click to zoom.
gemma2-9b · medial · geo gemma2-9b__medial__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 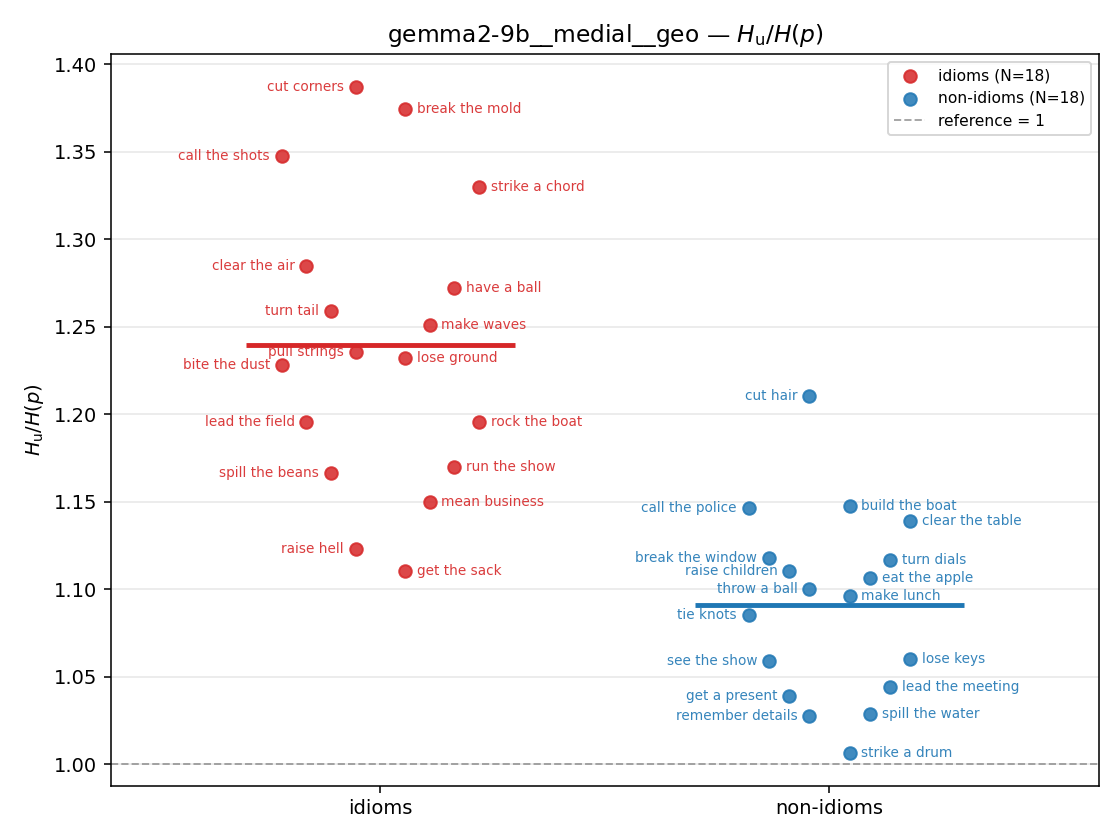 | 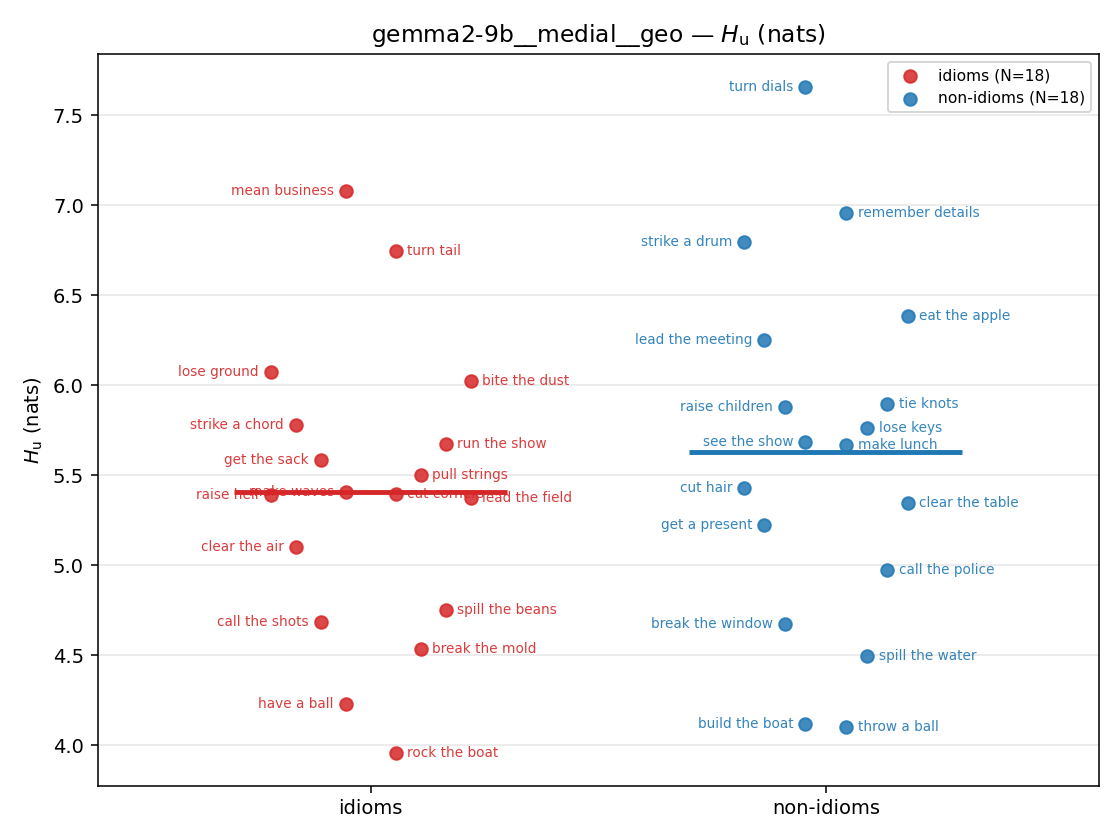 | 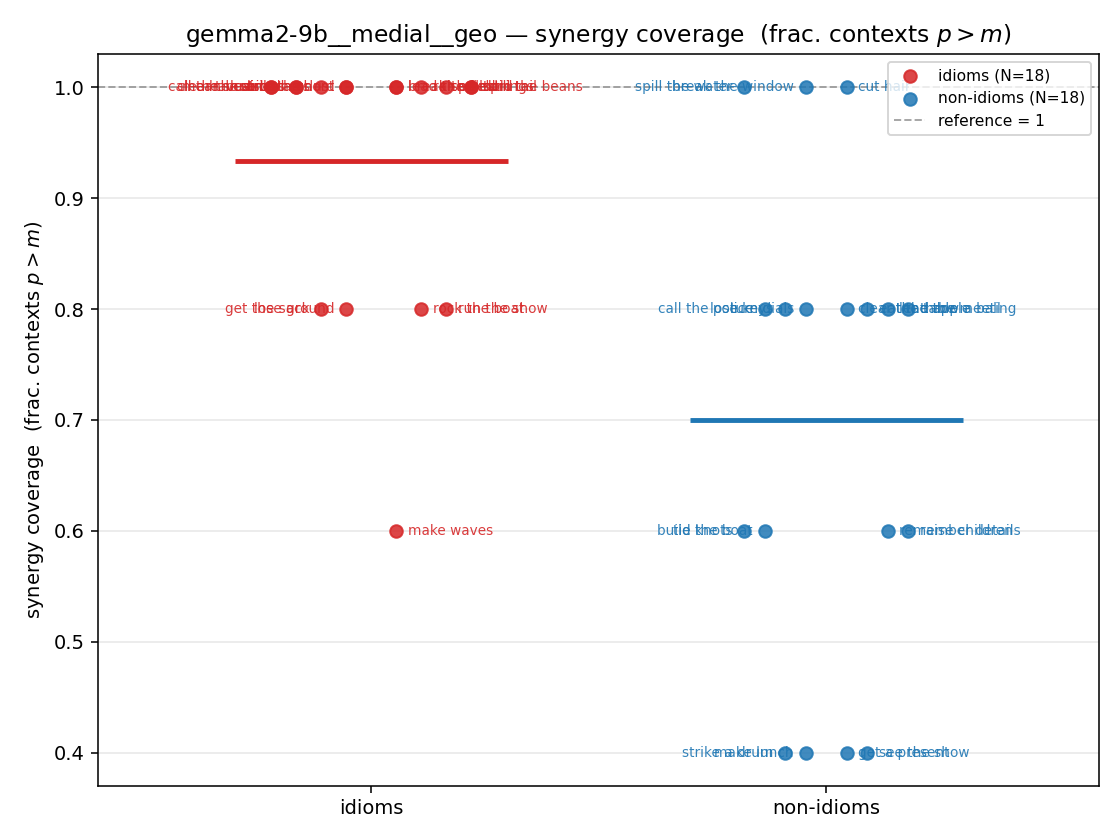 | 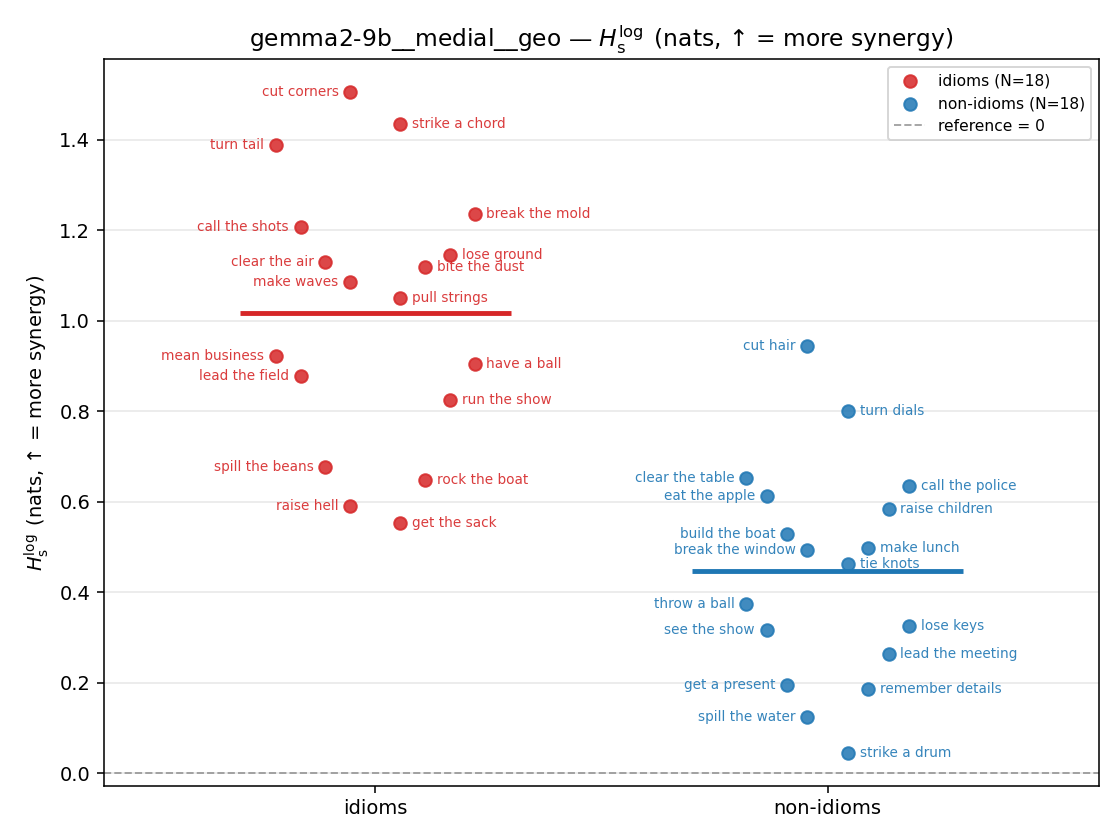 | 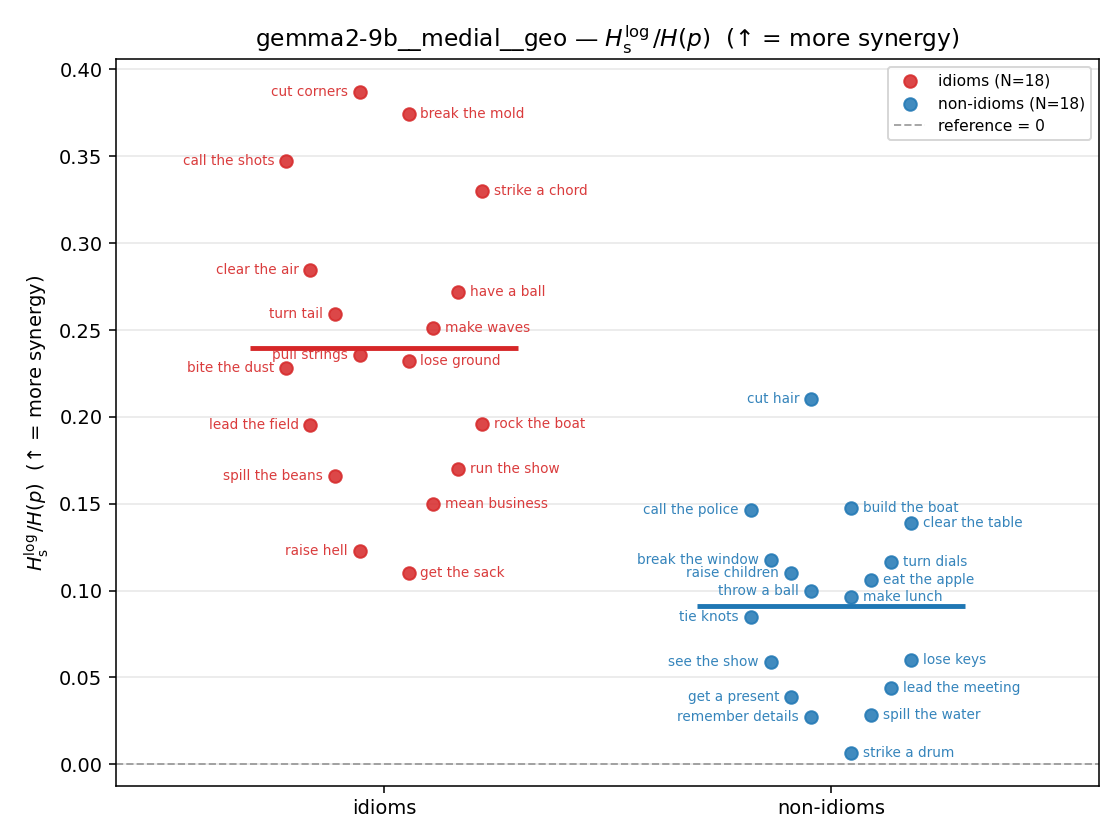 | 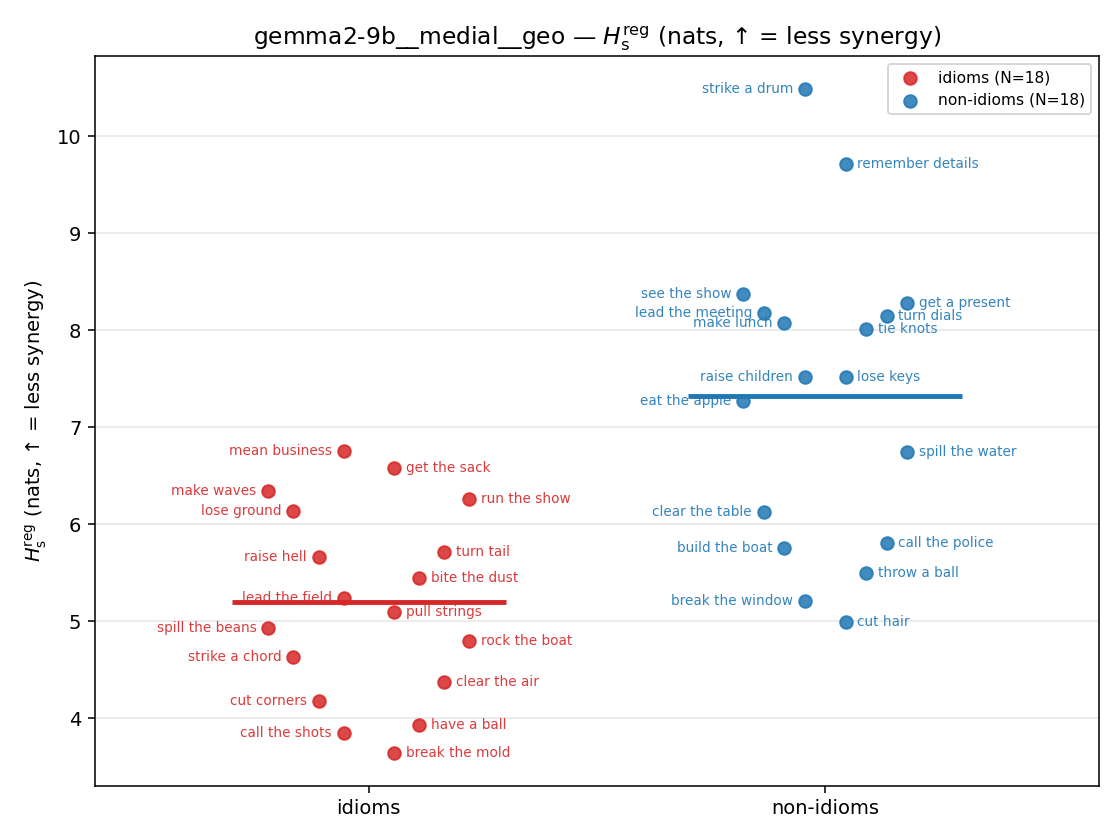 | 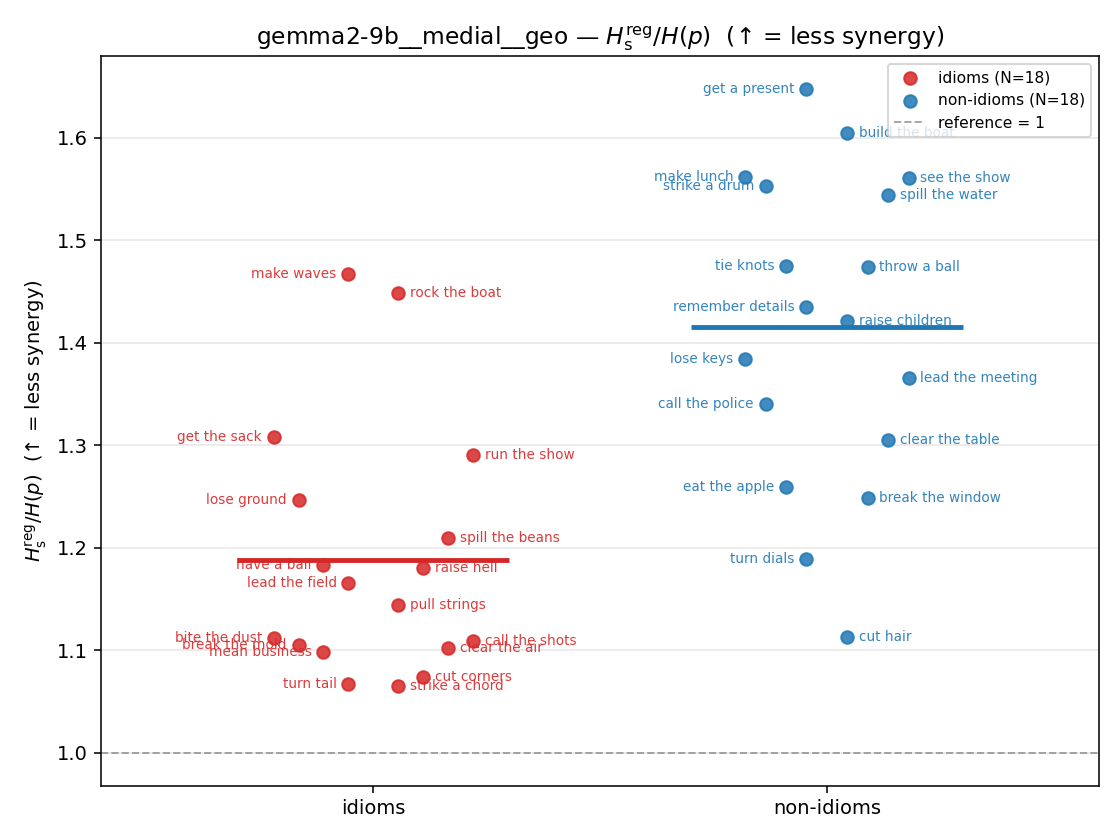 | 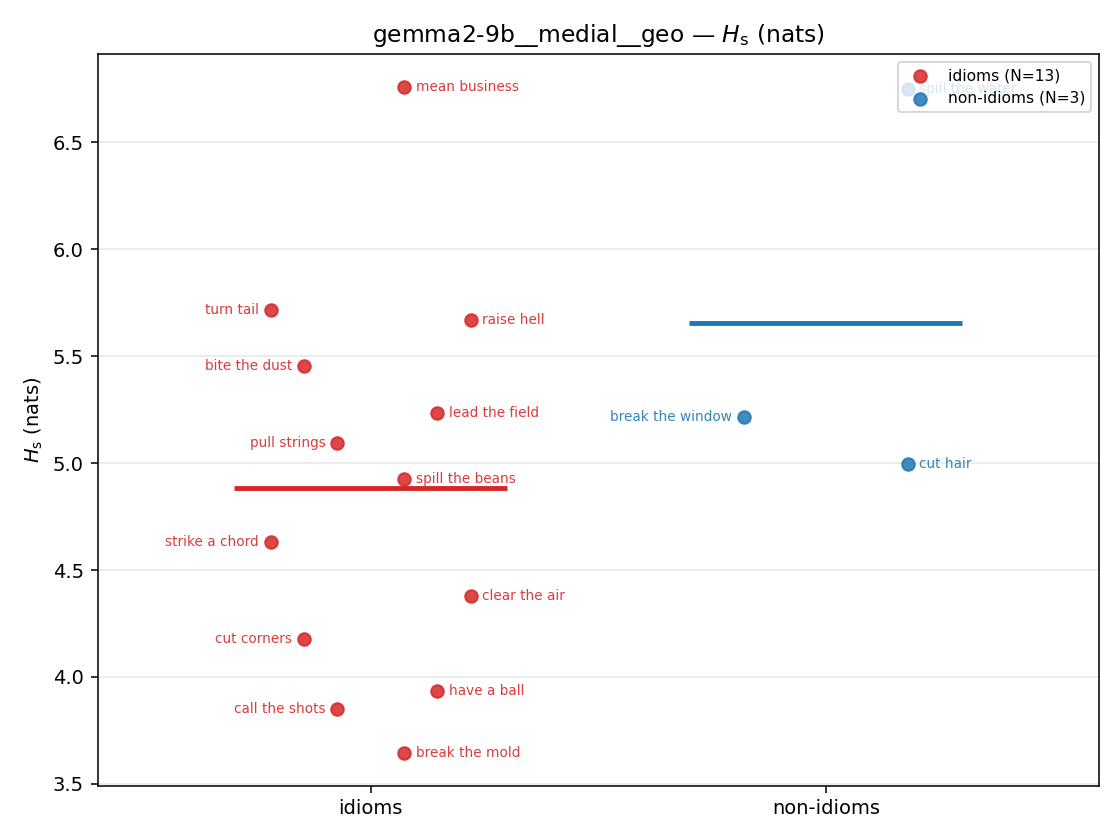 | 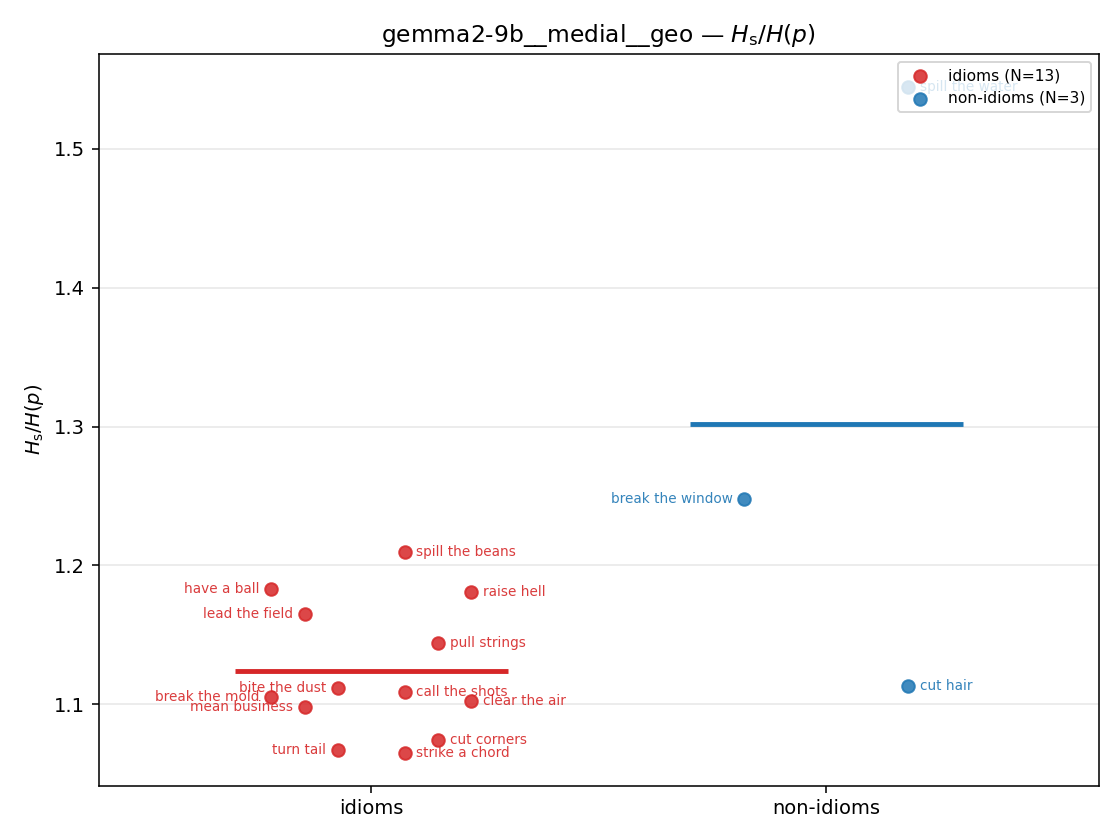 |
| mean ± 95% CI | 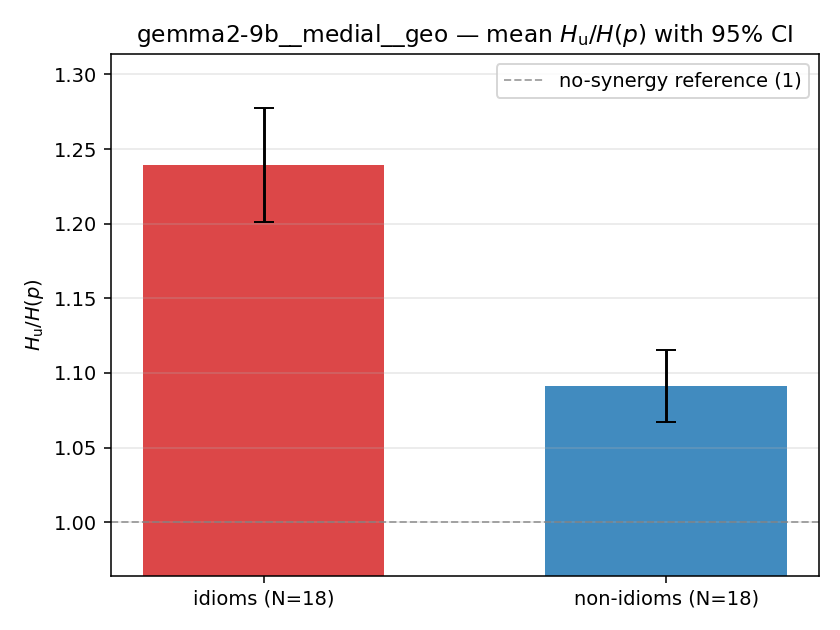 | 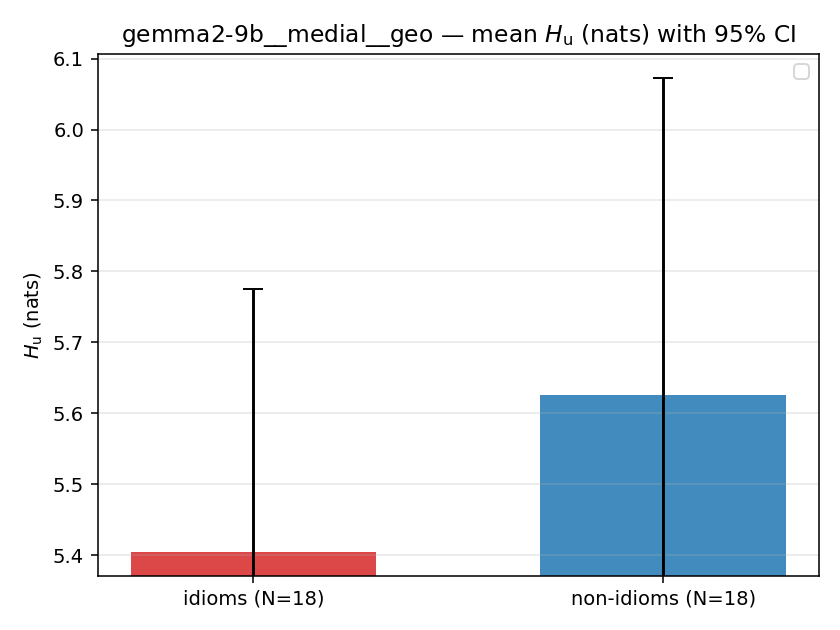 | 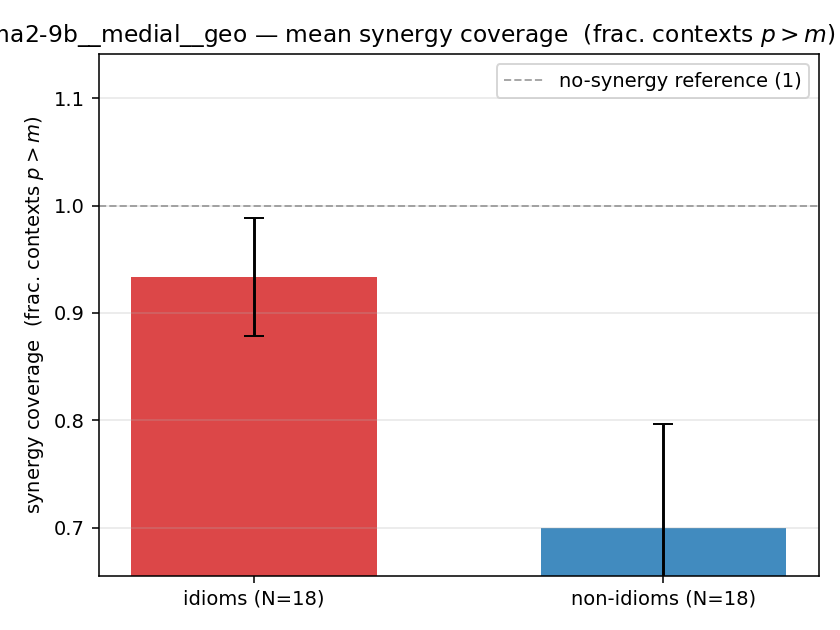 | 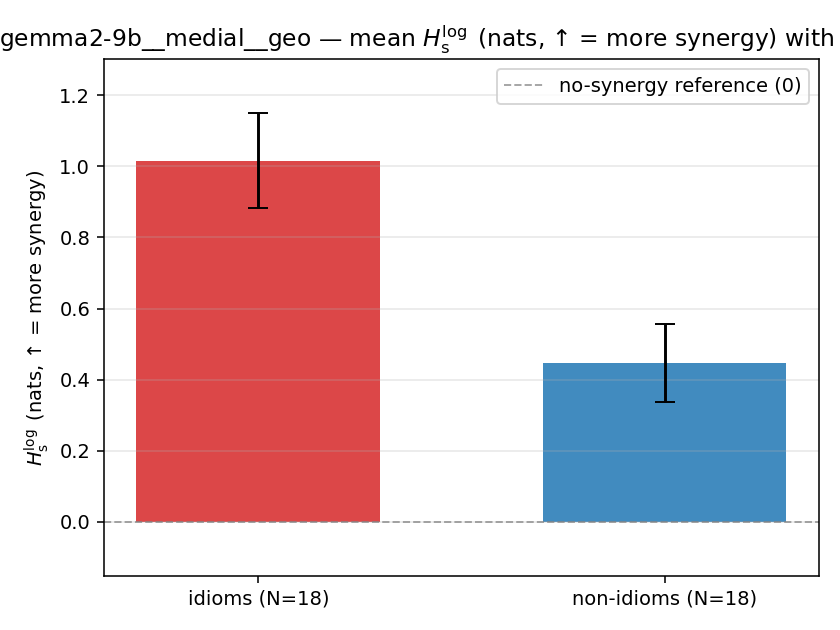 | 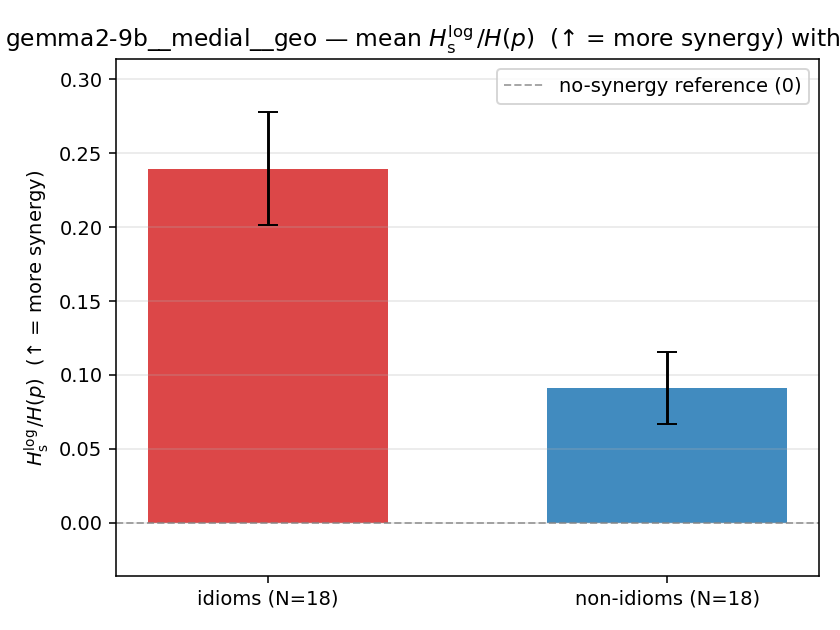 | 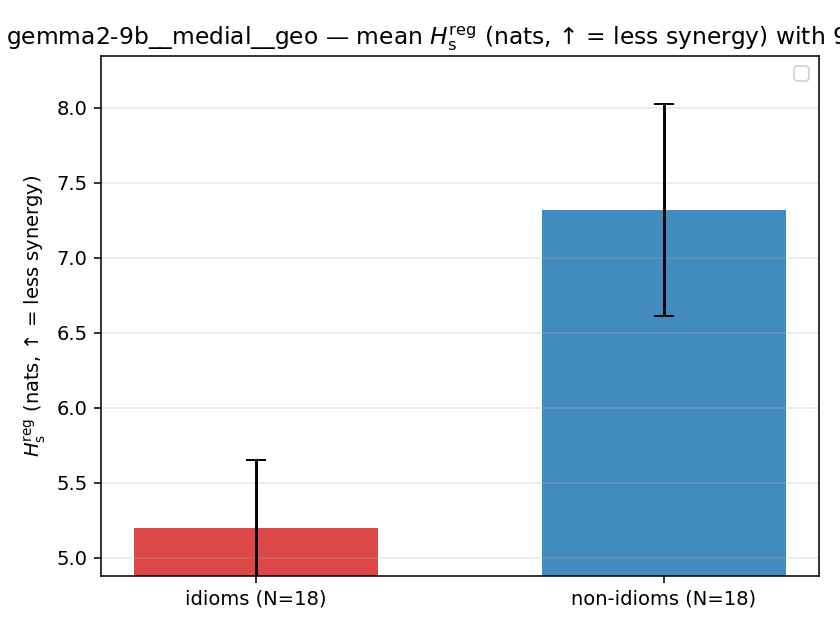 | 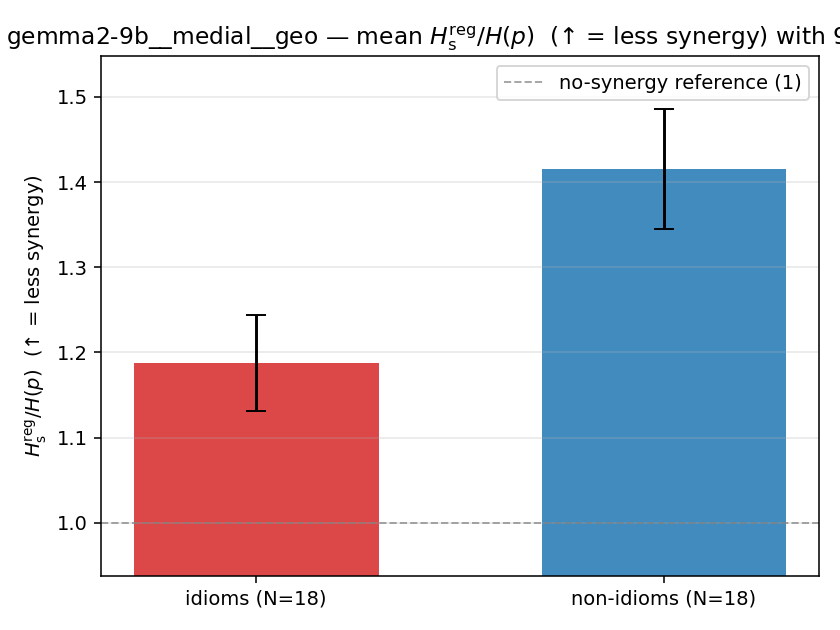 | 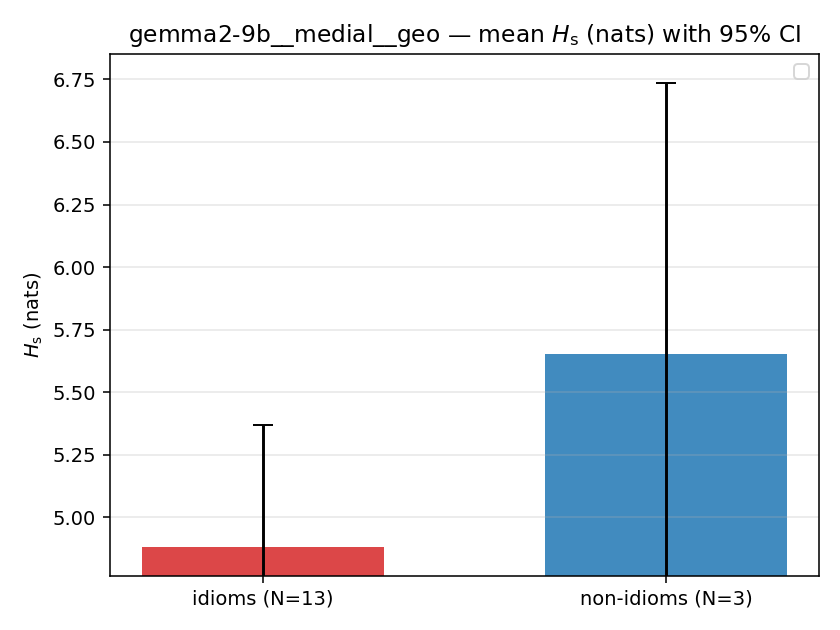 | 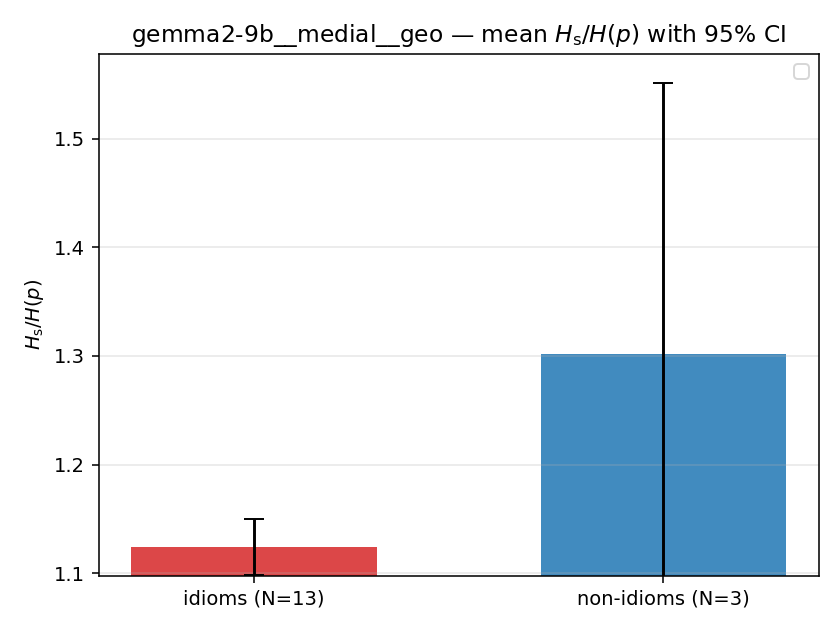 |
| per-idiom (sorted) | 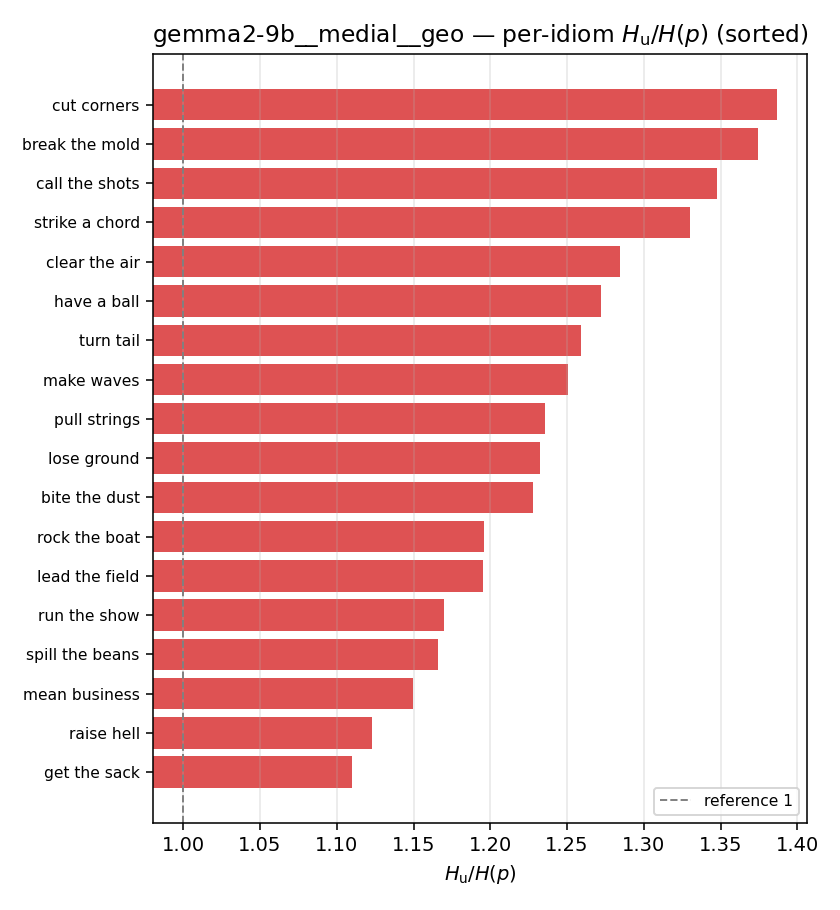 | 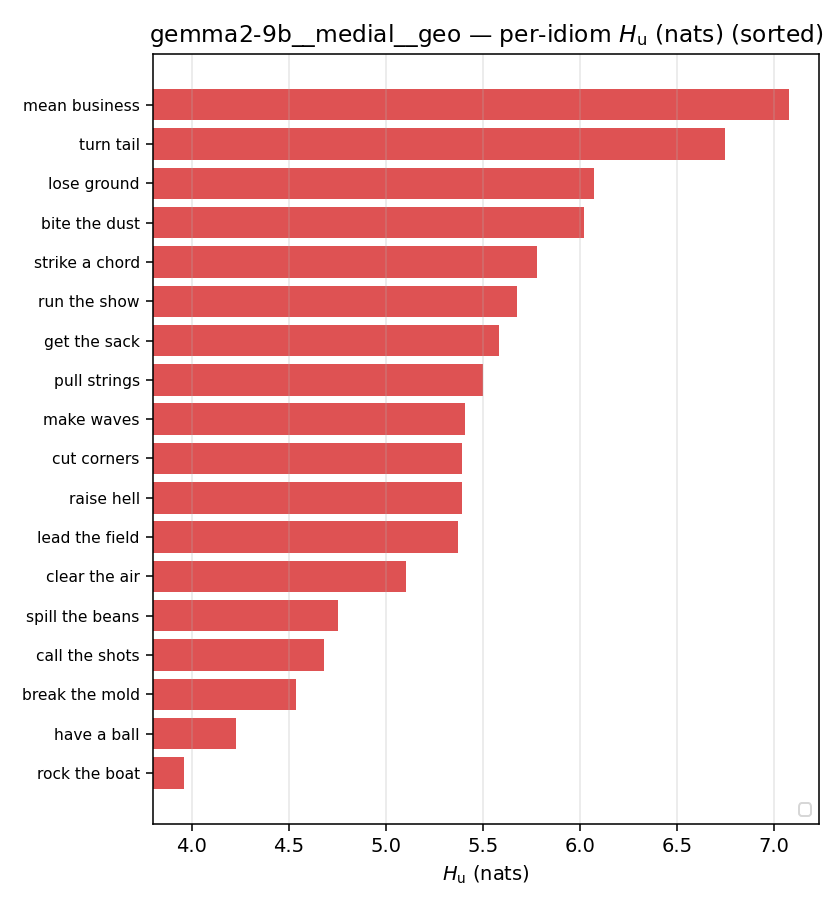 | 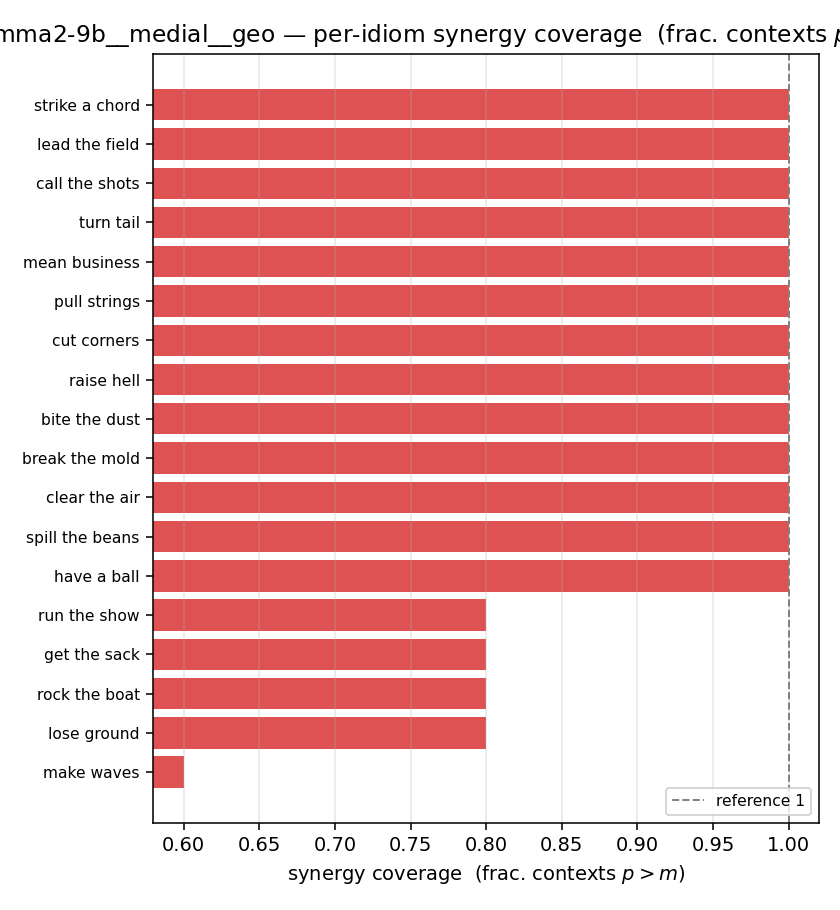 | 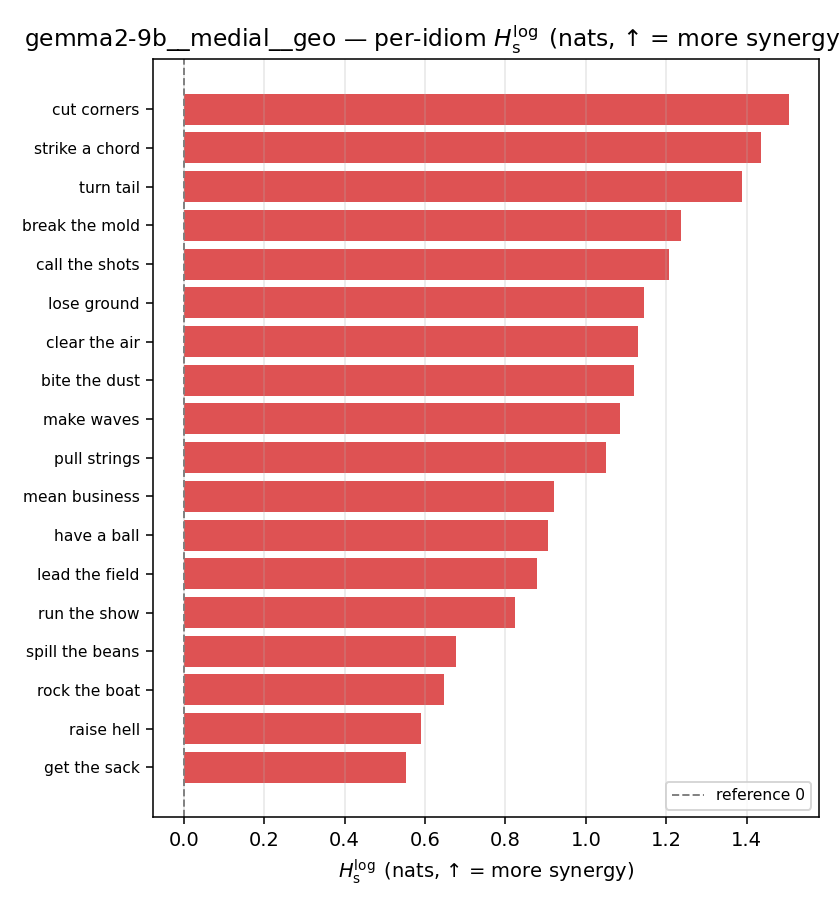 | 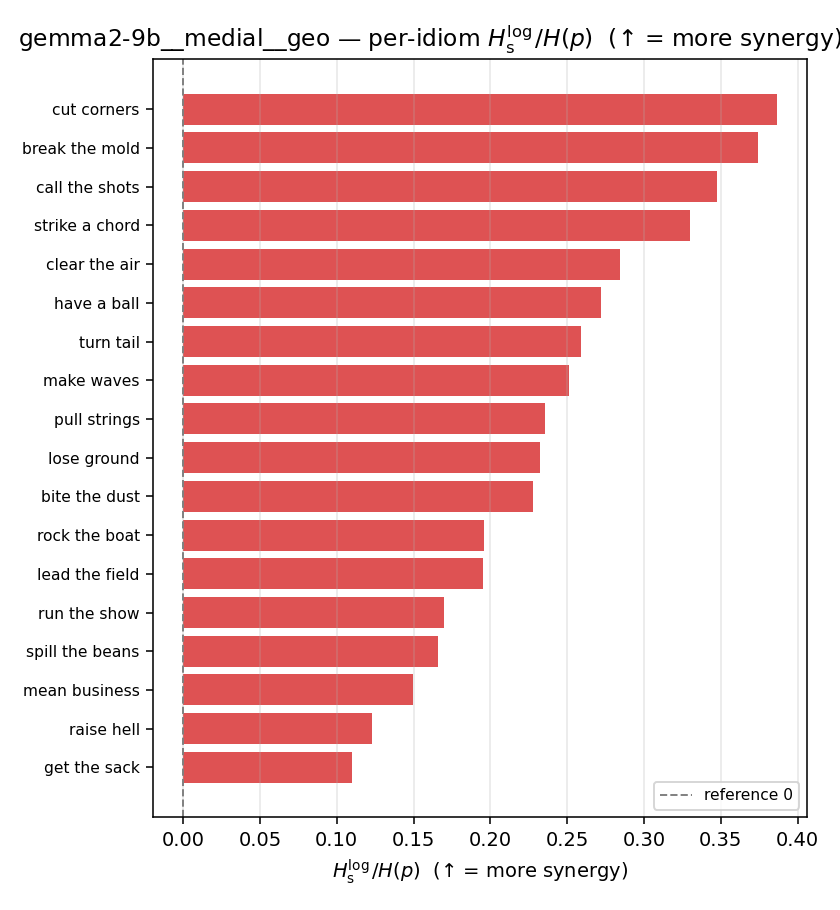 | 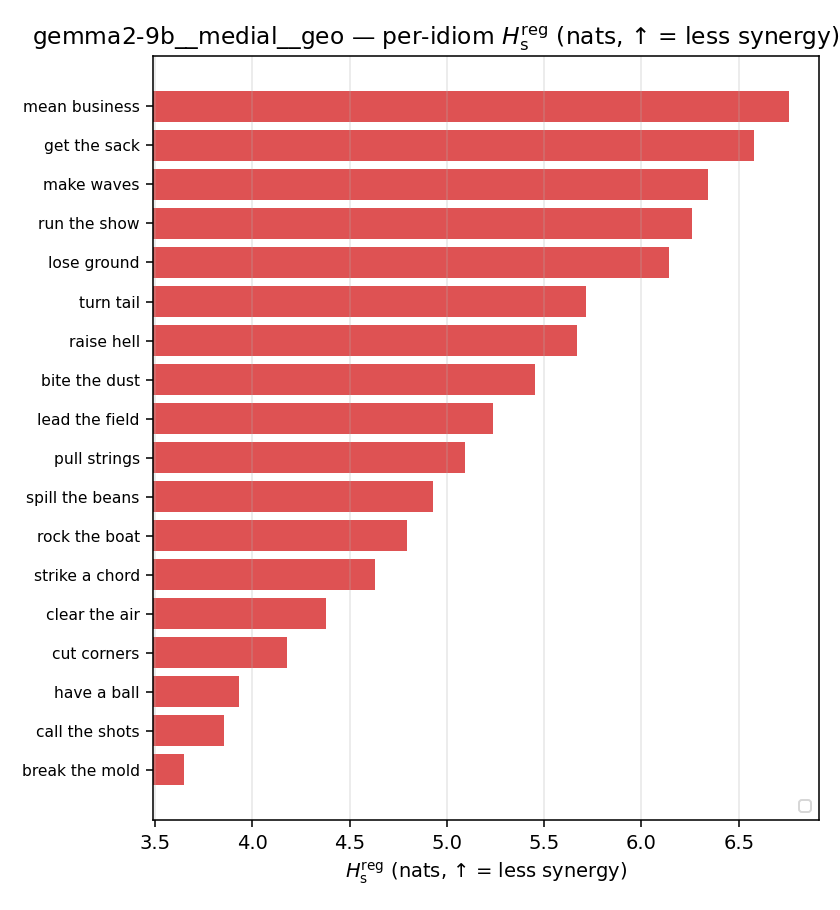 | 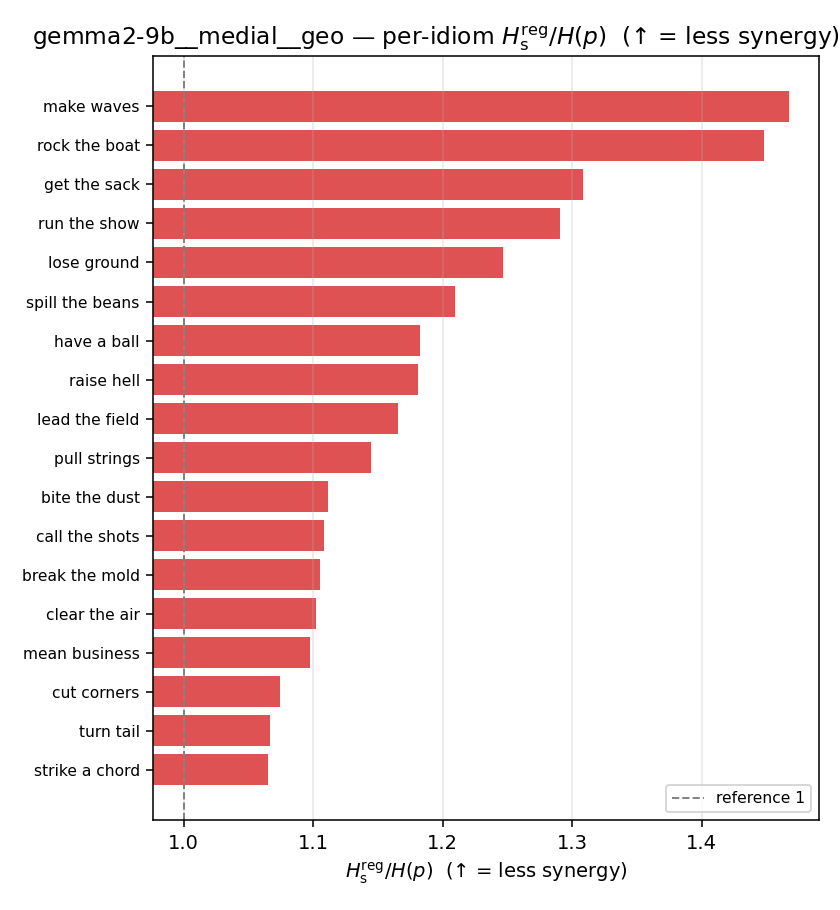 | 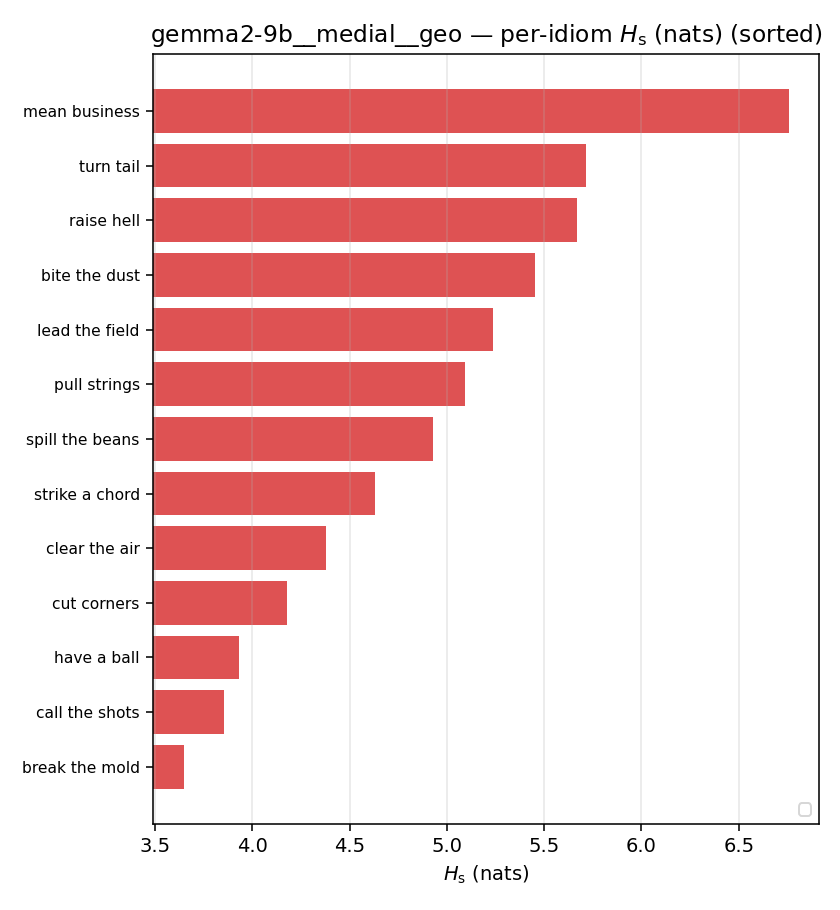 | 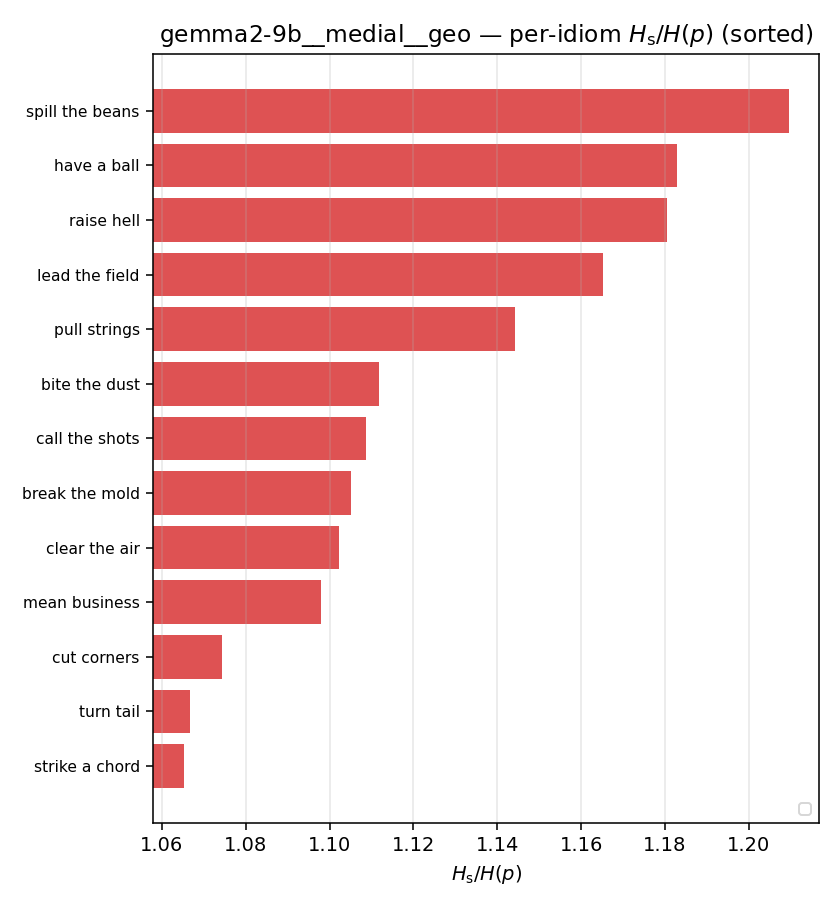 |
gemma2-9b · medial · joint gemma2-9b__medial__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 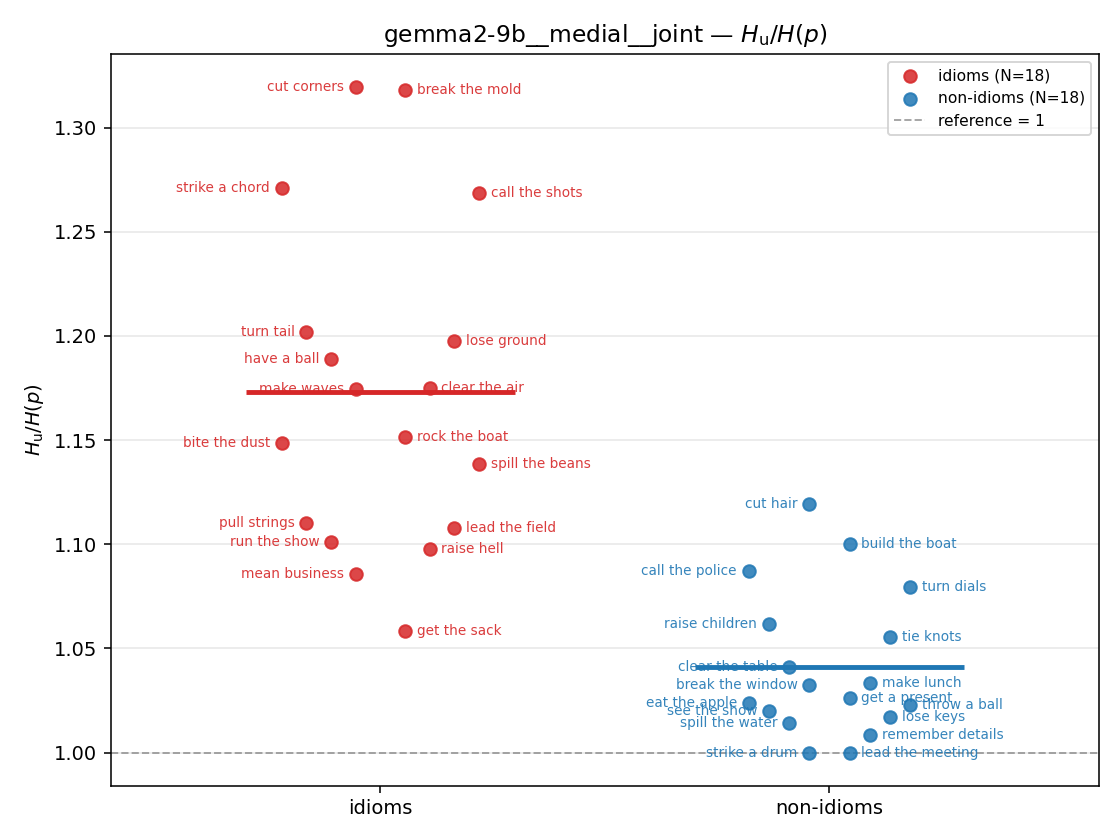 | 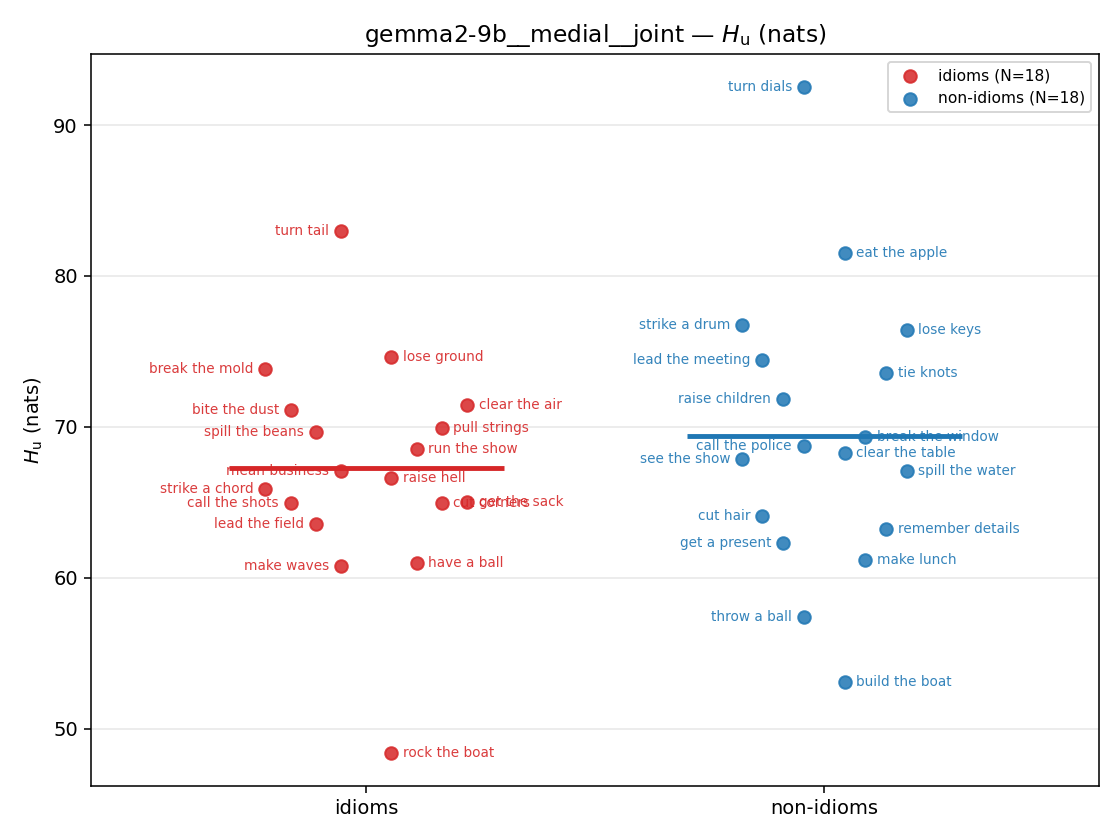 | 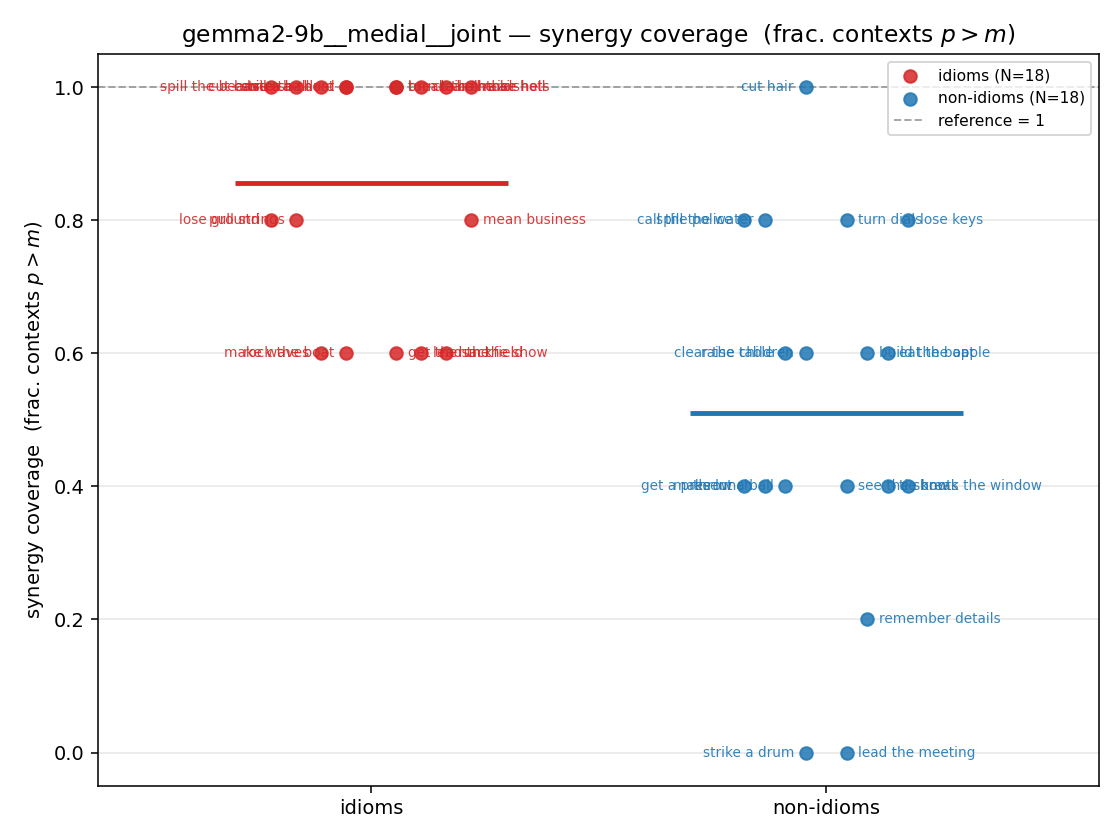 | 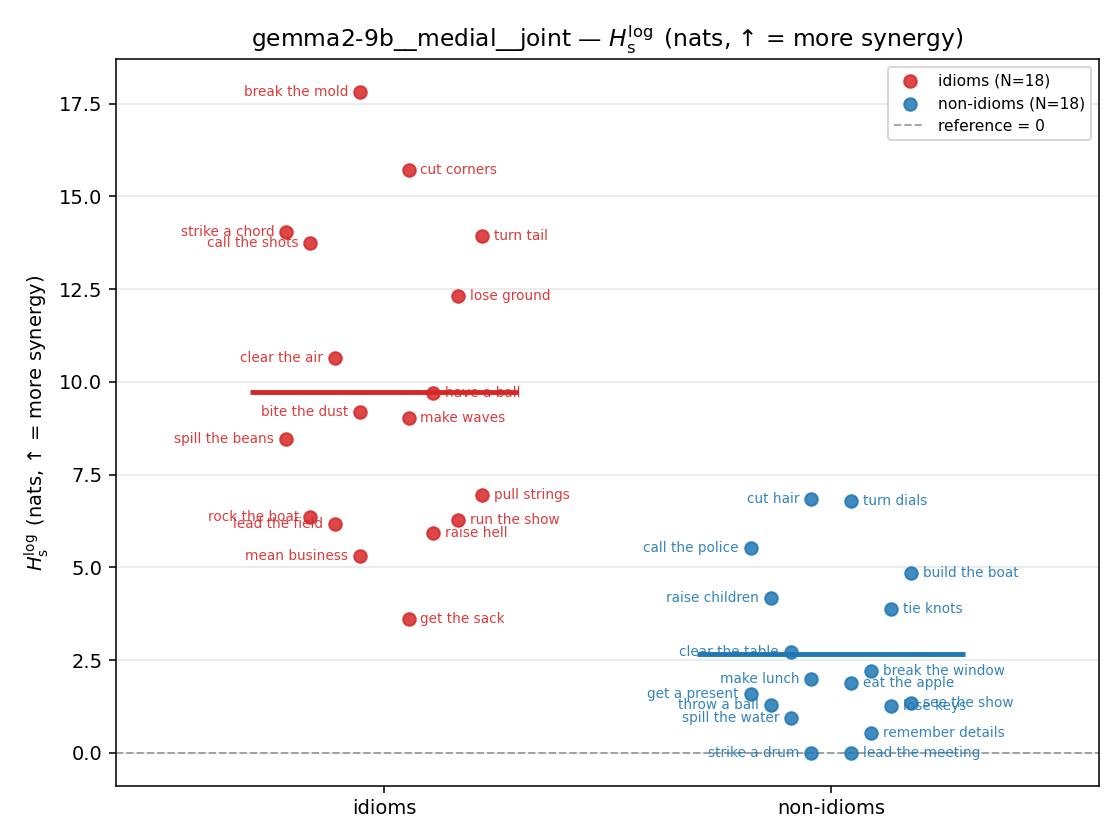 | 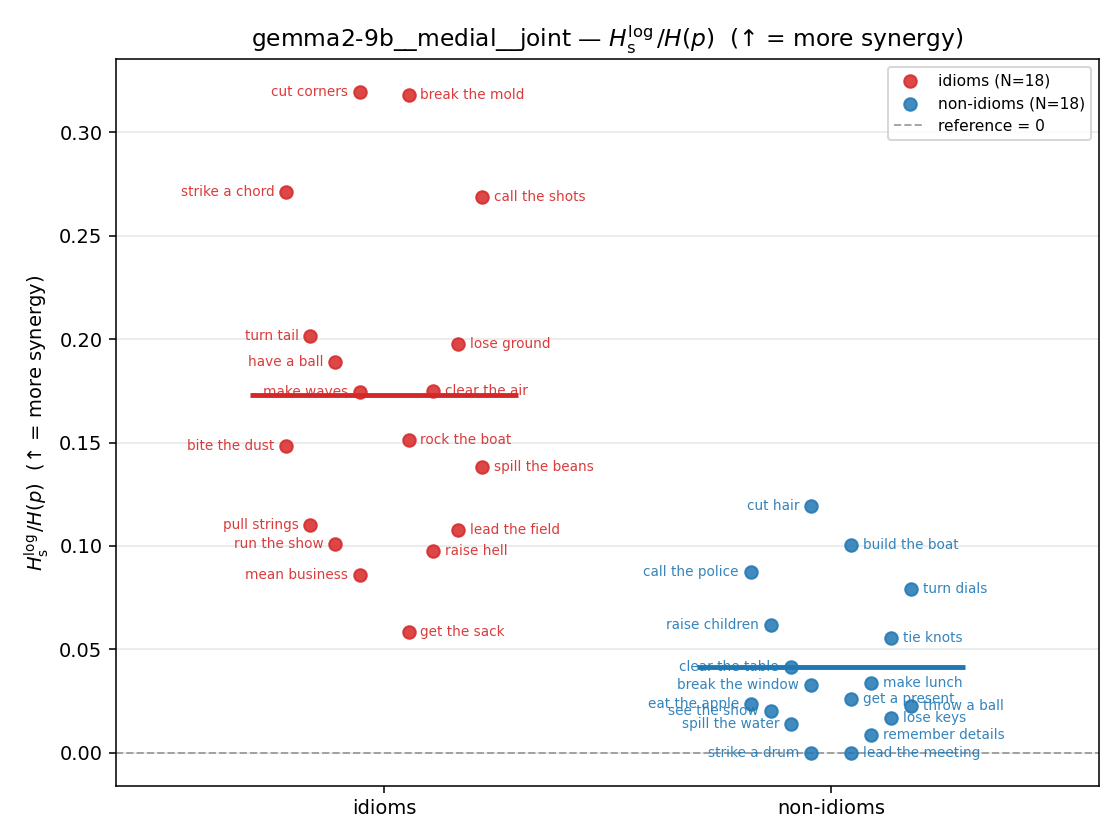 | 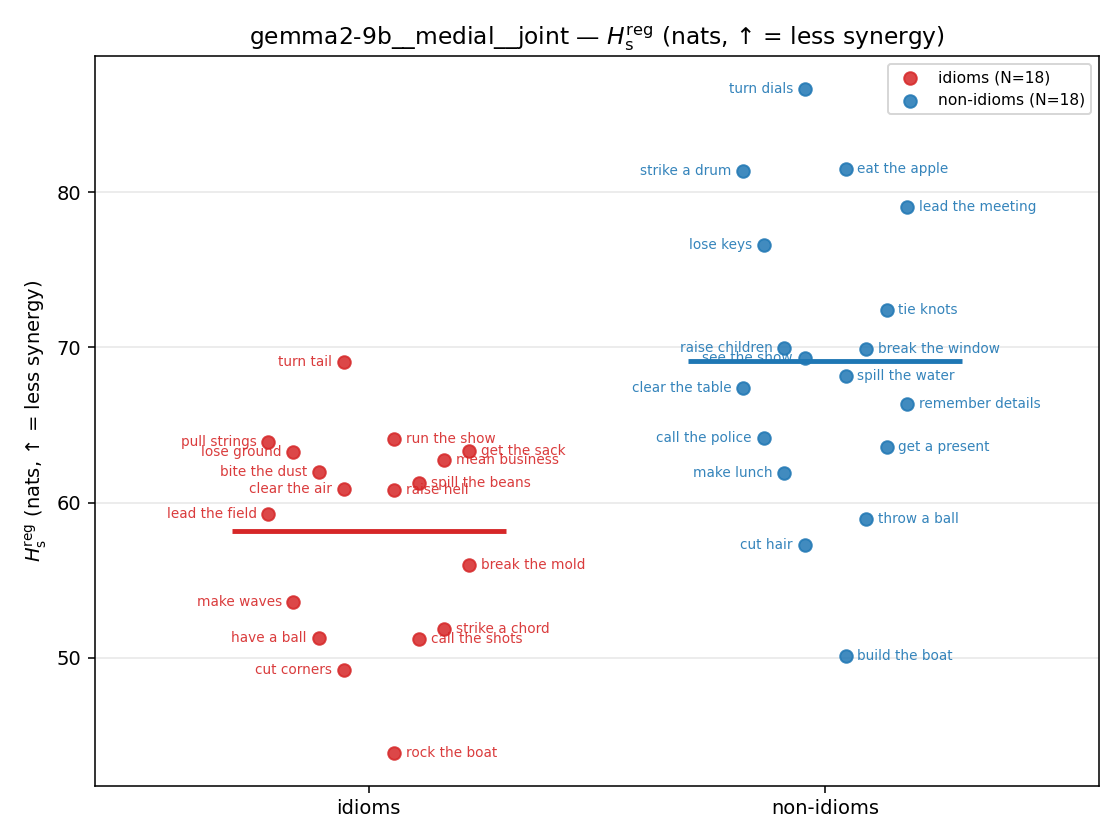 | 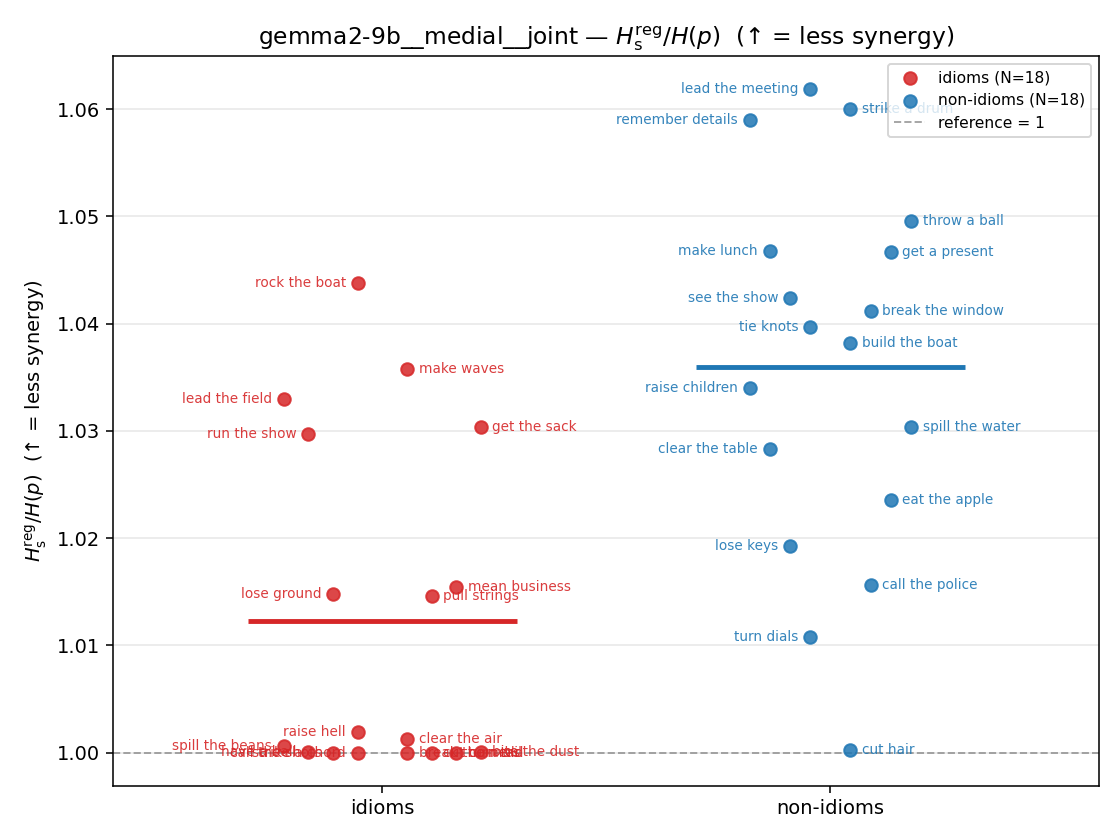 | 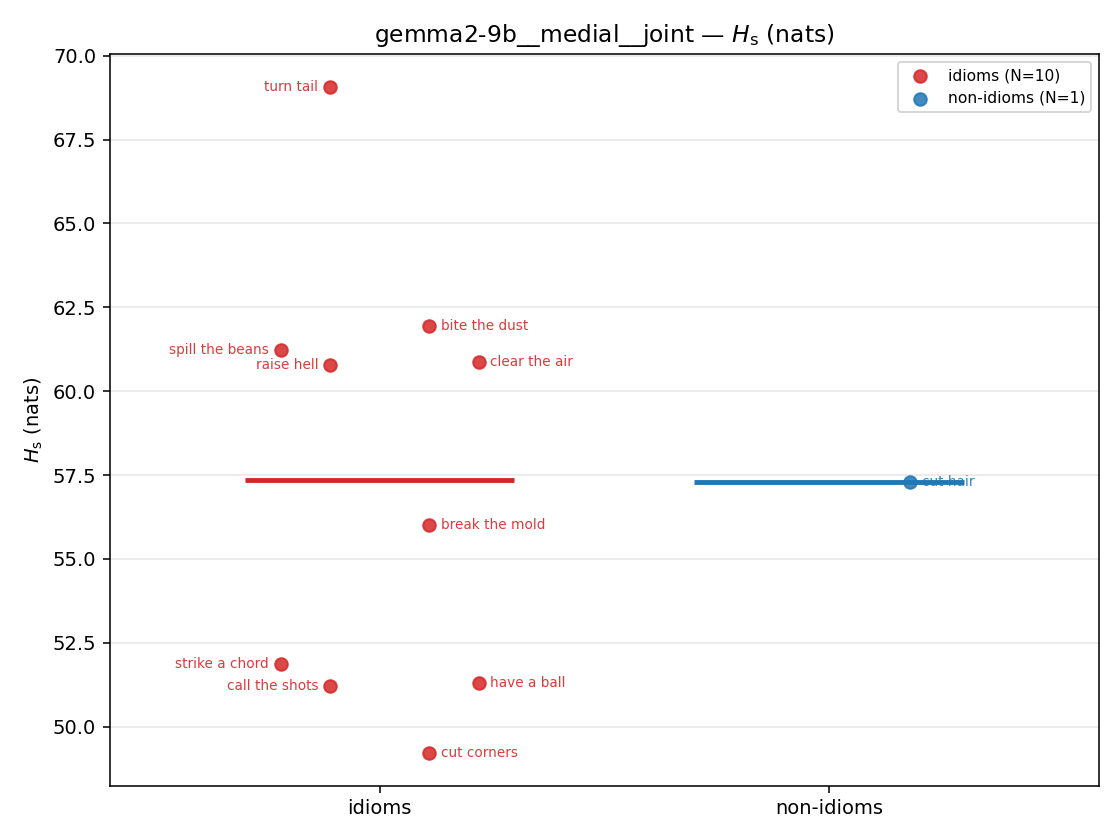 | 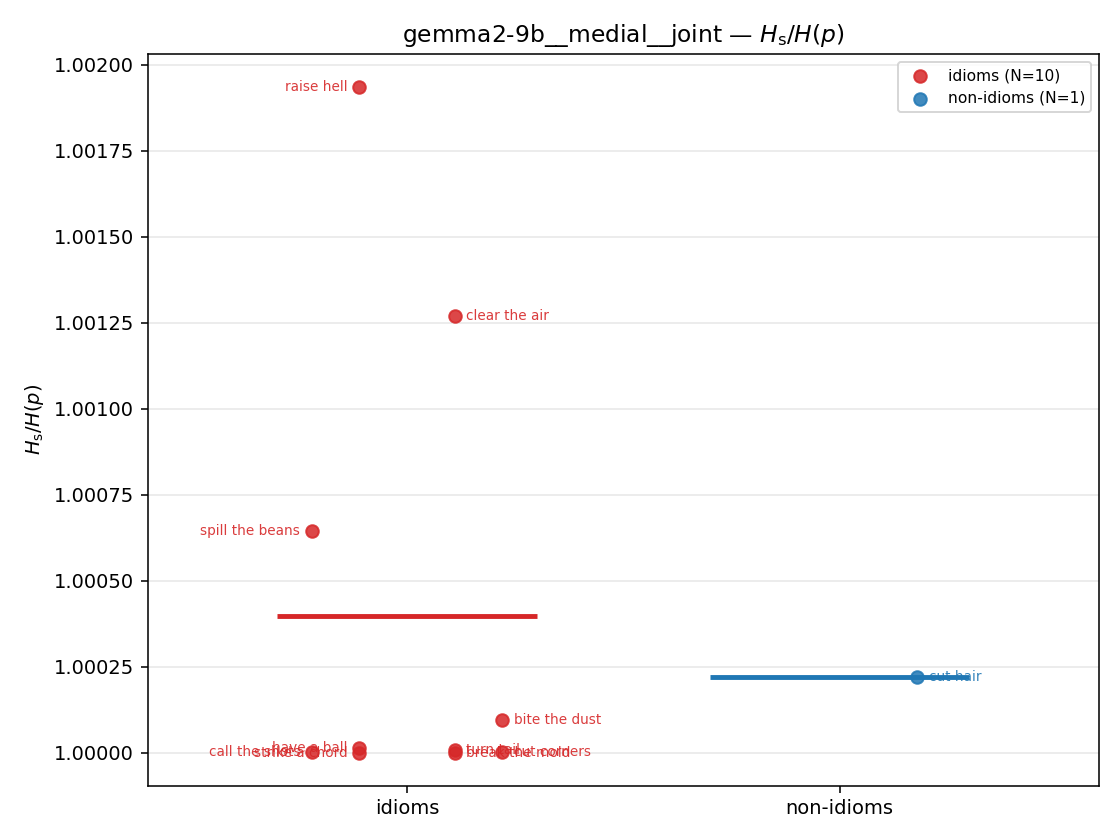 |
| mean ± 95% CI | 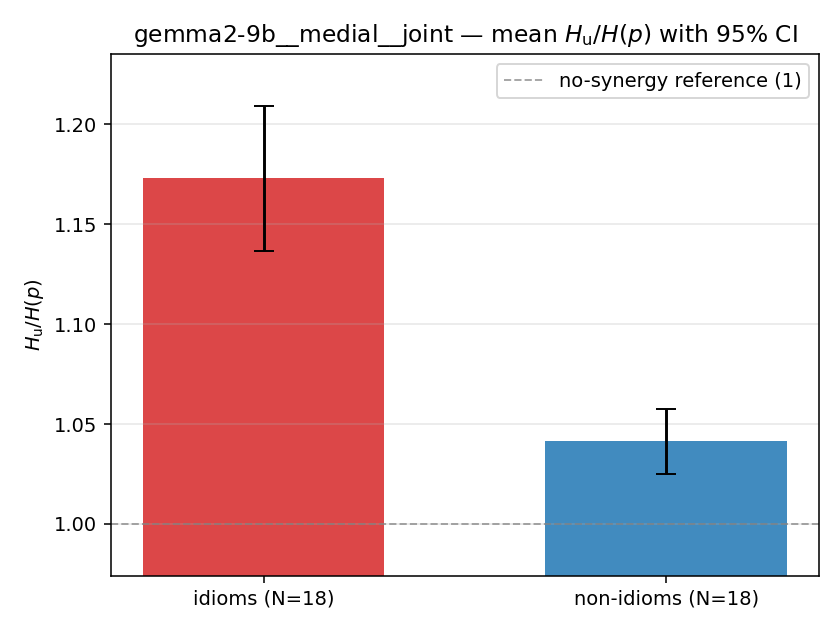 | 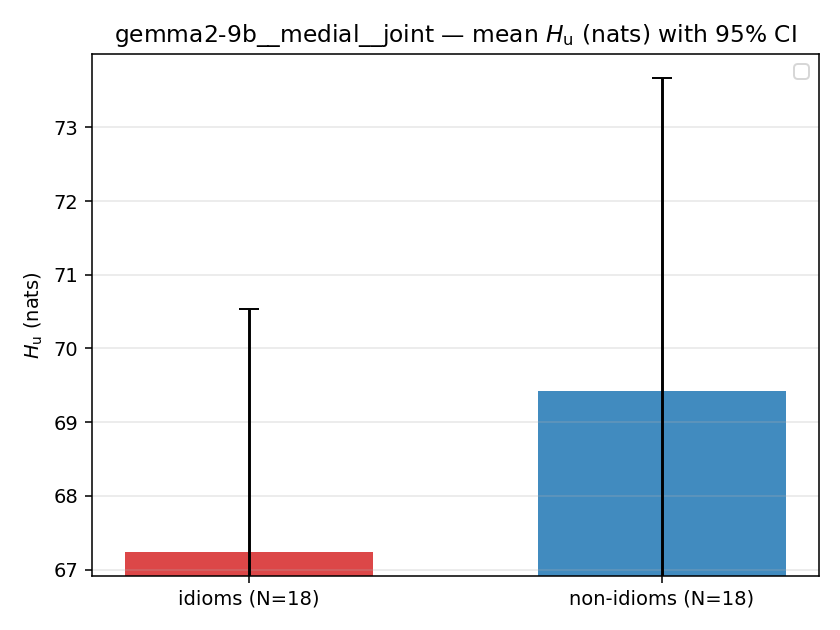 | 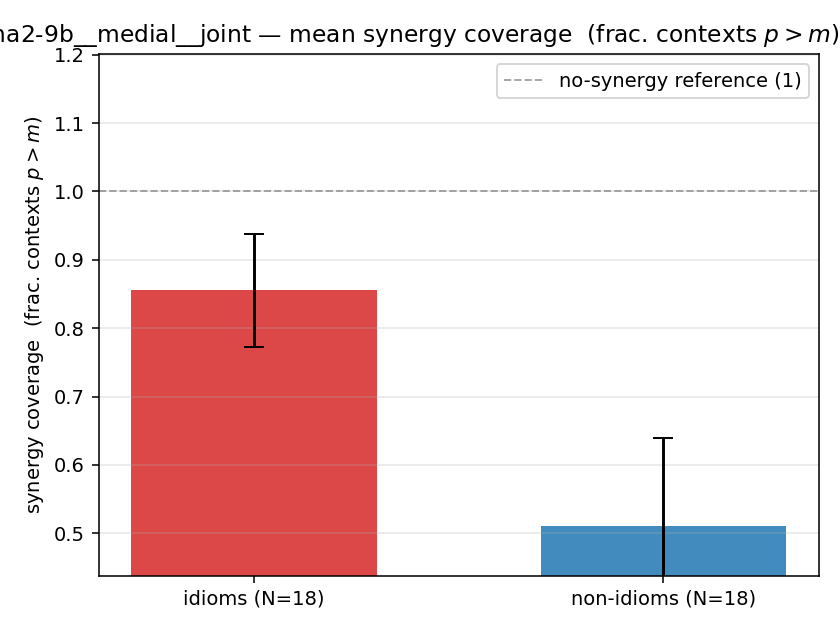 | 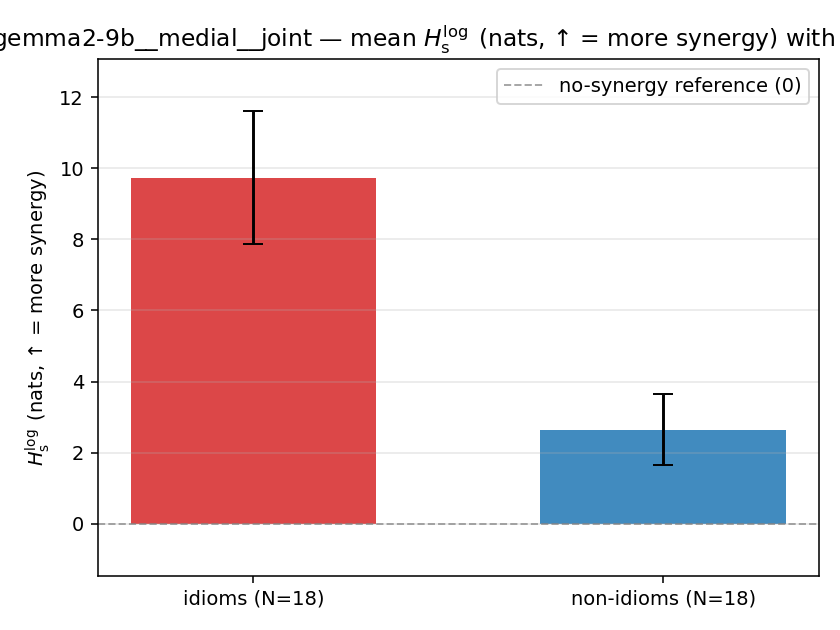 | 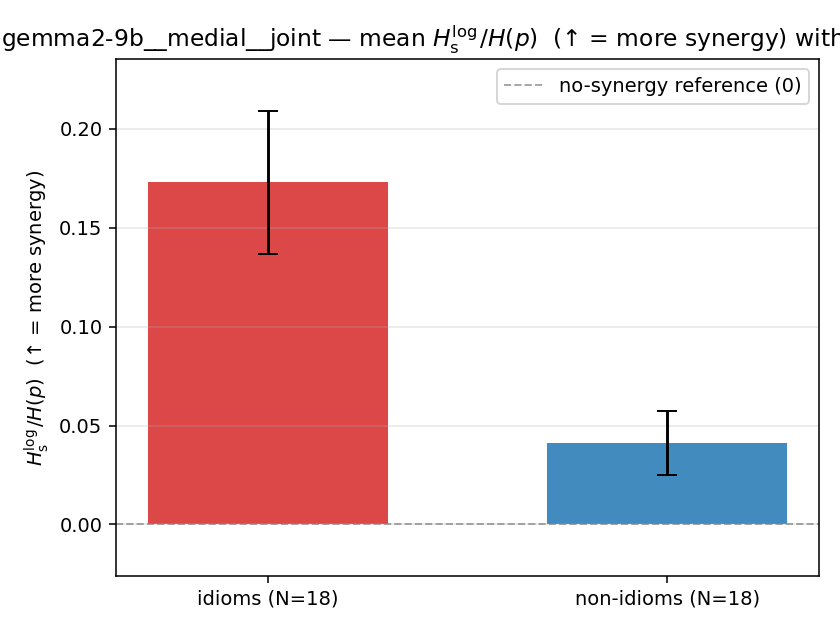 | 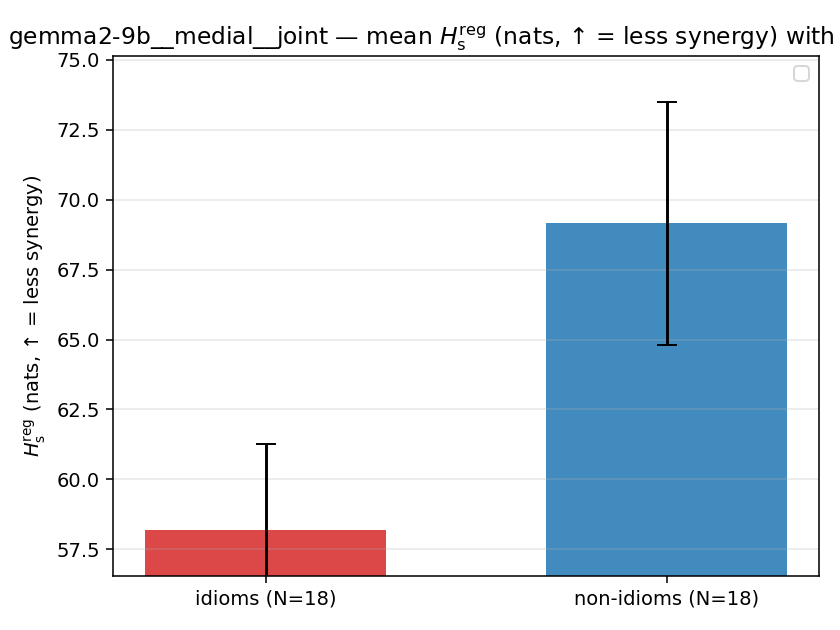 | 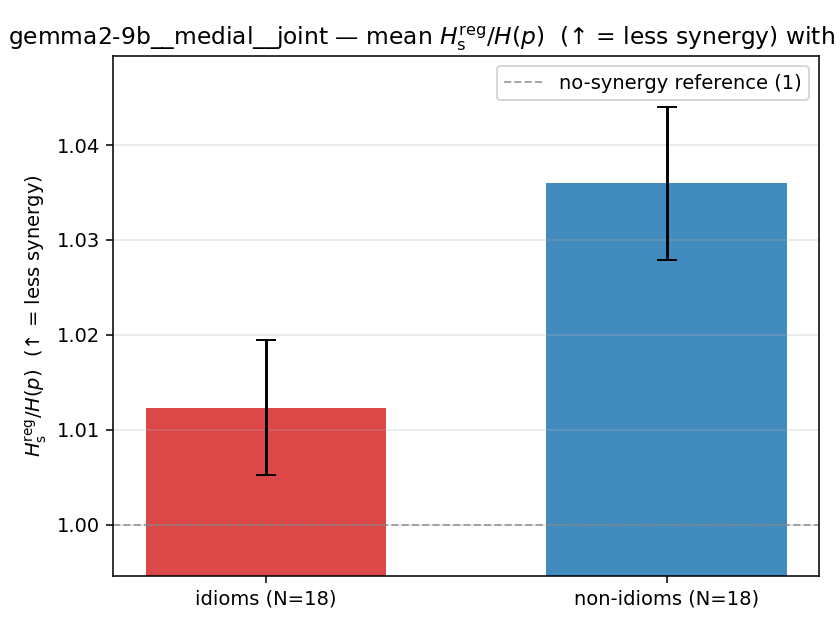 |  | 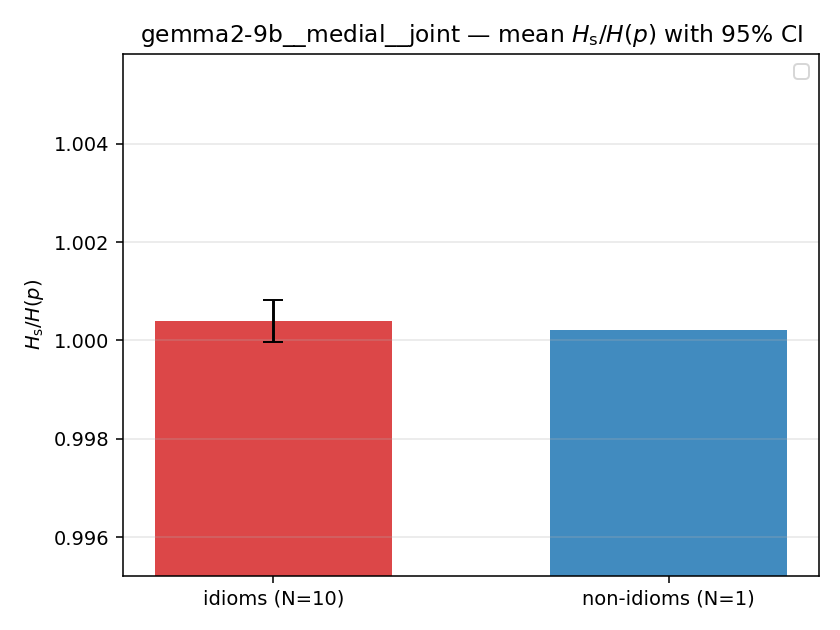 |
| per-idiom (sorted) | 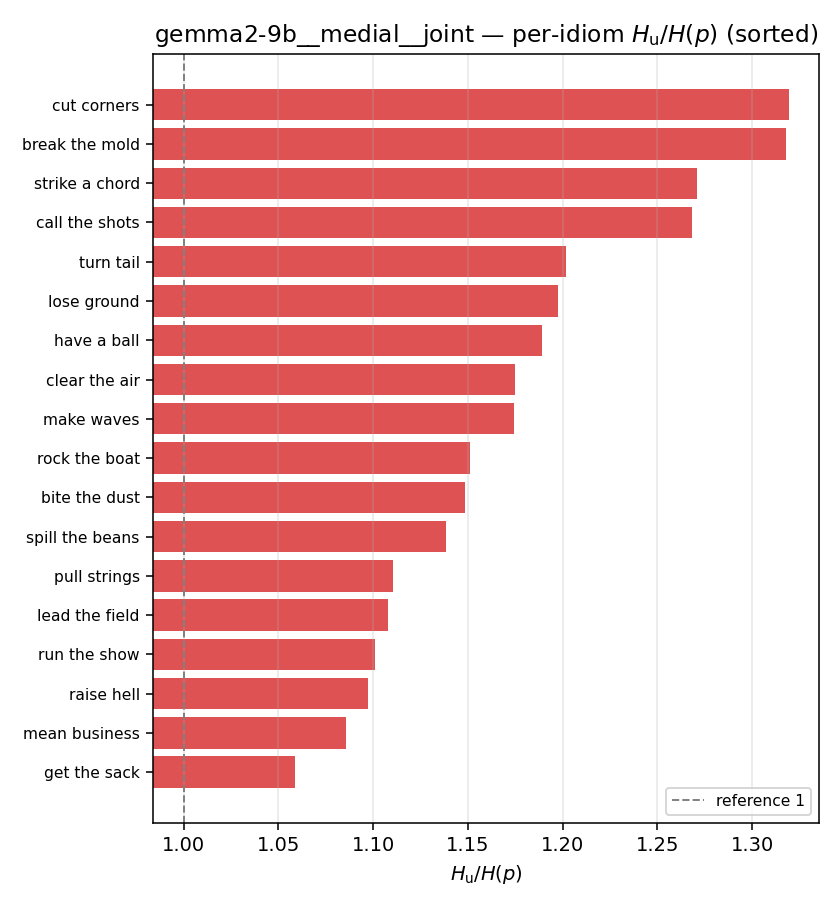 | 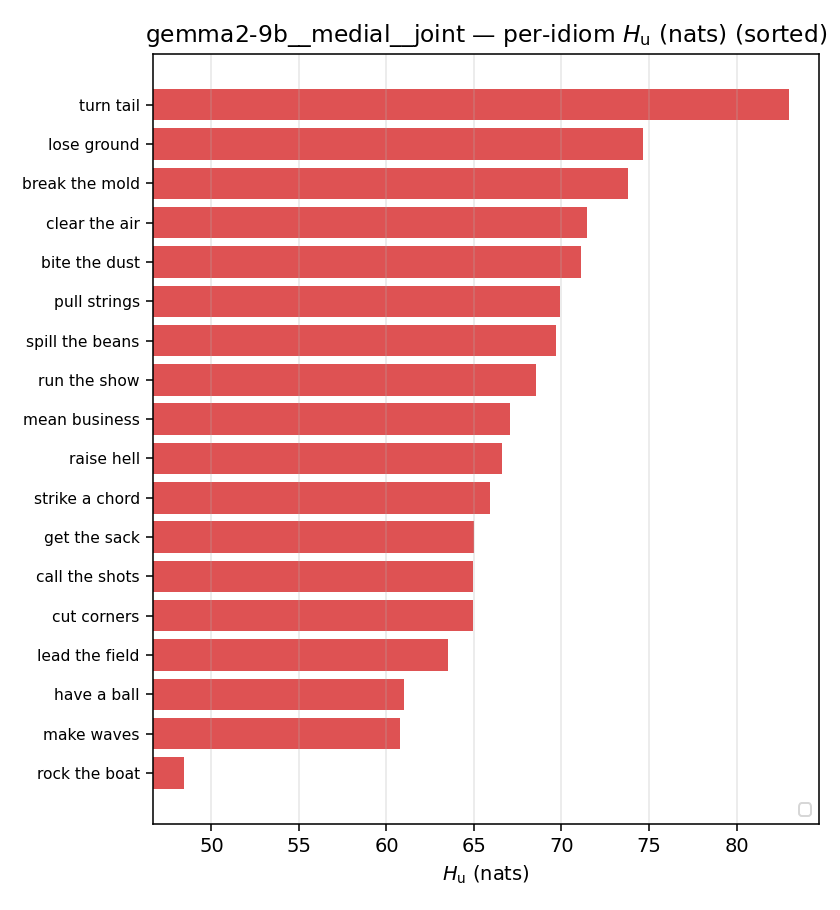 | 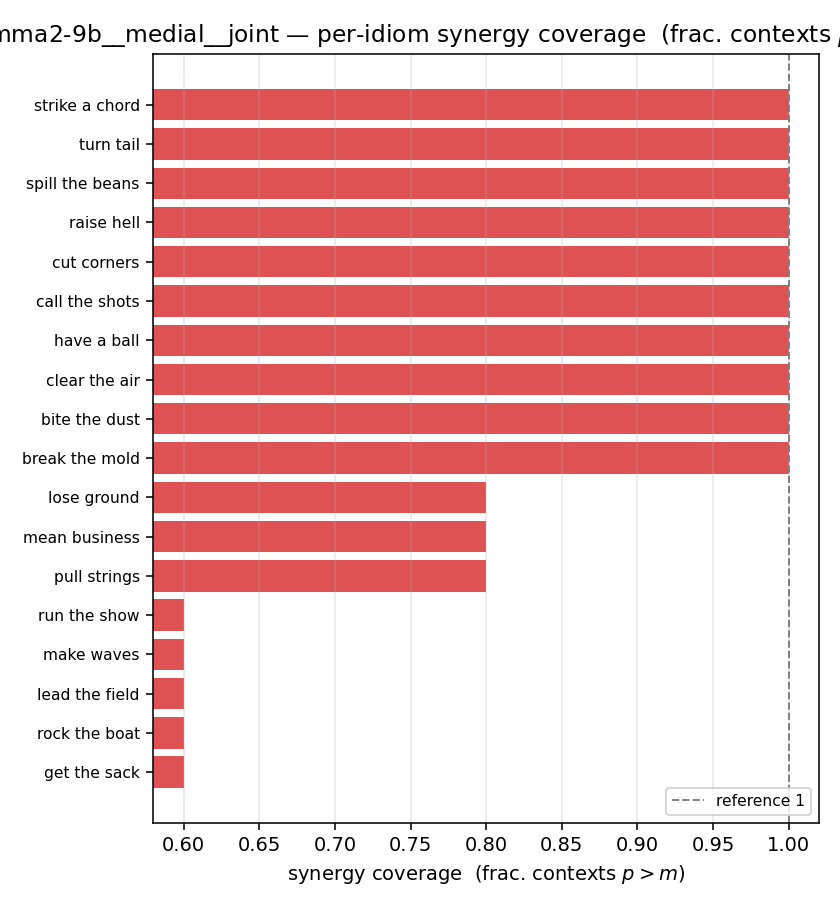 | 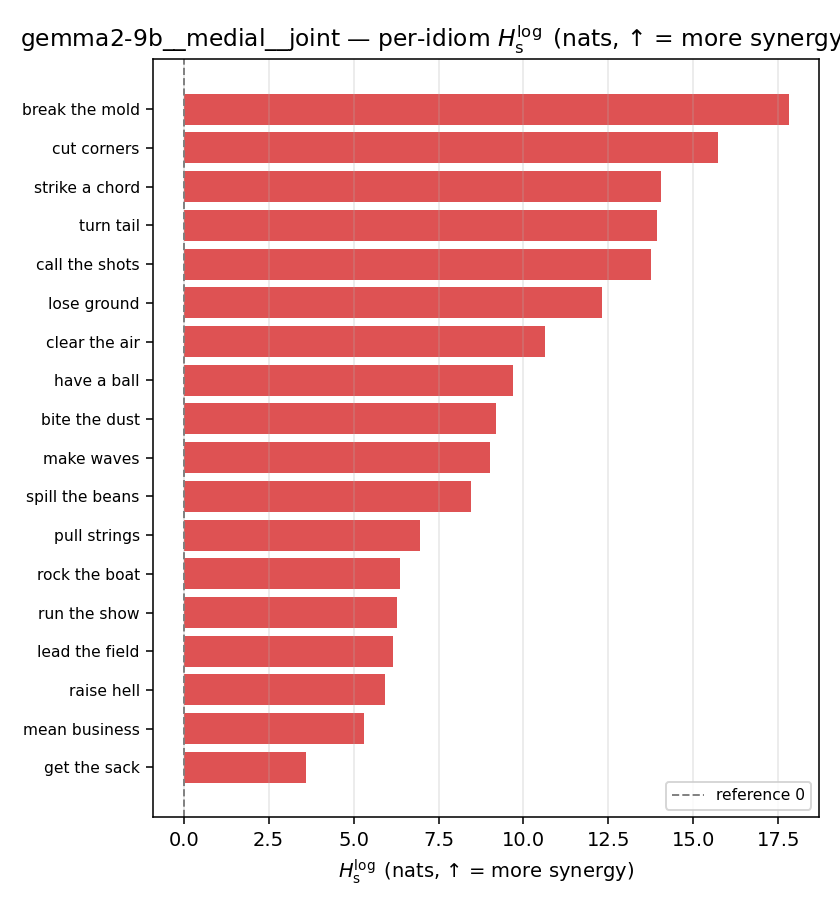 | 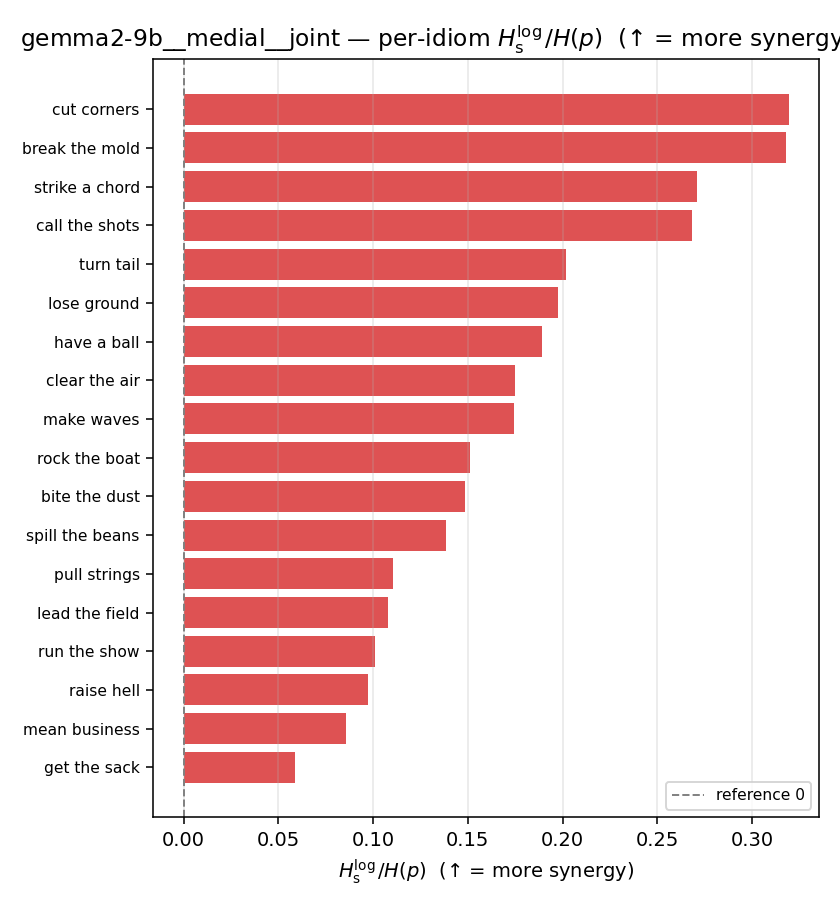 | 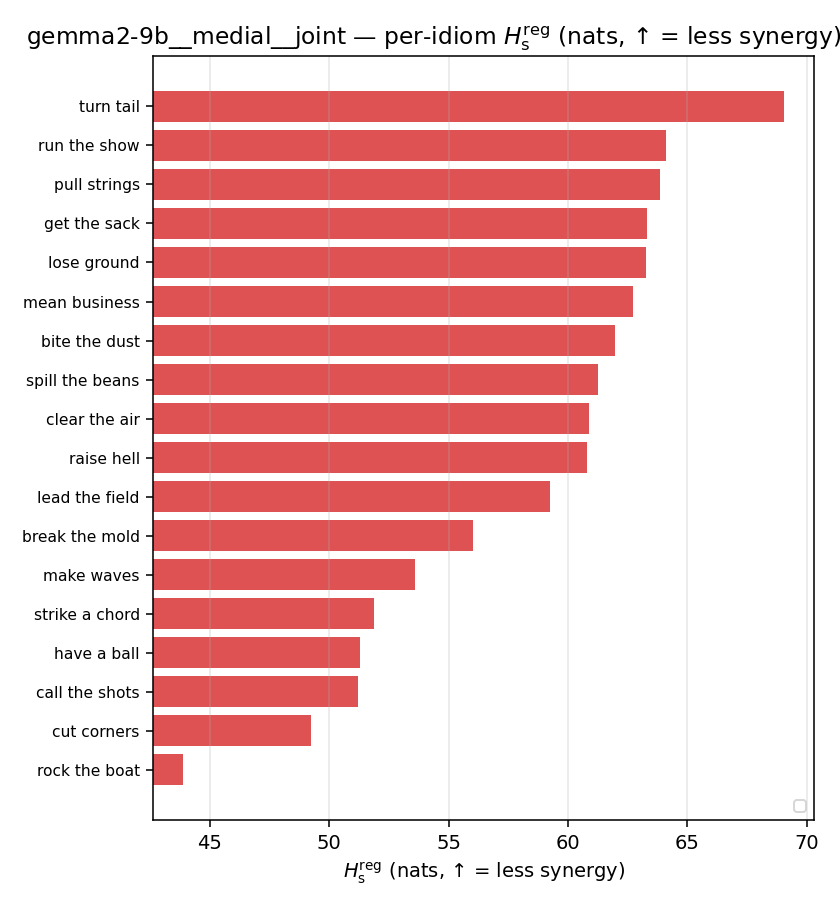 | 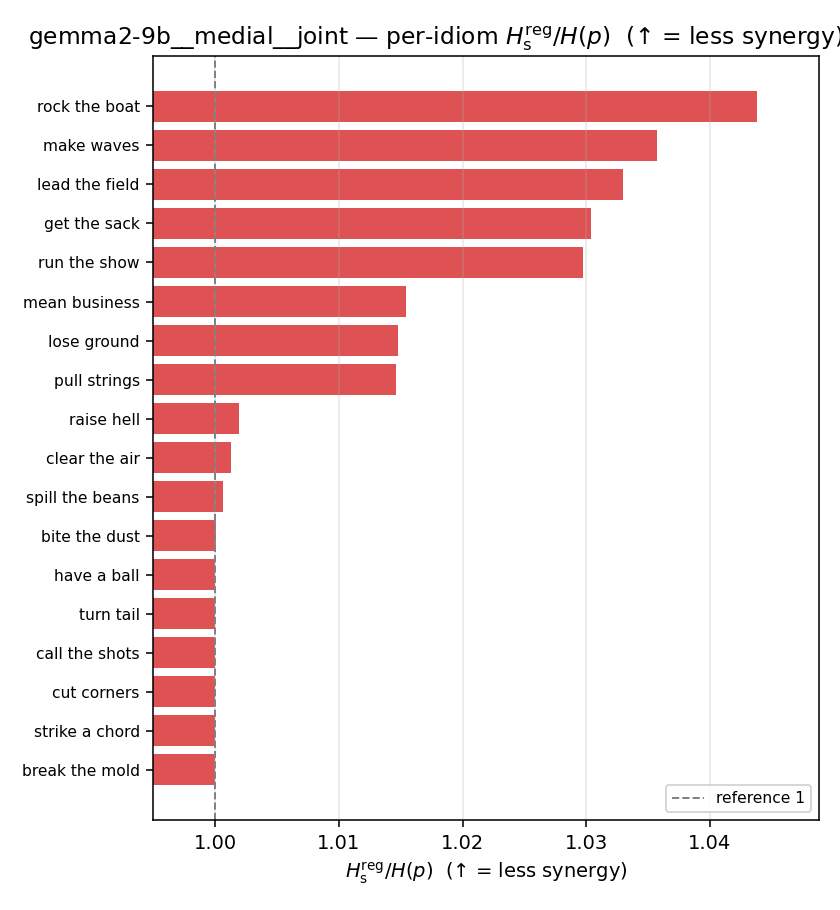 | 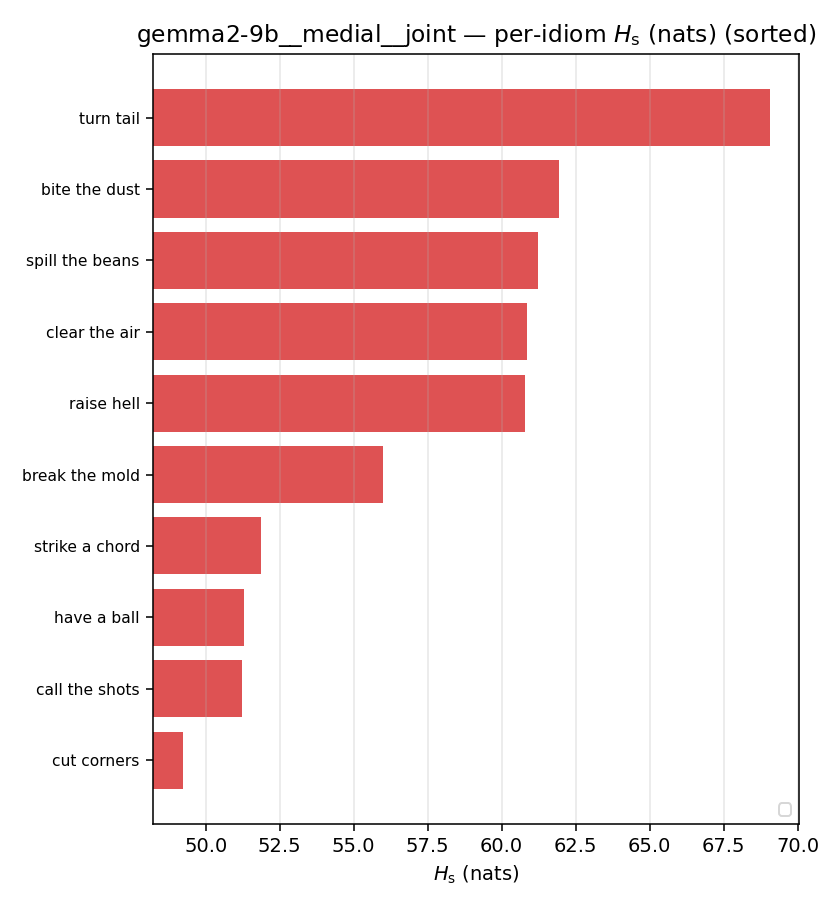 | 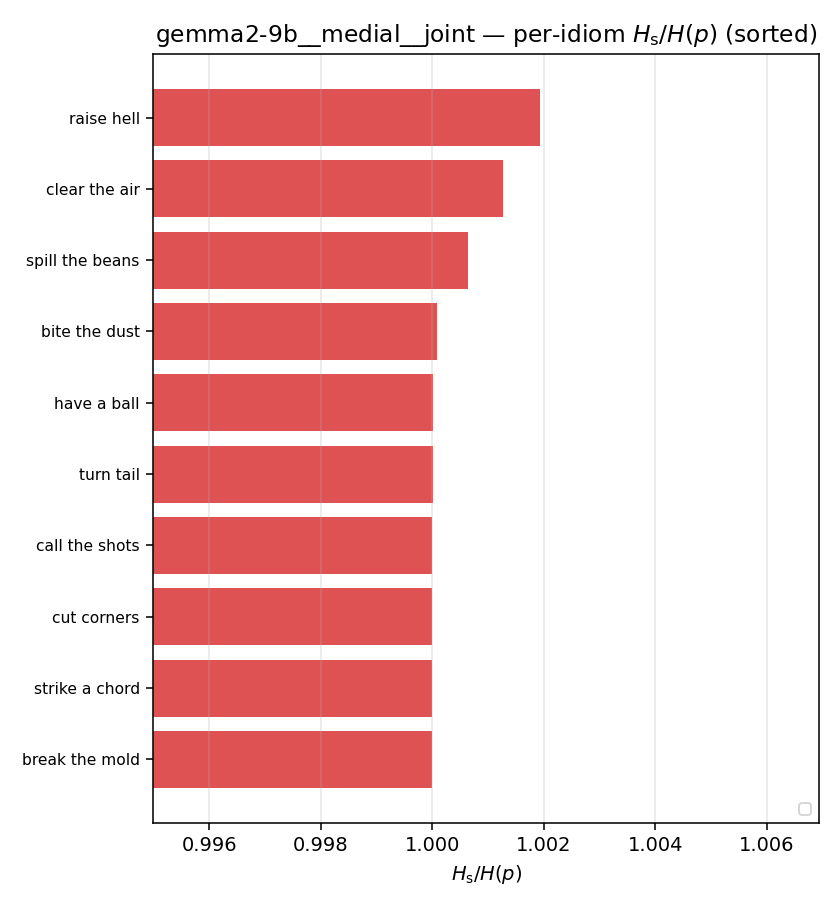 |
gemma2-9b · full · geo gemma2-9b__full__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 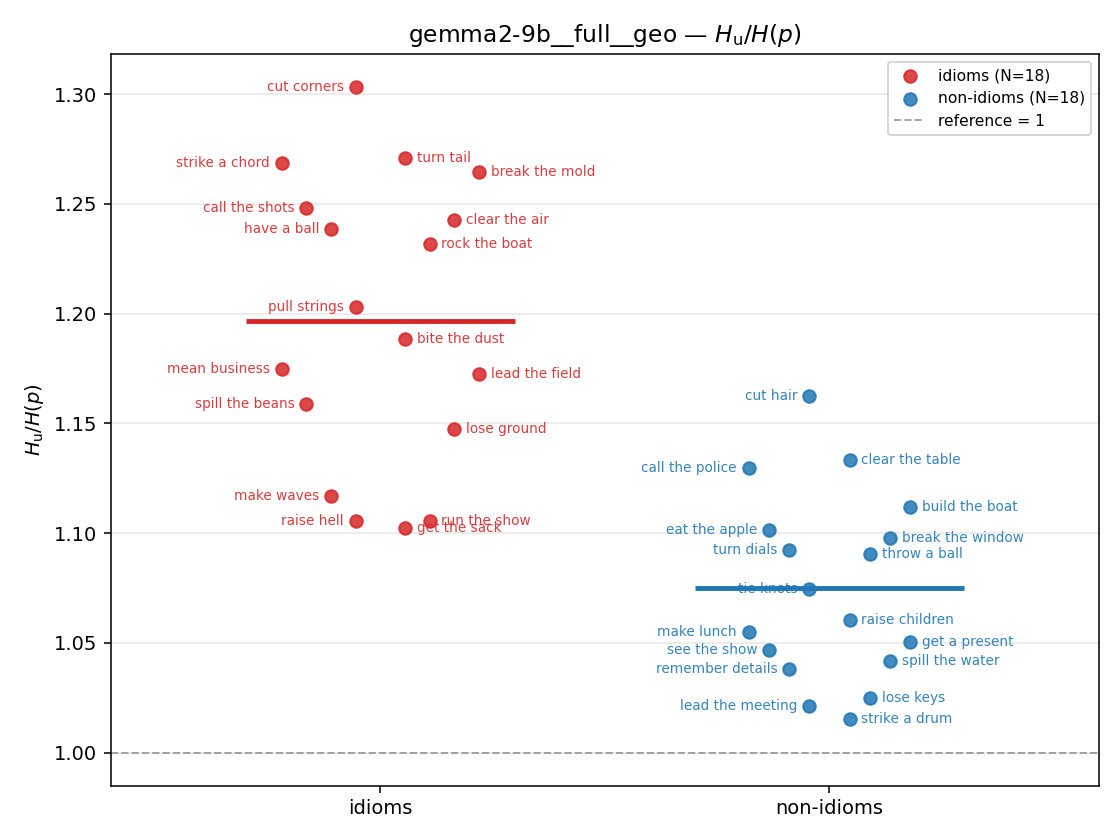 | 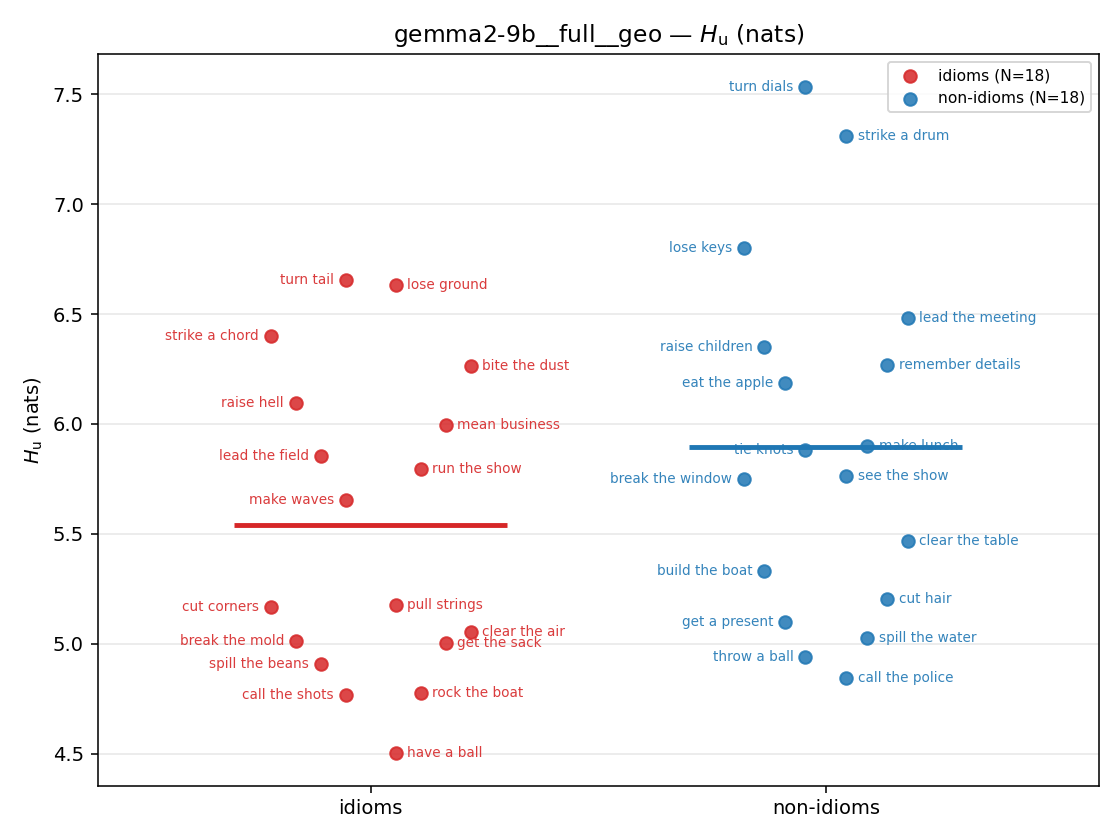 | 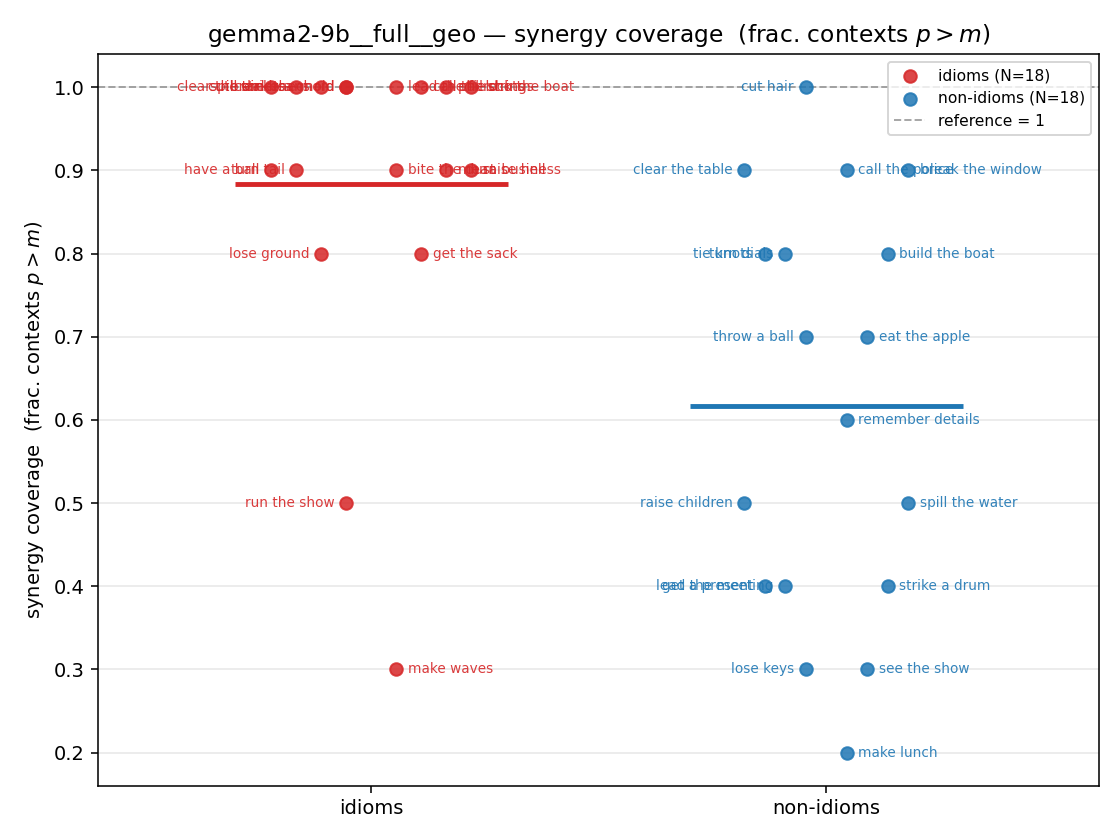 | 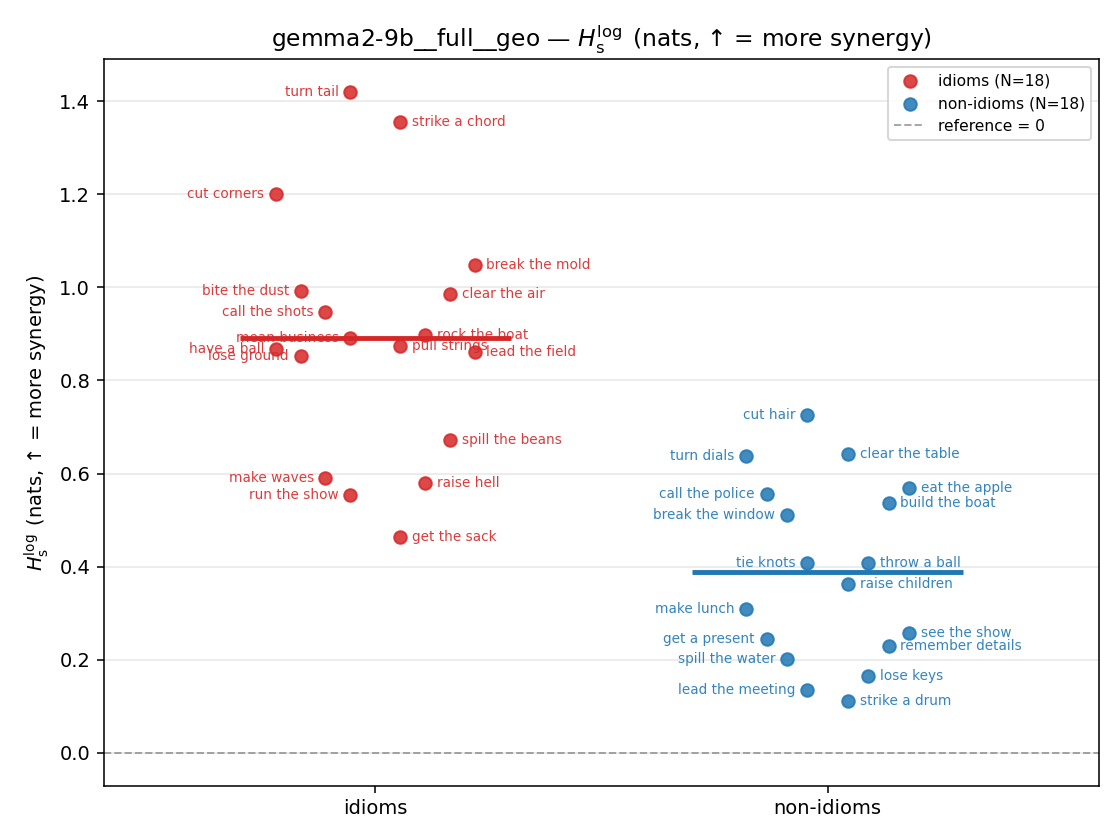 | 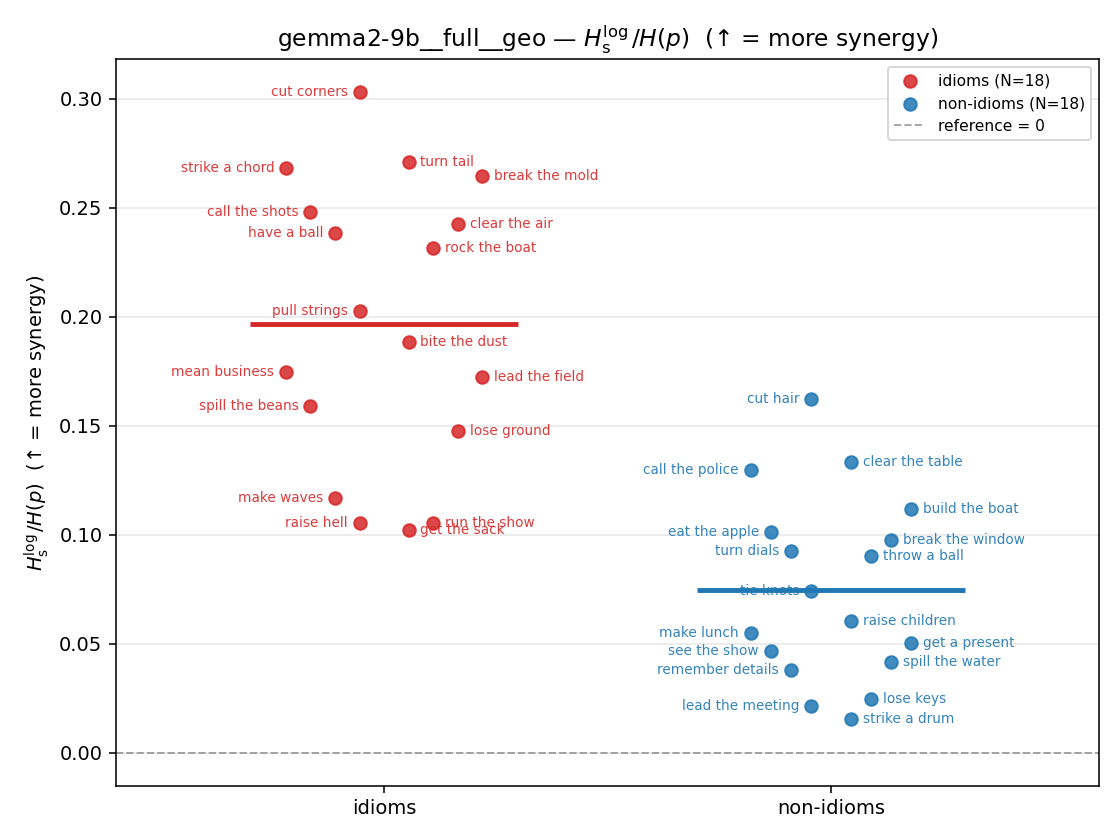 | 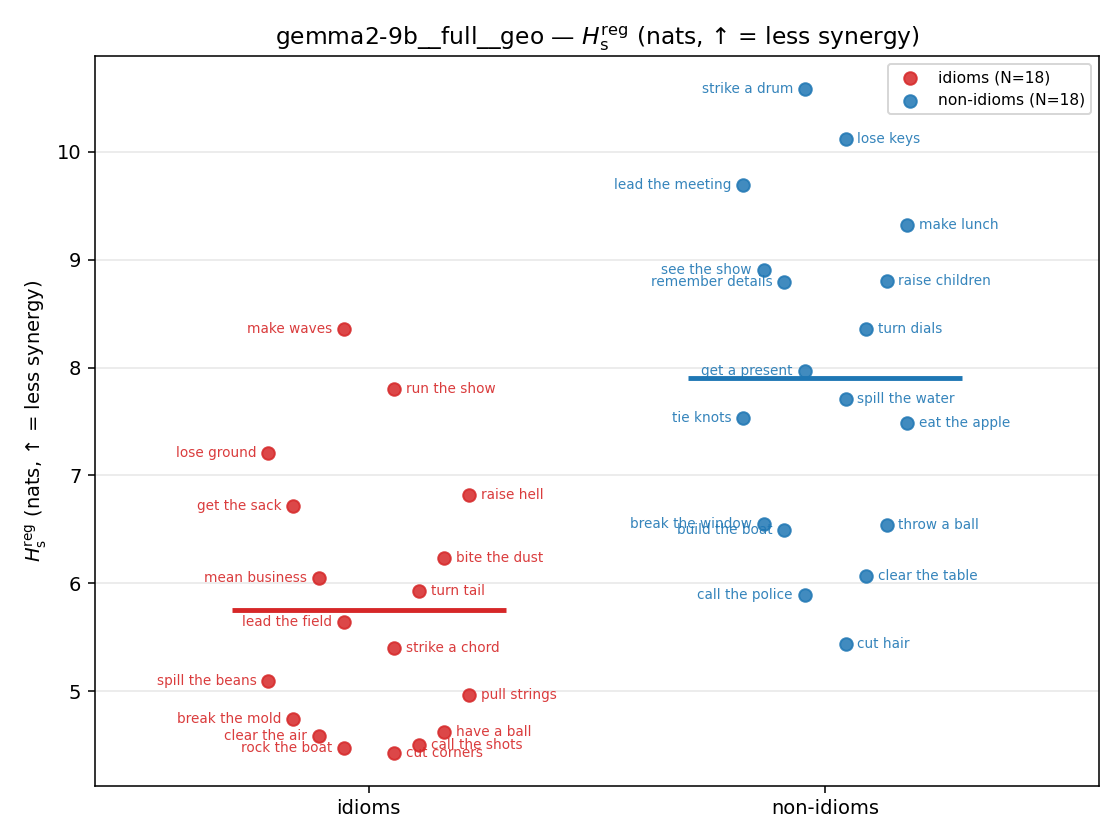 | 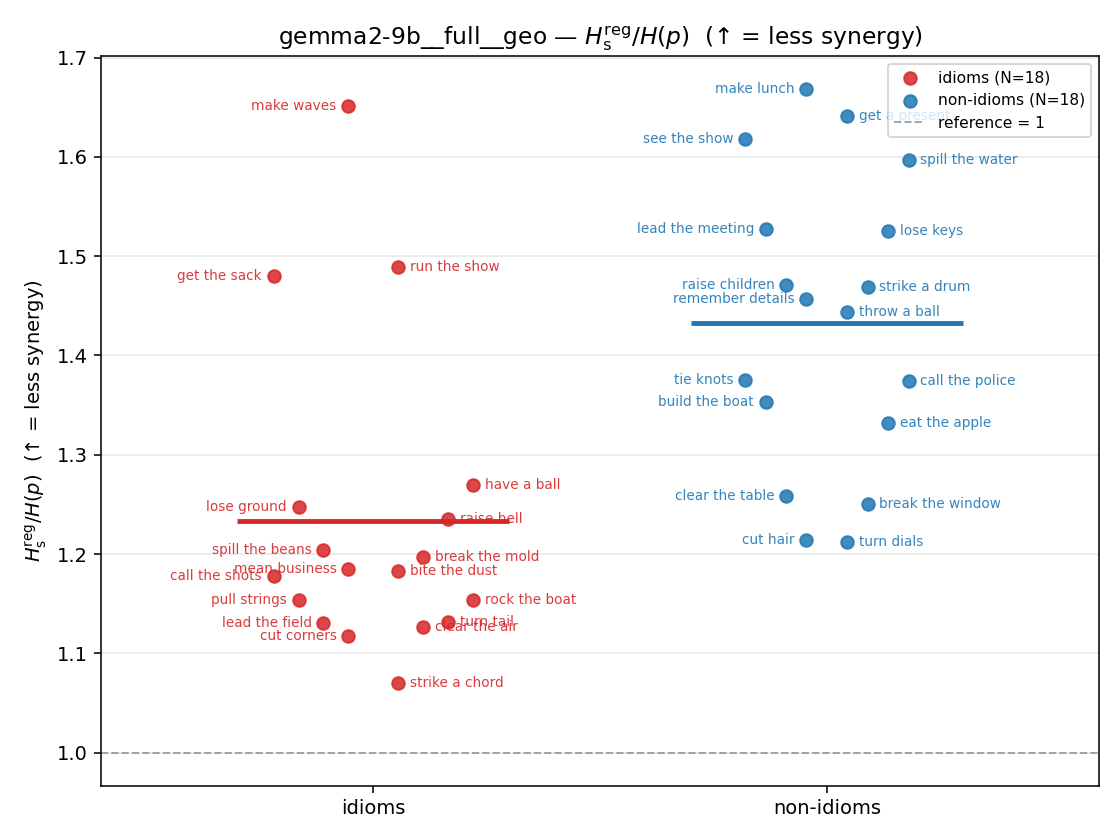 | 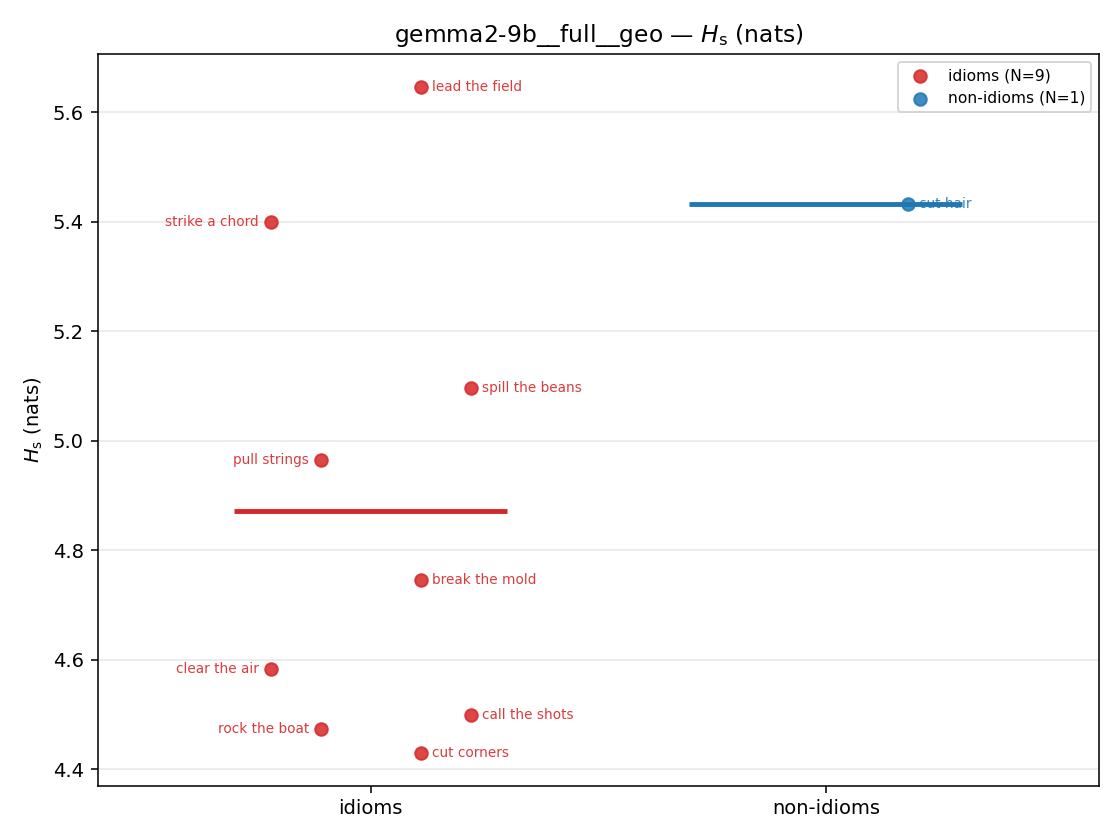 | 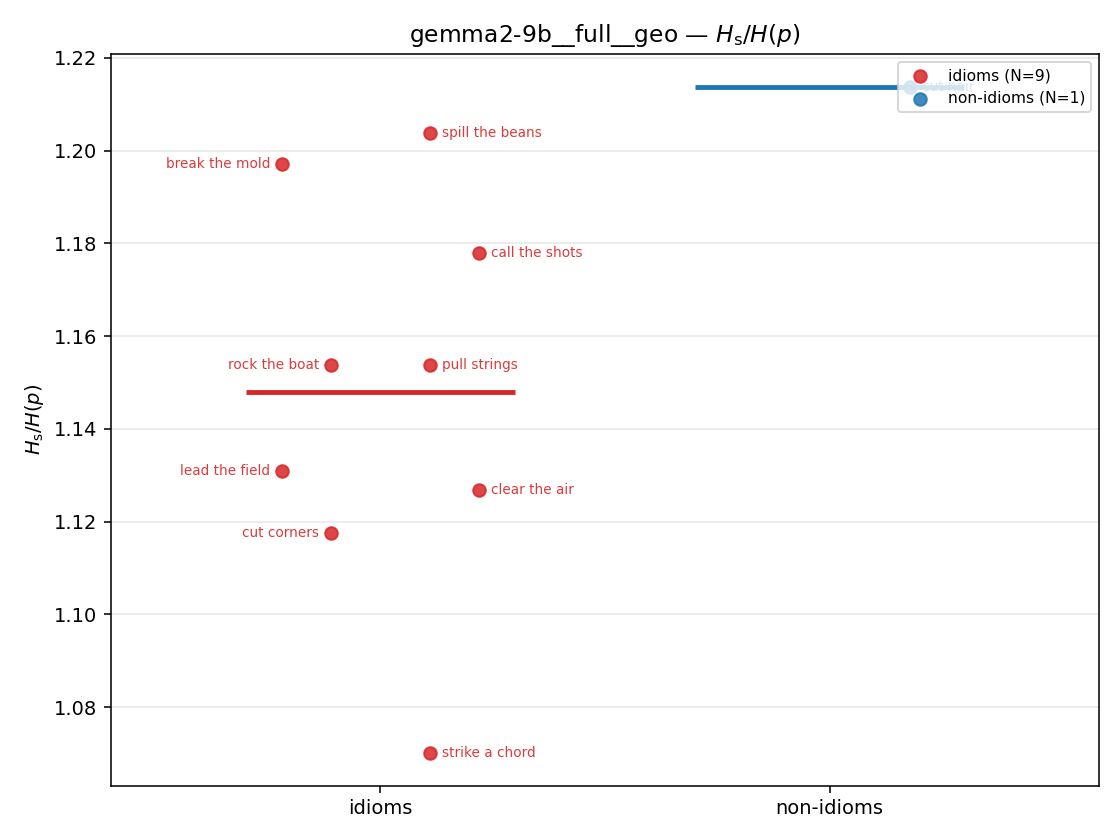 |
| mean ± 95% CI | 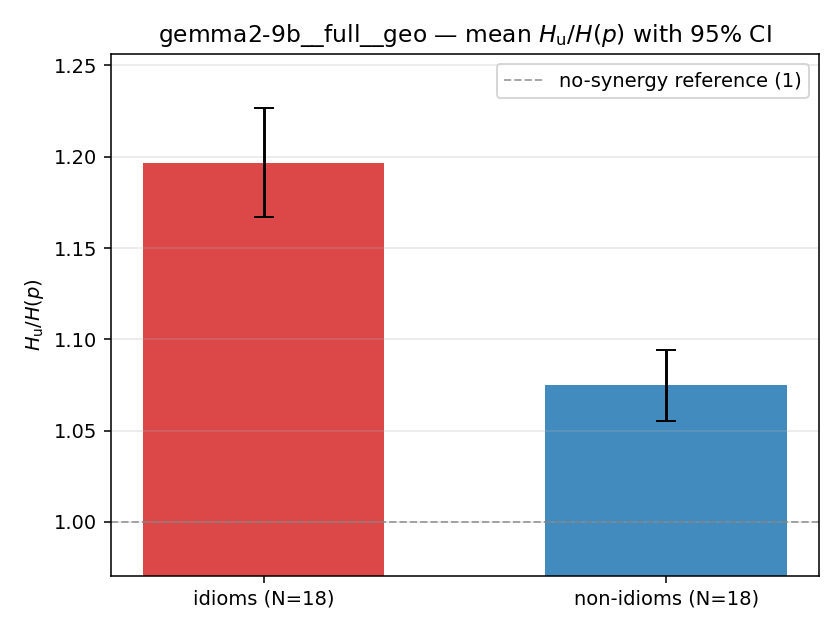 | 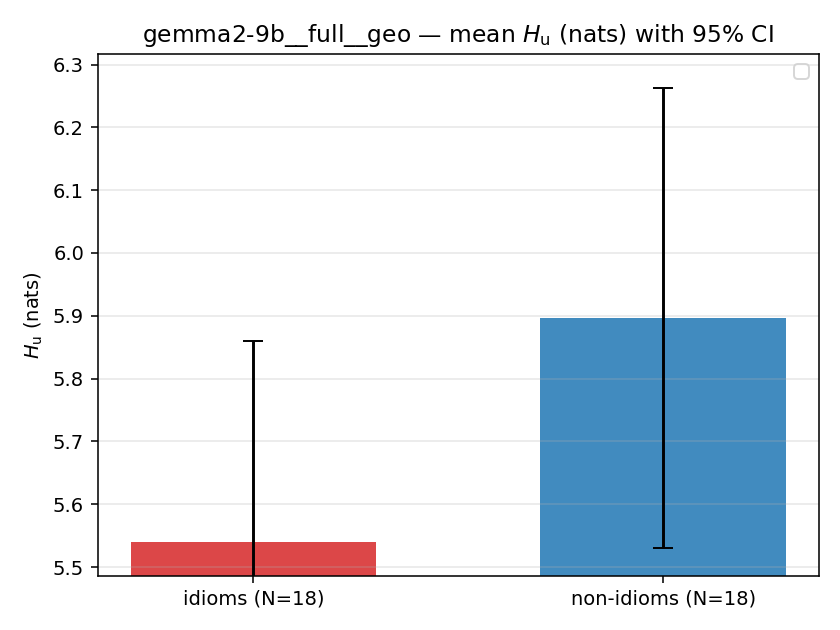 | 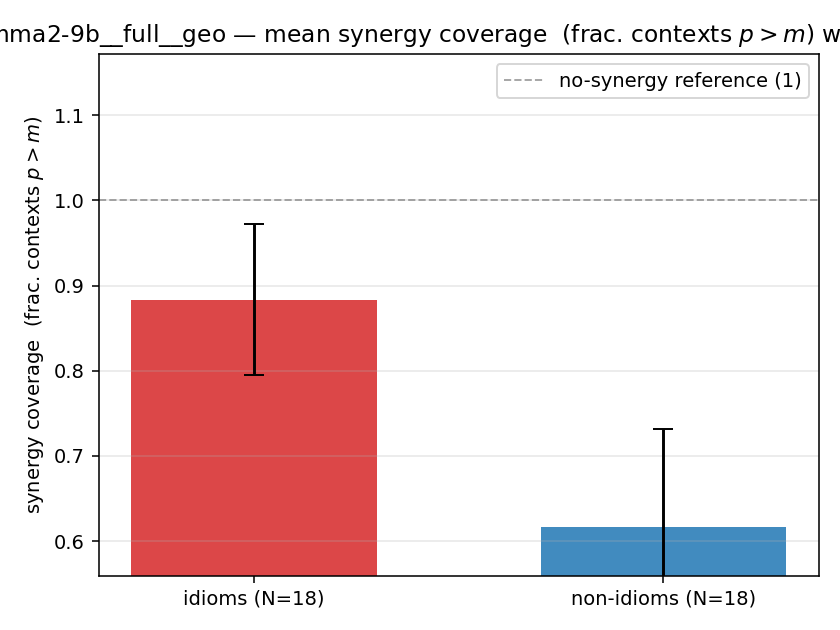 | 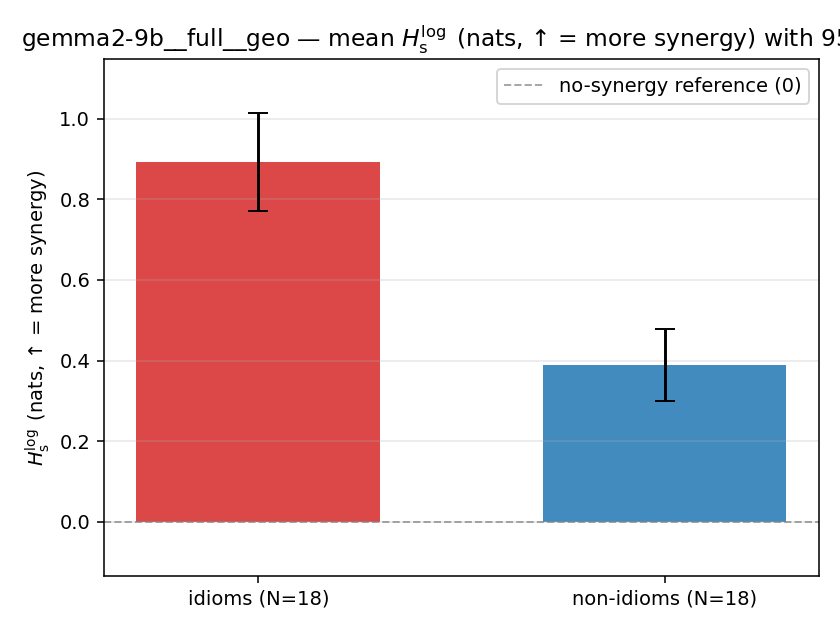 | 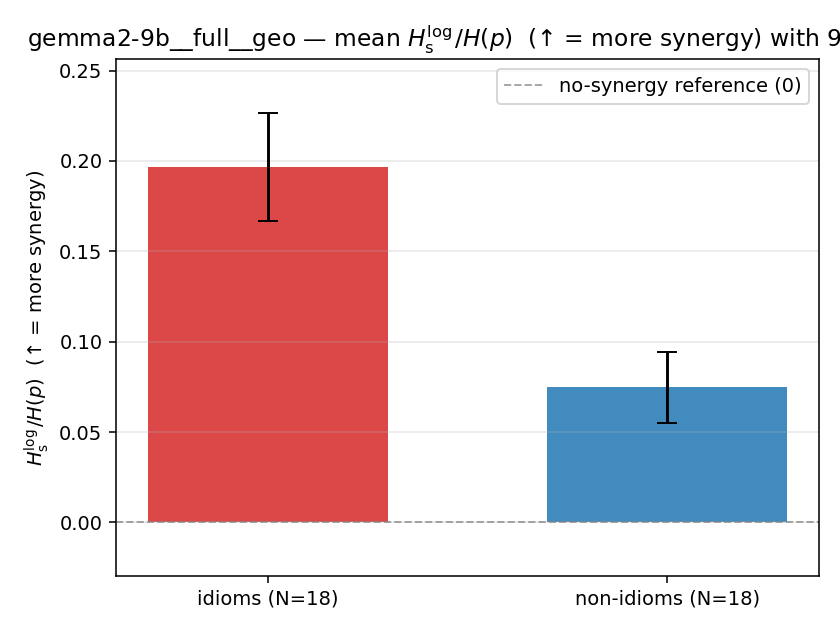 | 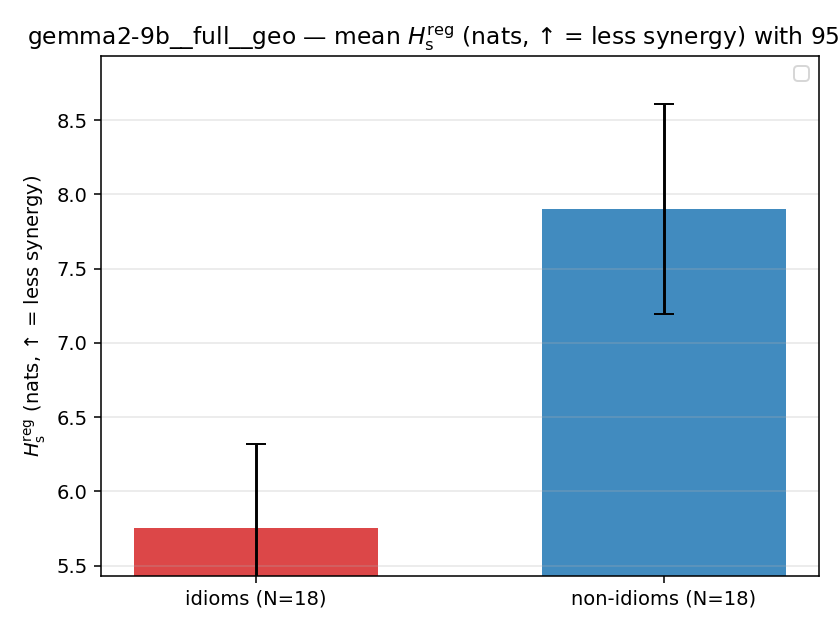 | 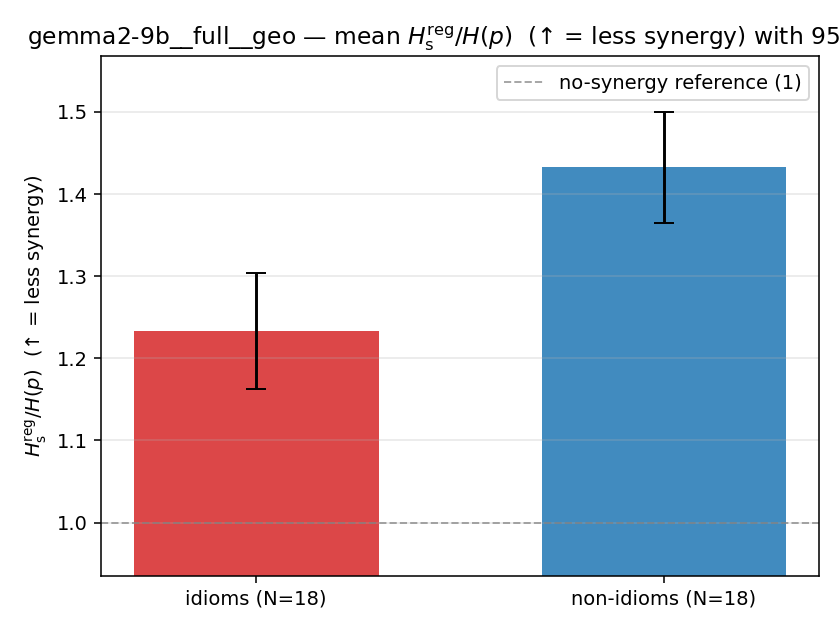 | 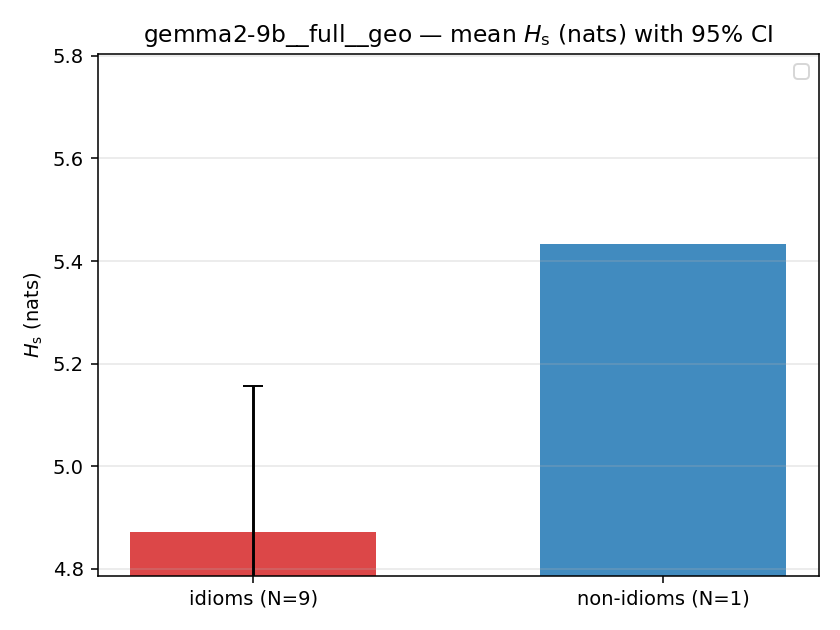 | 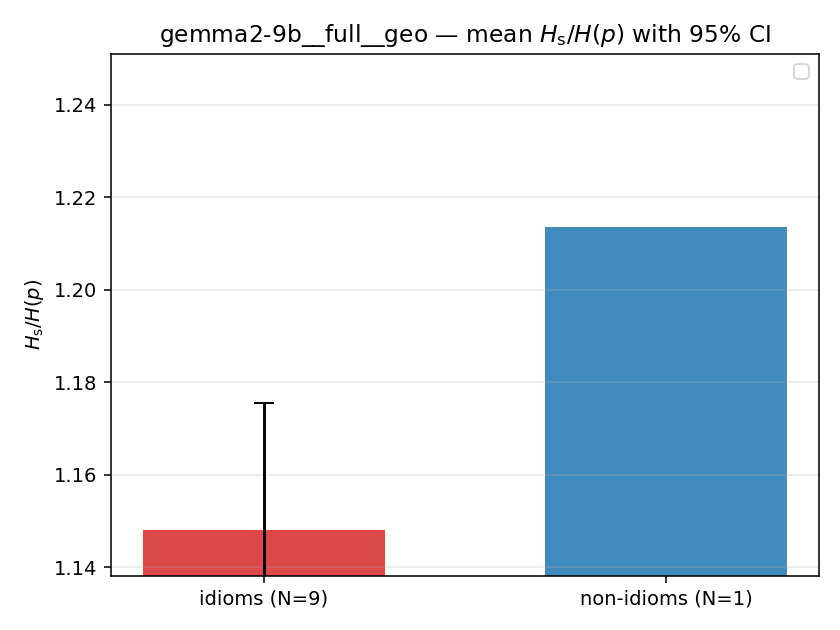 |
| per-idiom (sorted) | 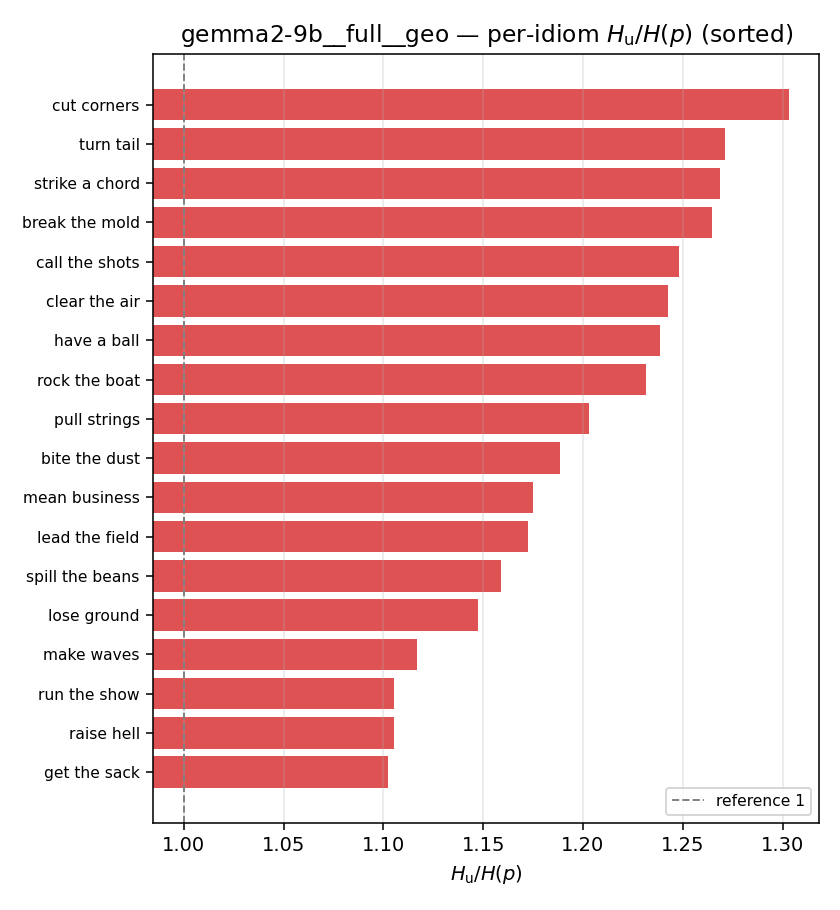 | 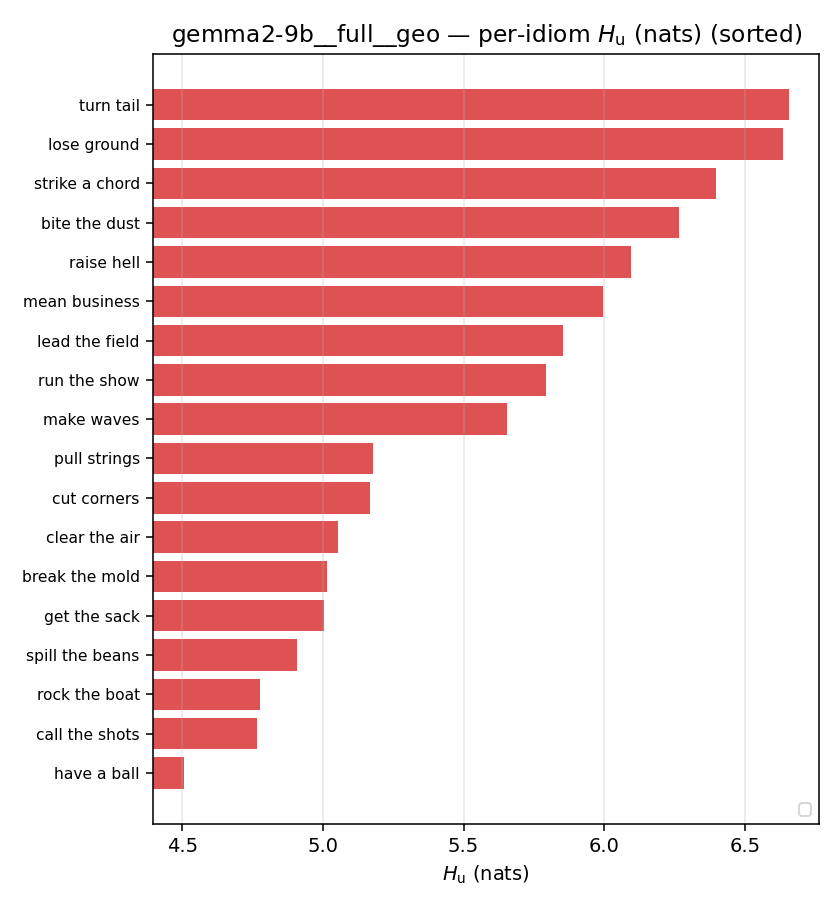 | 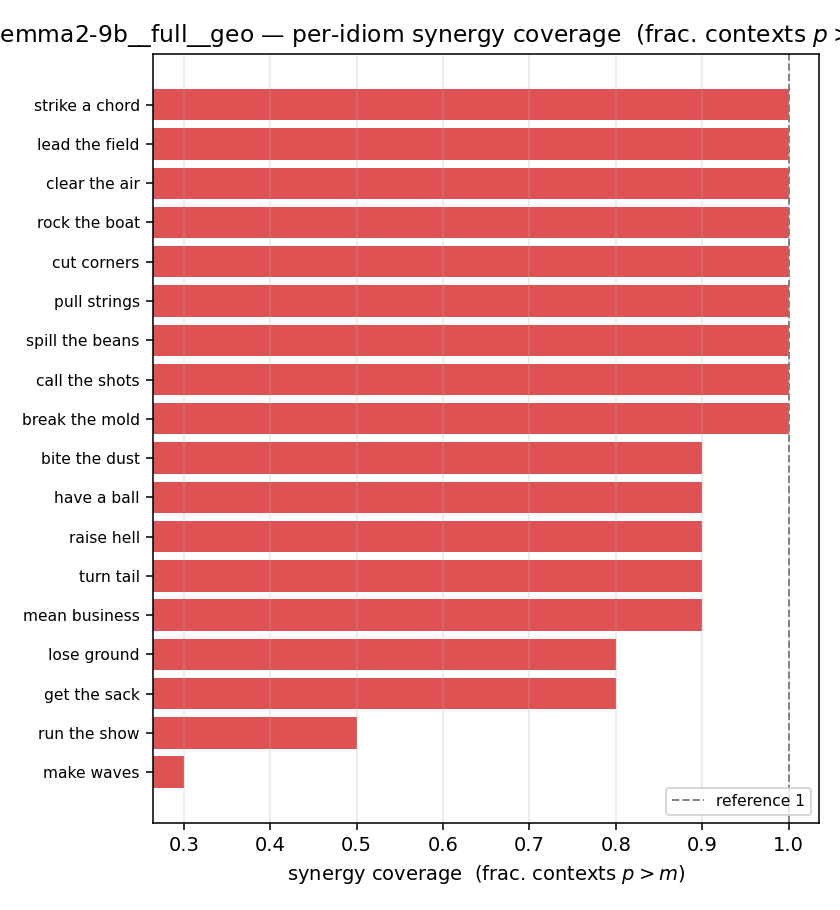 | 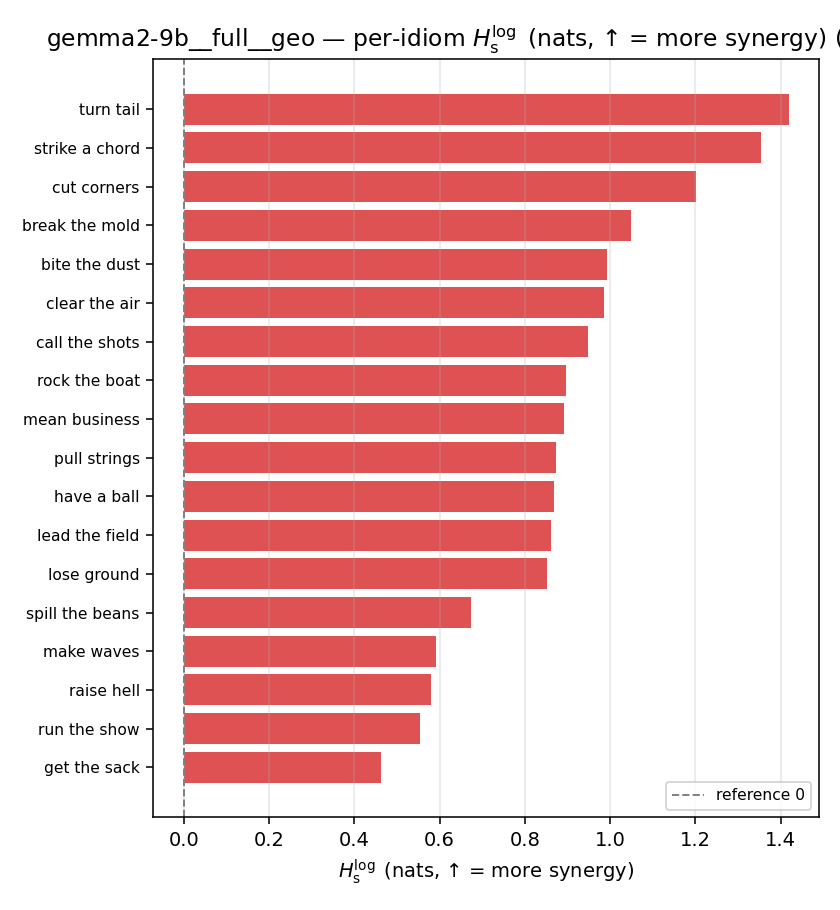 | 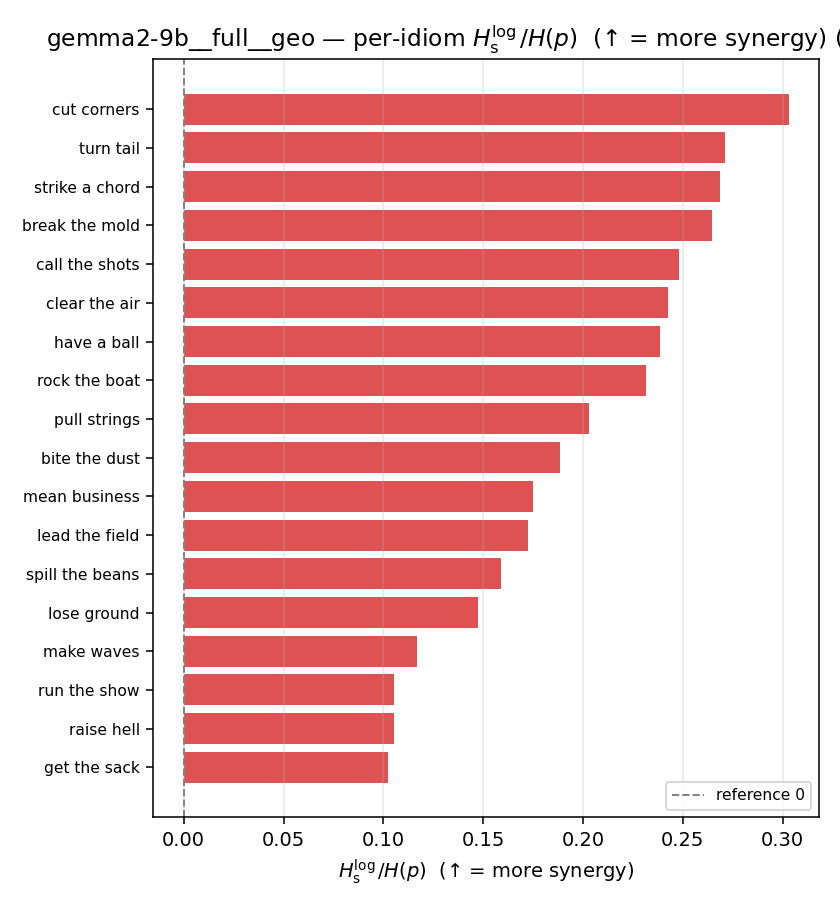 | 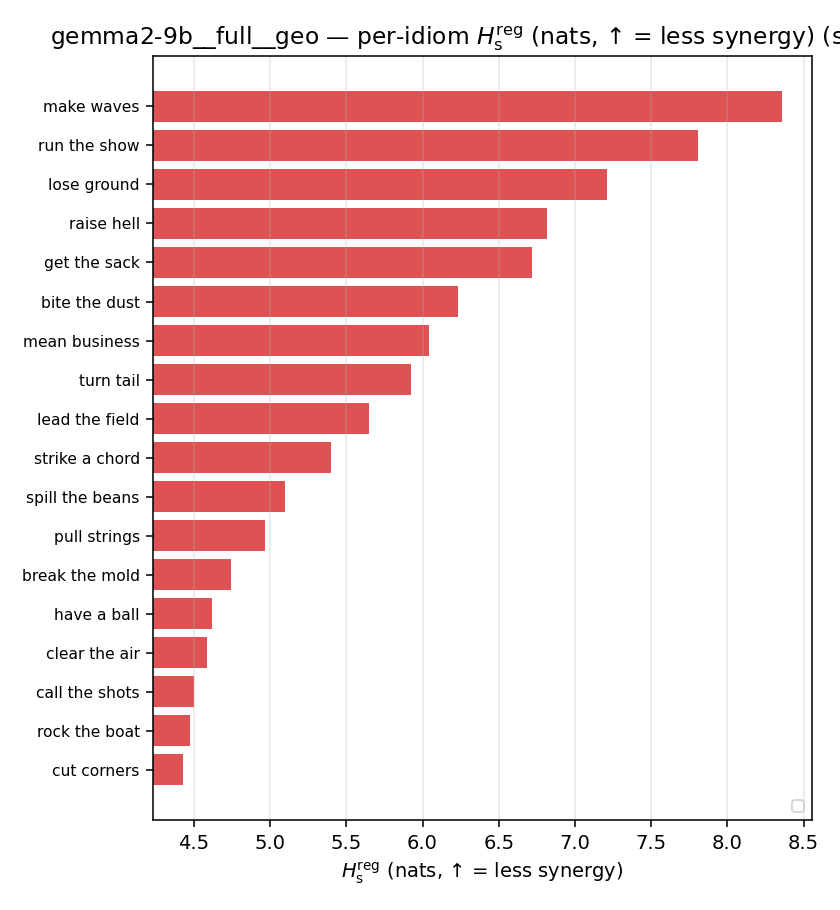 | 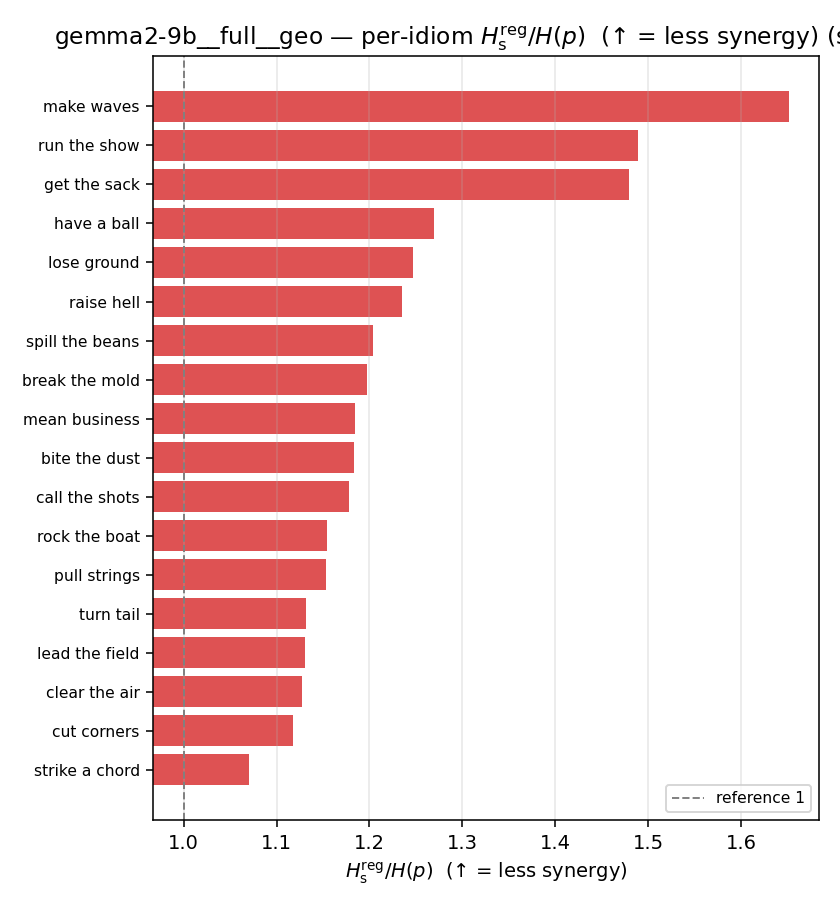 | 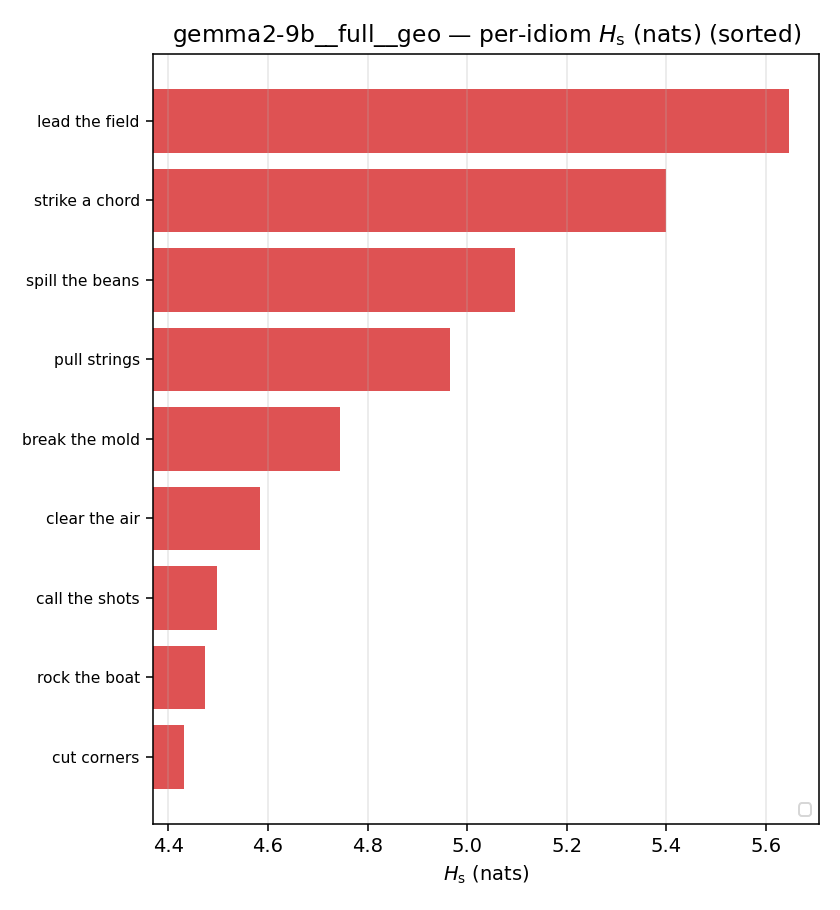 | 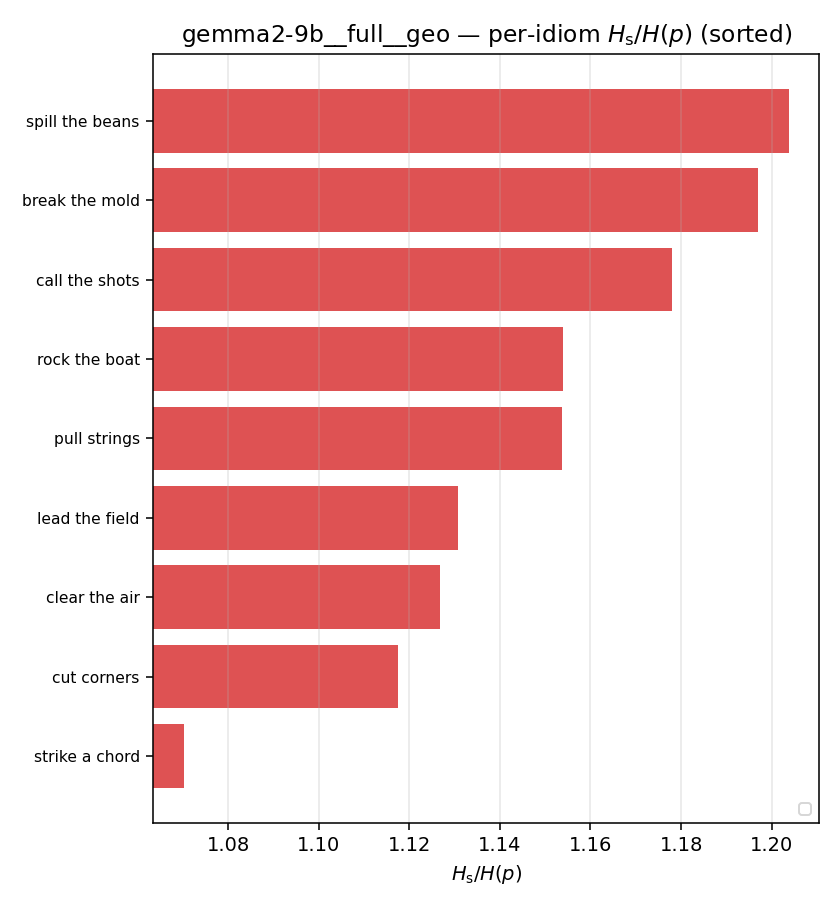 |
gemma2-9b · full · joint gemma2-9b__full__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 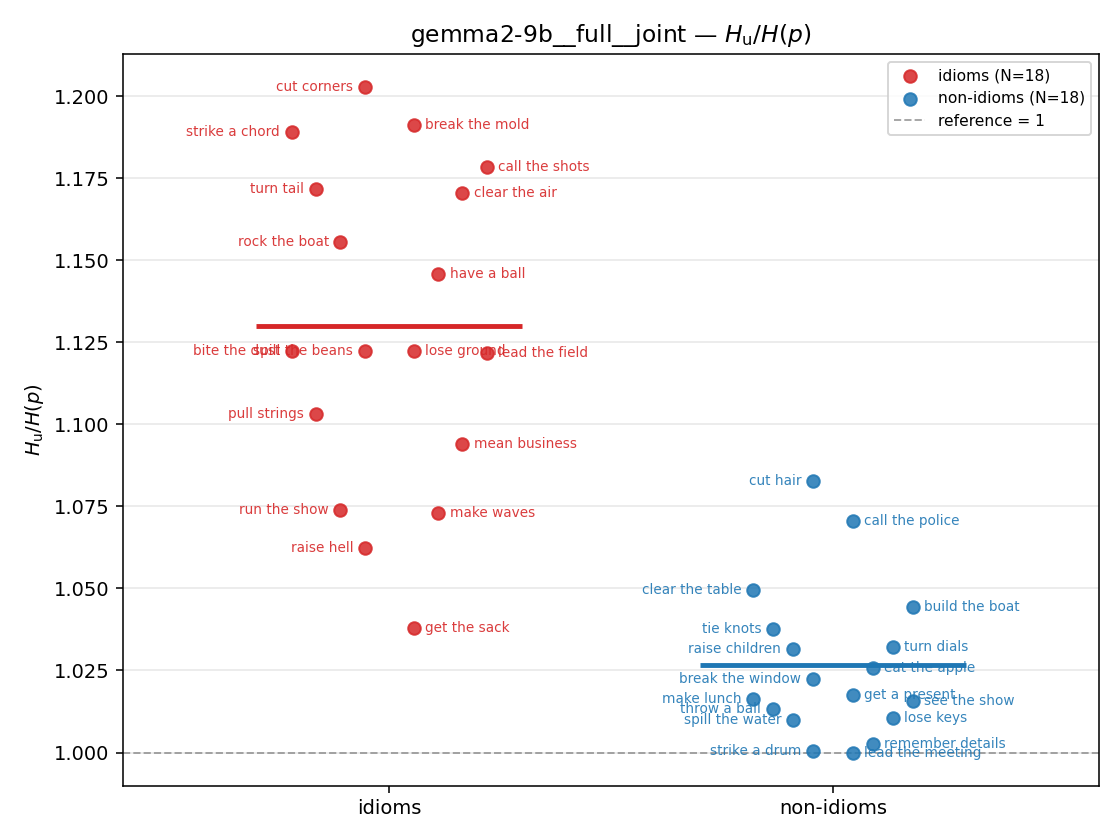 | 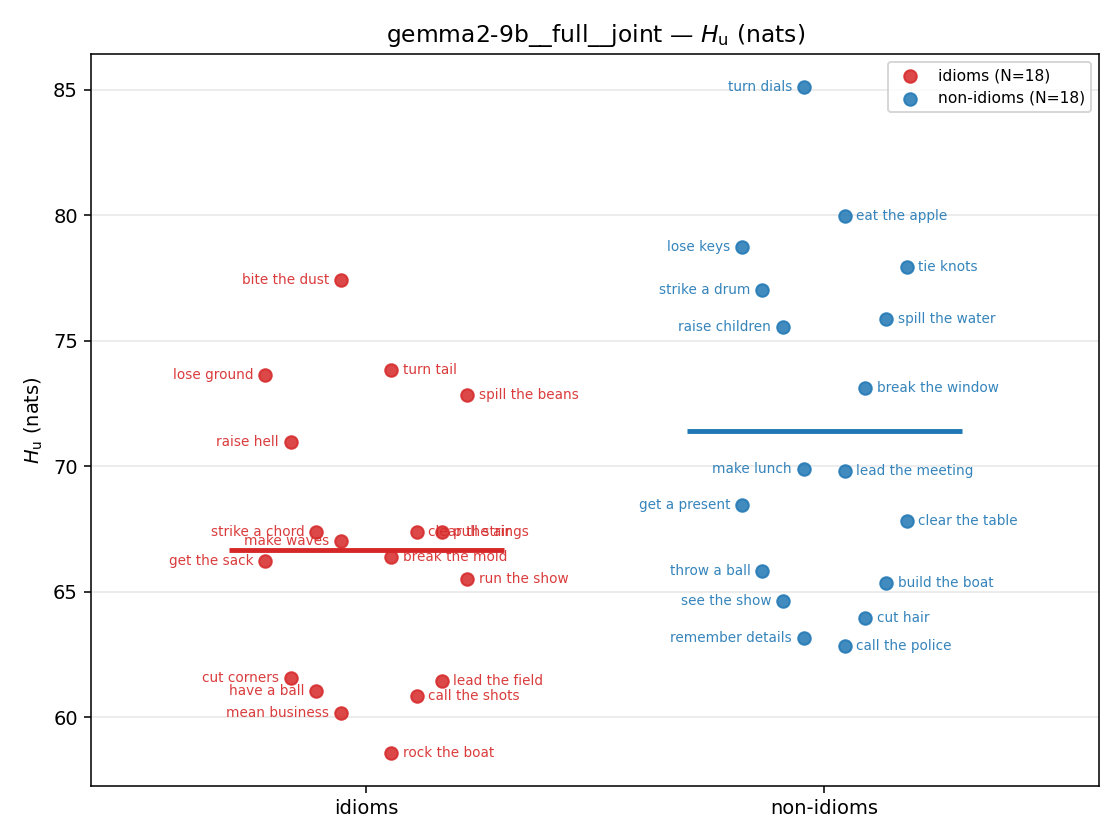 | 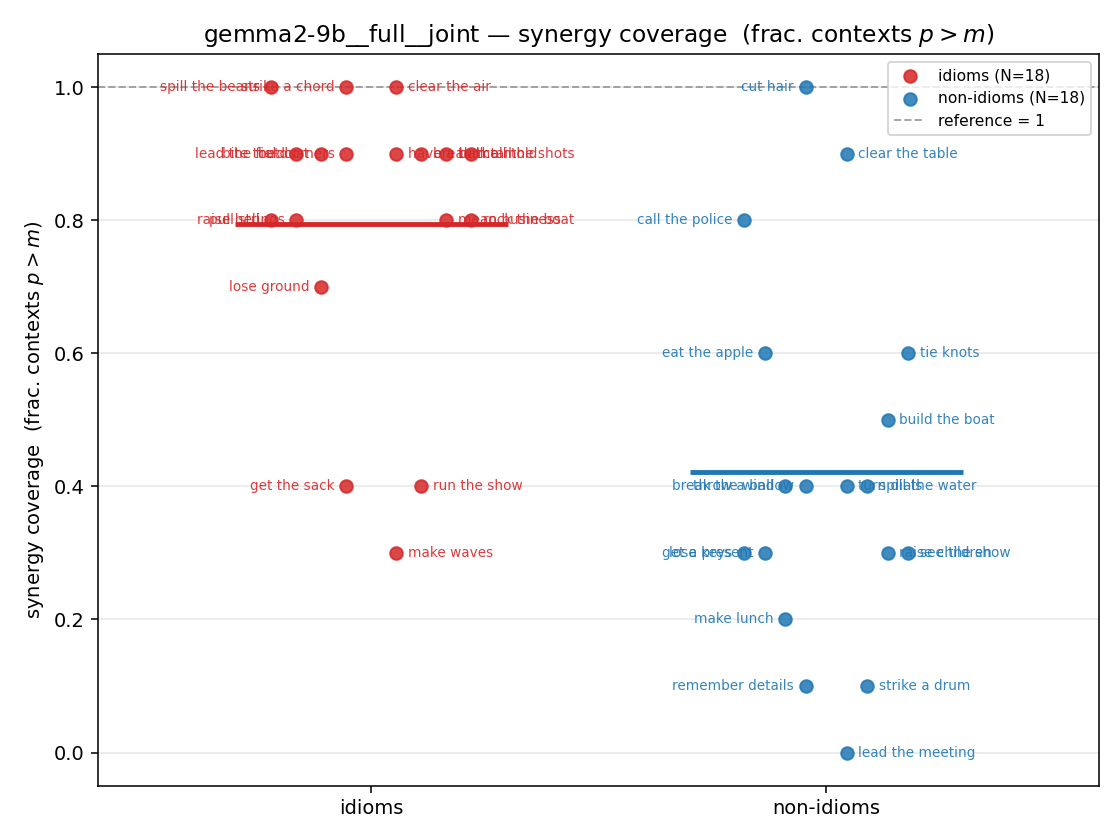 | 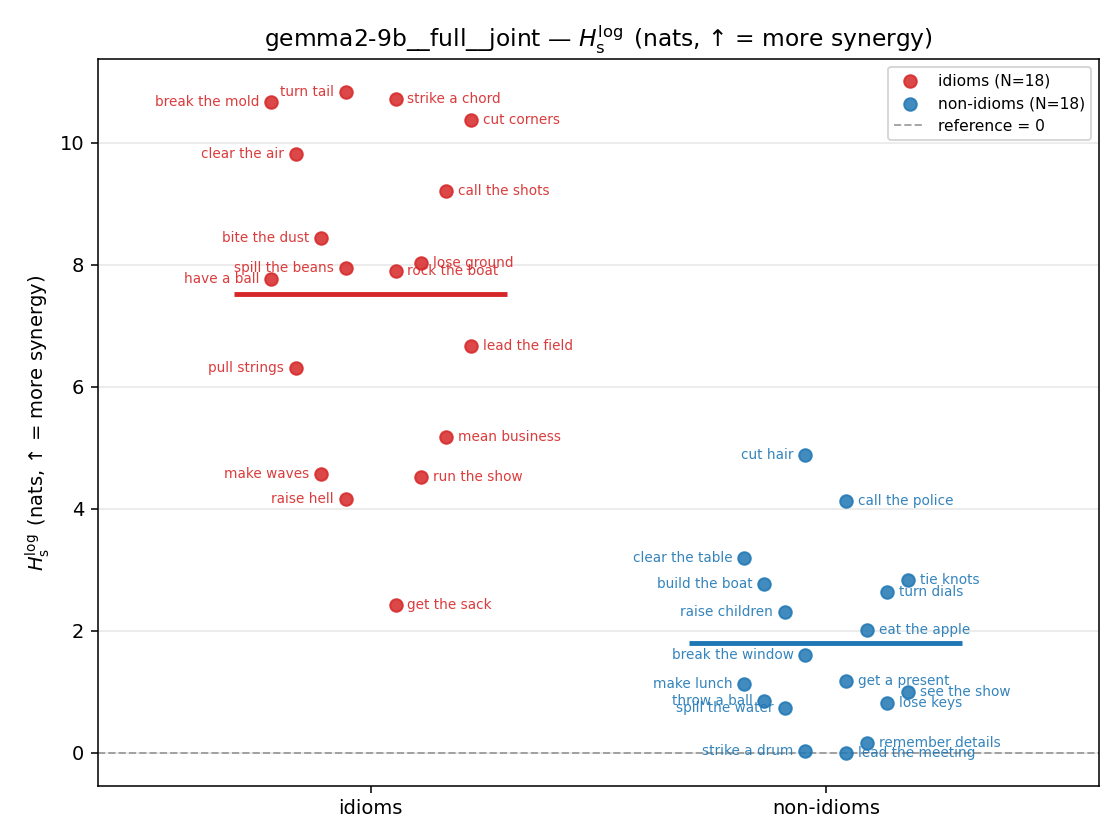 | 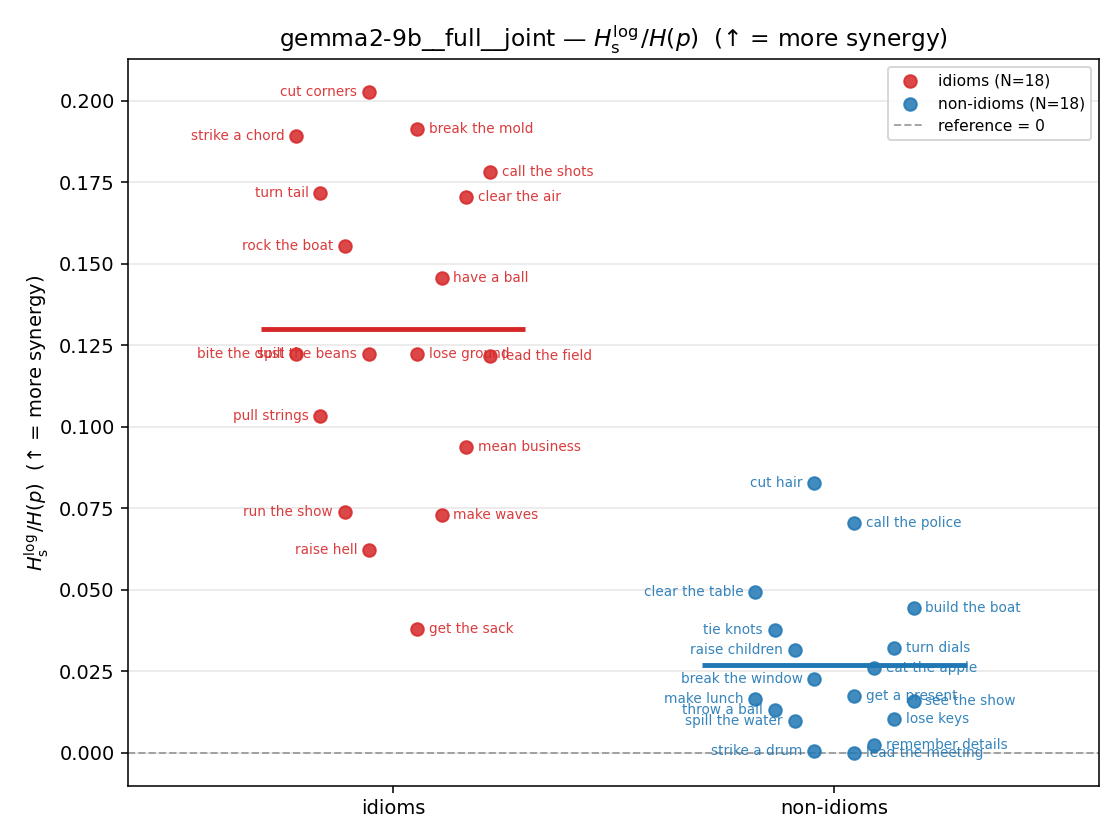 | 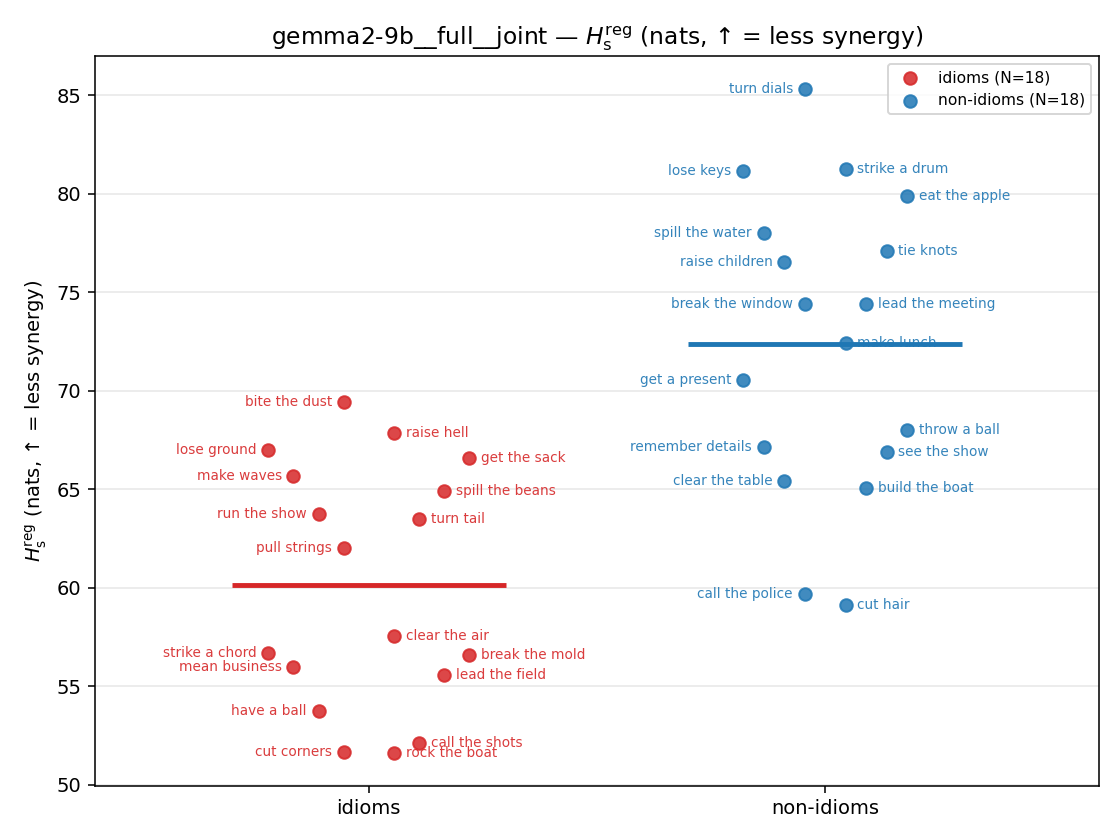 | 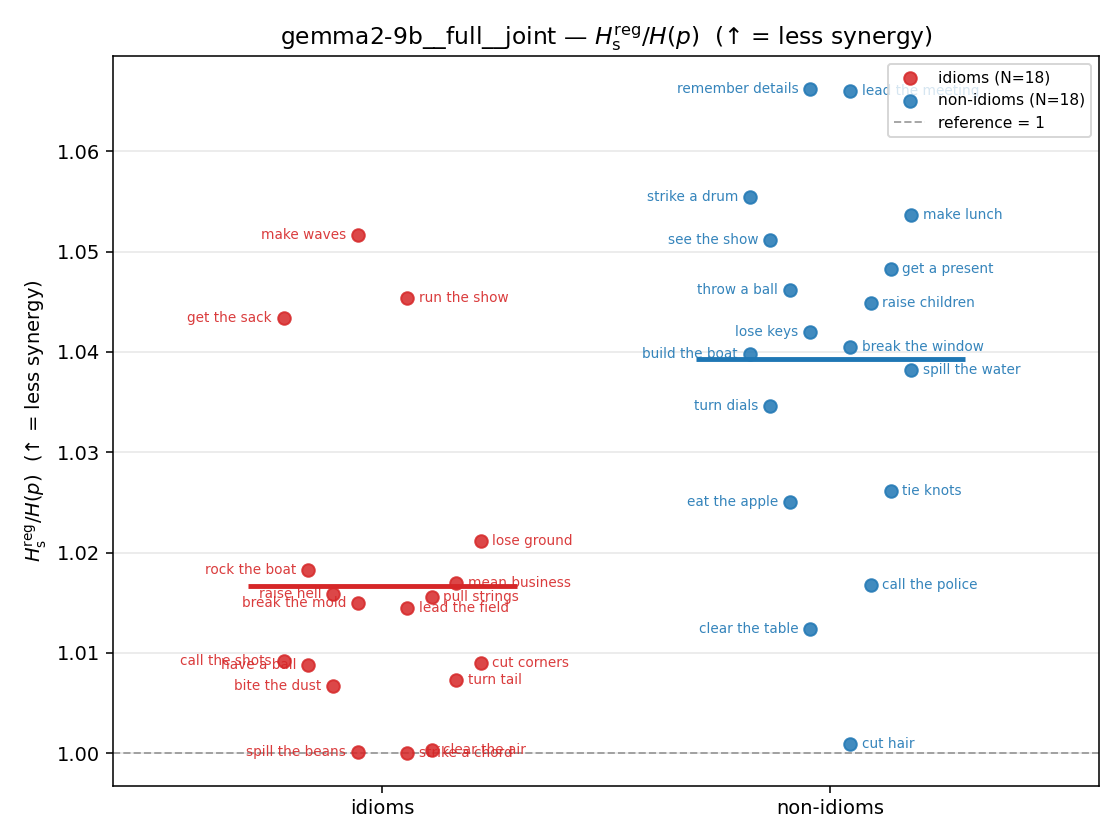 | 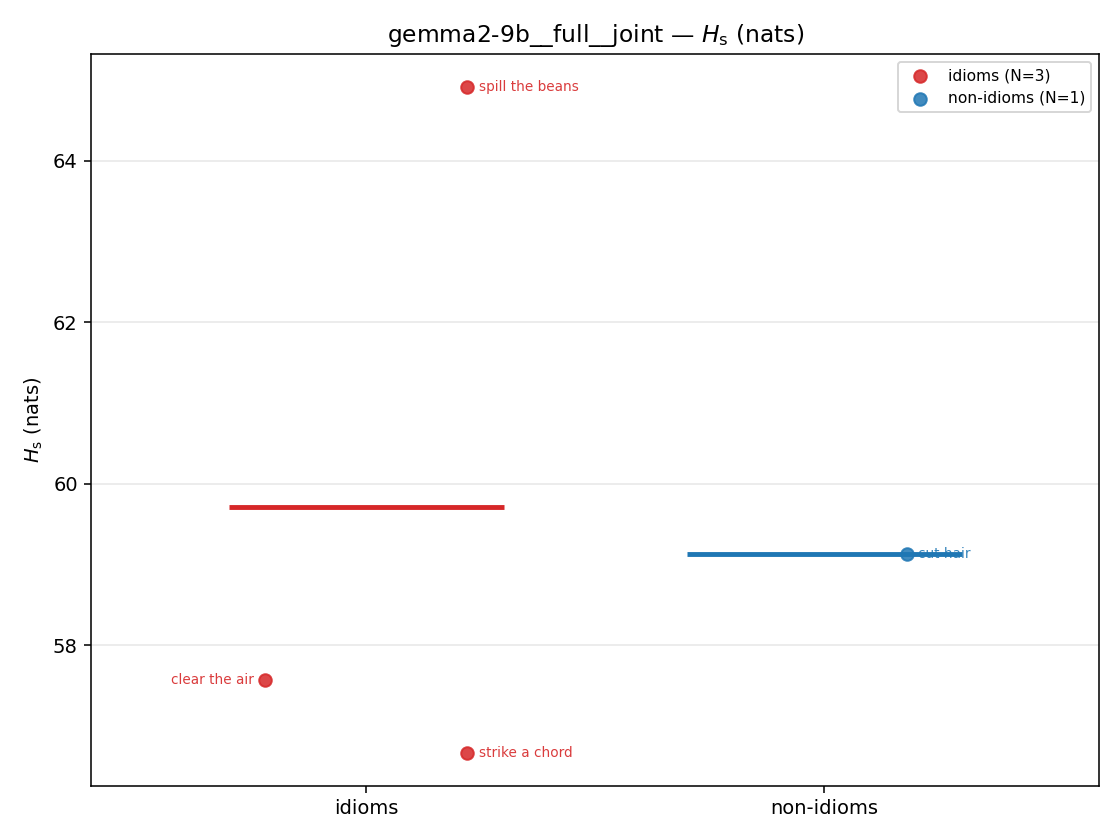 | 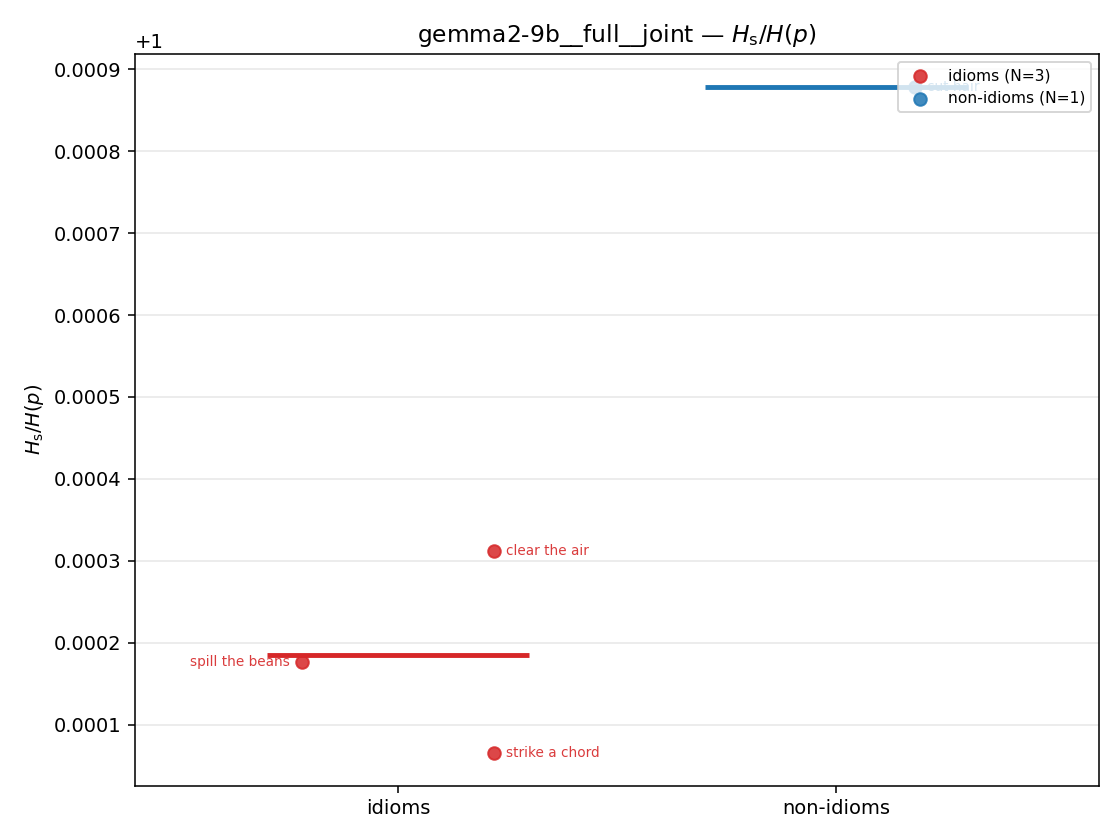 |
| mean ± 95% CI | 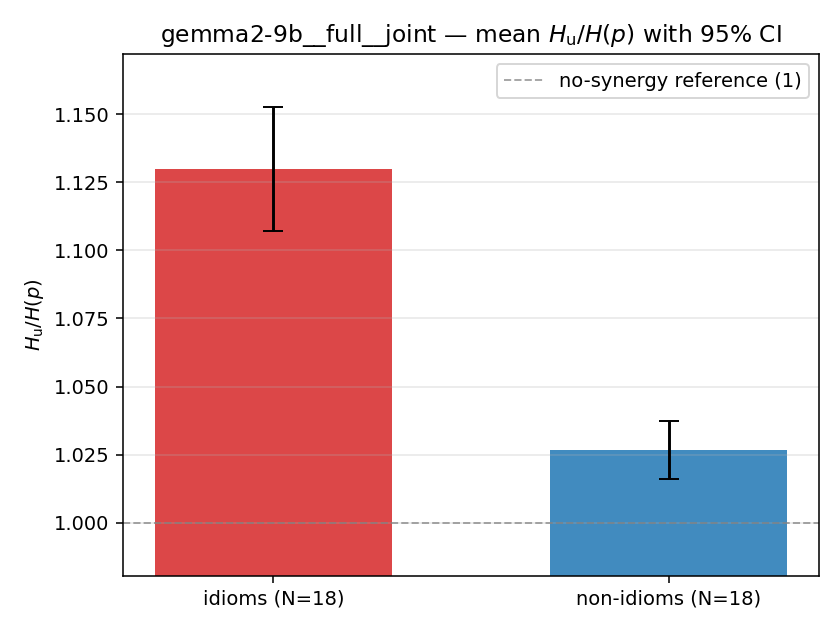 | 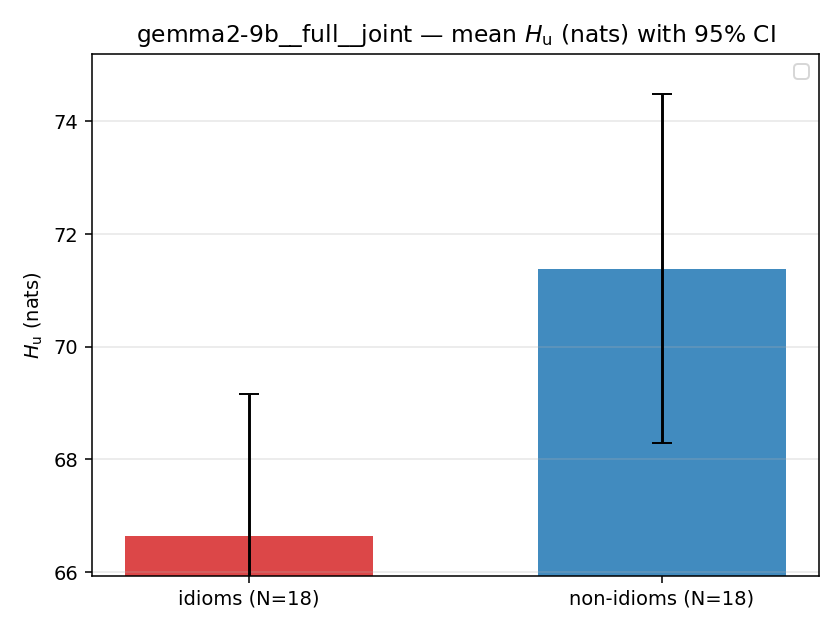 | 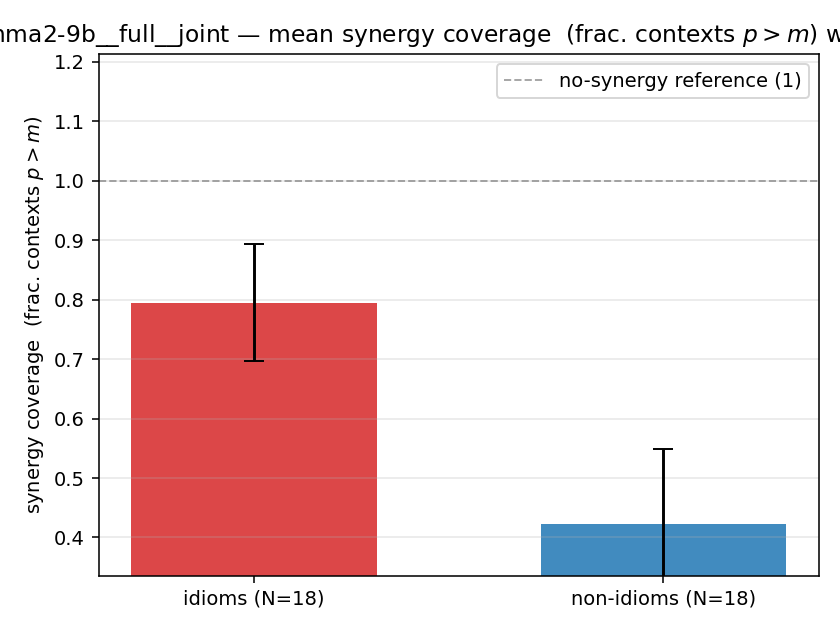 | 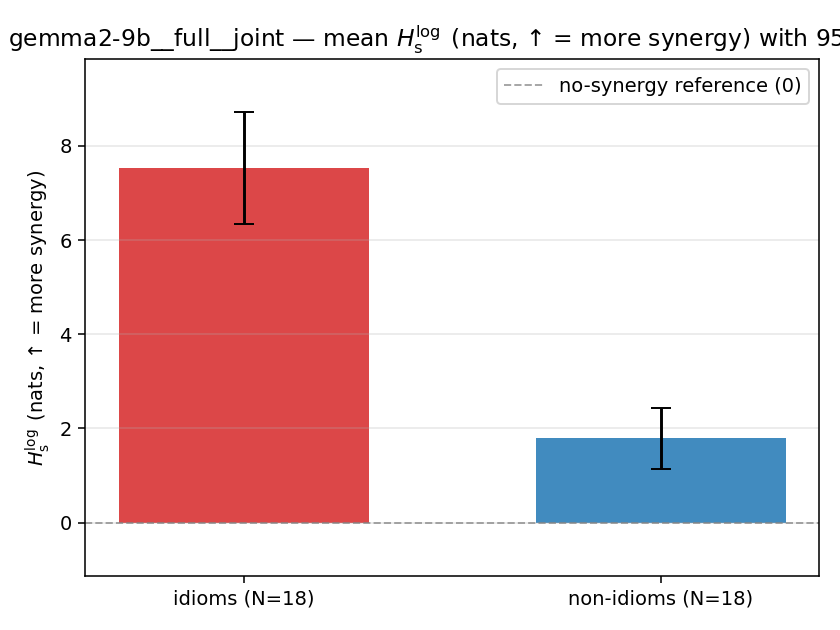 | 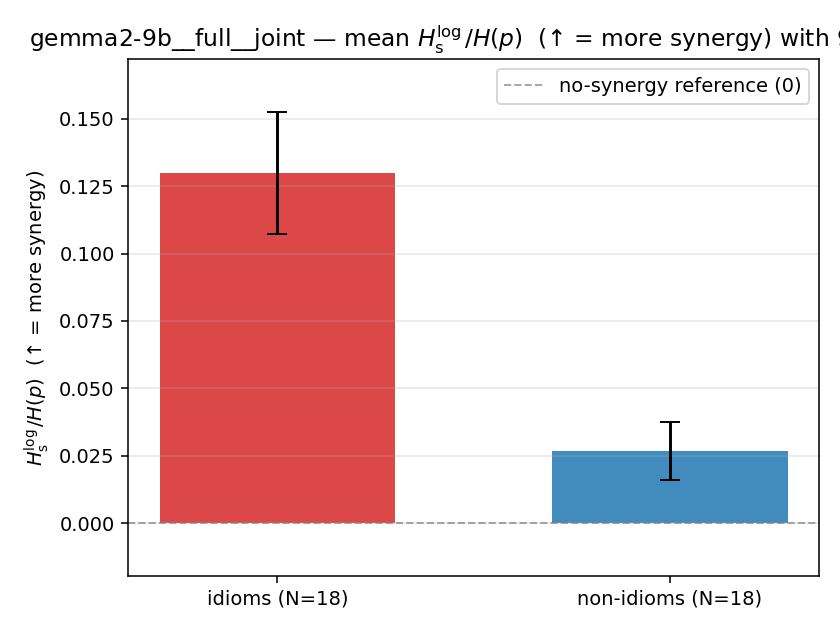 | 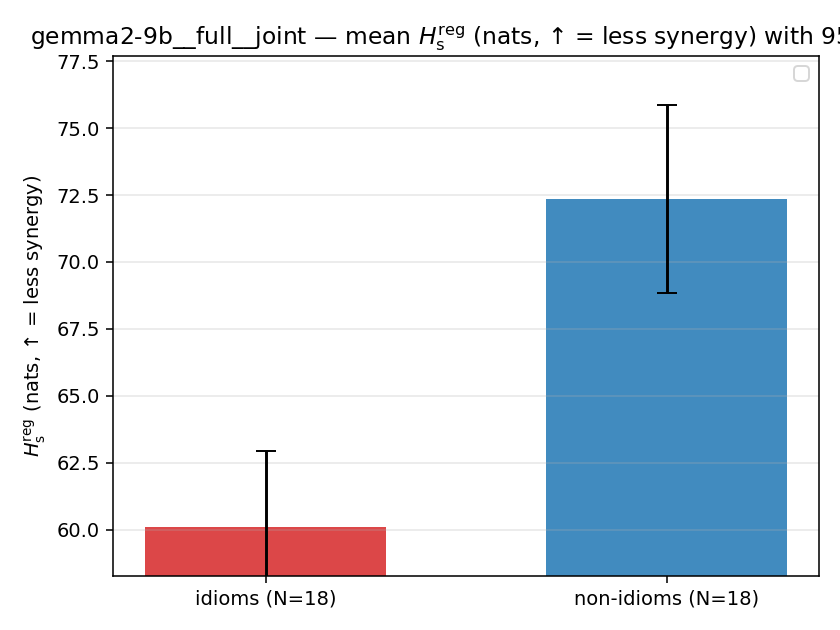 | 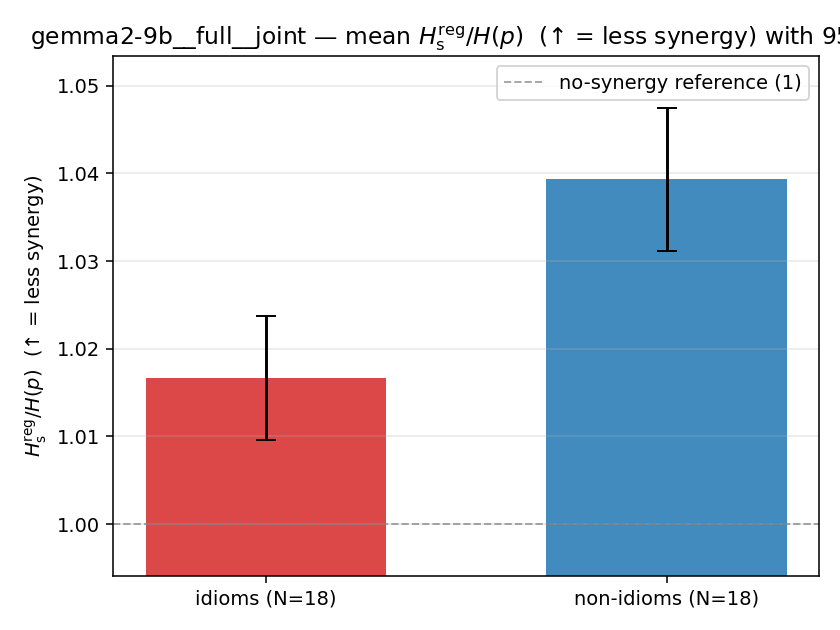 | 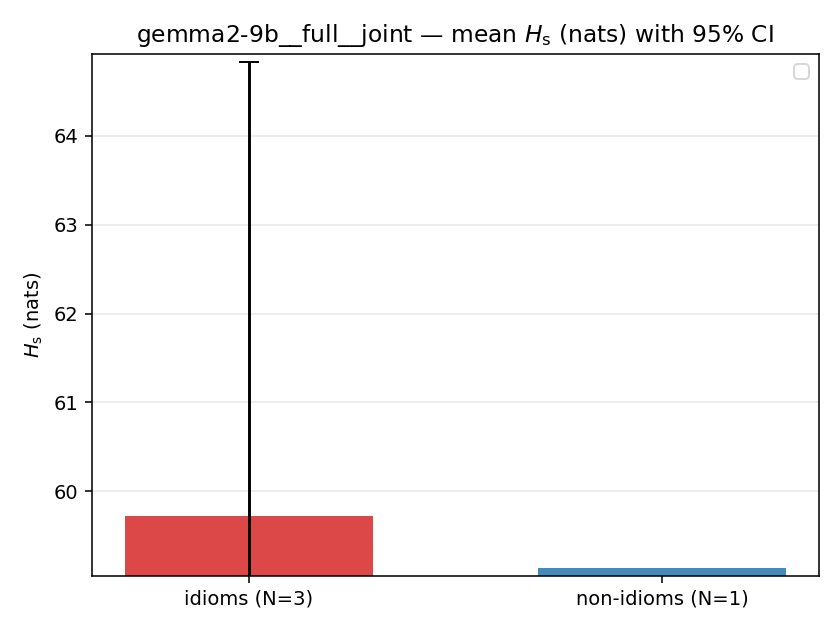 | 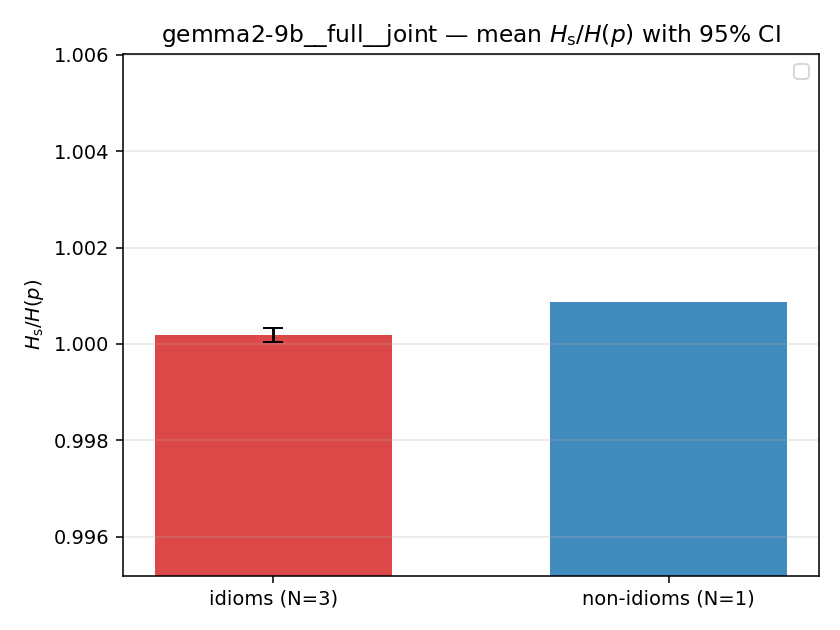 |
| per-idiom (sorted) | 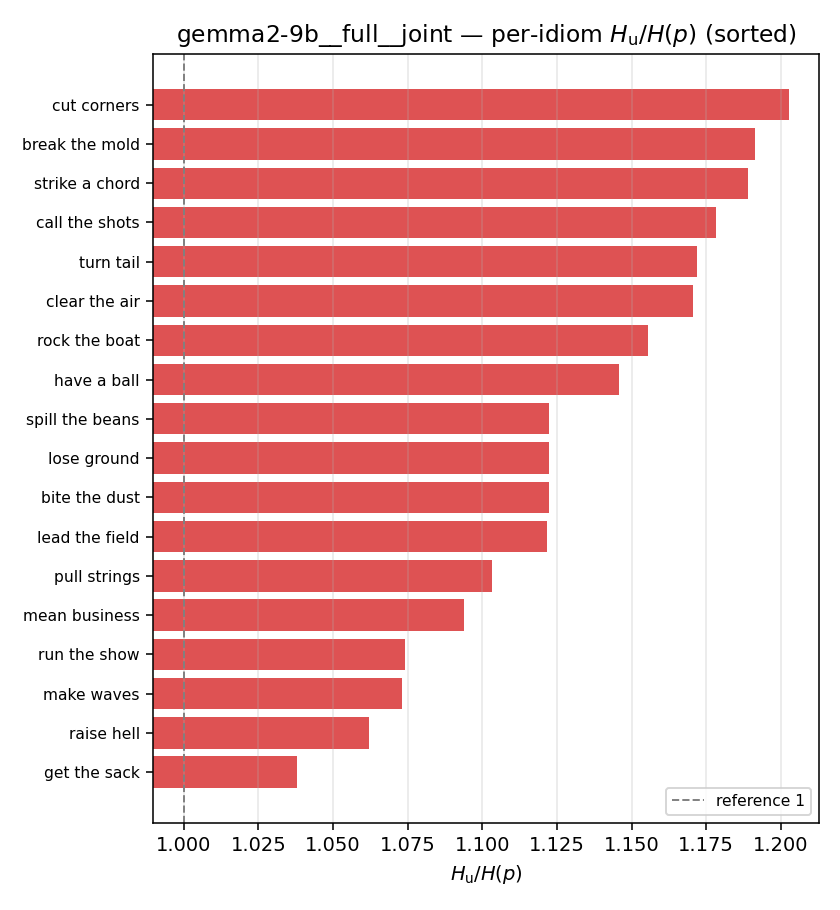 | 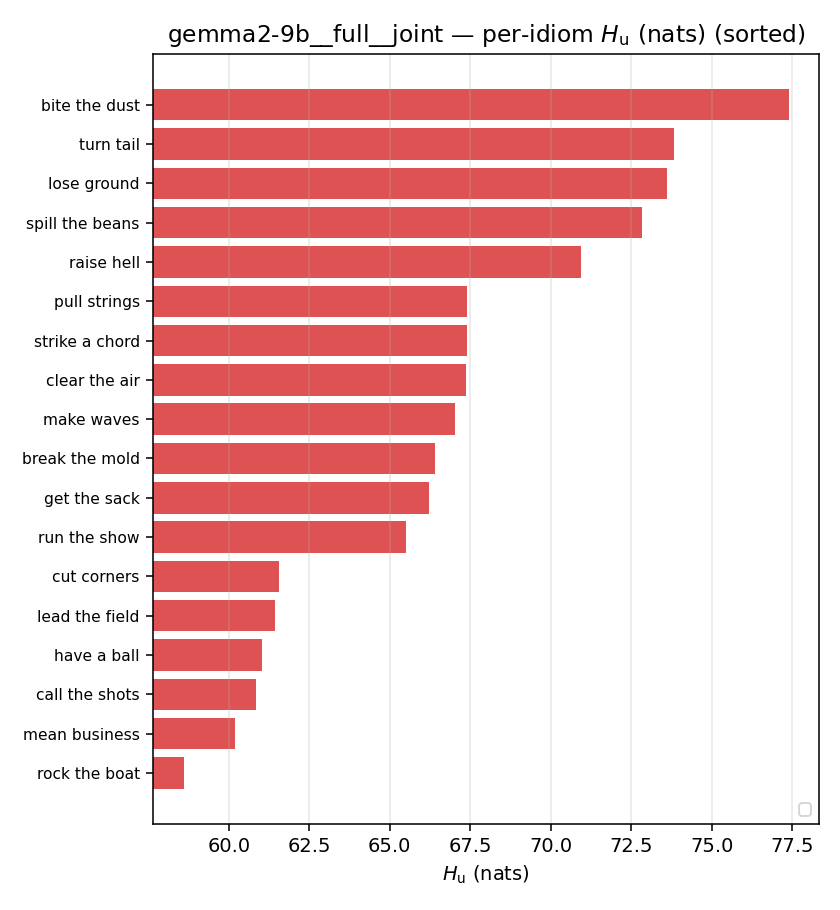 | 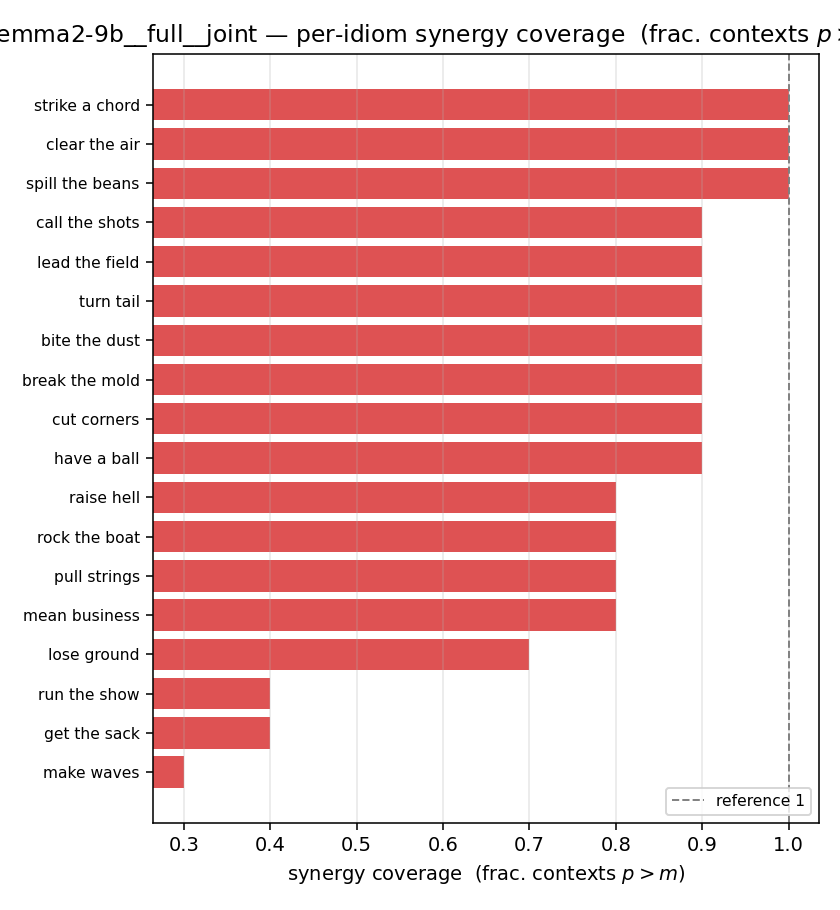 | 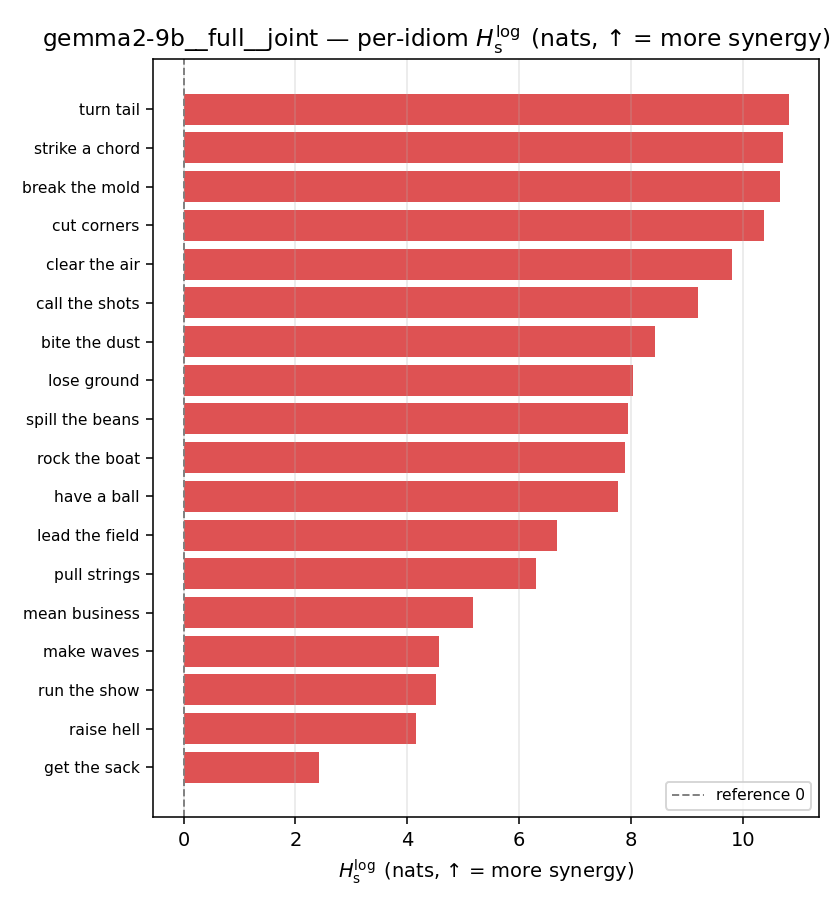 | 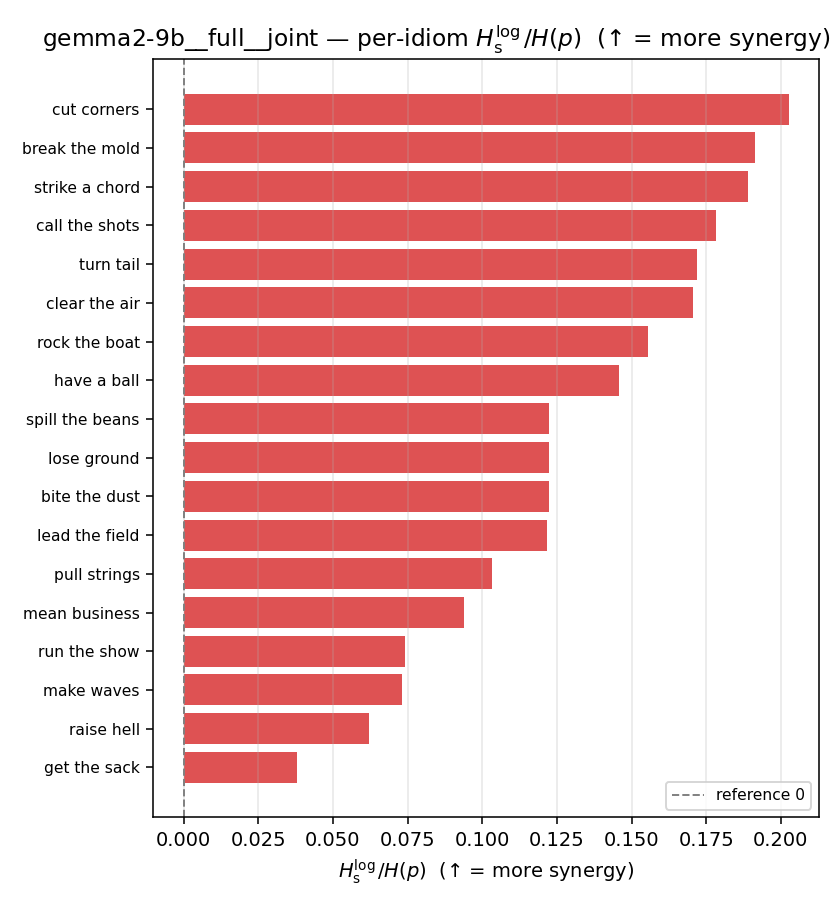 | 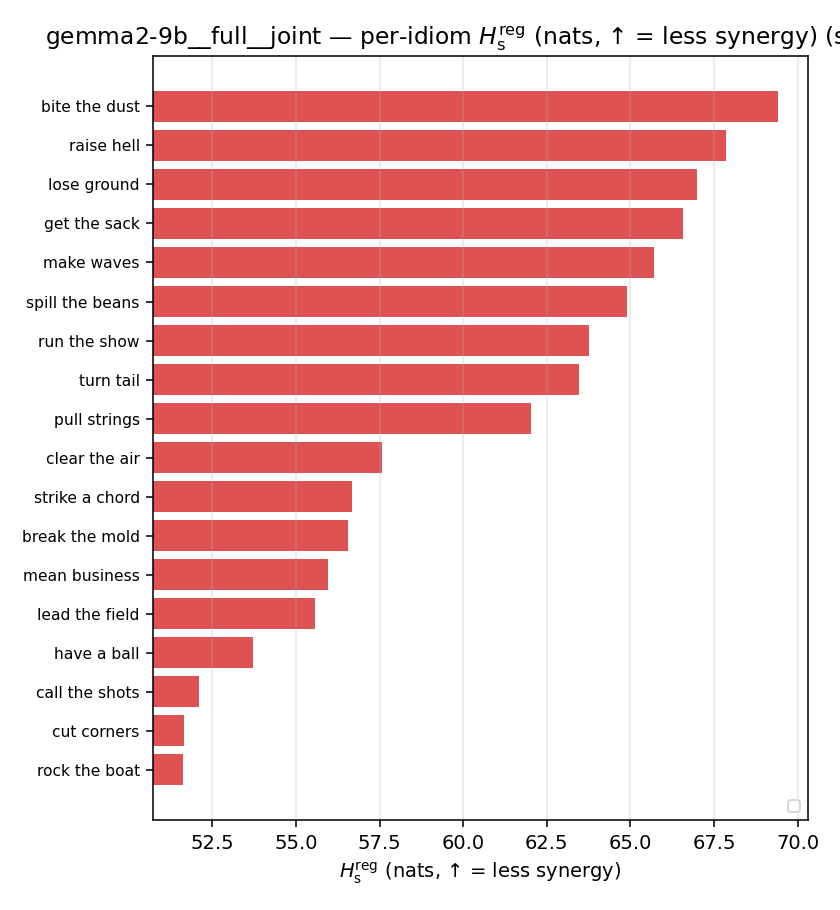 | 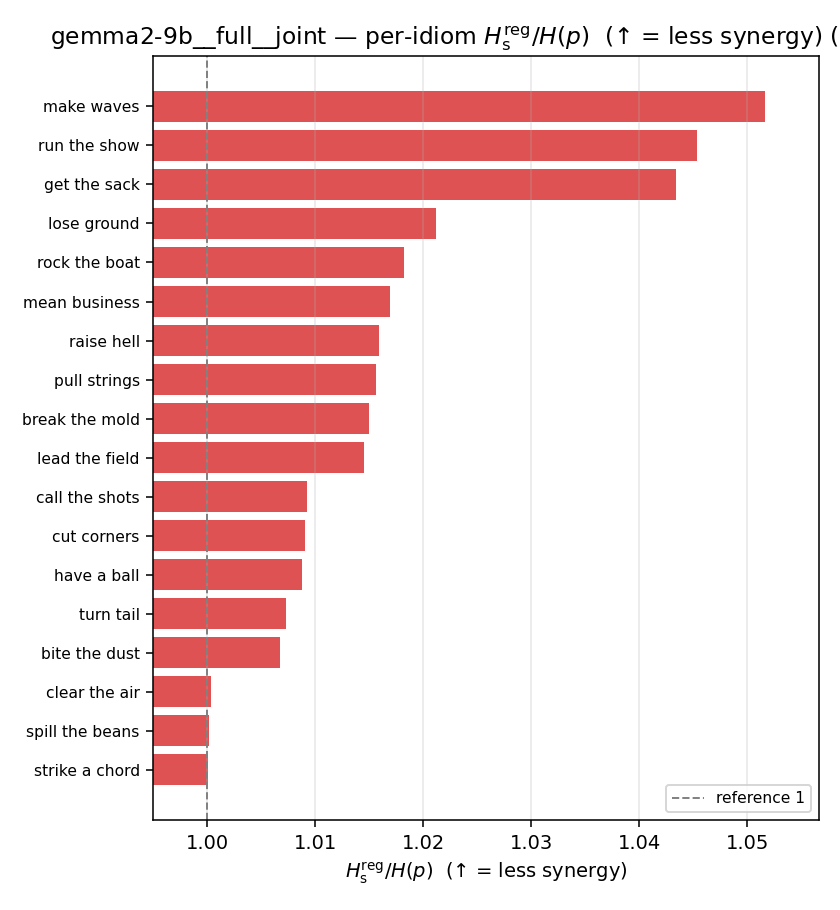 |  |  |
qwen3-8b-base — per-config figures
3×9 grid of figure-type × metric (↑syn = bigger means more synergy, ↓syn = bigger means less). Tables scroll horizontally; “— (no finite values)” marks the original Hs/ratio_s where every phrase was +inf. Click to zoom.
qwen3-8b-base · medial · geo qwen3-8b-base__medial__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 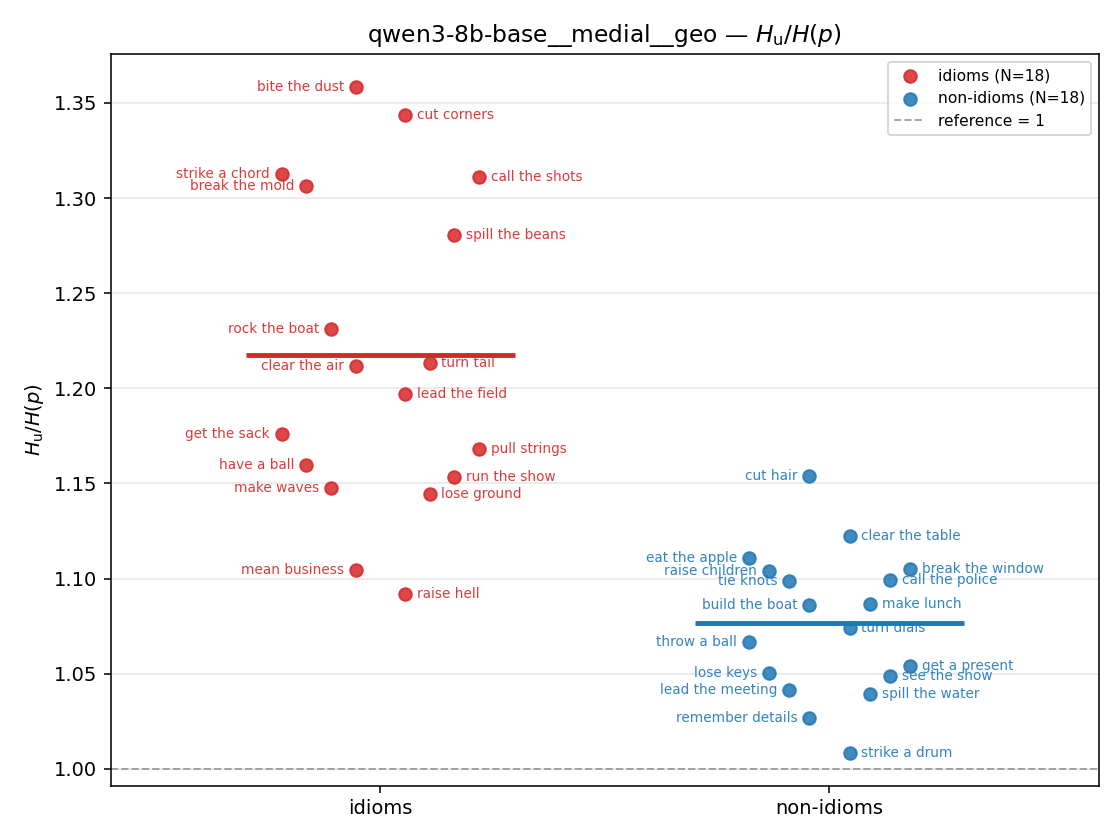 | 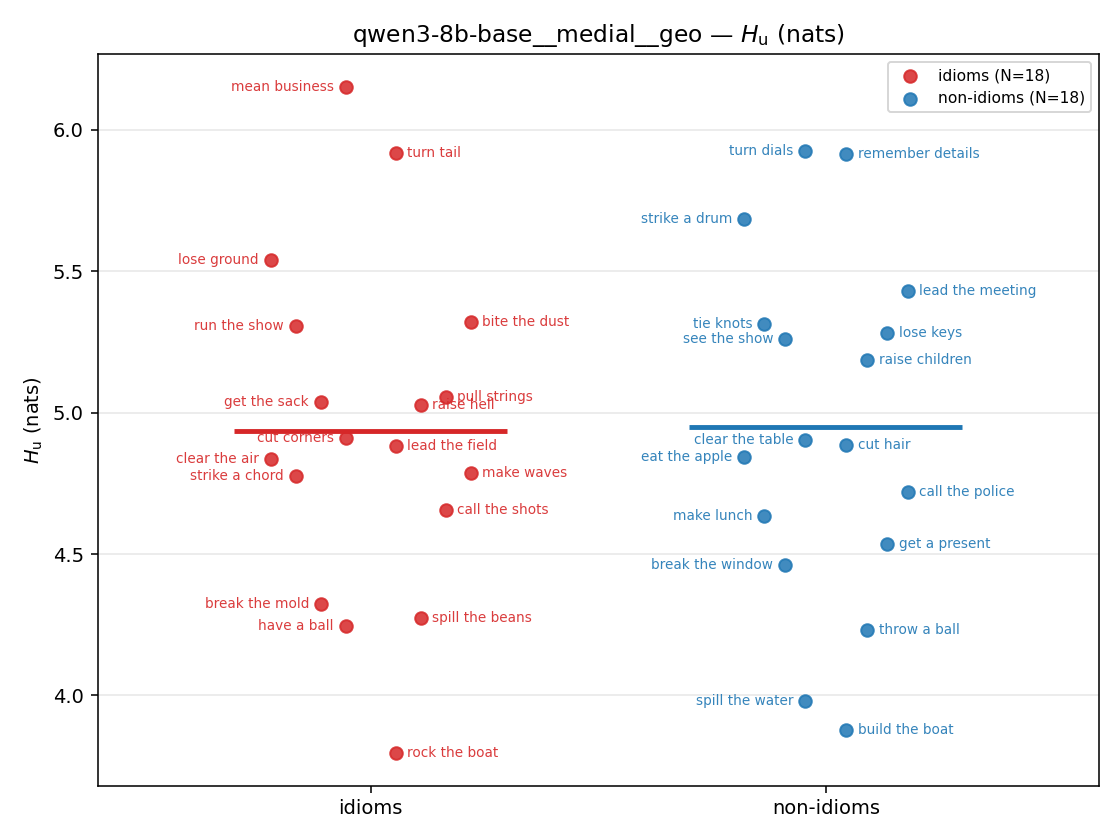 | 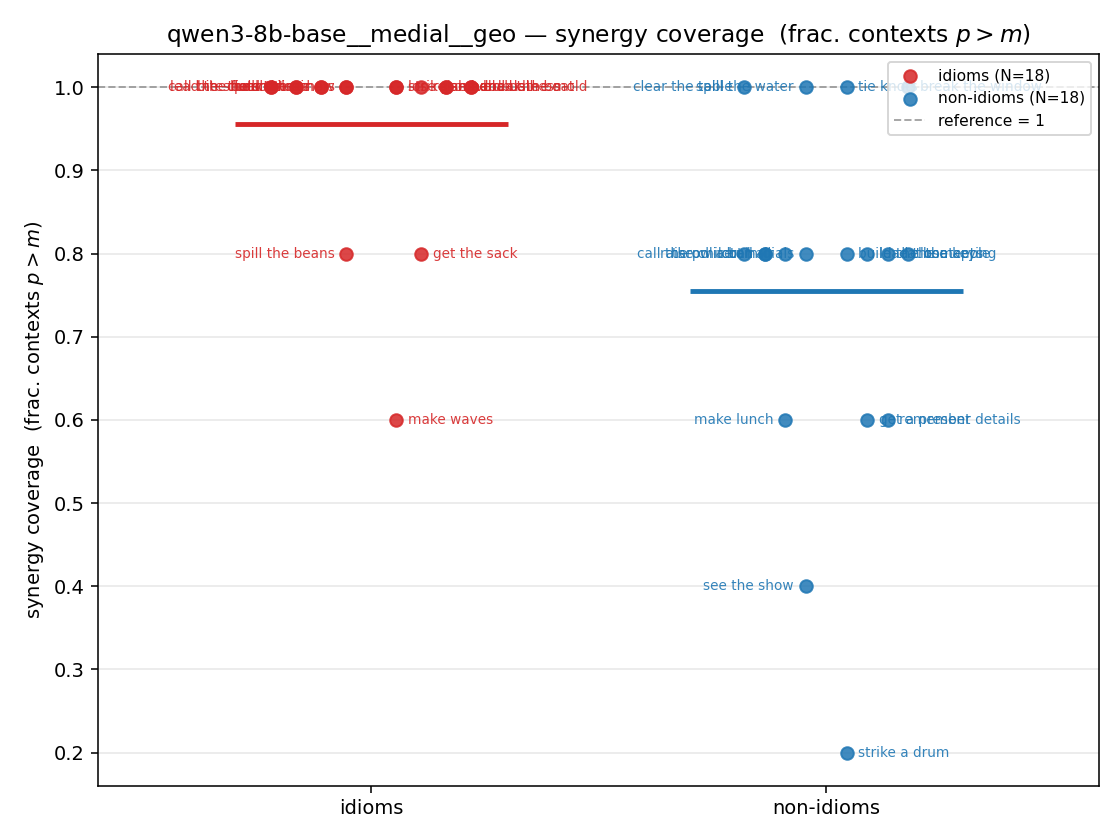 | 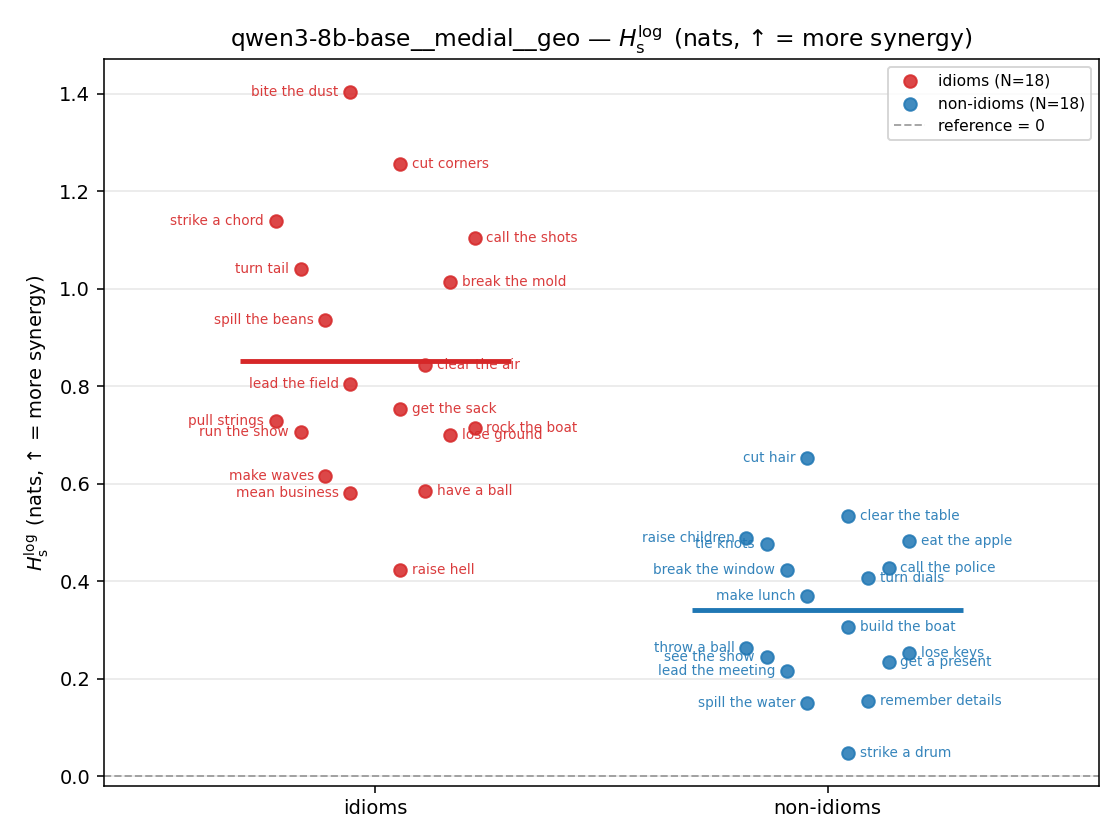 | 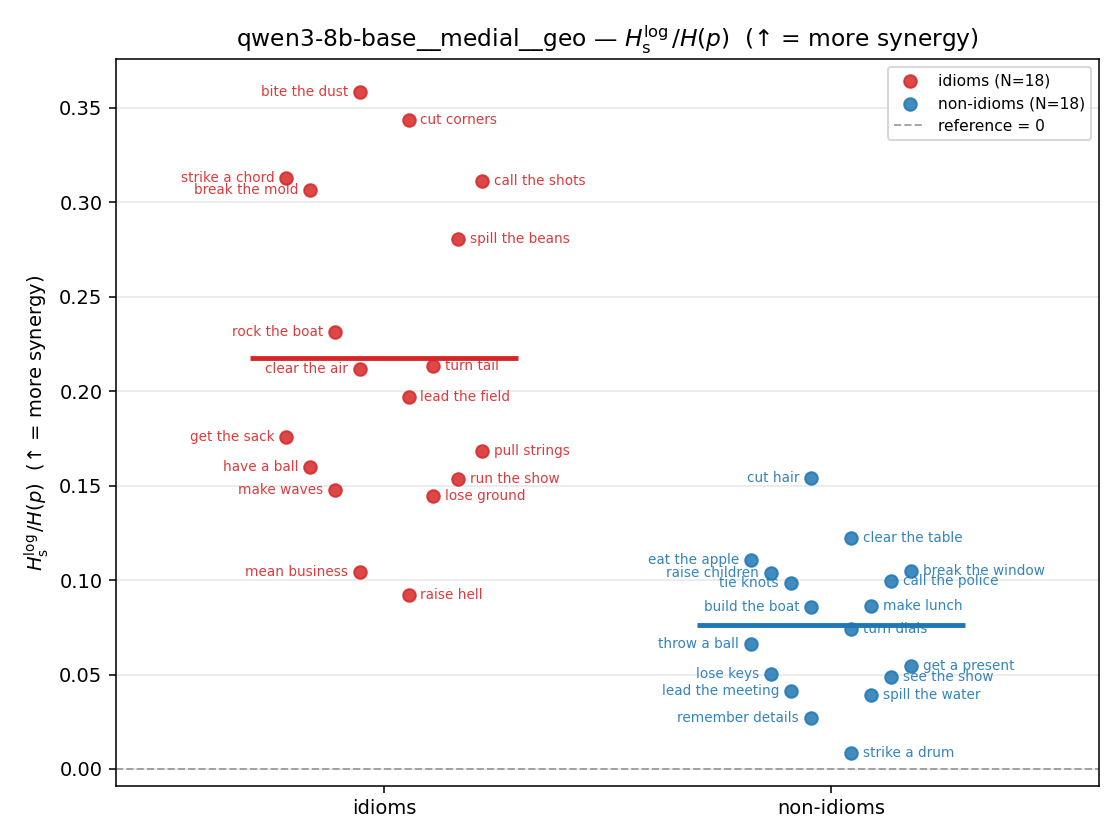 | 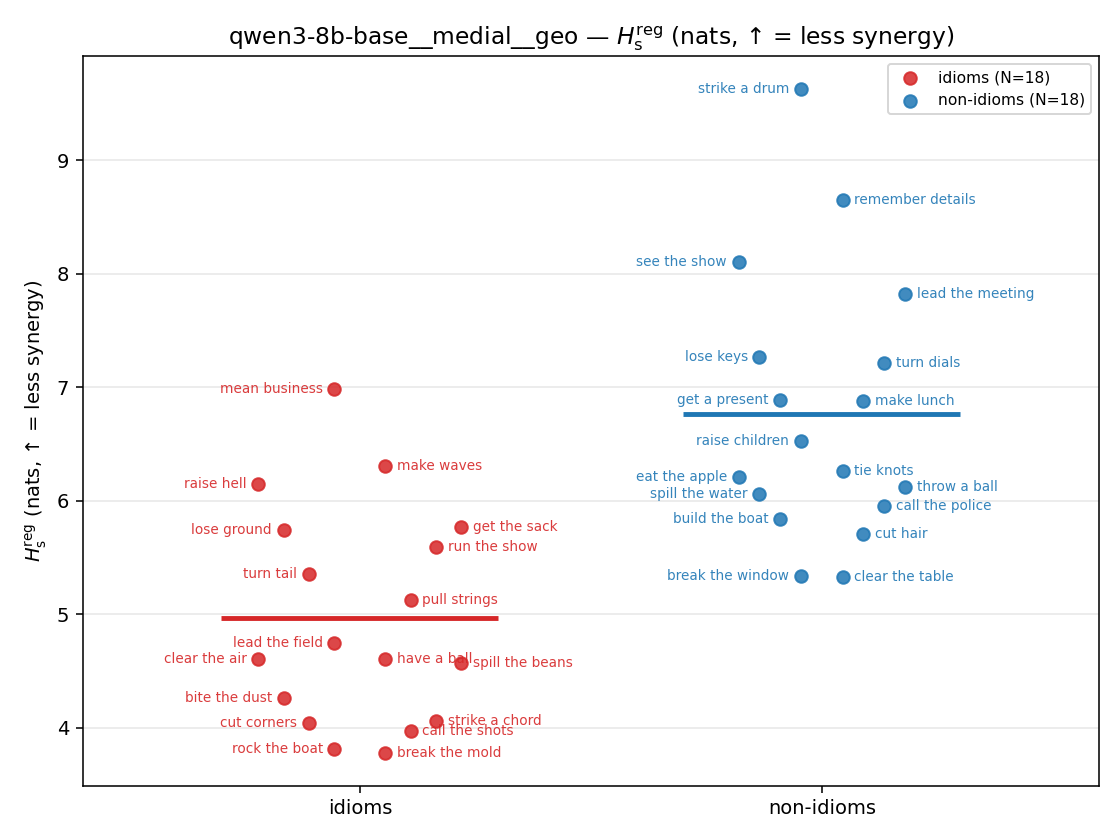 | 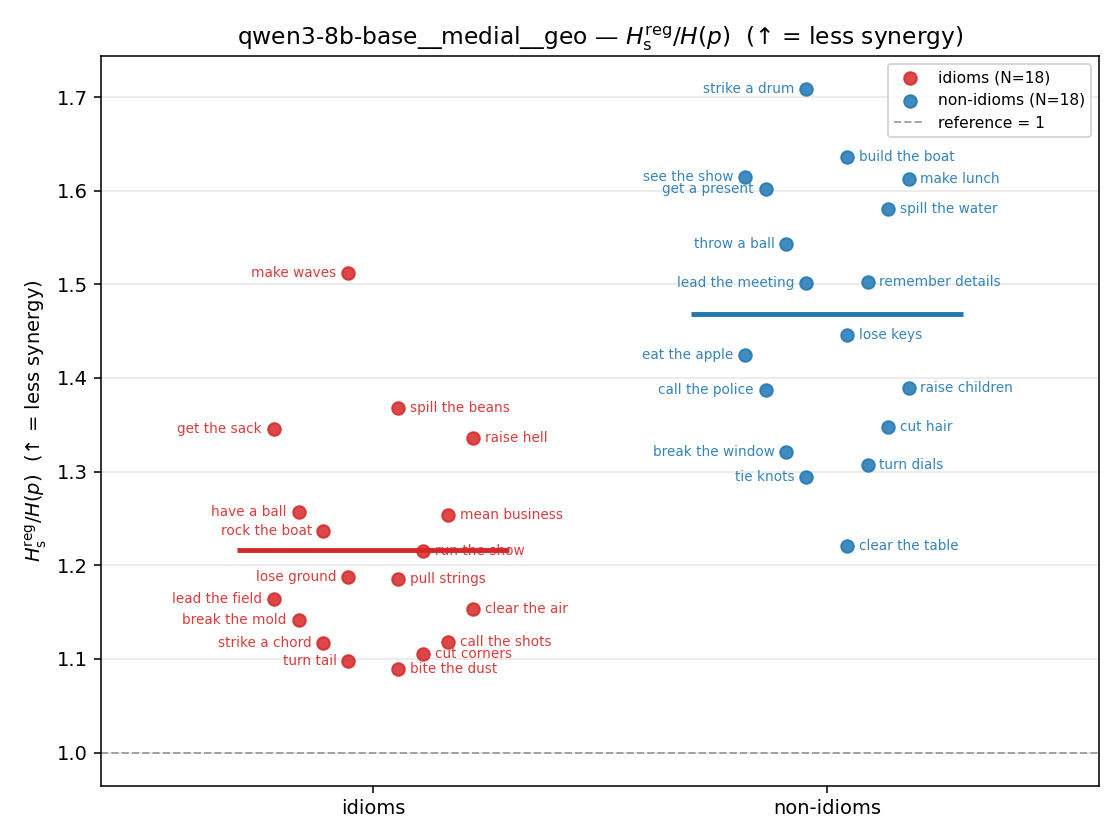 | 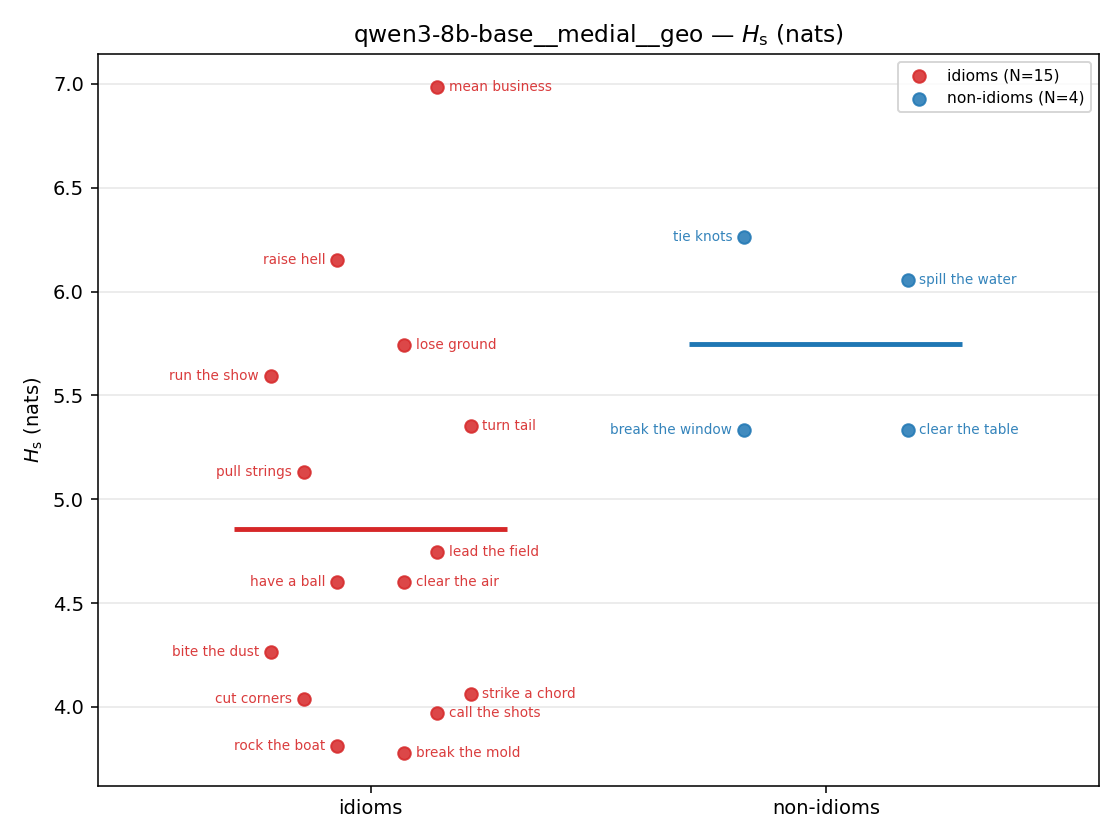 | 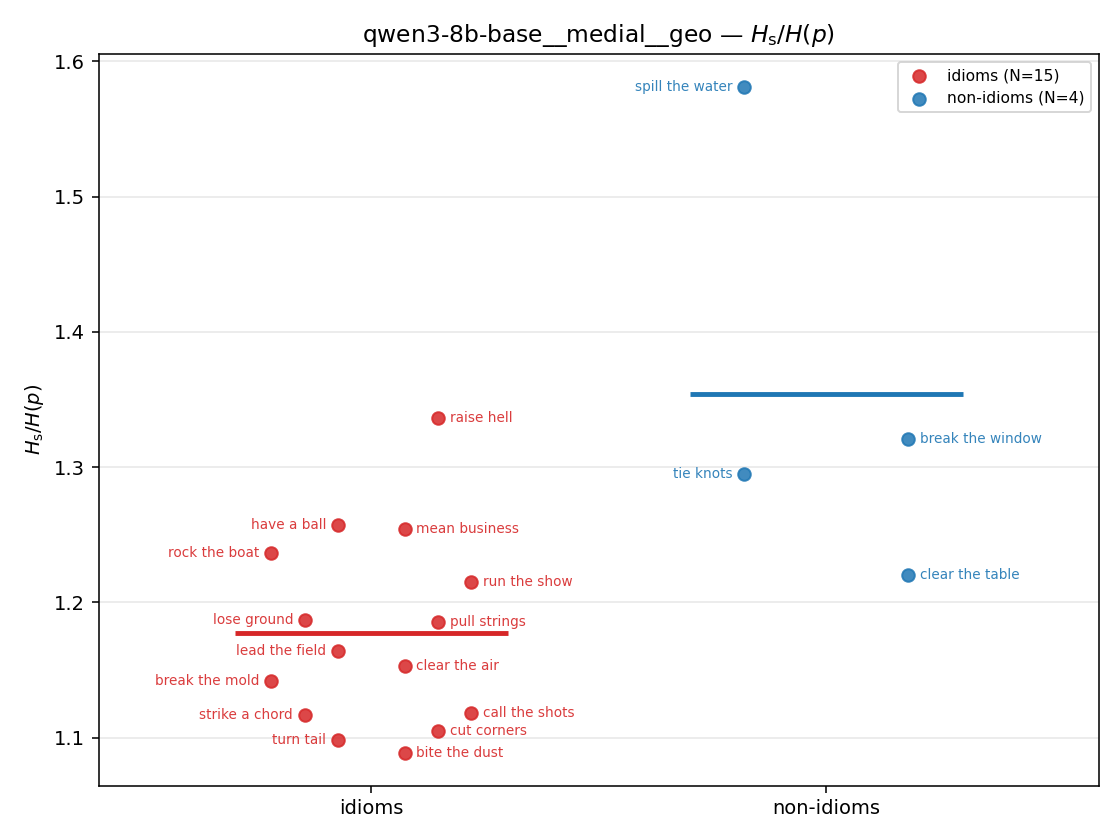 |
| mean ± 95% CI | 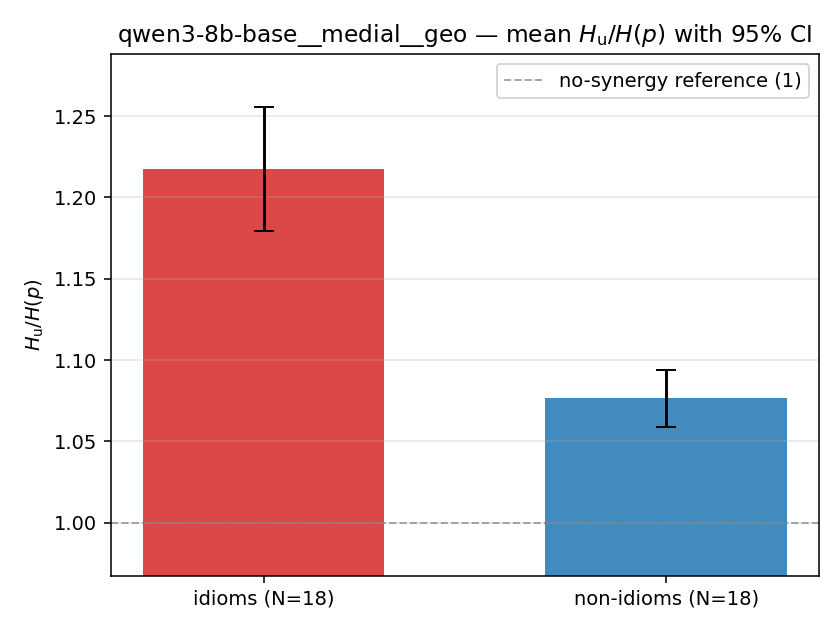 | 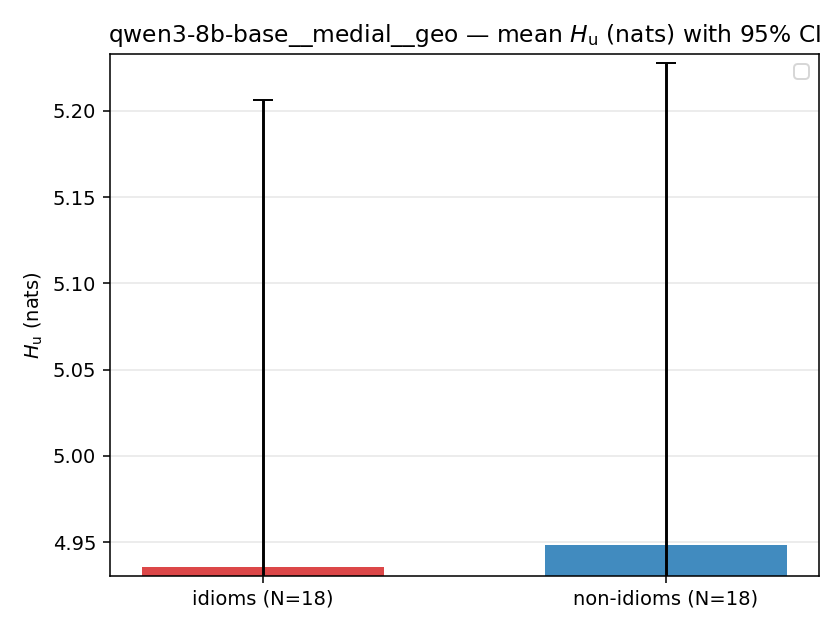 | 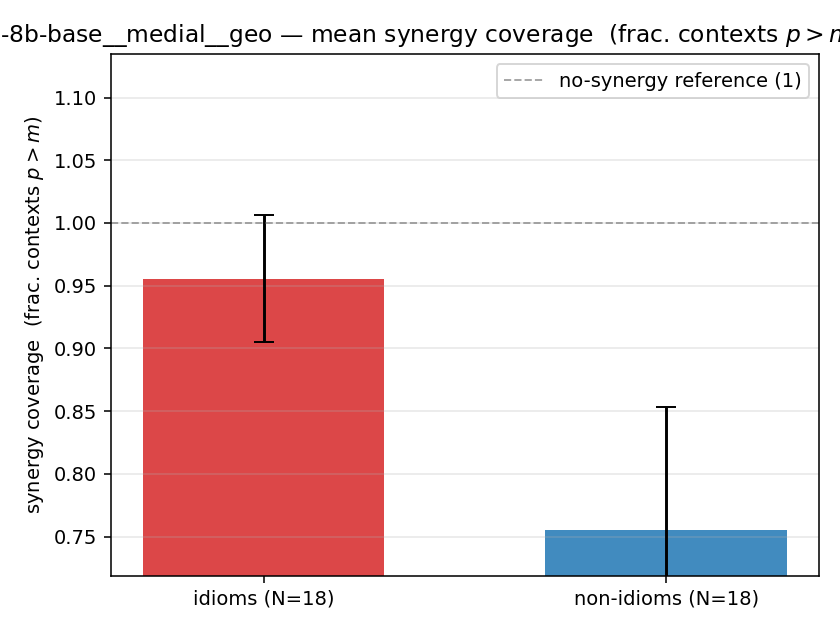 | 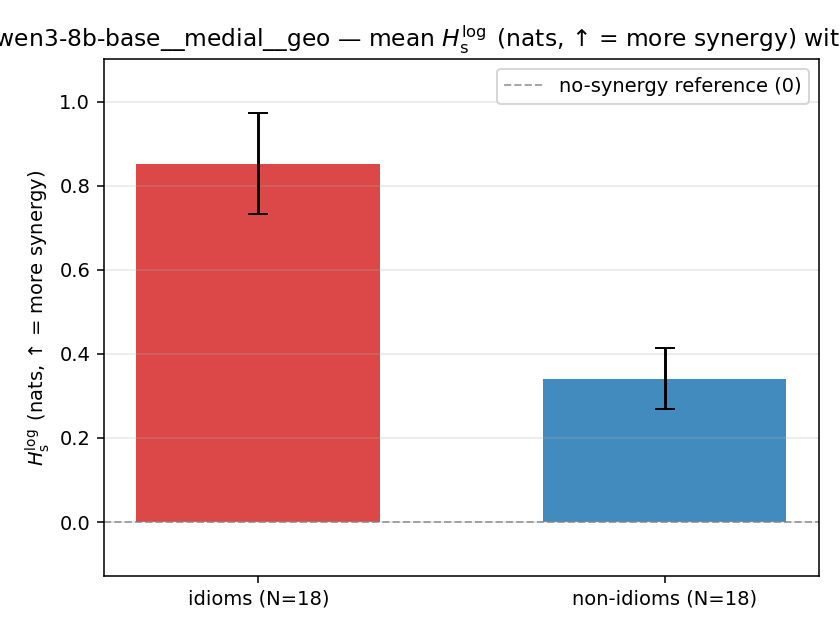 | 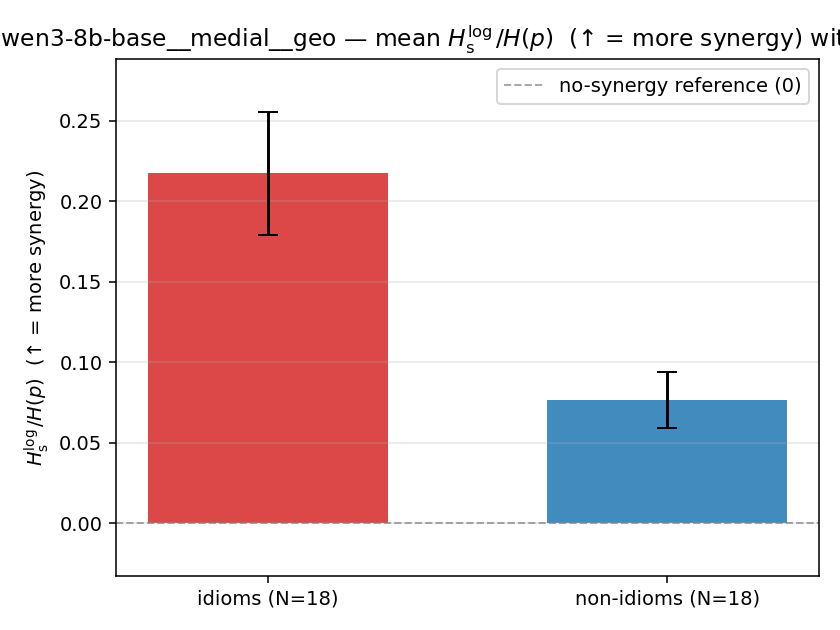 | 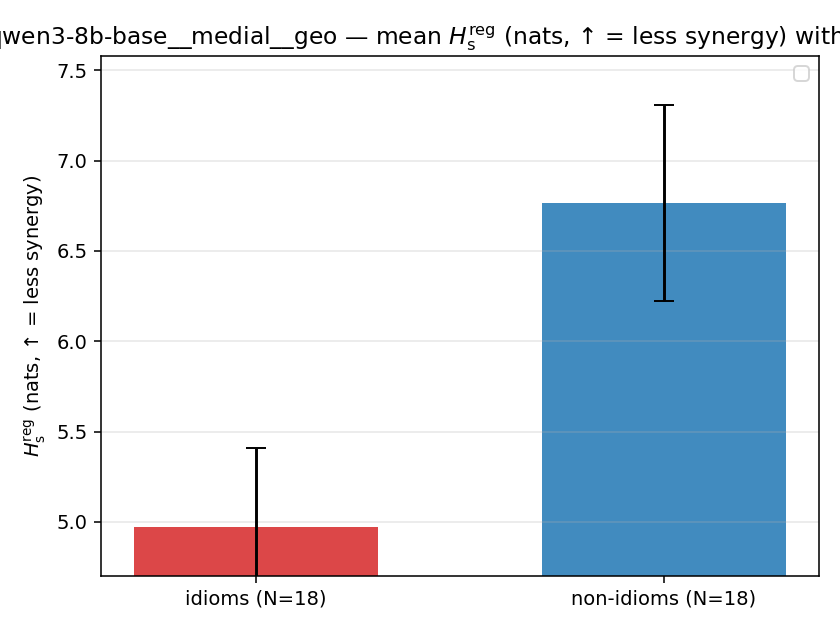 | 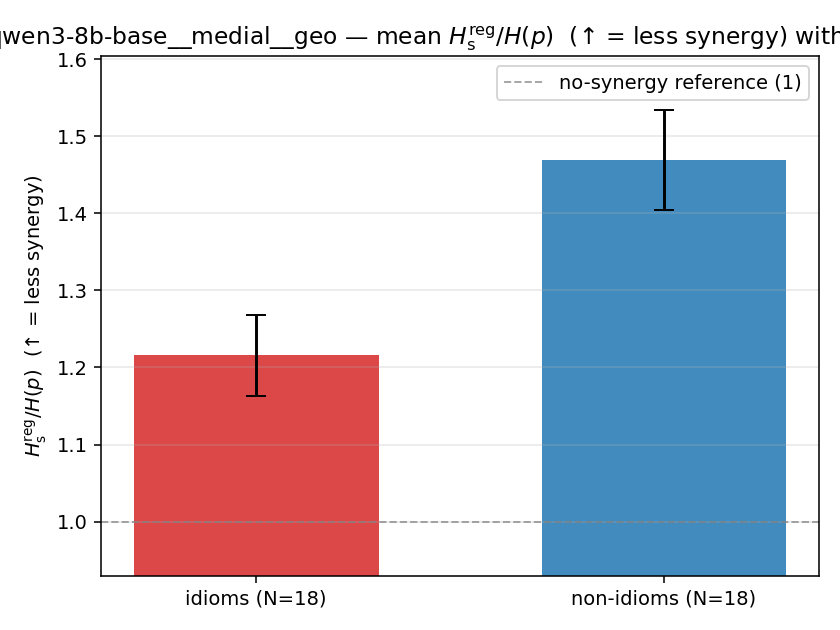 | 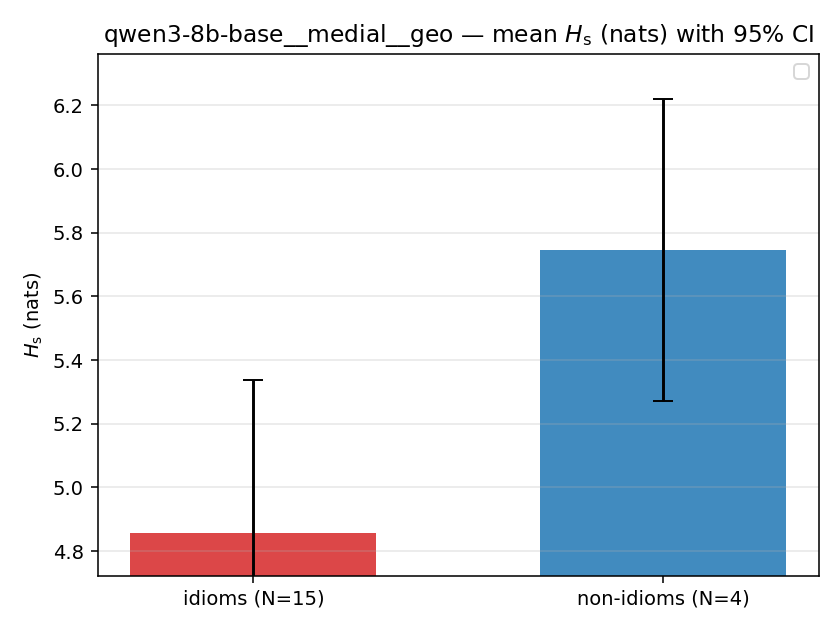 | 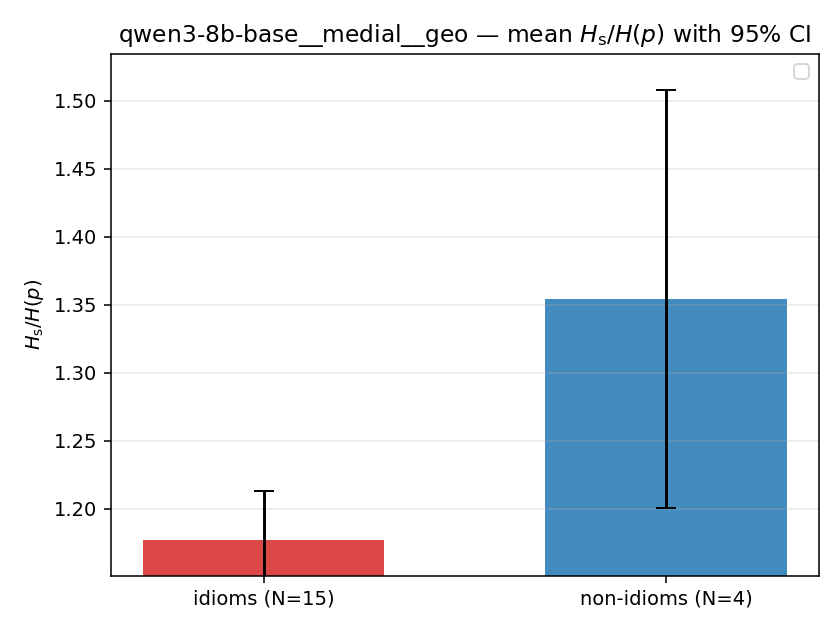 |
| per-idiom (sorted) | 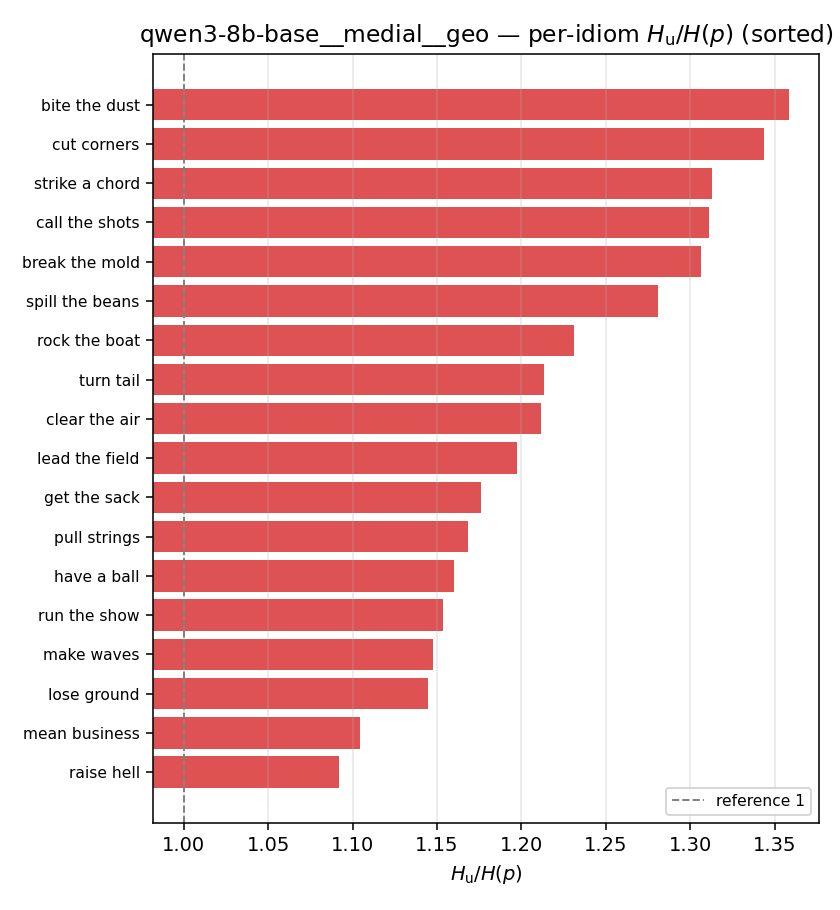 | 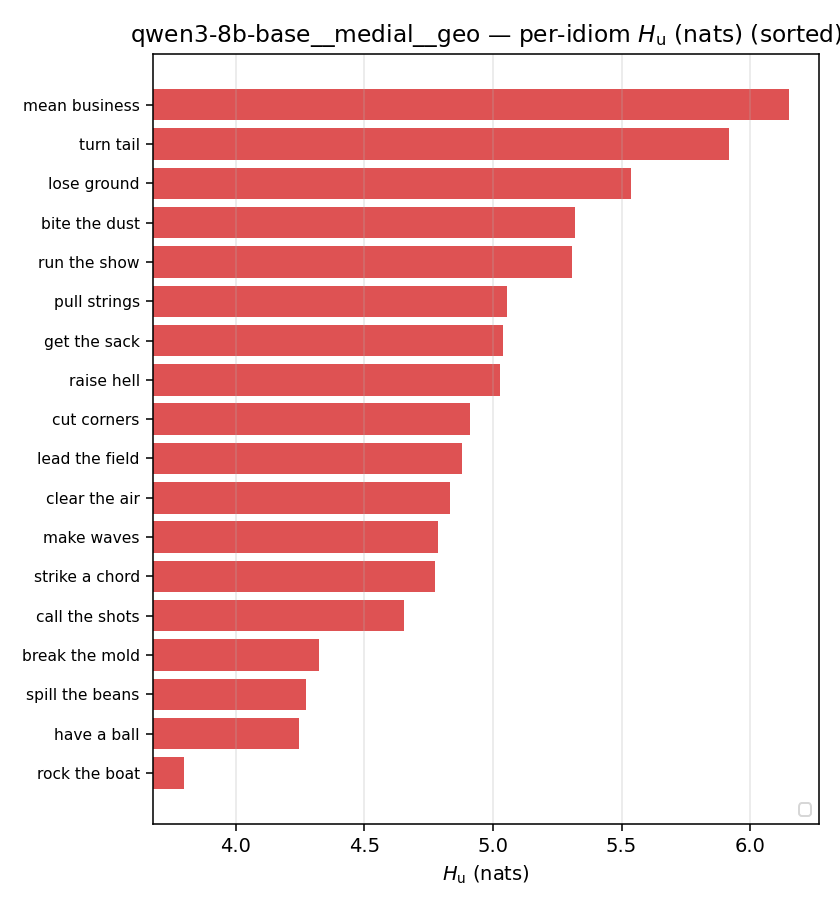 | 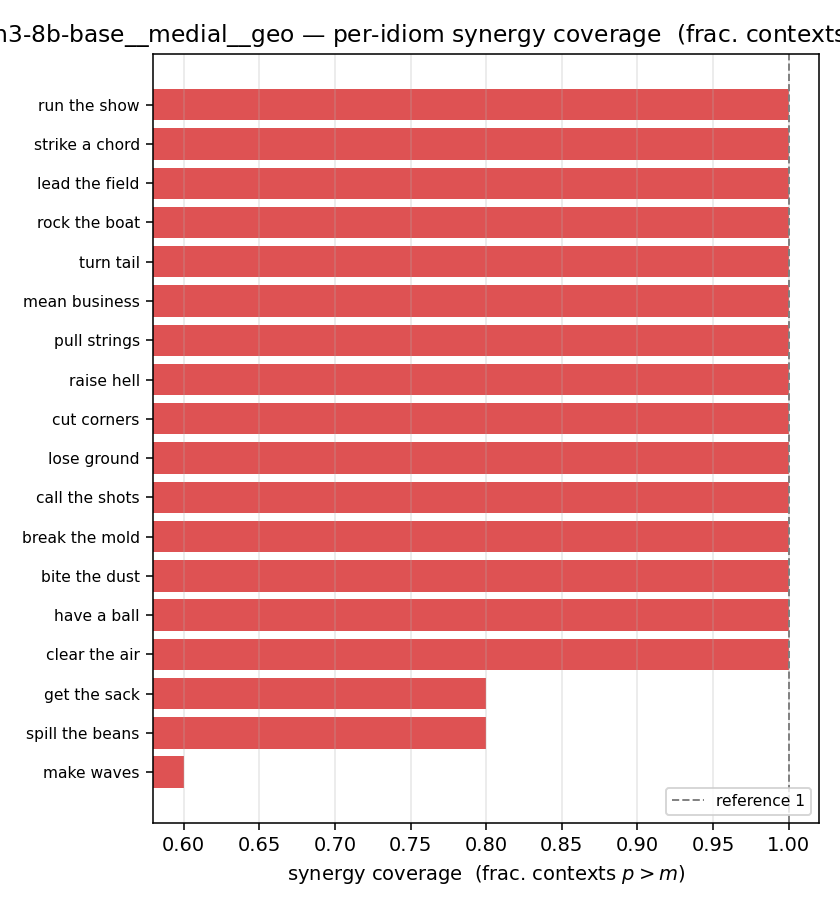 | 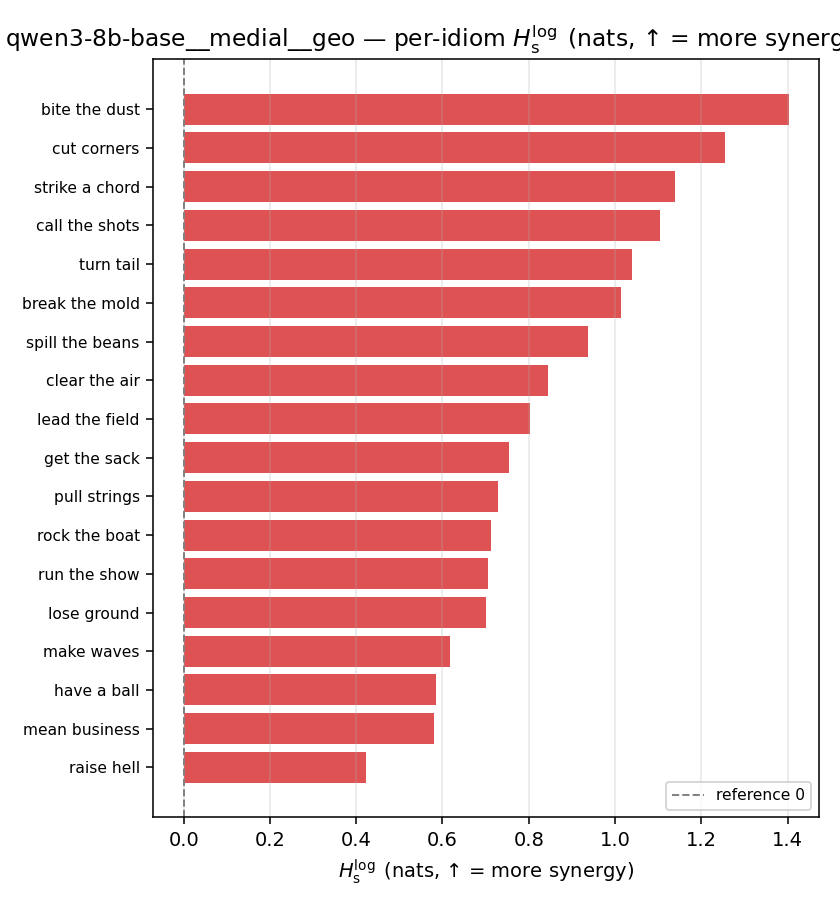 | 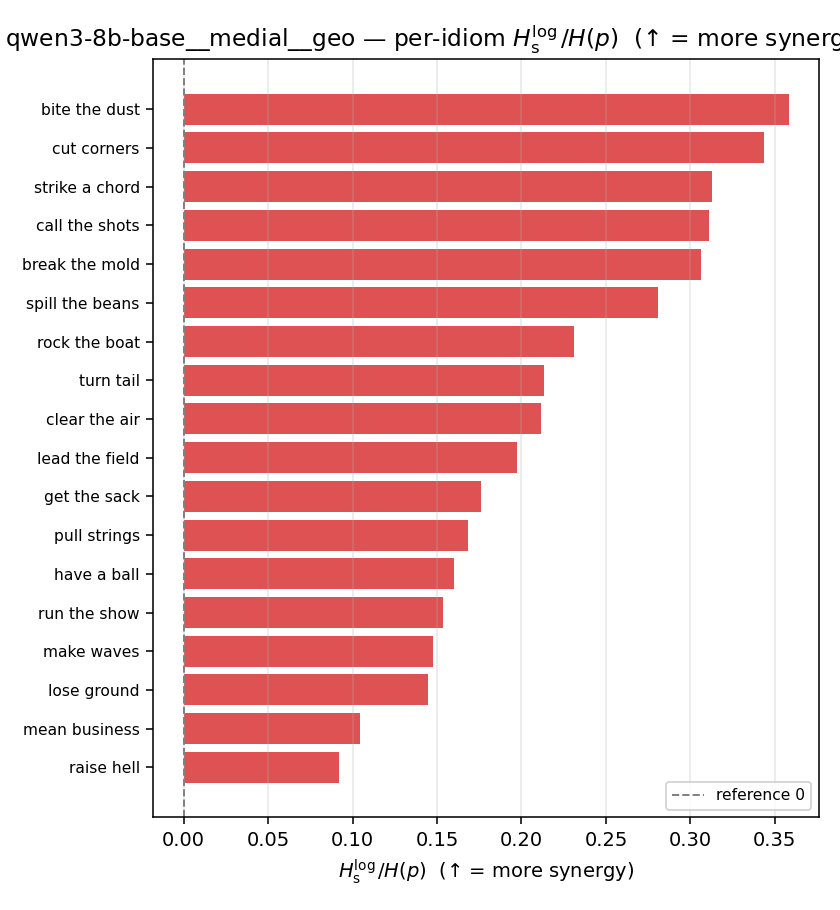 | 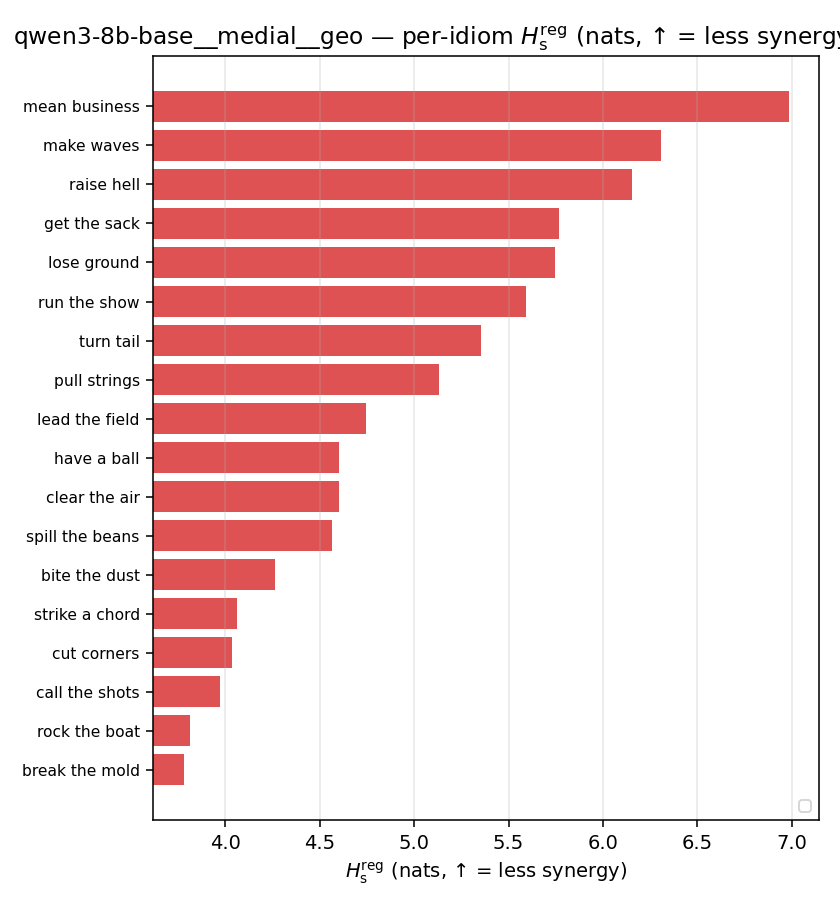 | 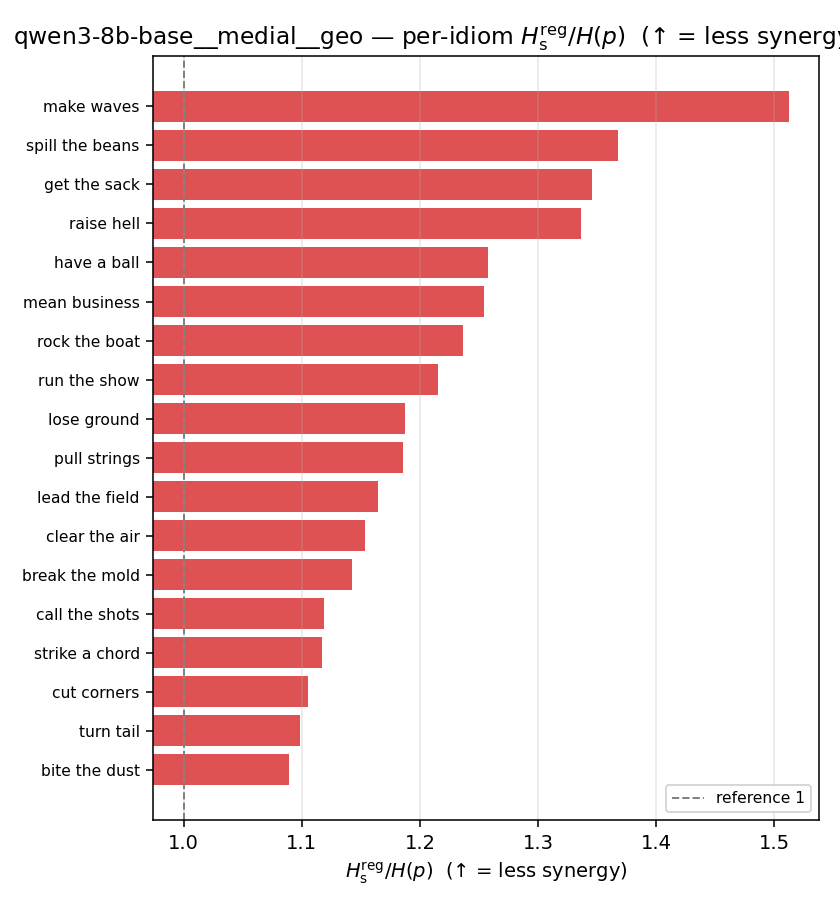 | 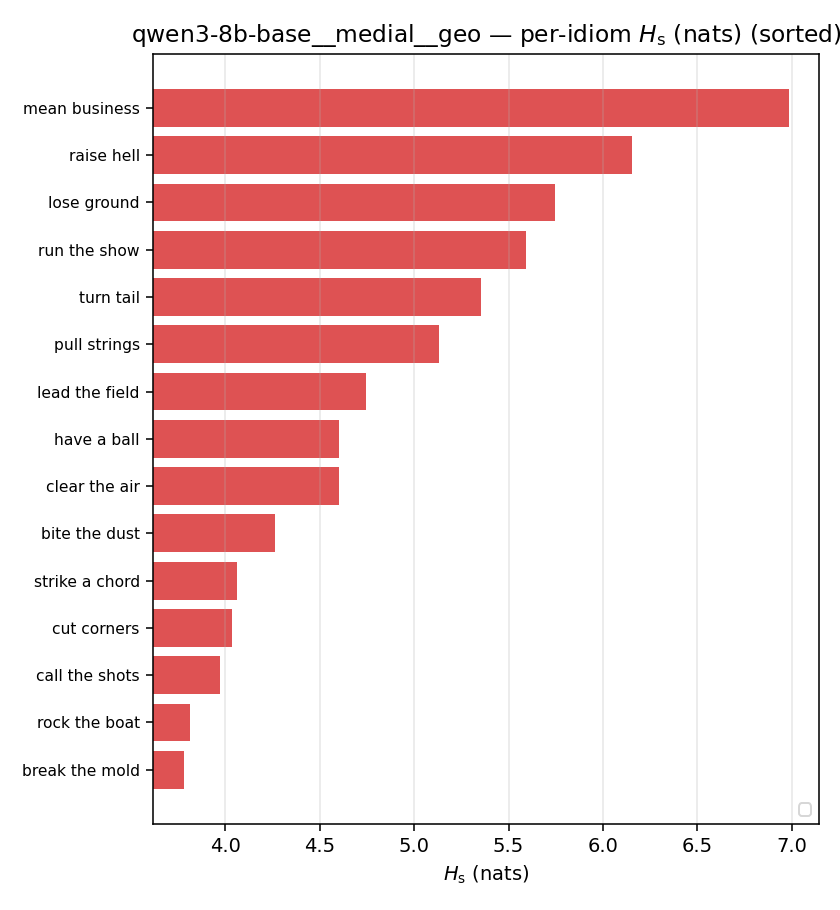 | 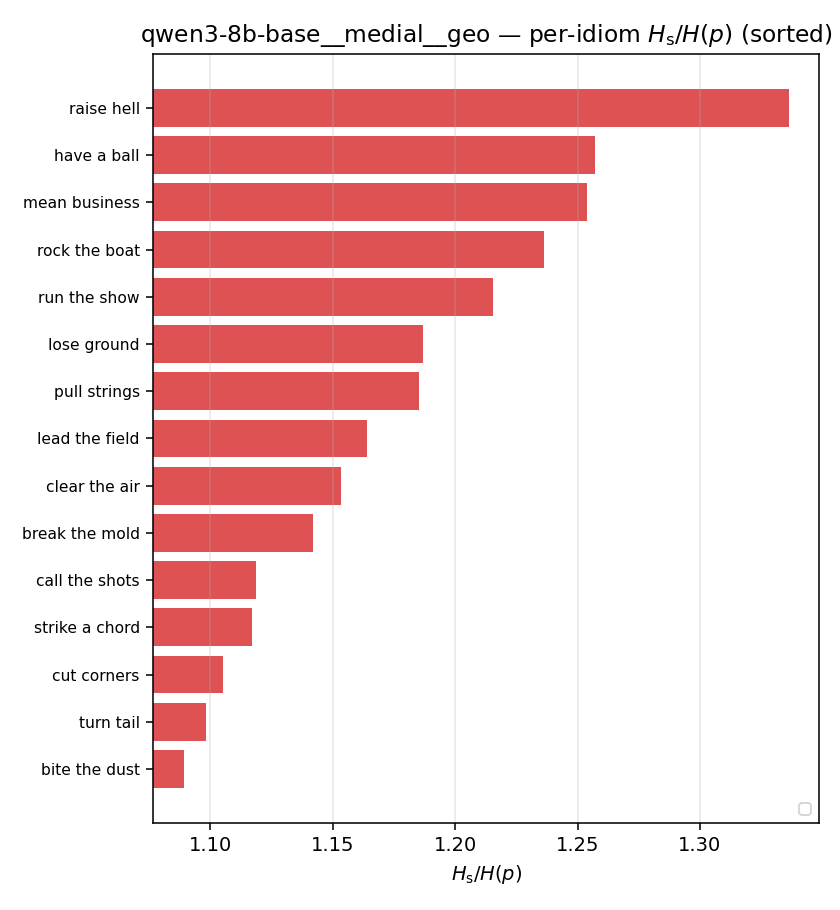 |
qwen3-8b-base · medial · joint qwen3-8b-base__medial__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 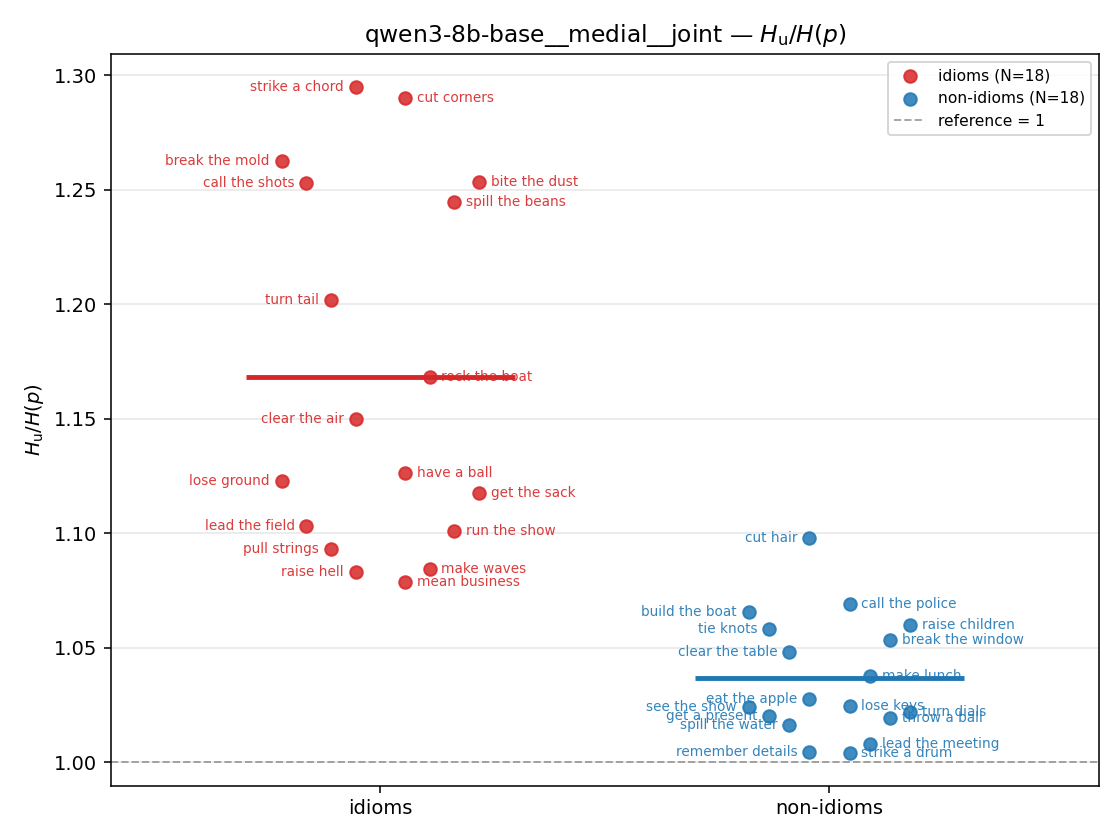 | 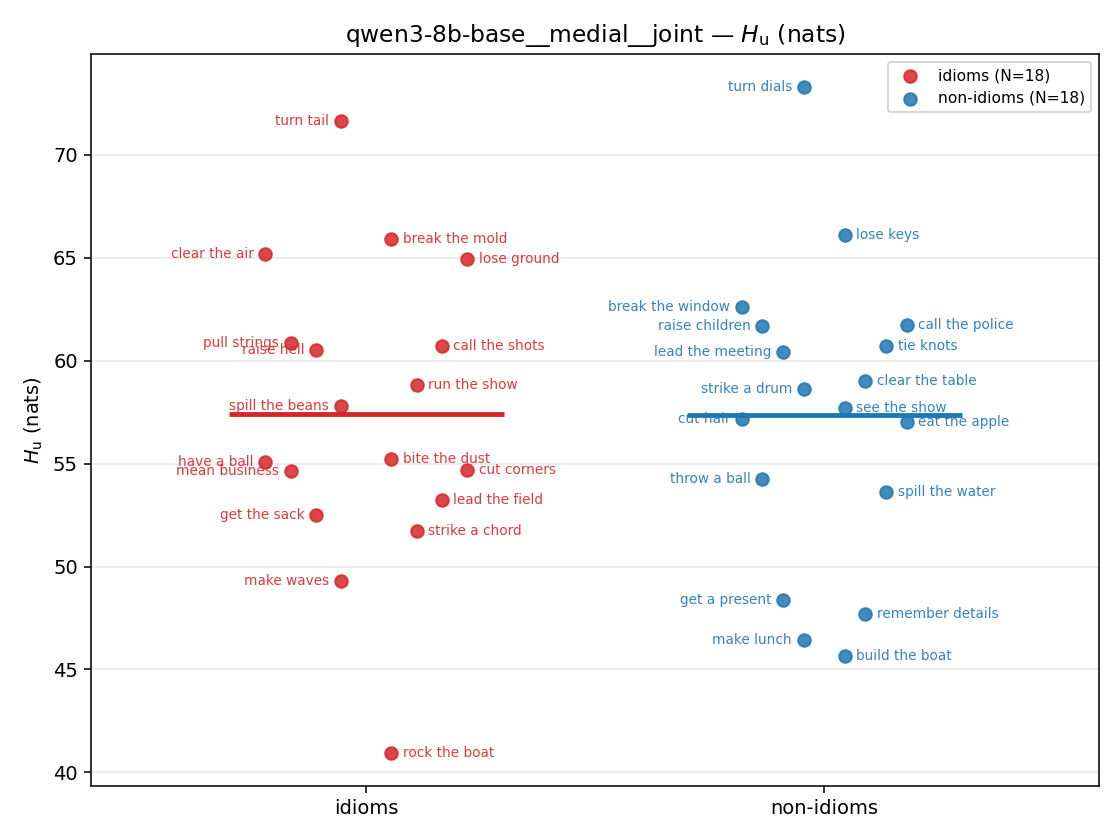 | 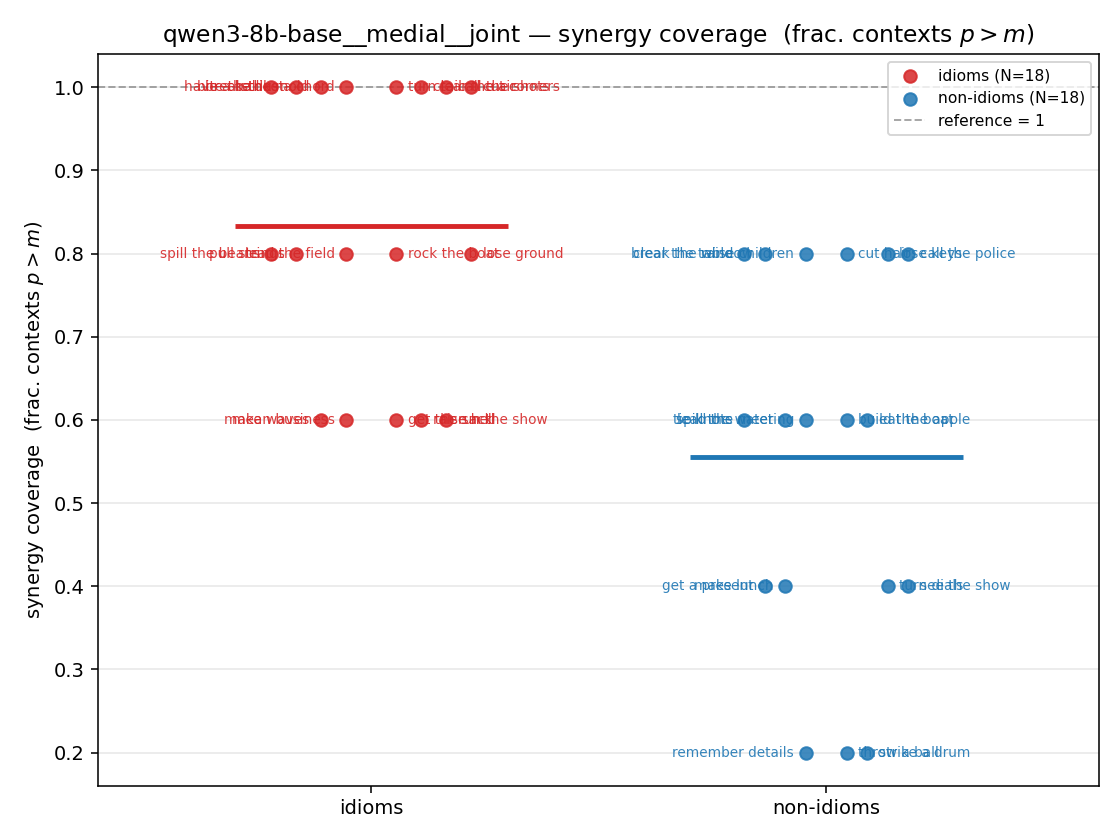 | 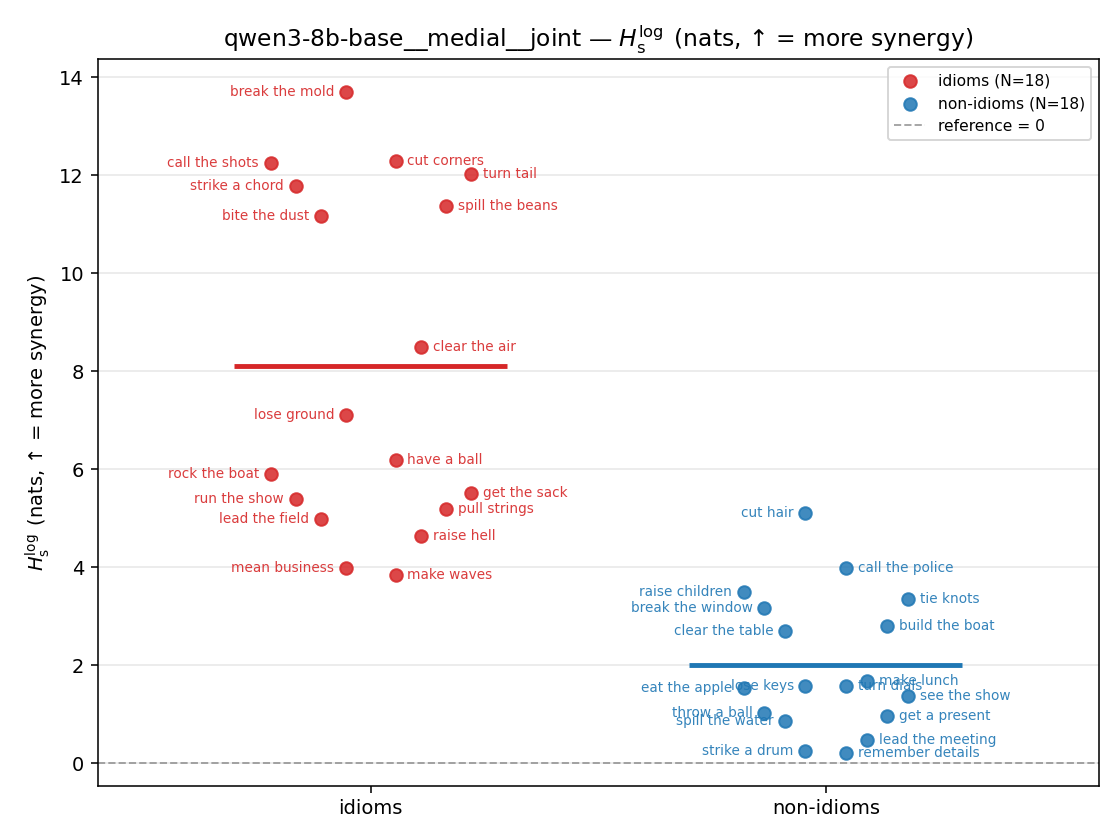 | 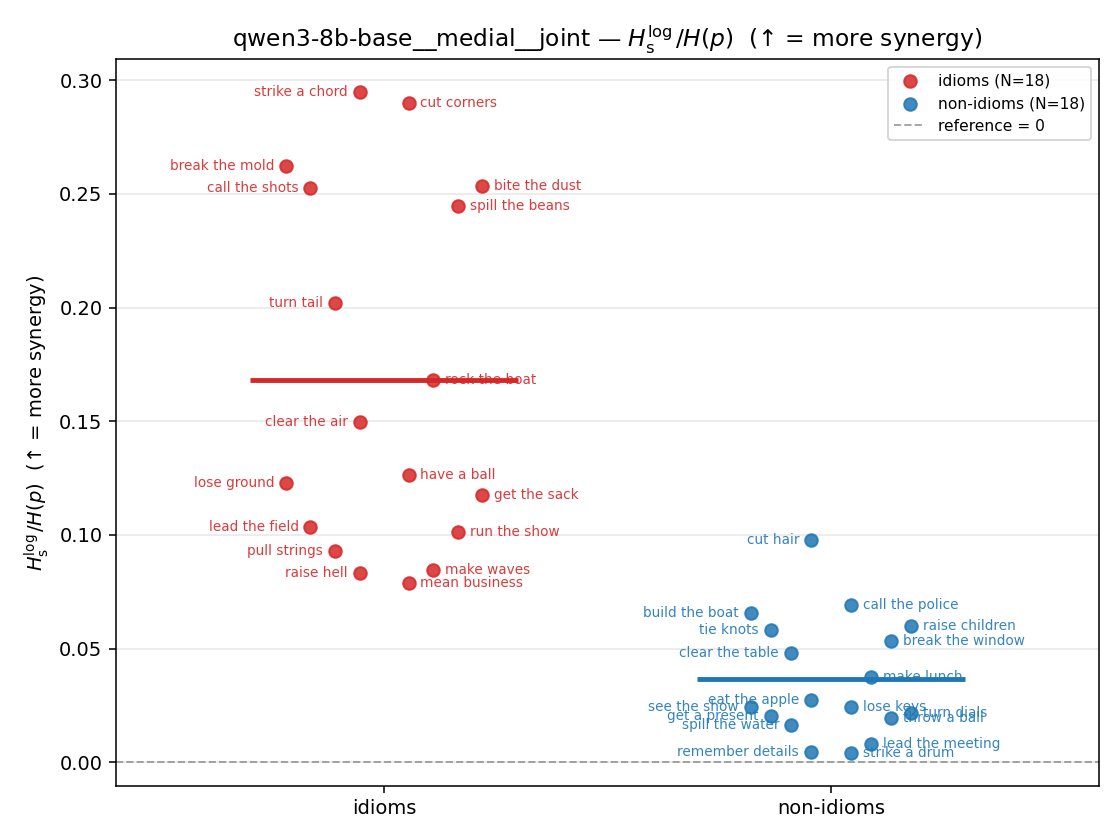 | 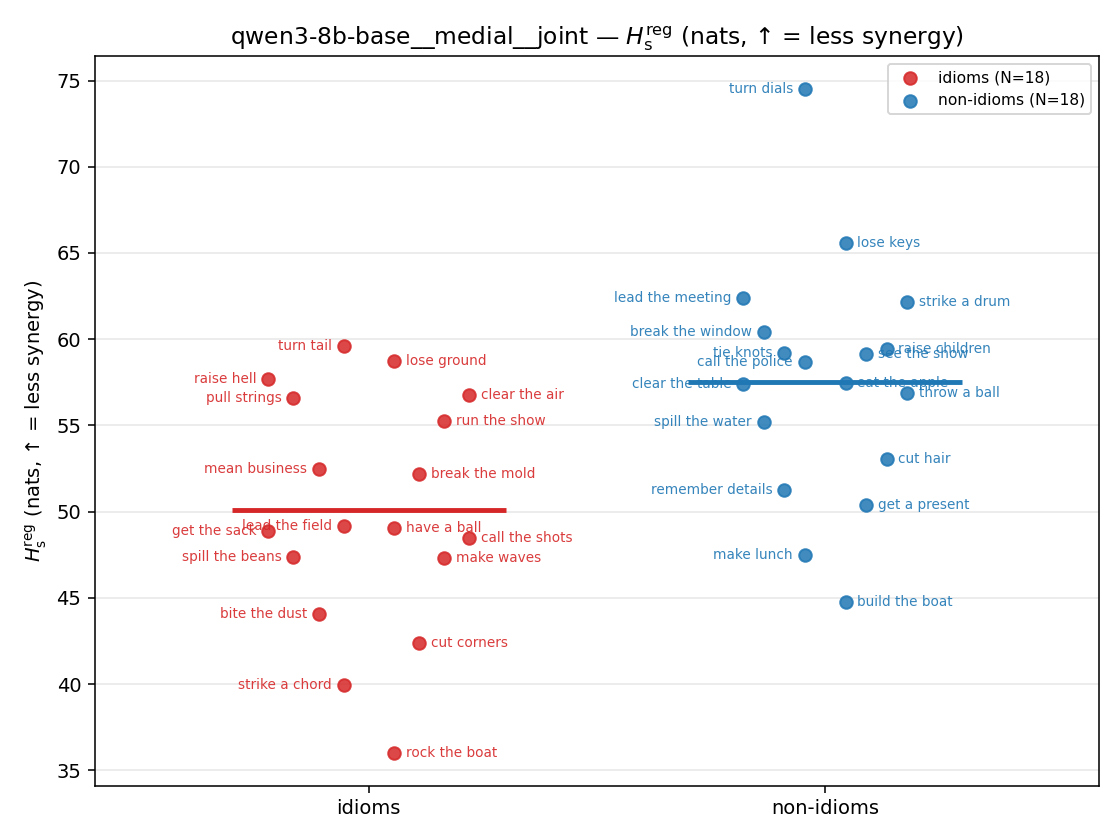 | 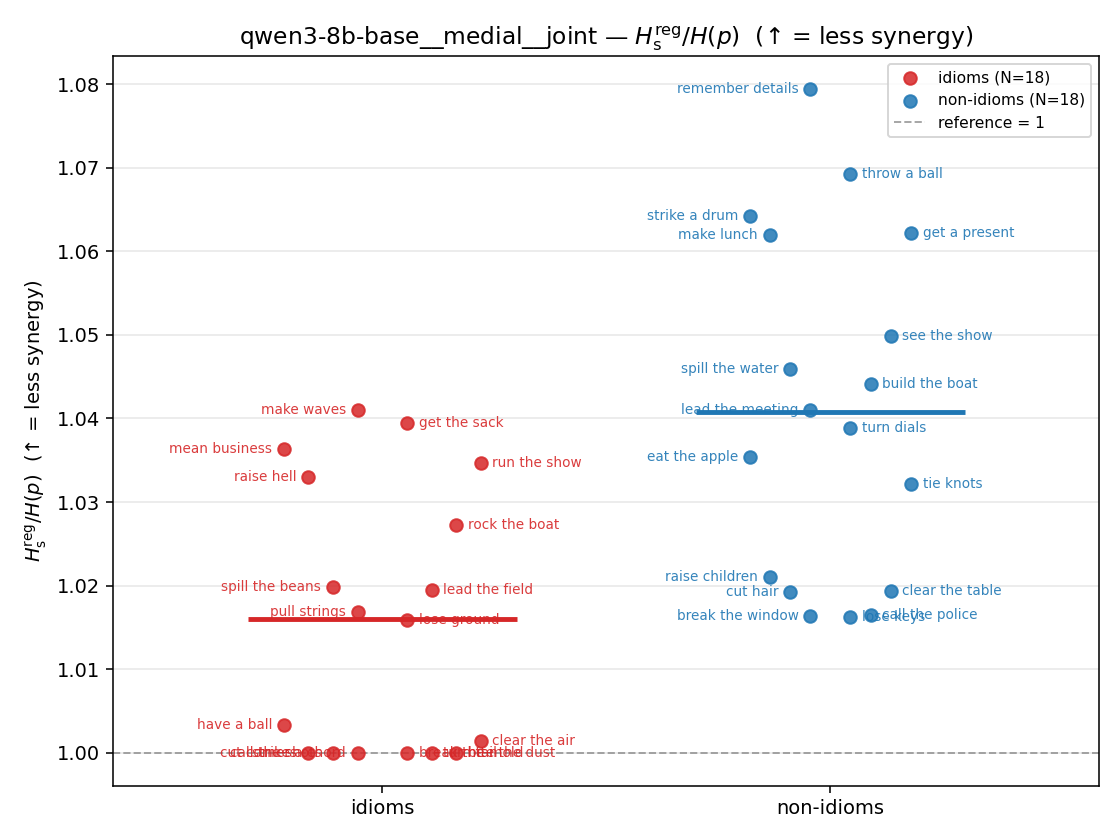 | — (no finite values) | — (no finite values) |
| mean ± 95% CI | 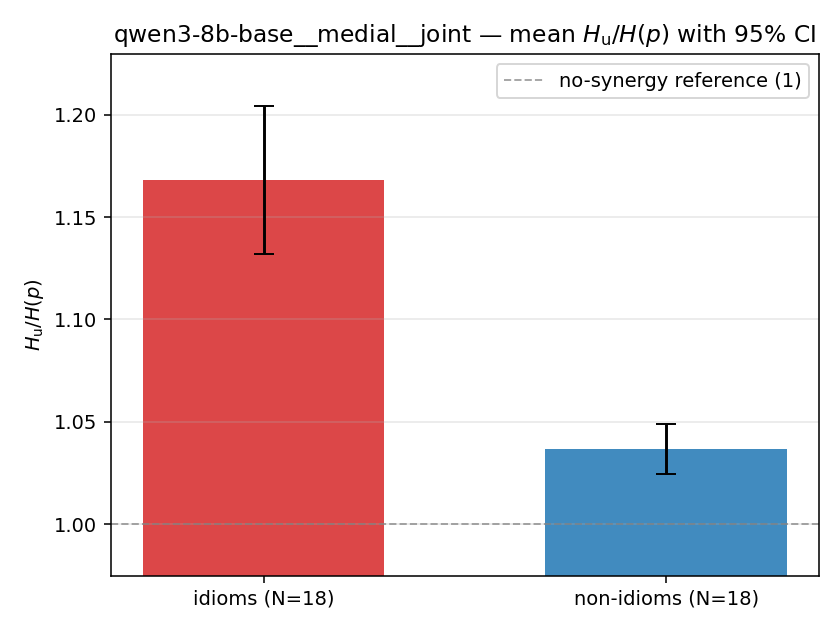 | 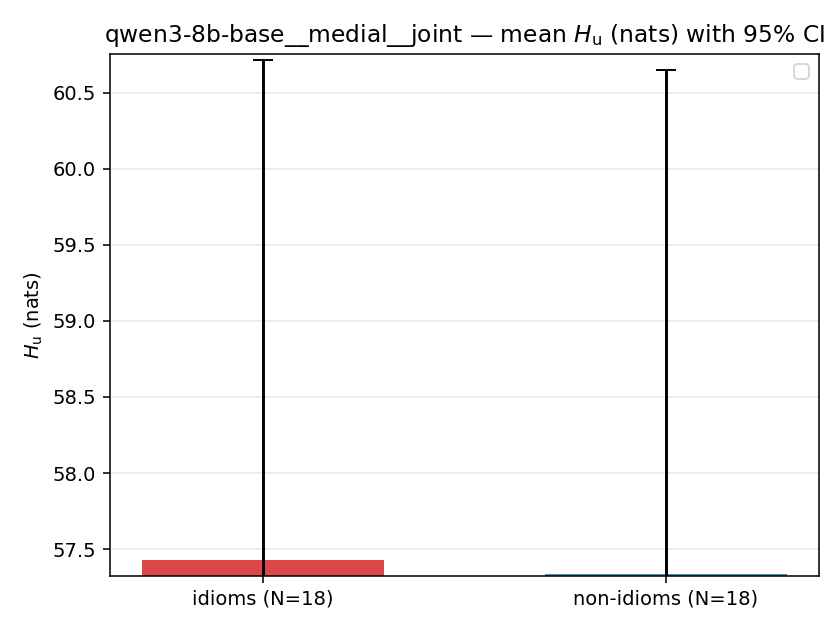 | 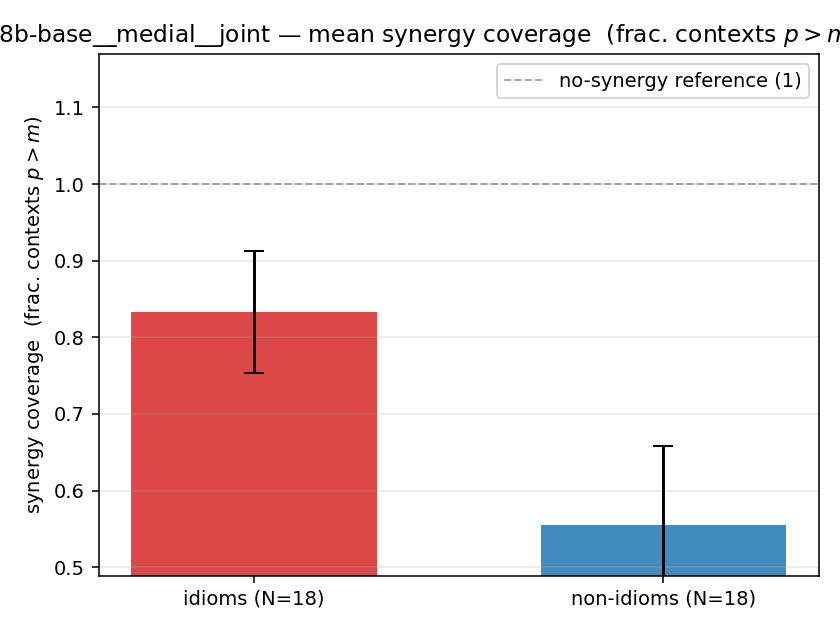 | 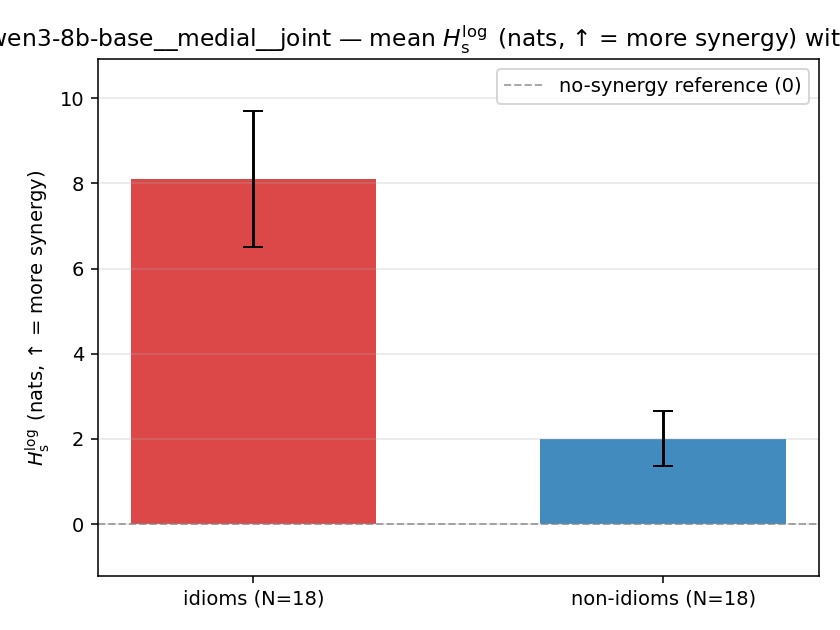 | 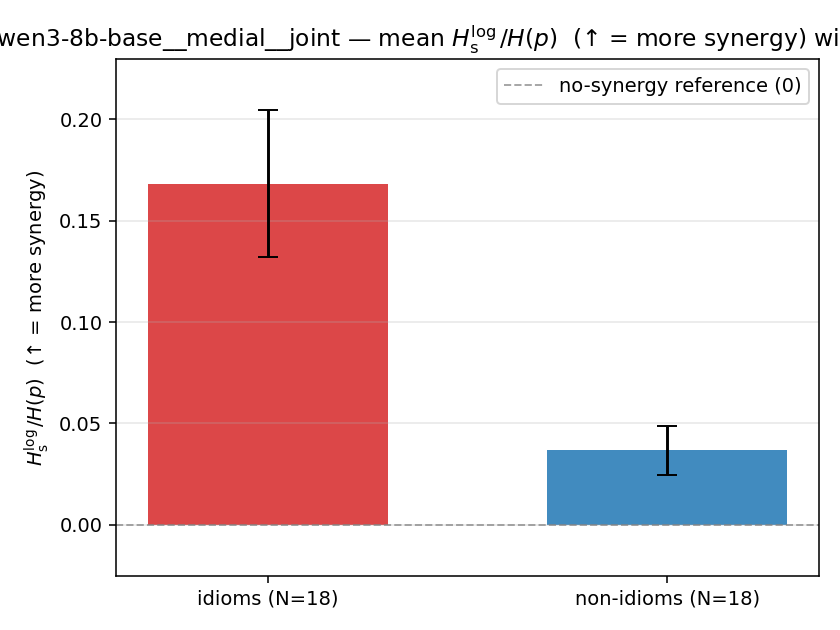 | 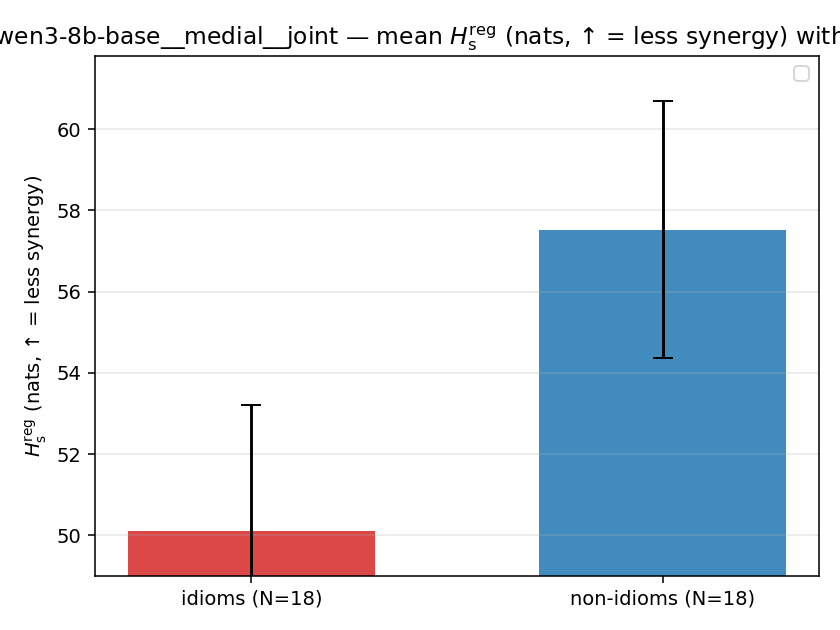 | 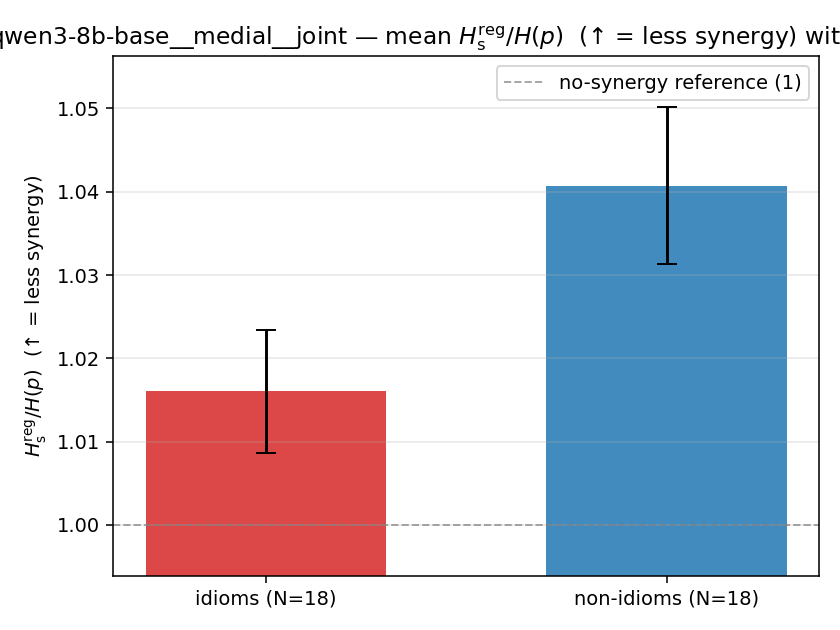 | — (no finite values) | — (no finite values) |
| per-idiom (sorted) | 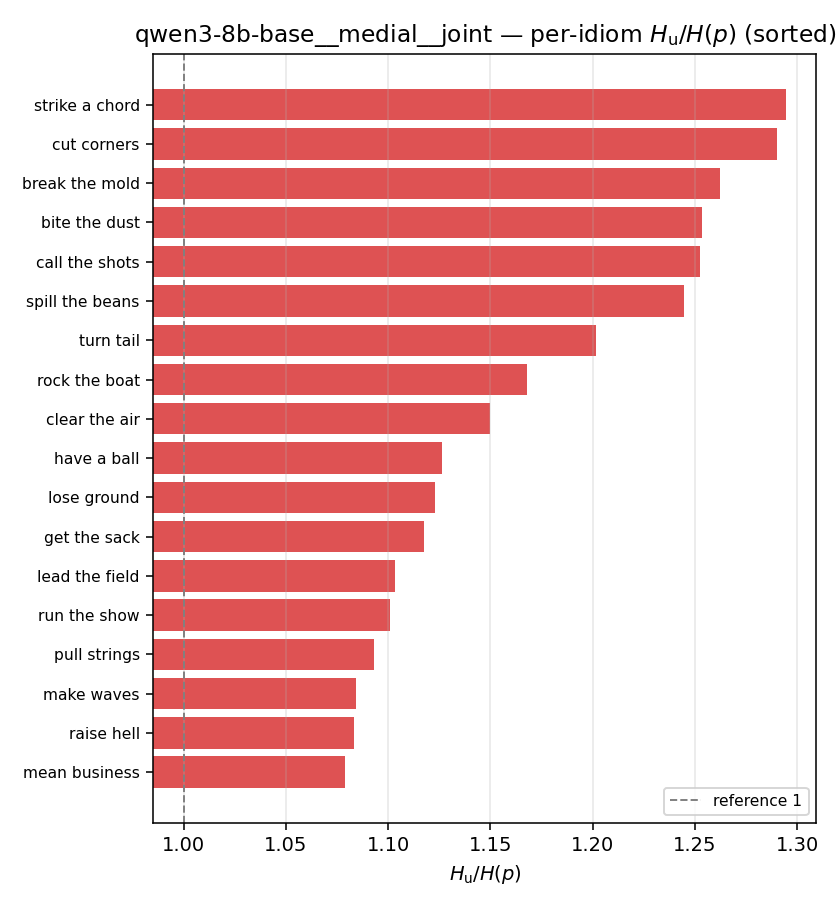 | 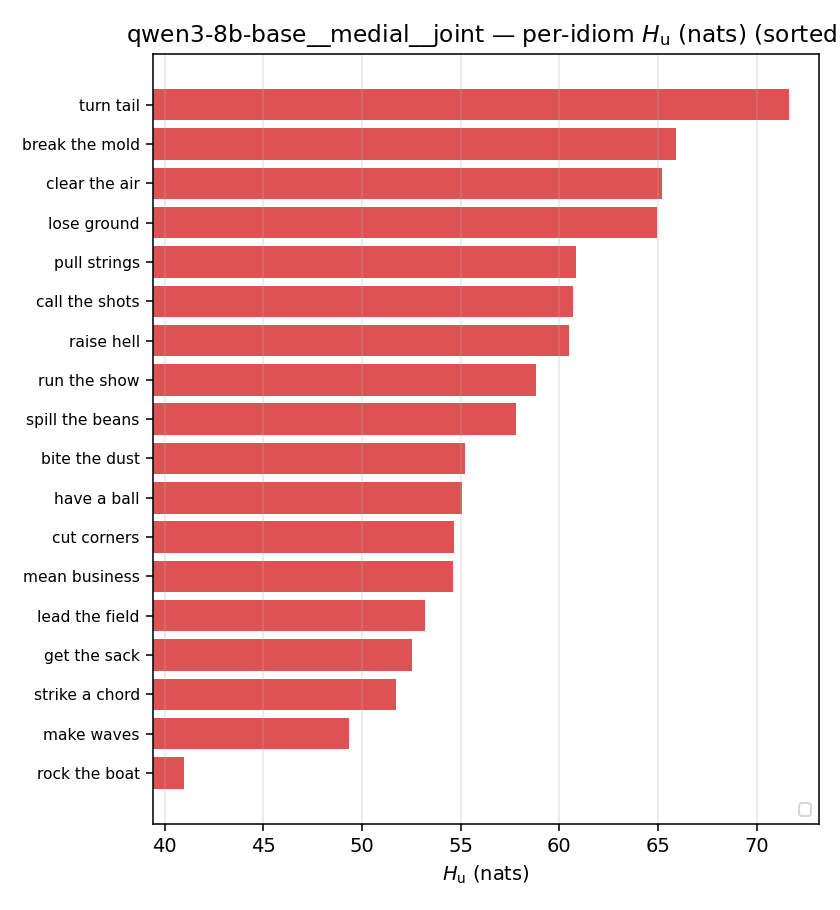 | 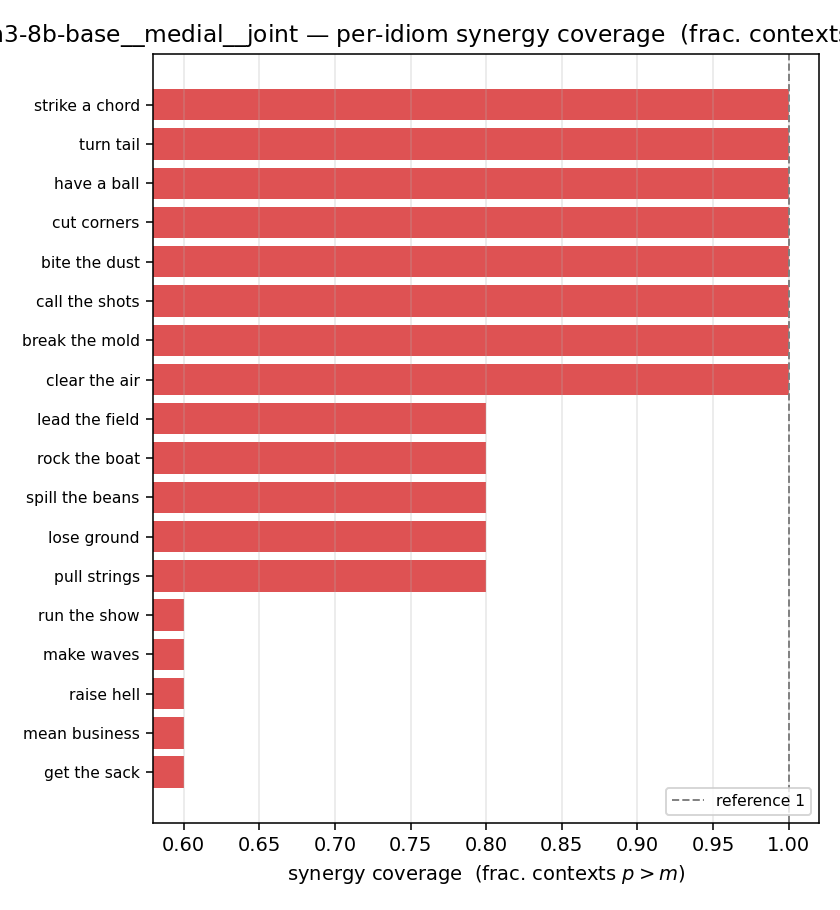 | 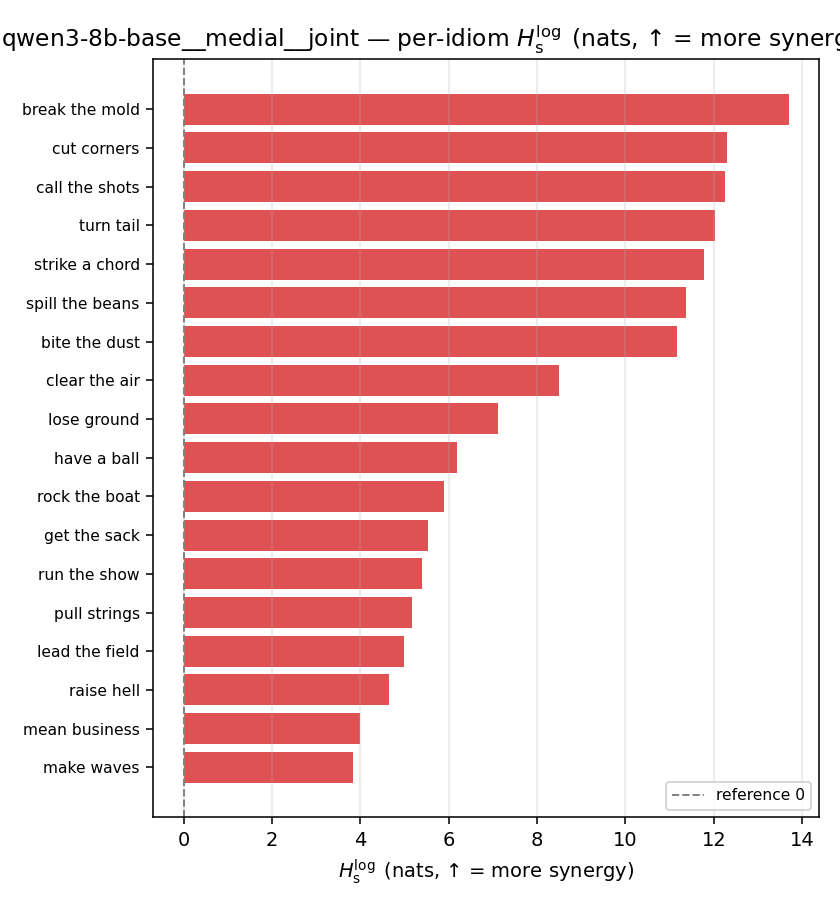 | 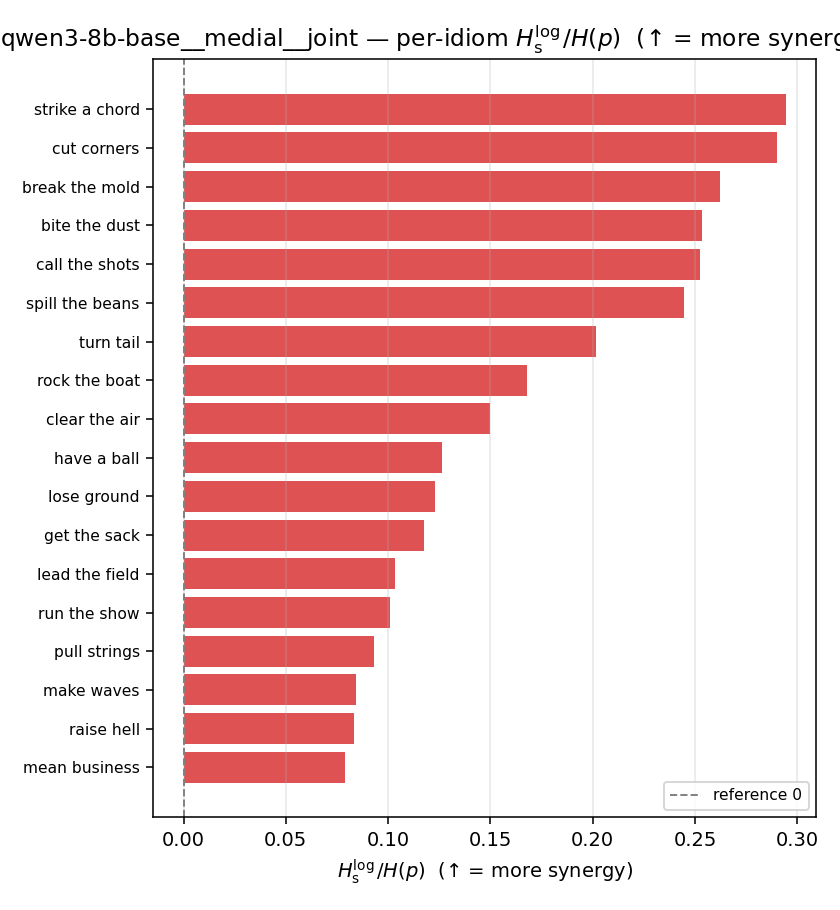 | 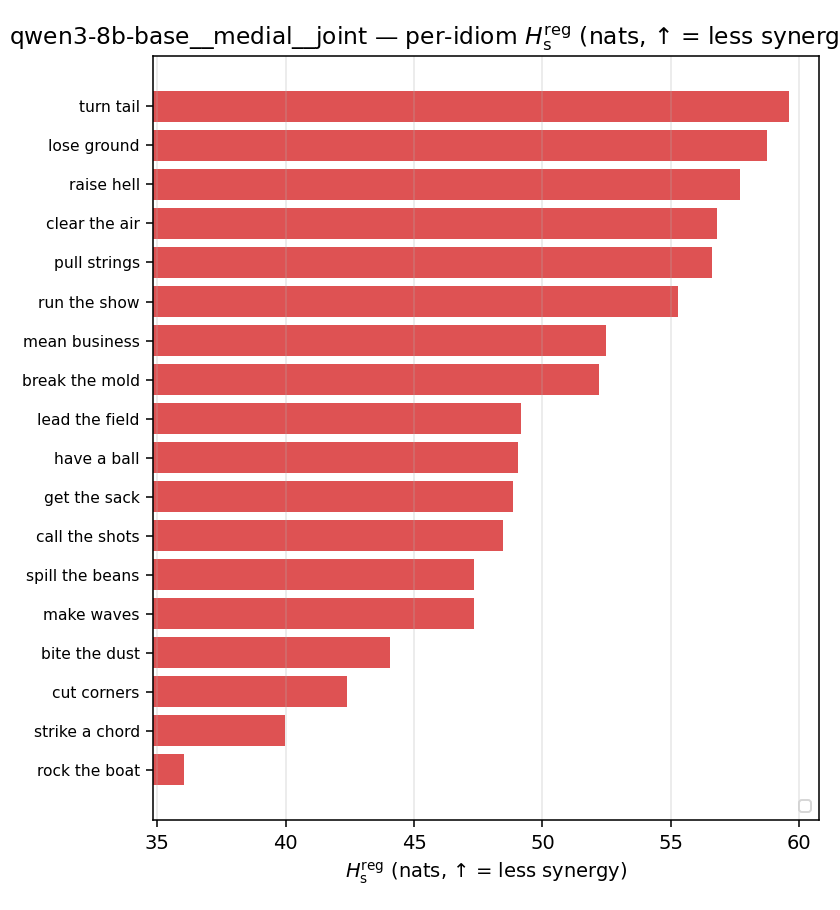 | 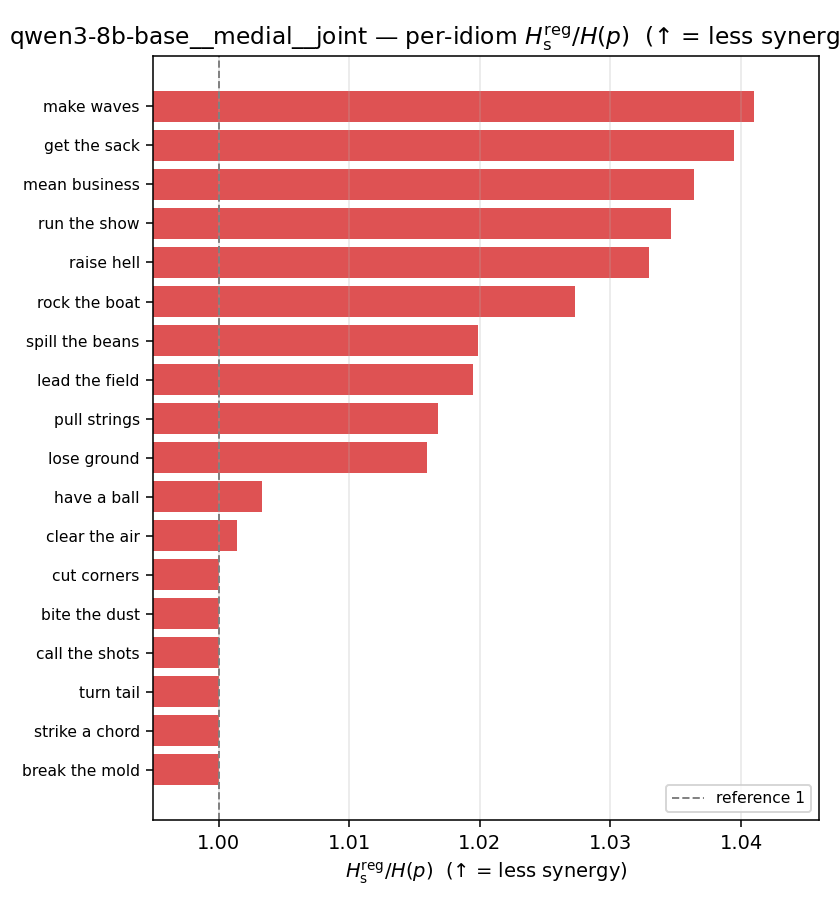 | — (no finite values) | — (no finite values) |
qwen3-8b-base · full · geo qwen3-8b-base__full__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 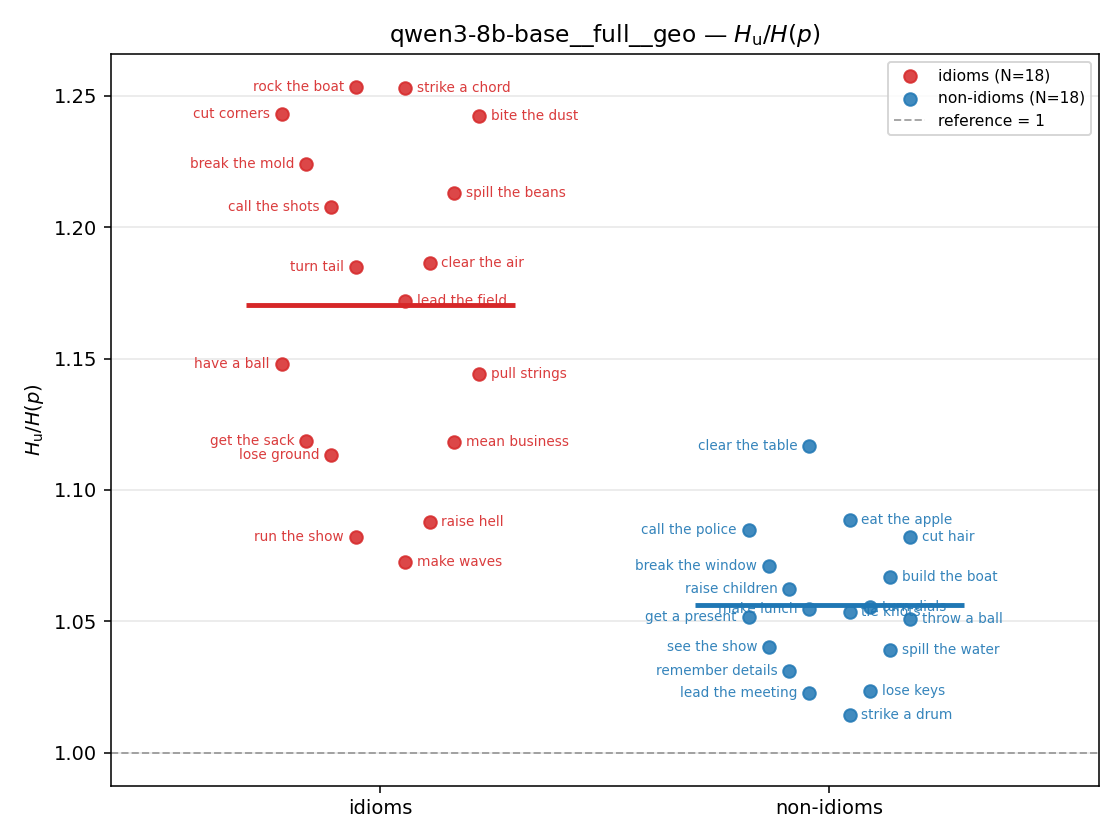 | 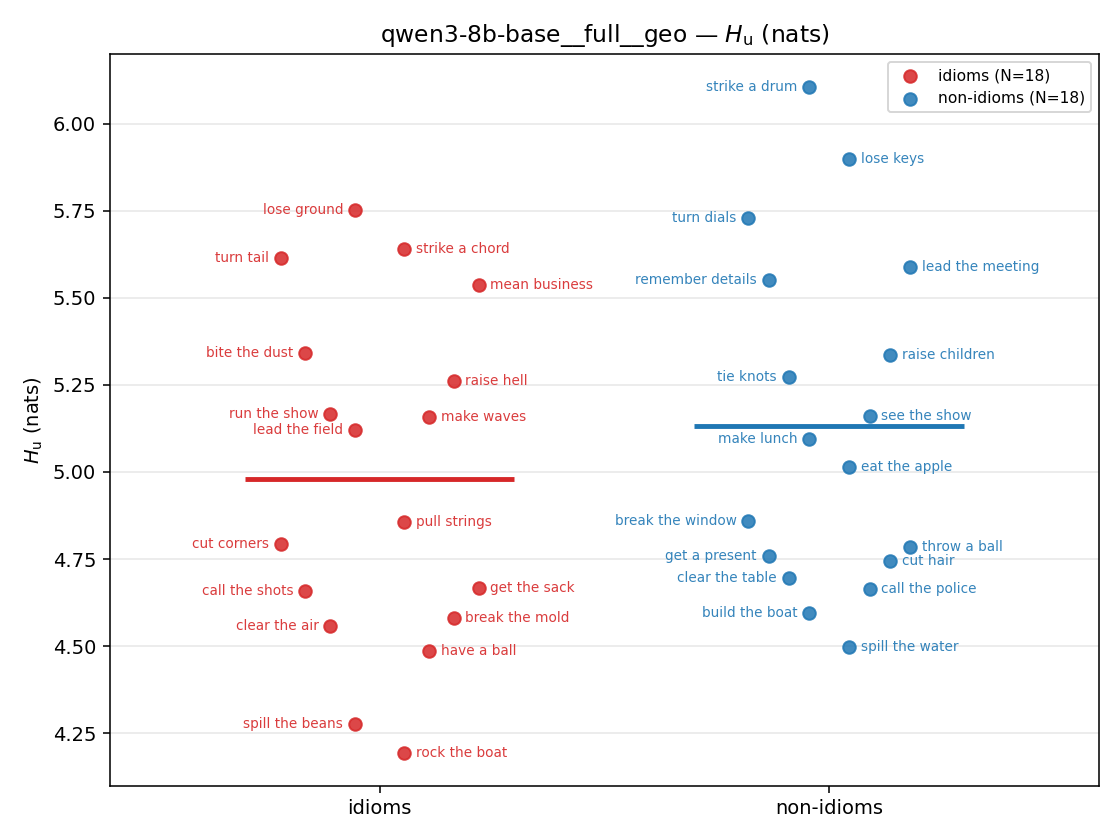 | 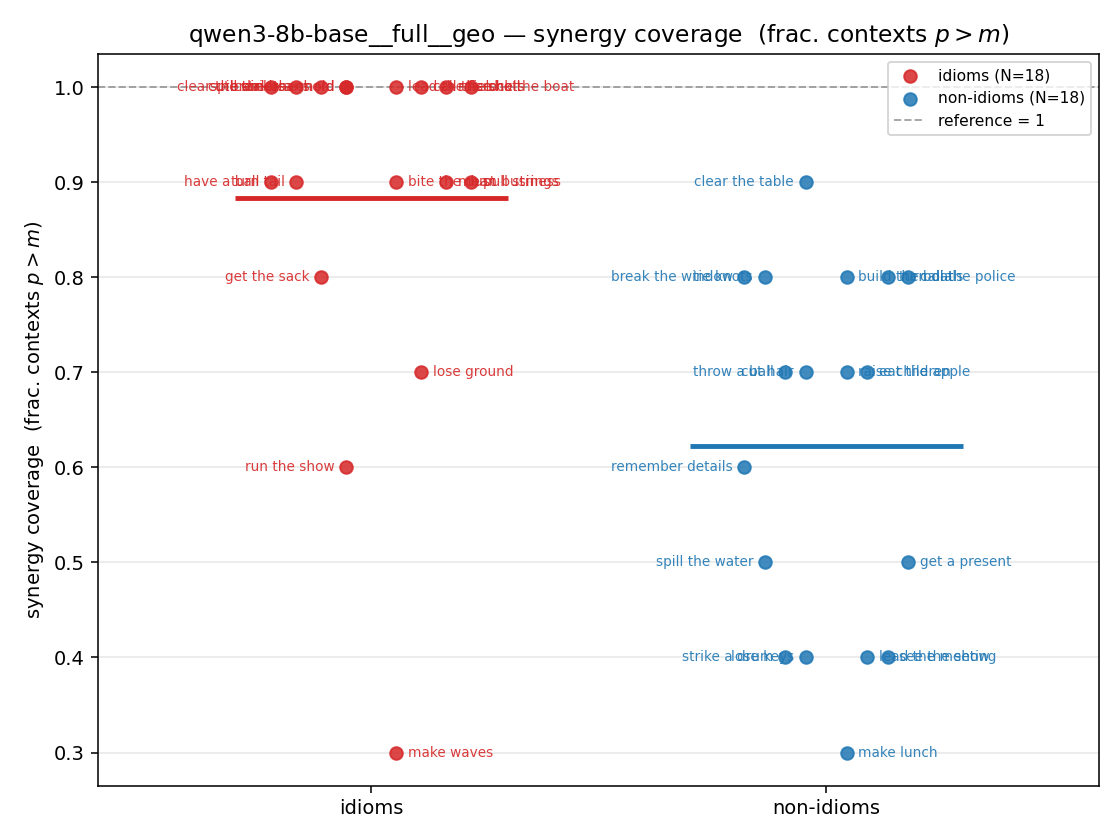 | 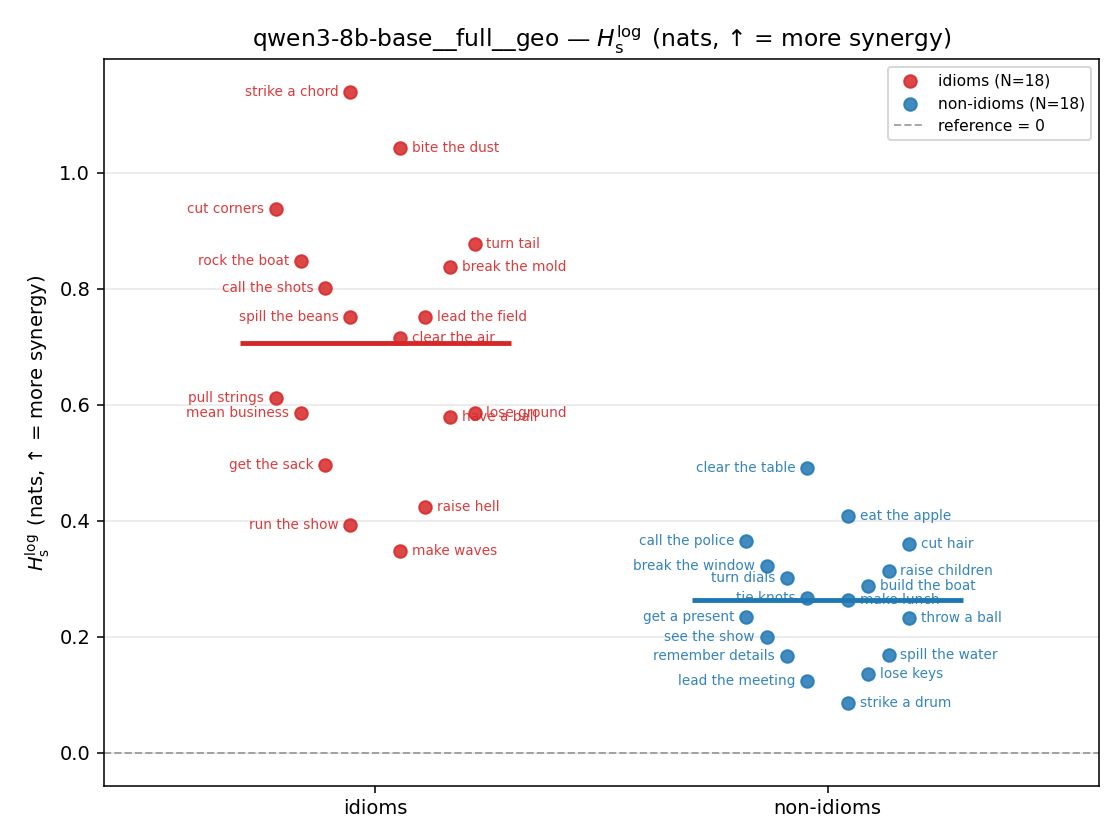 | 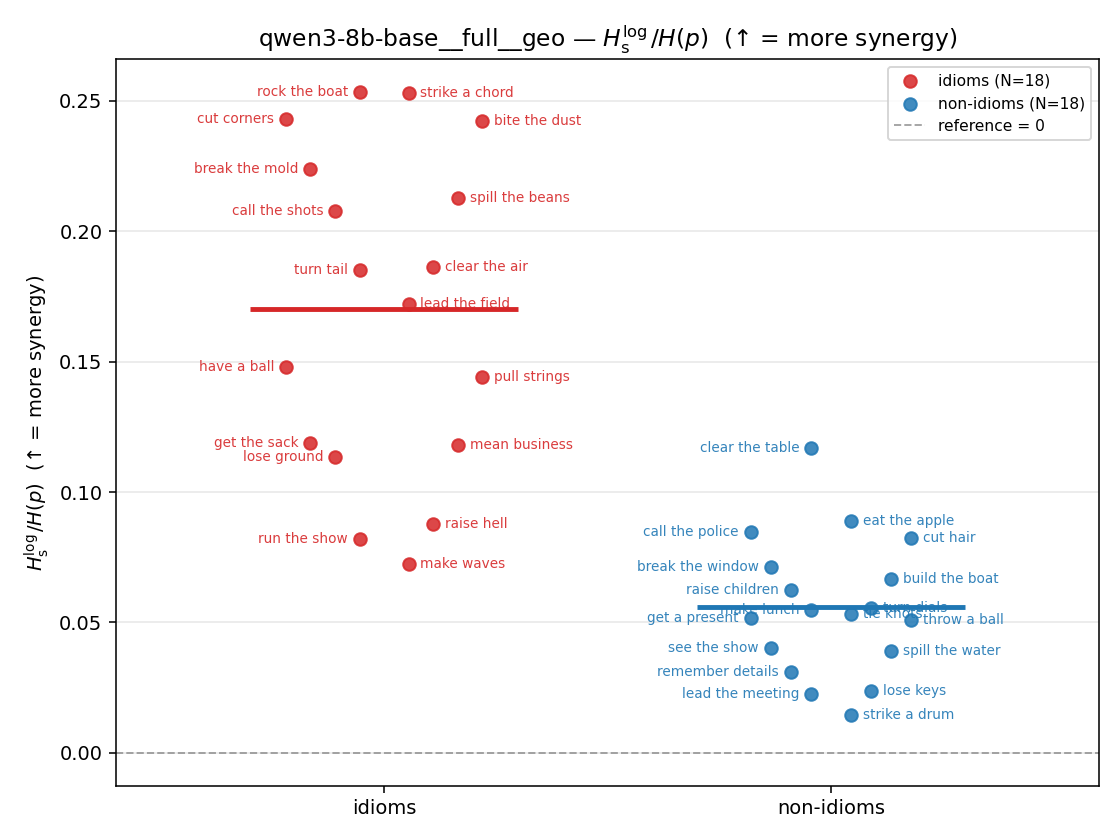 | 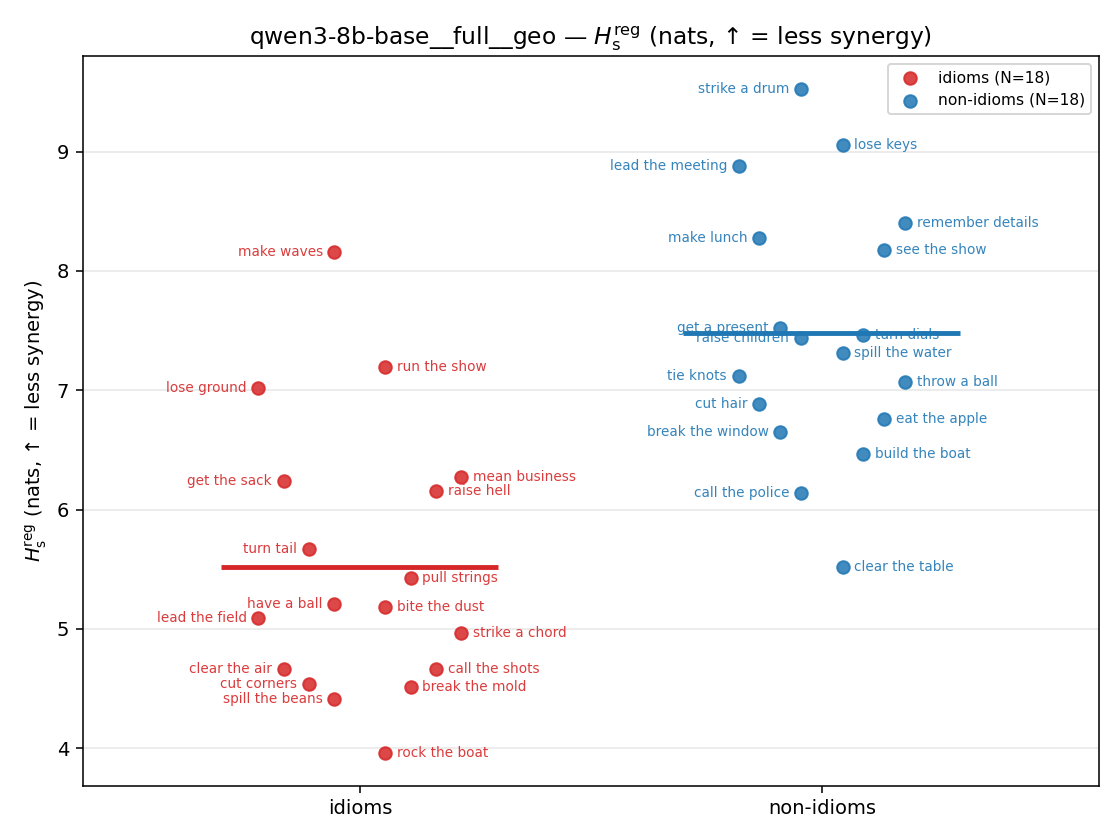 | 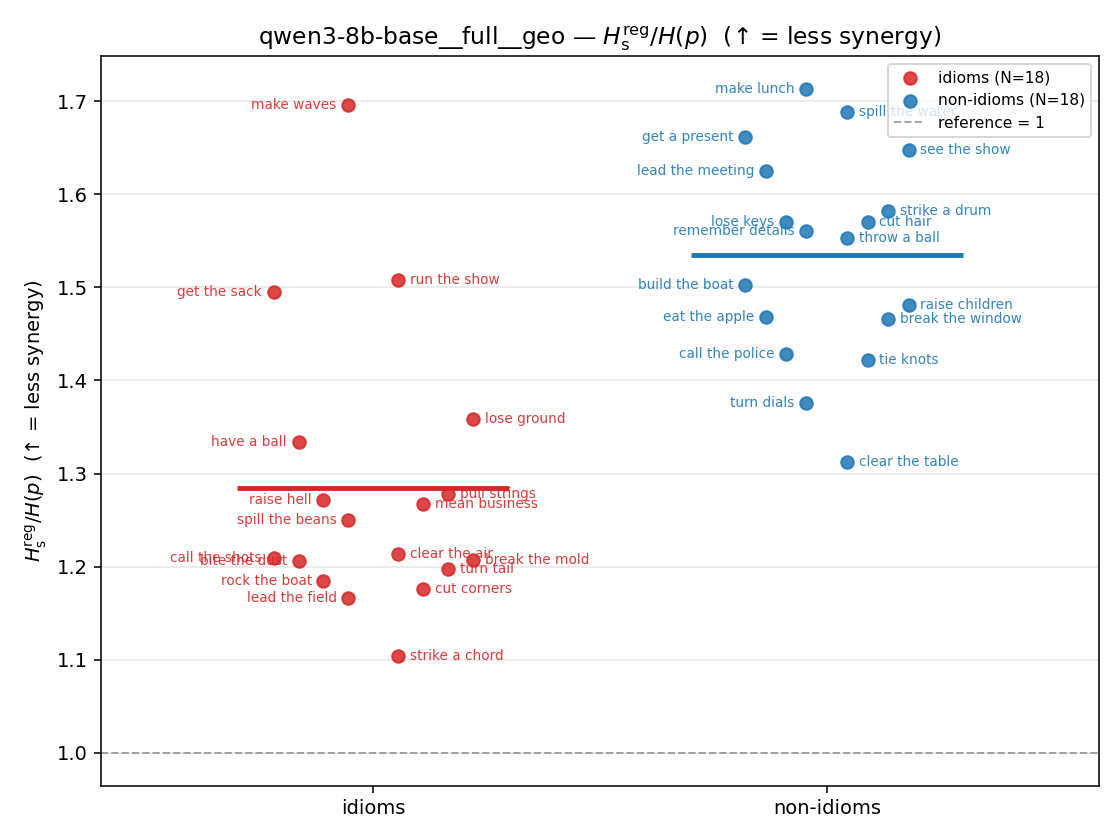 | — (no finite values) | — (no finite values) |
| mean ± 95% CI | 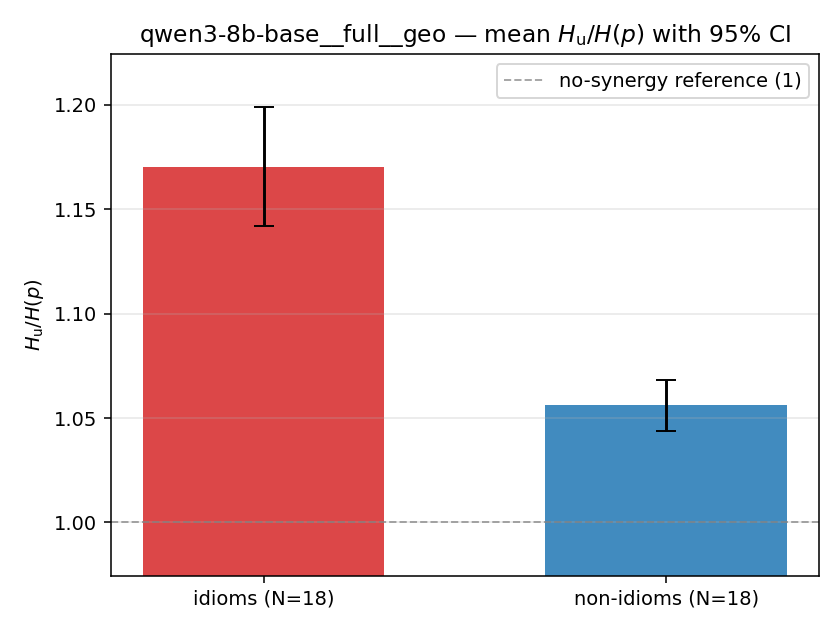 | 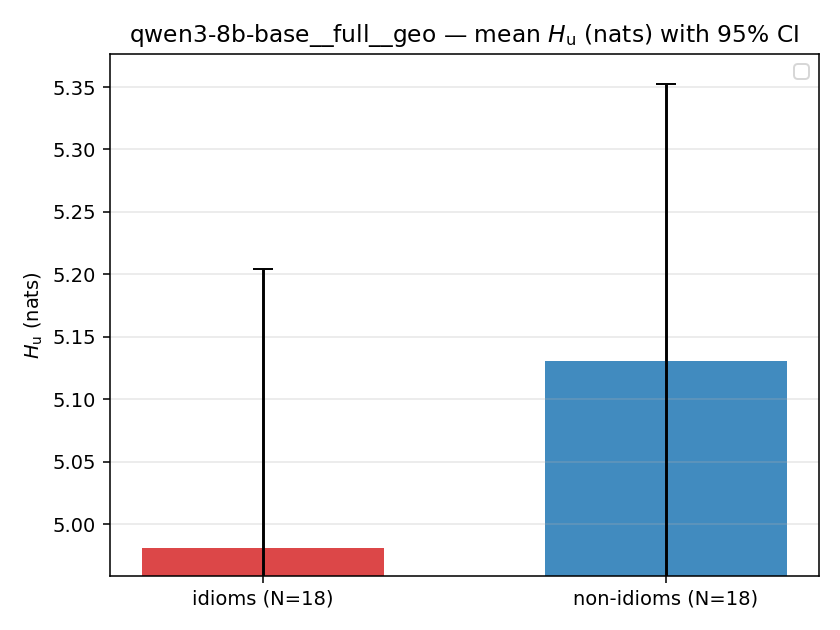 | 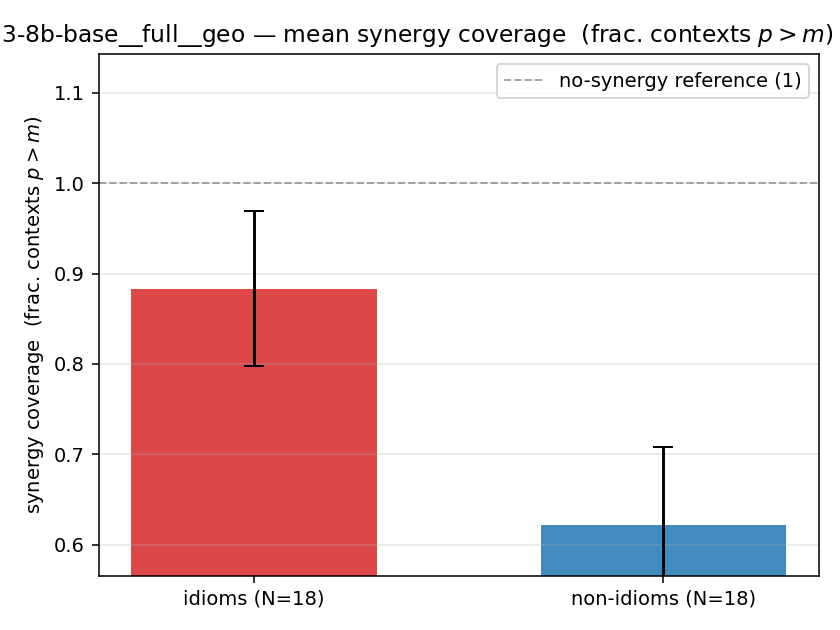 | 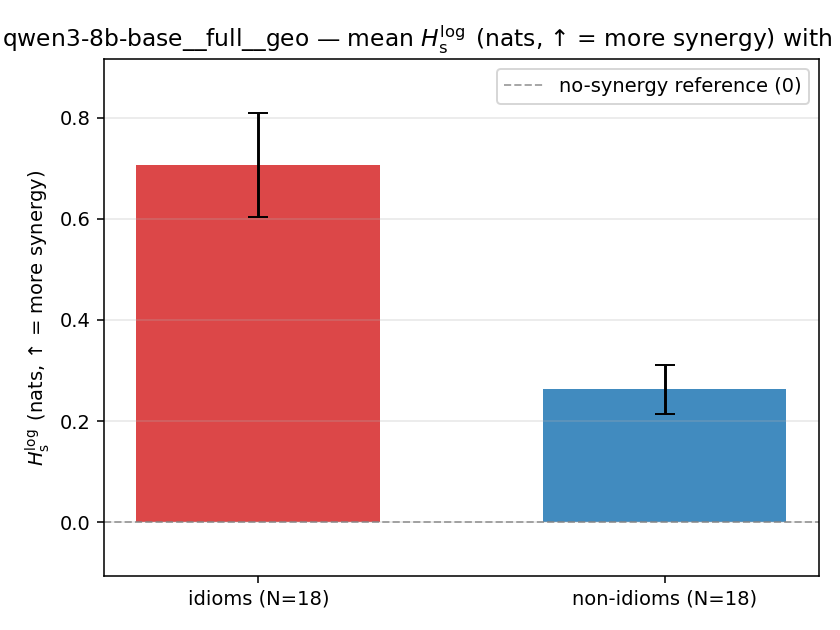 | 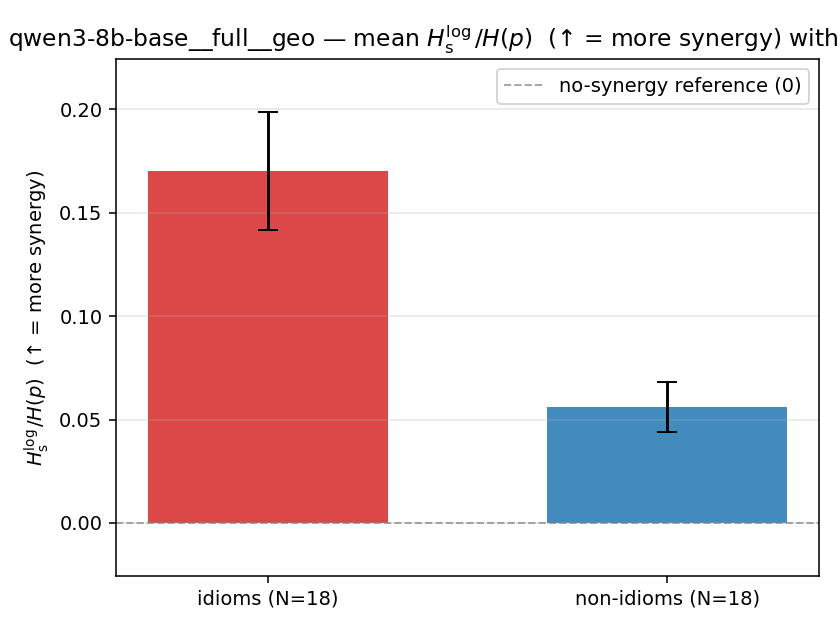 | 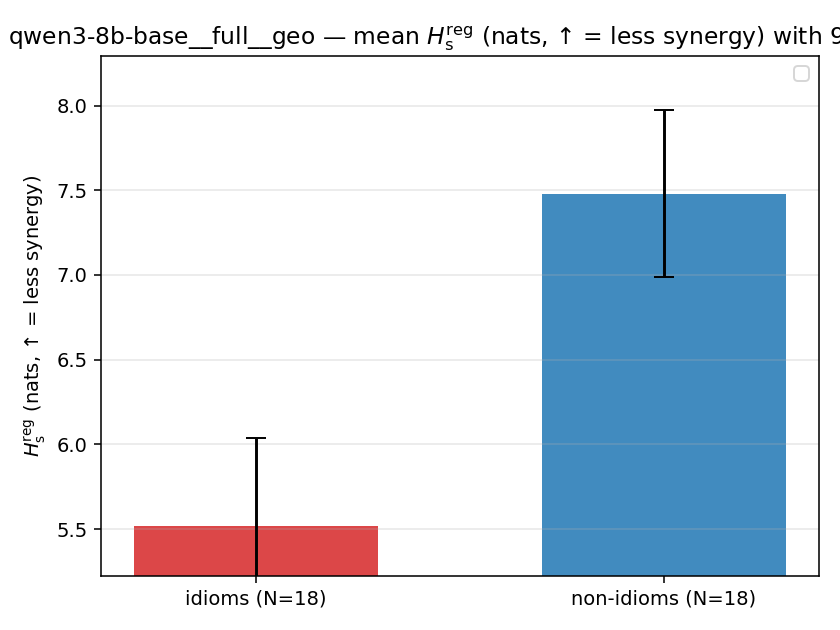 | 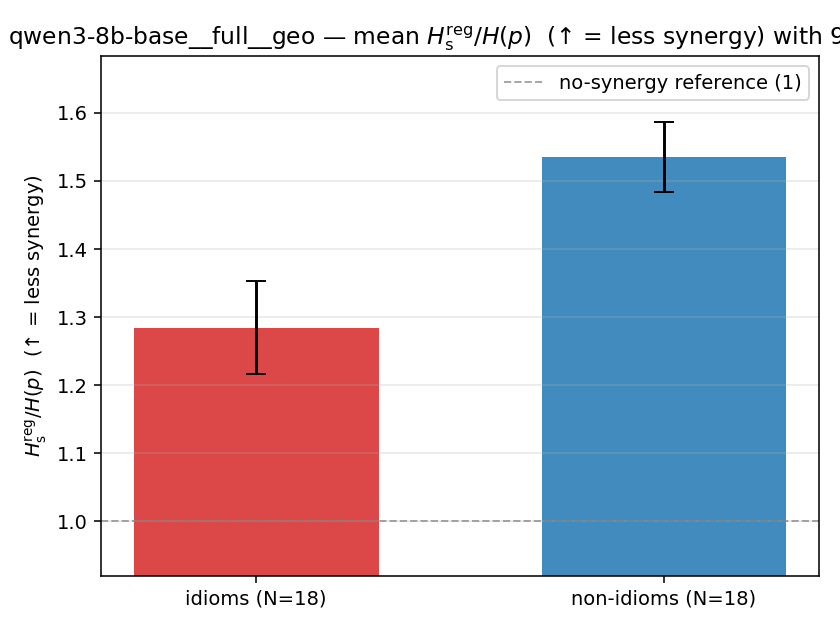 | — (no finite values) | — (no finite values) |
| per-idiom (sorted) | 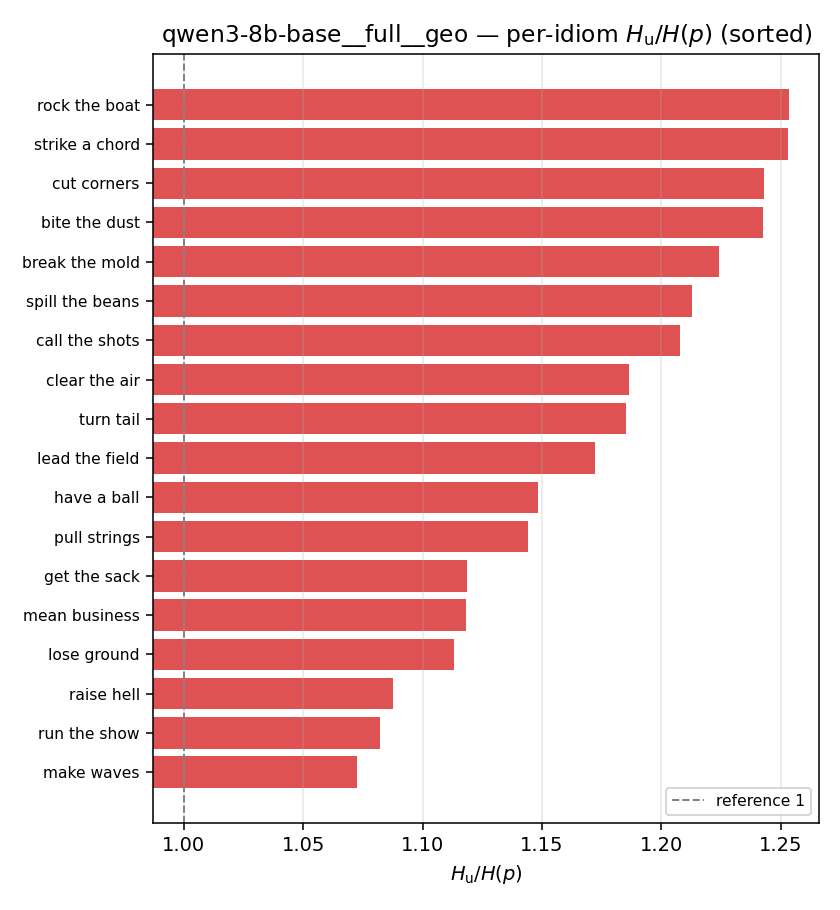 | 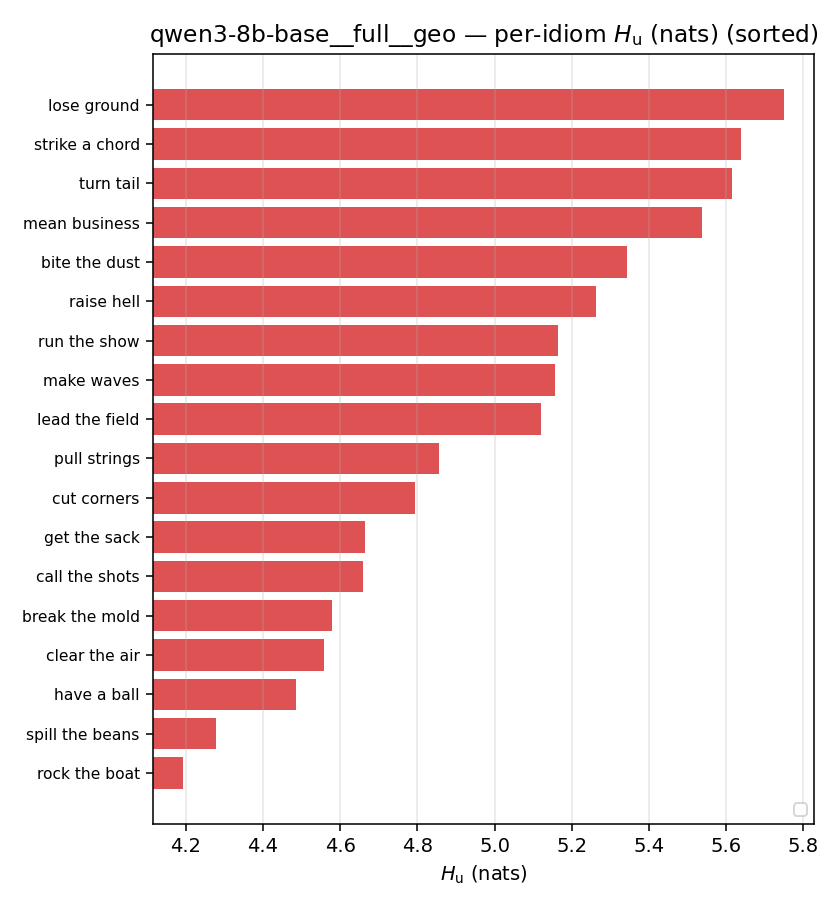 | 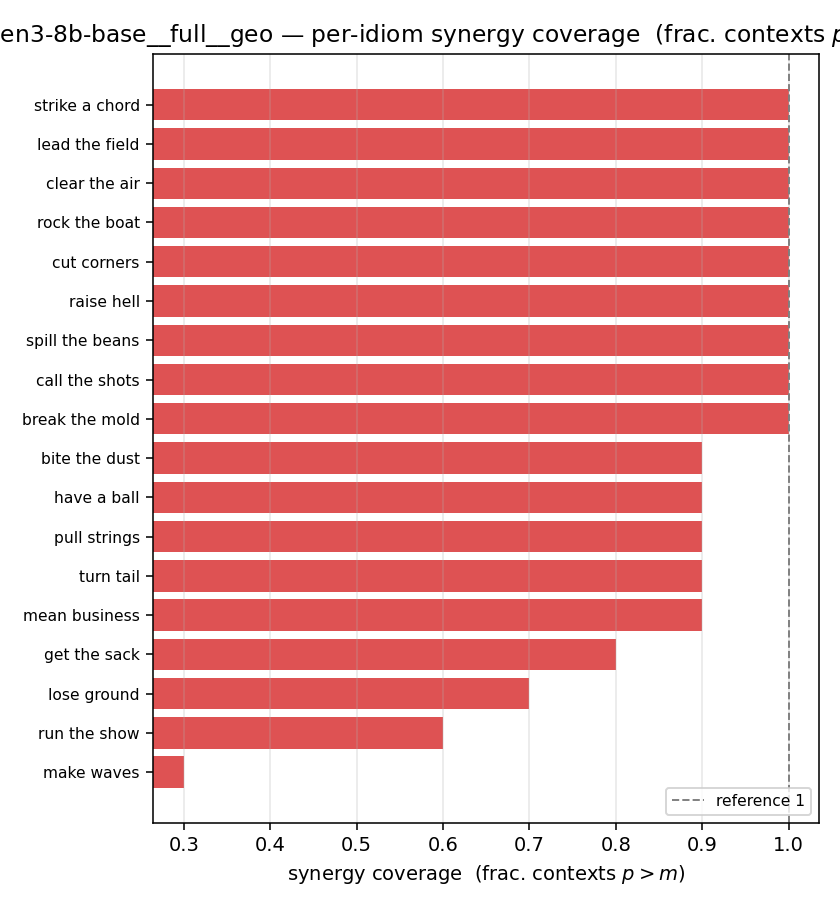 | 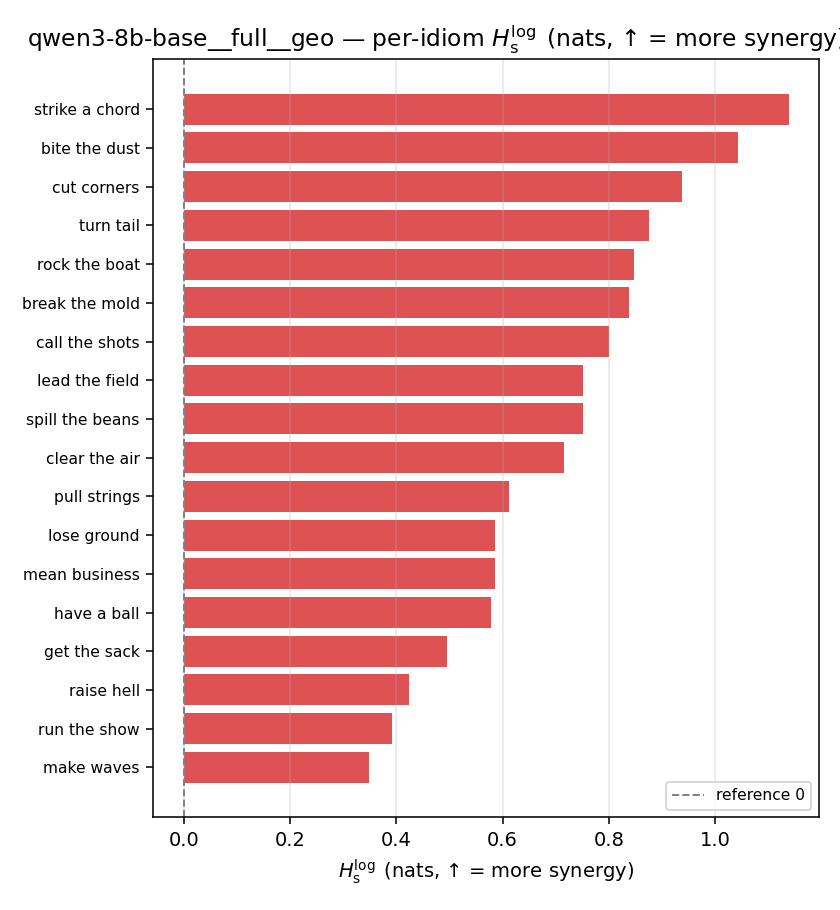 | 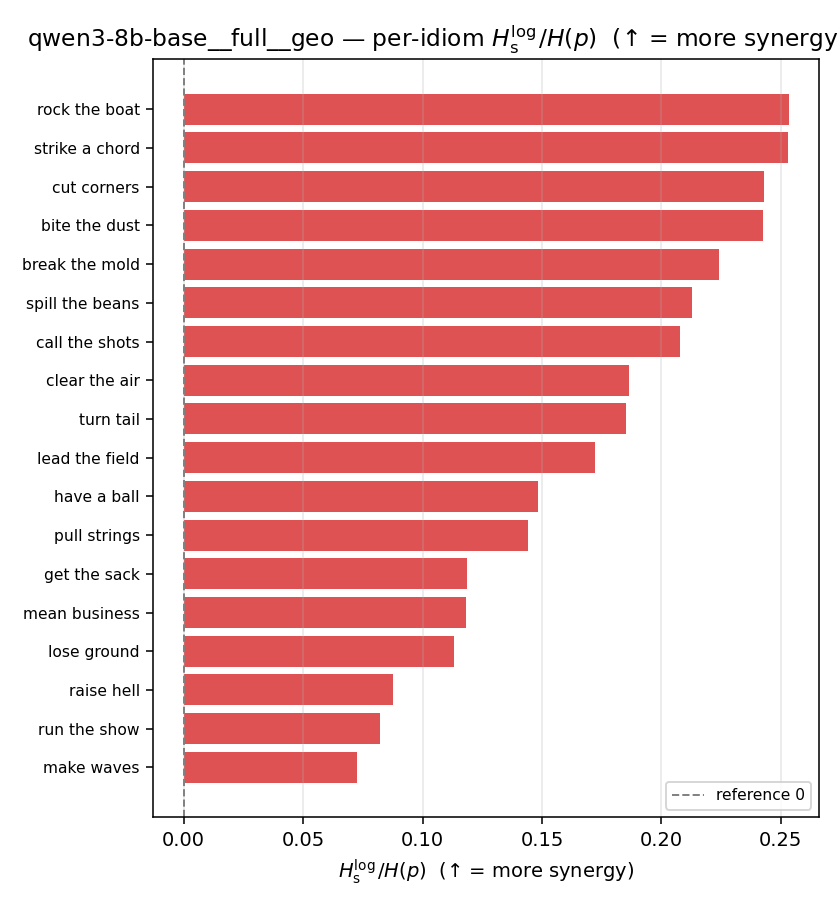 | 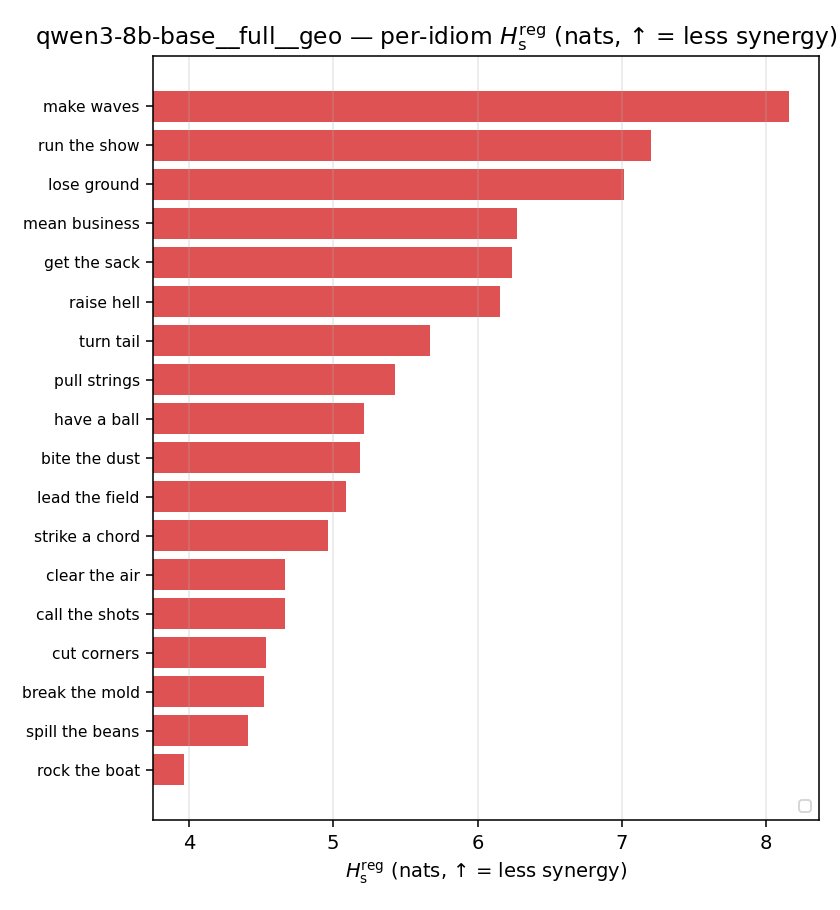 | 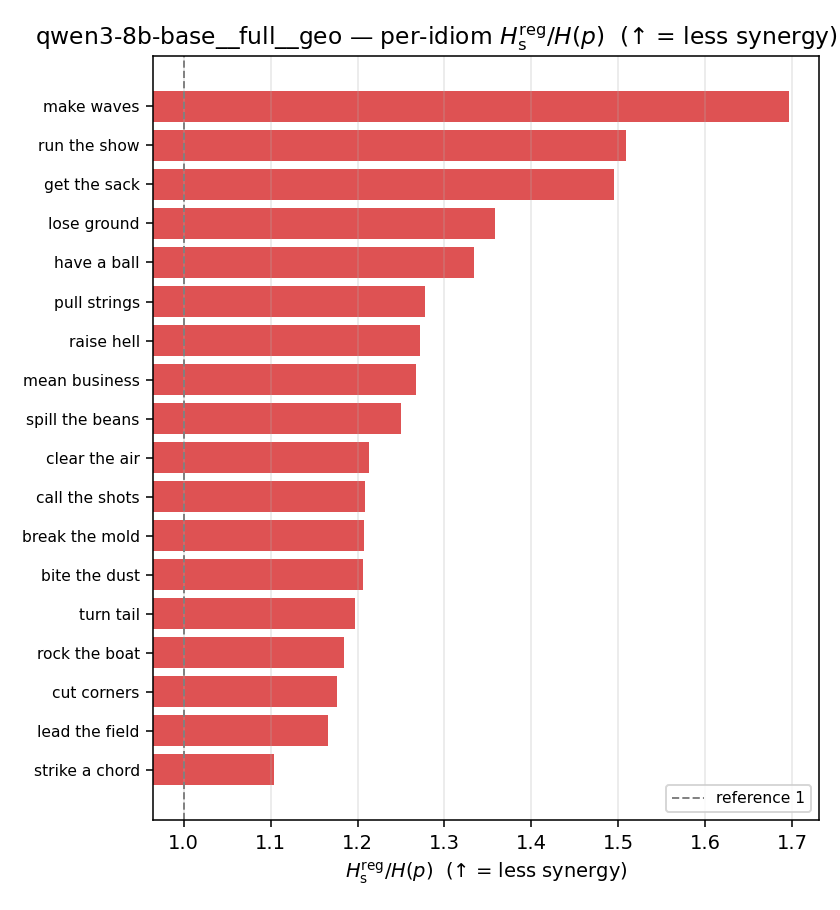 | — (no finite values) | — (no finite values) |
qwen3-8b-base · full · joint qwen3-8b-base__full__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 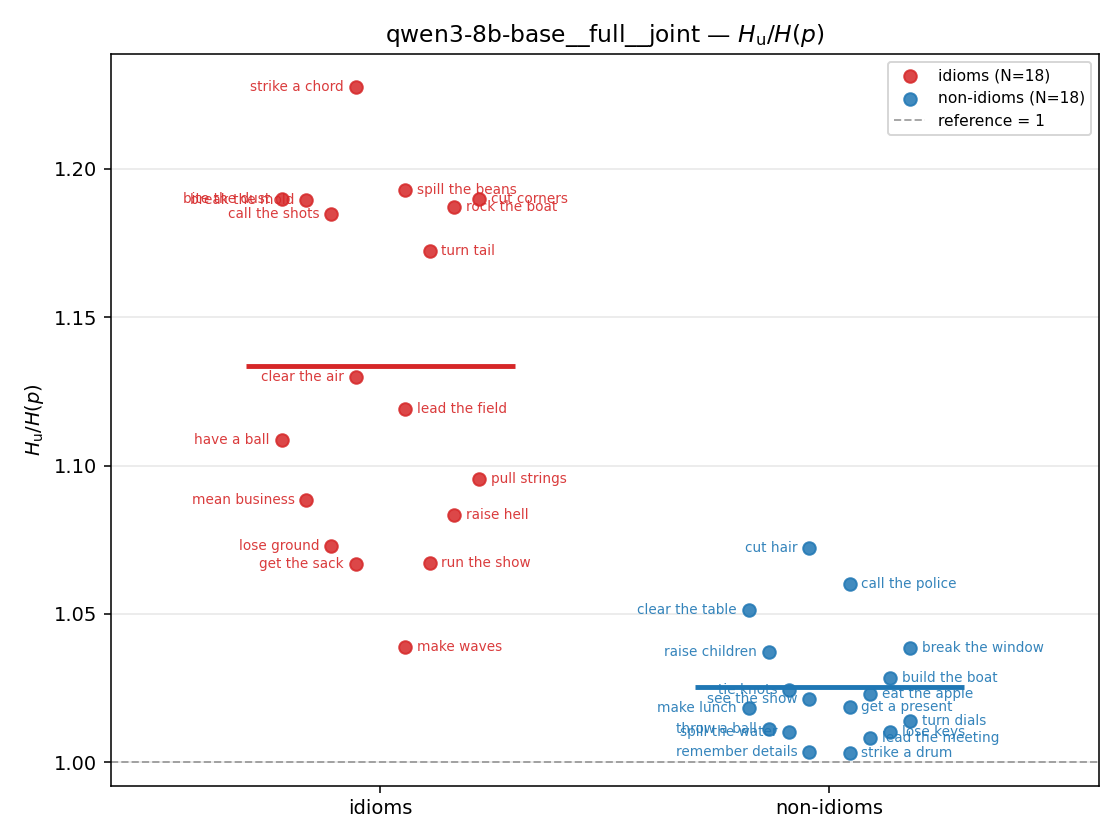 | 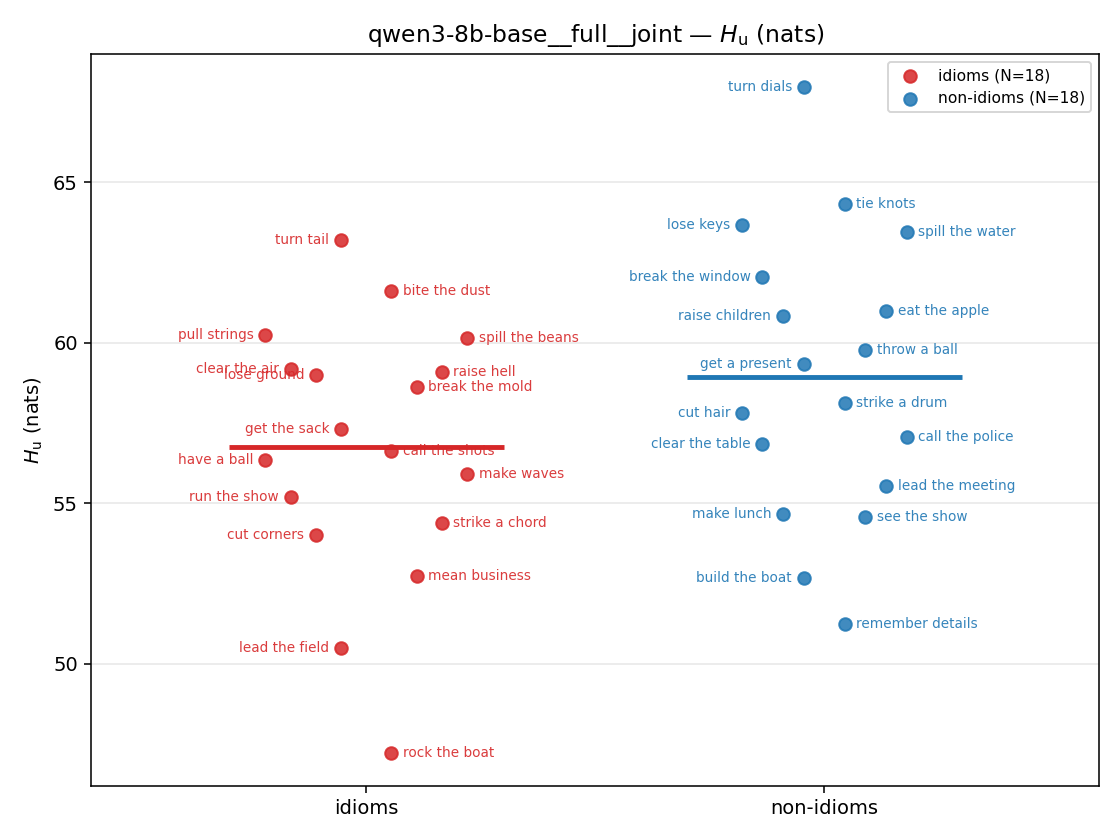 | 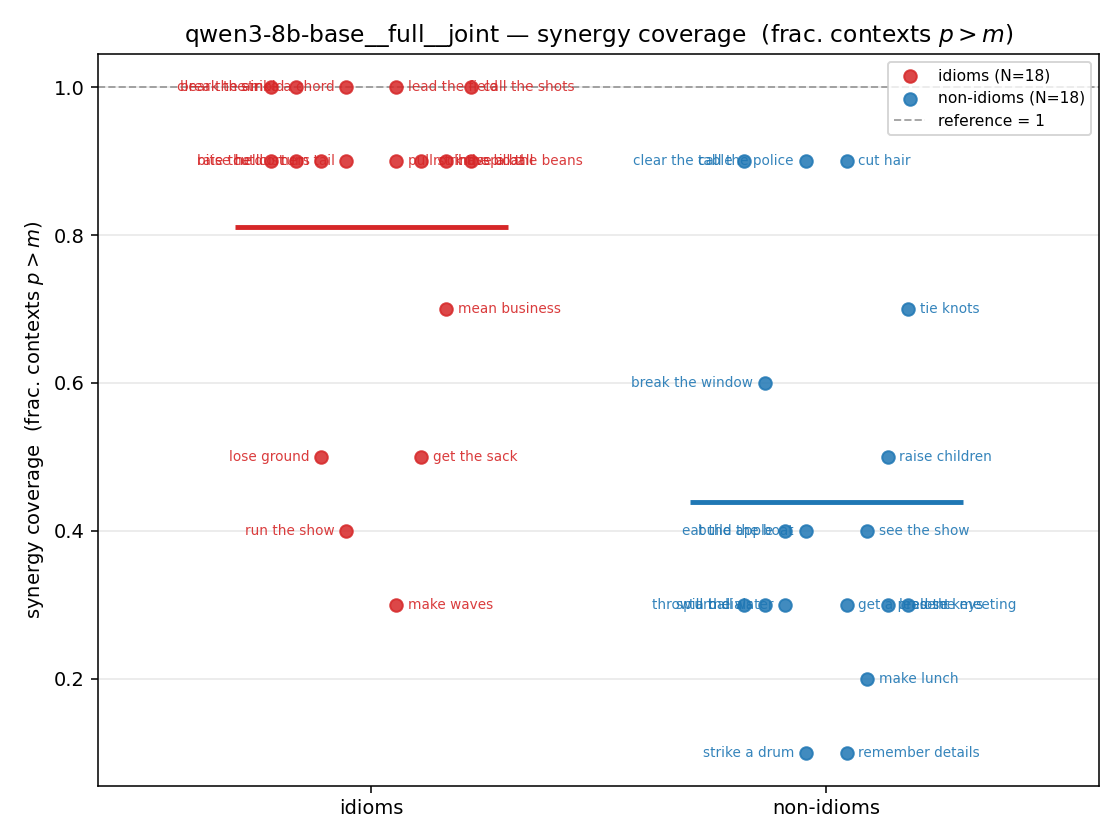 | 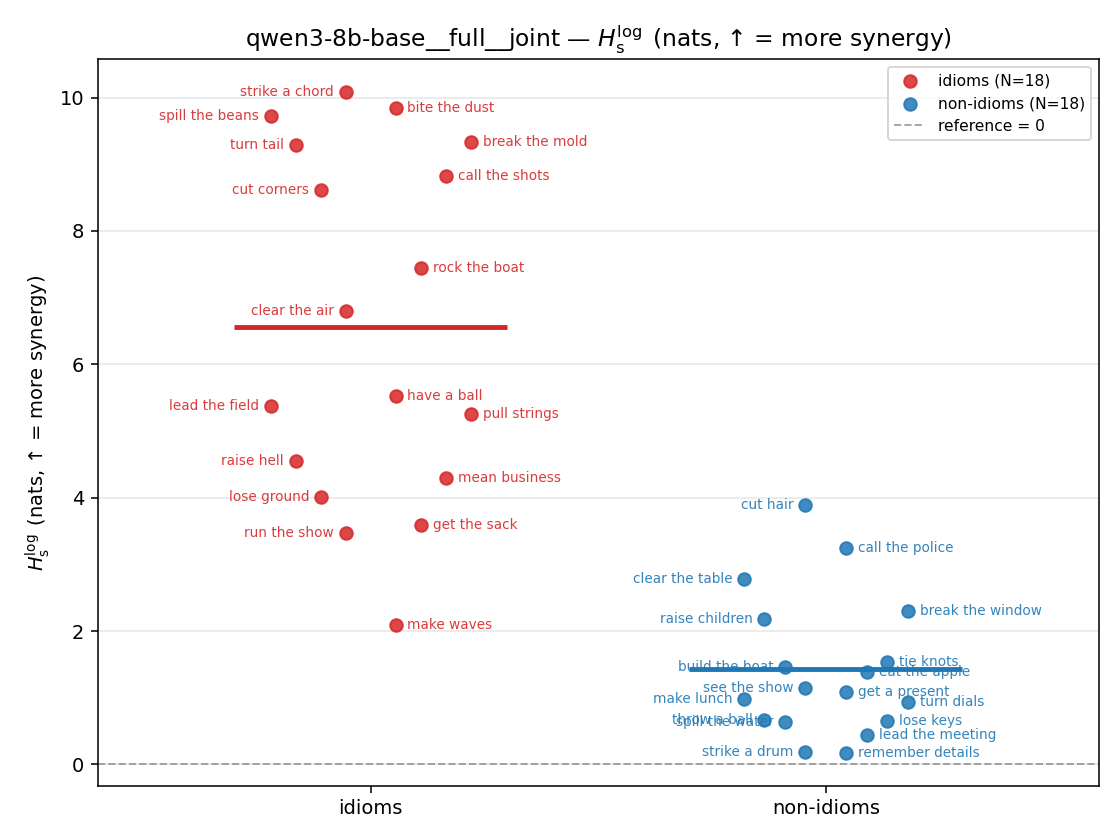 | 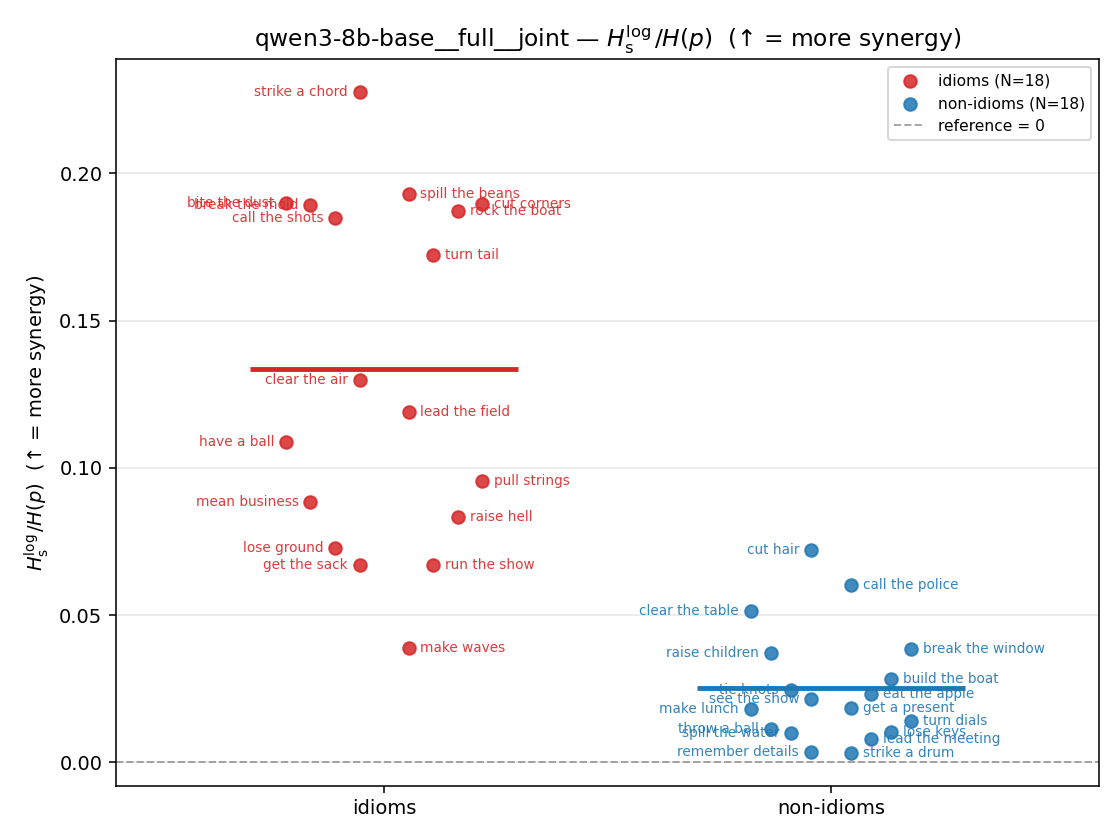 | 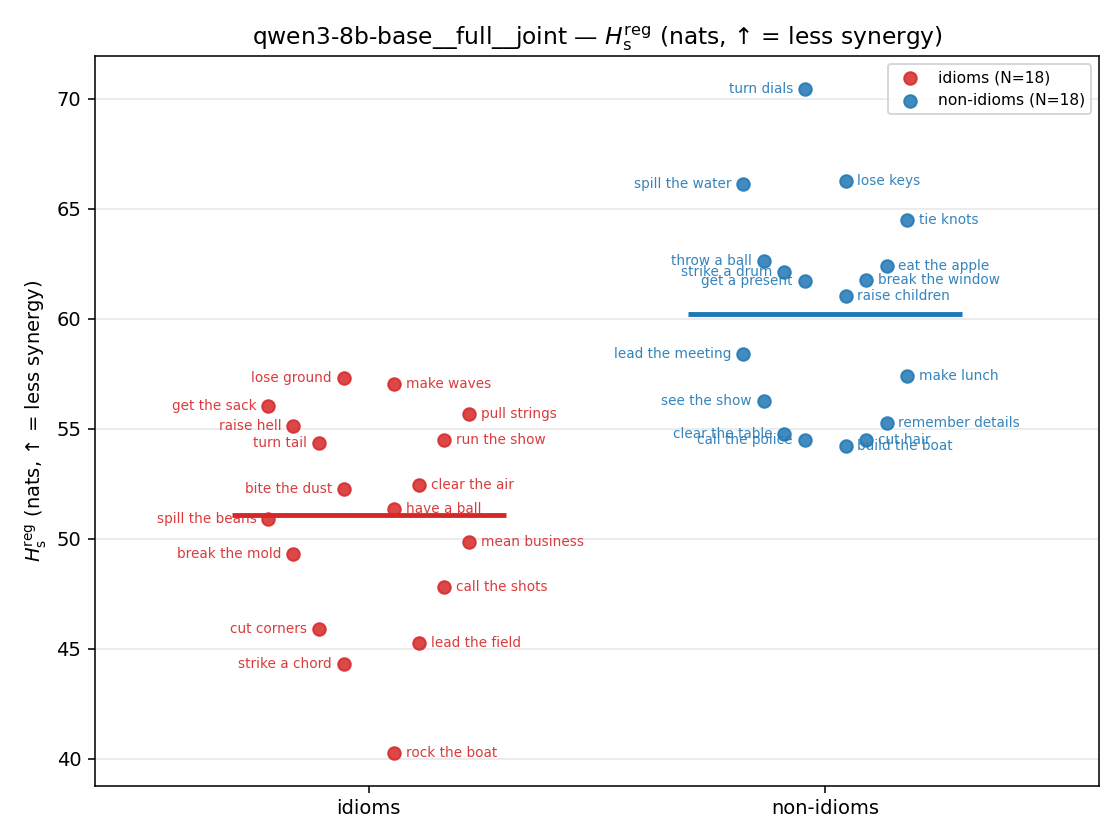 | 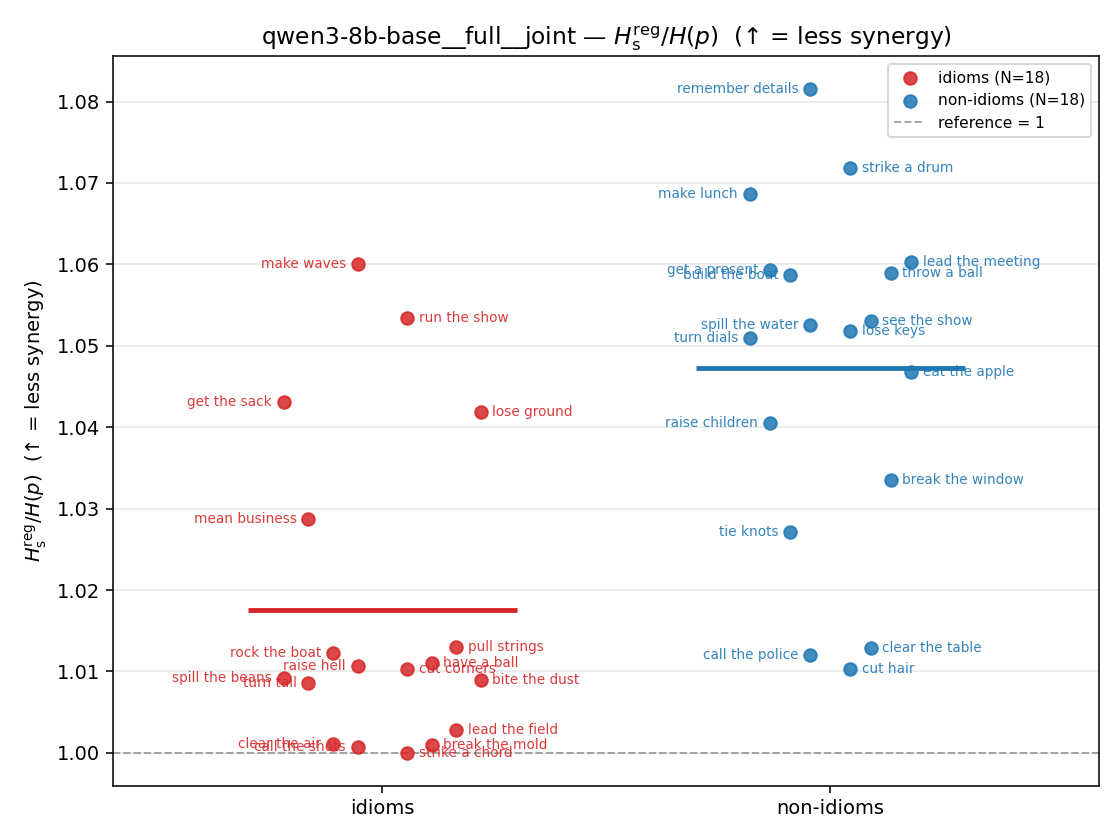 | — (no finite values) | — (no finite values) |
| mean ± 95% CI | 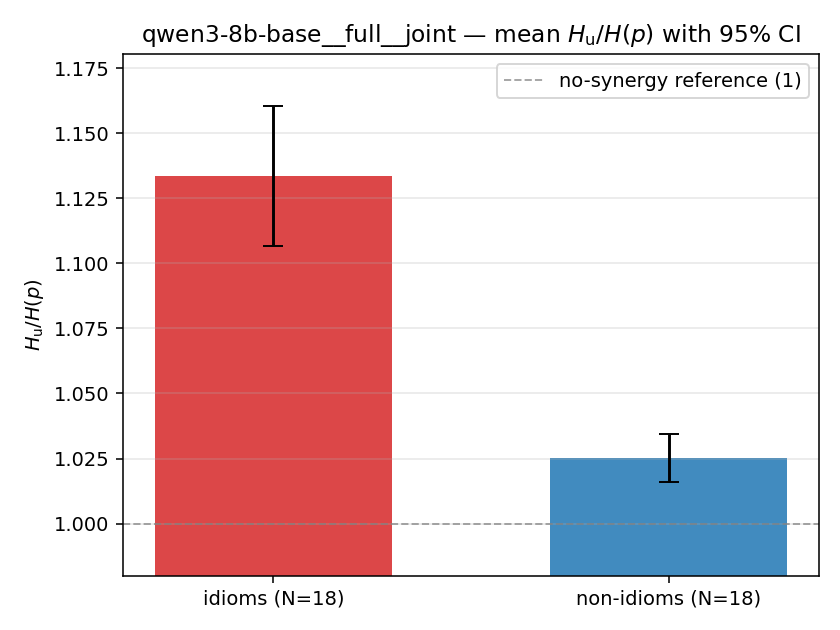 | 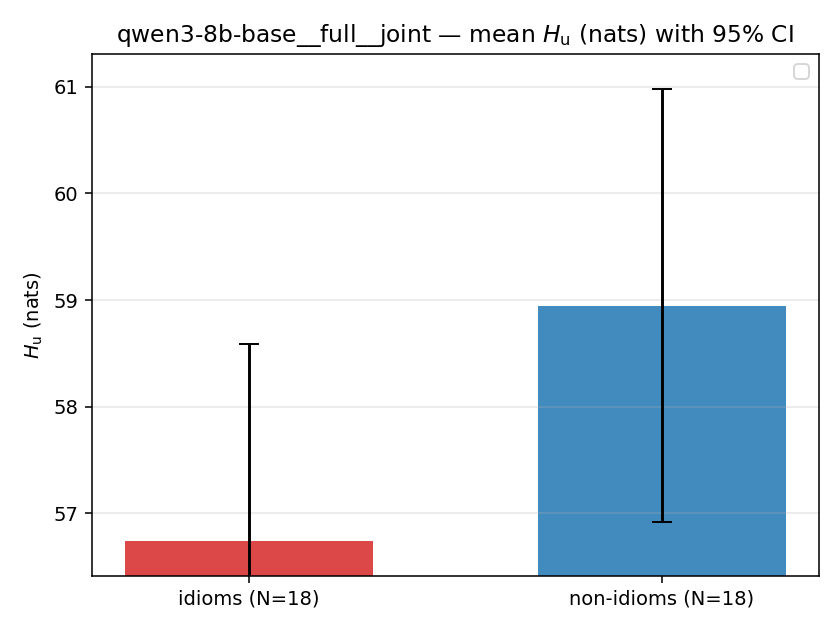 | 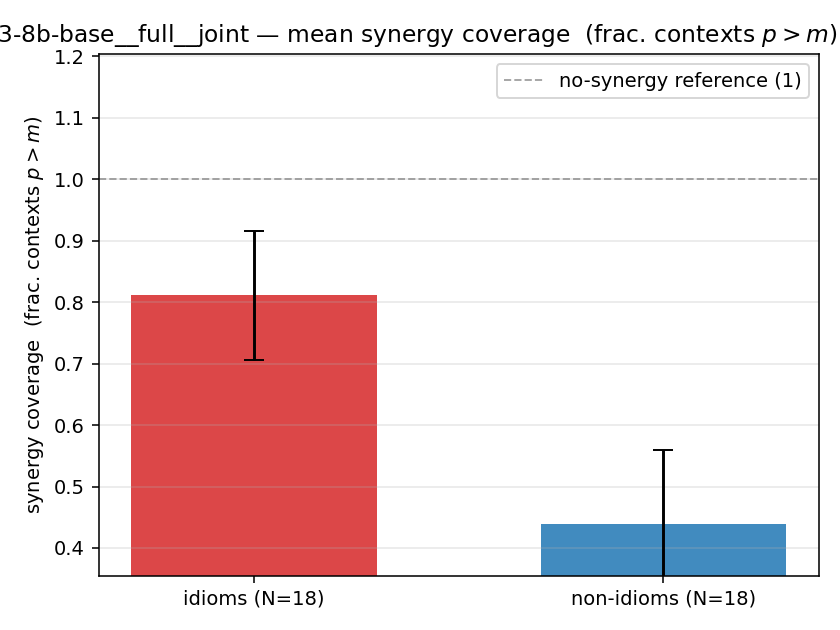 | 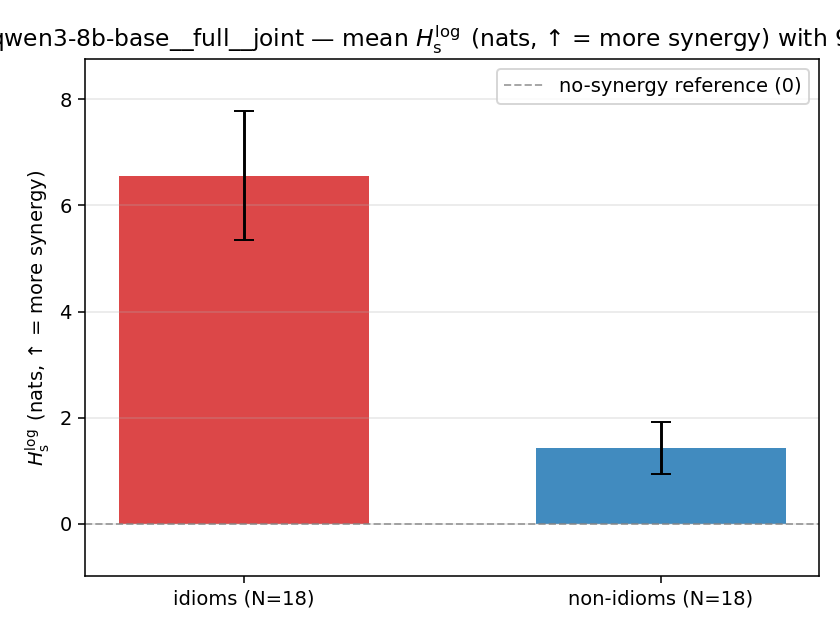 | 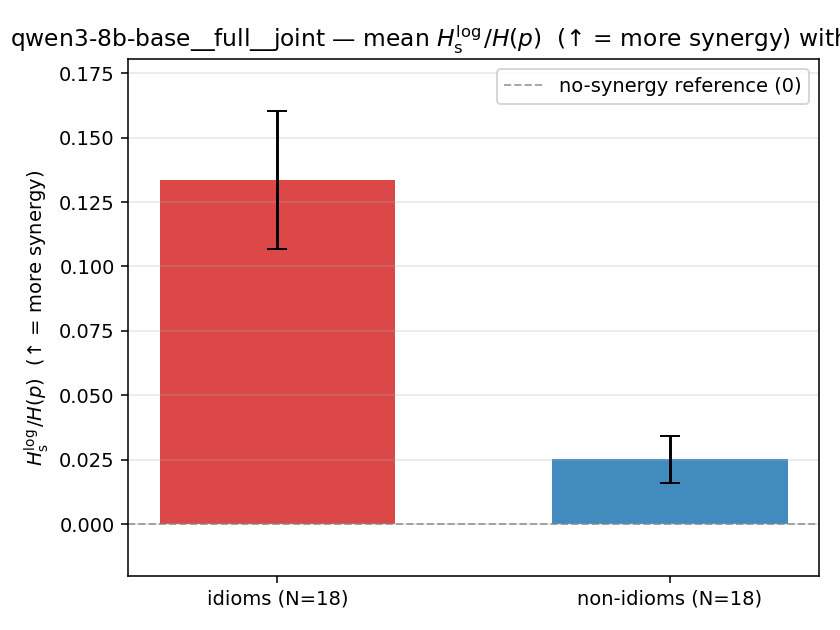 | 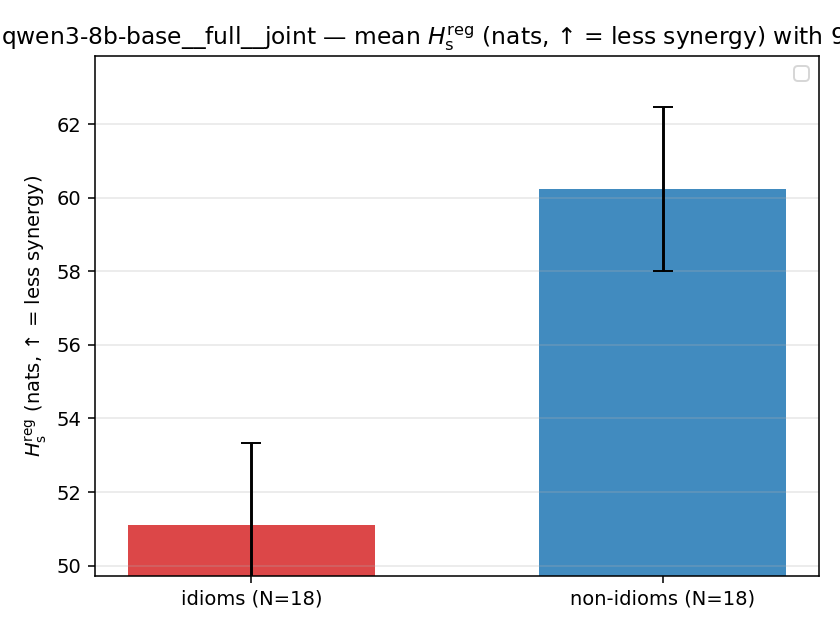 | 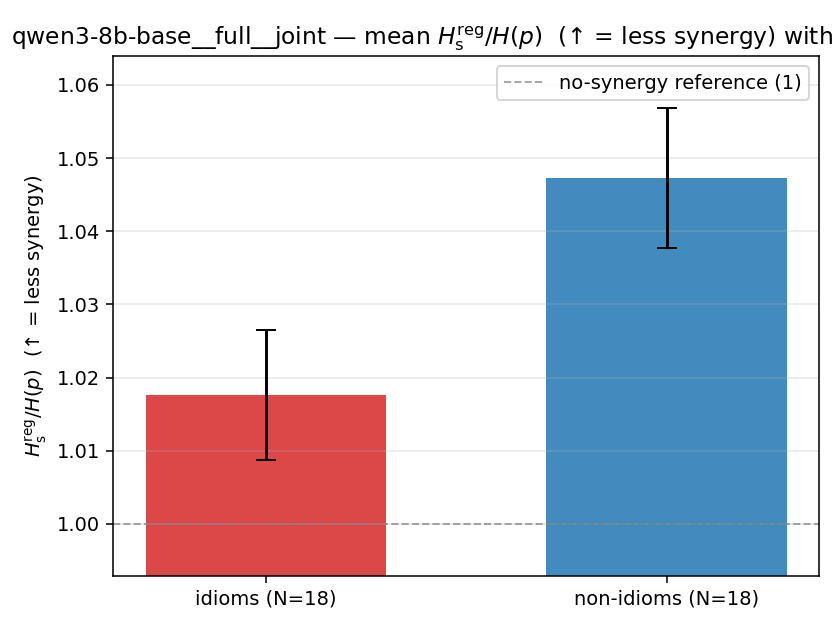 | — (no finite values) | — (no finite values) |
| per-idiom (sorted) | 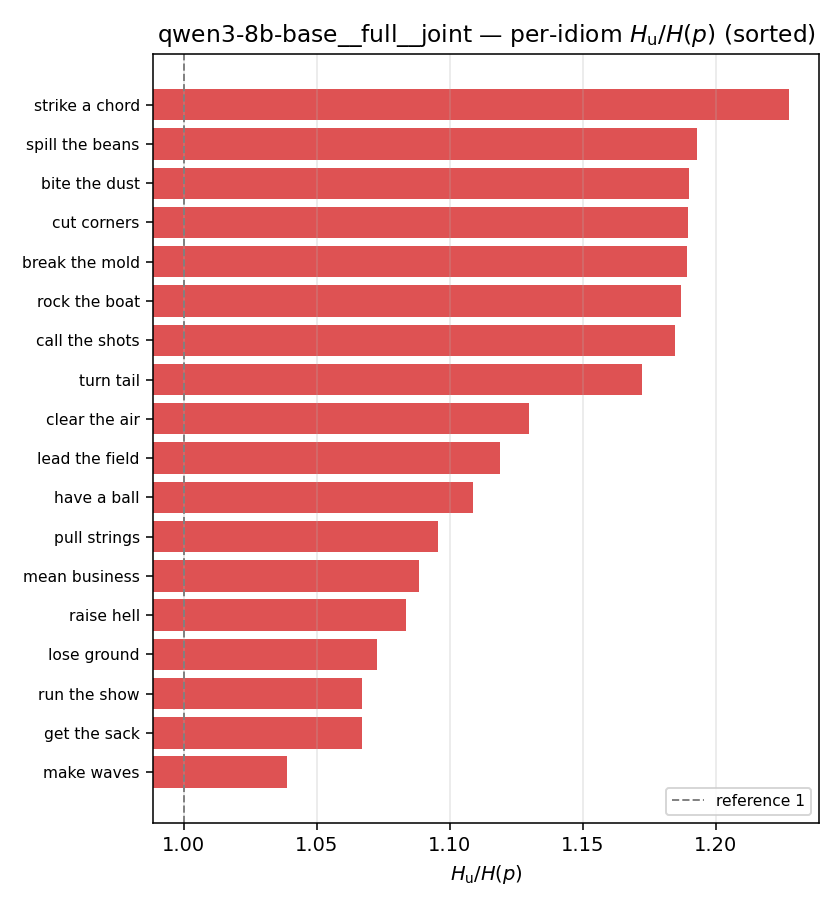 | 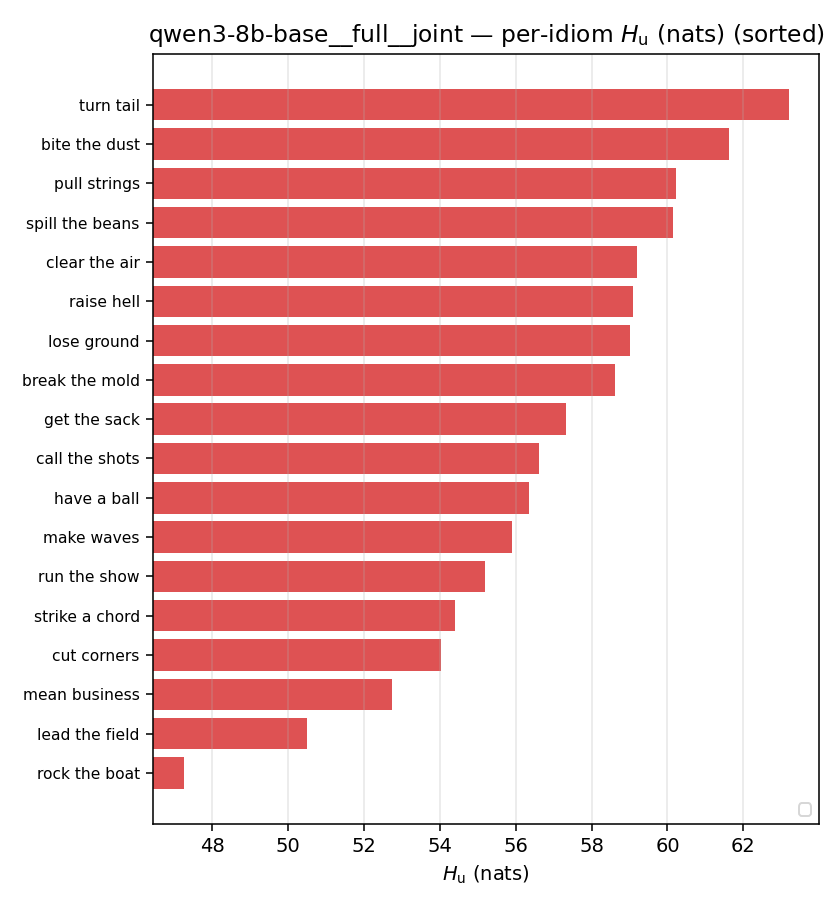 | 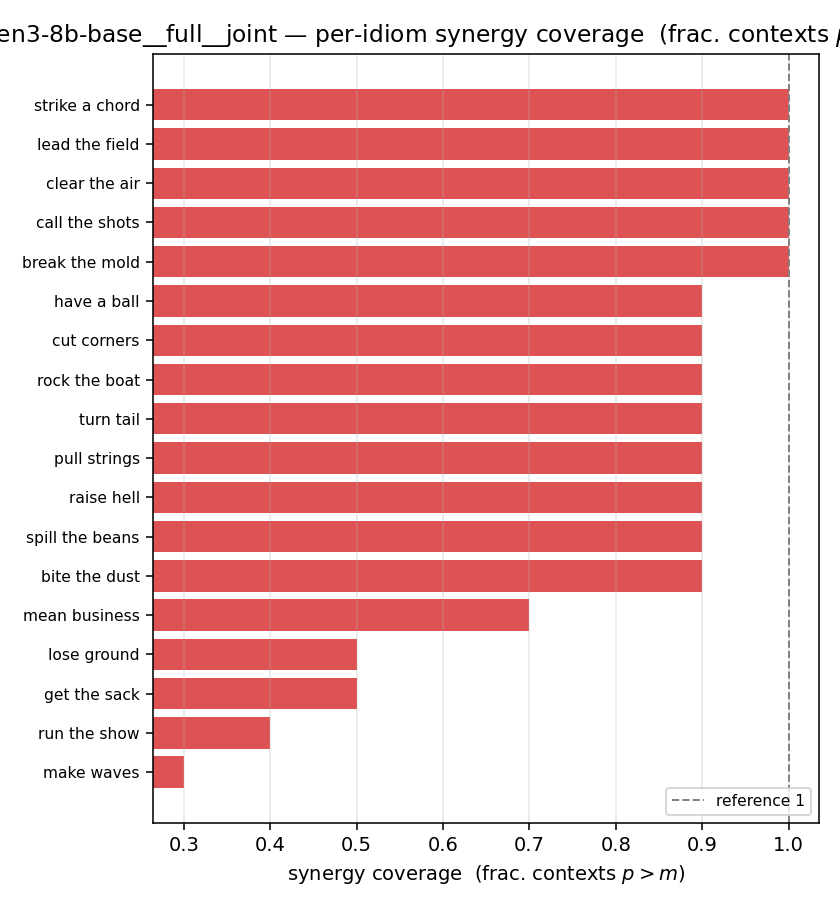 | 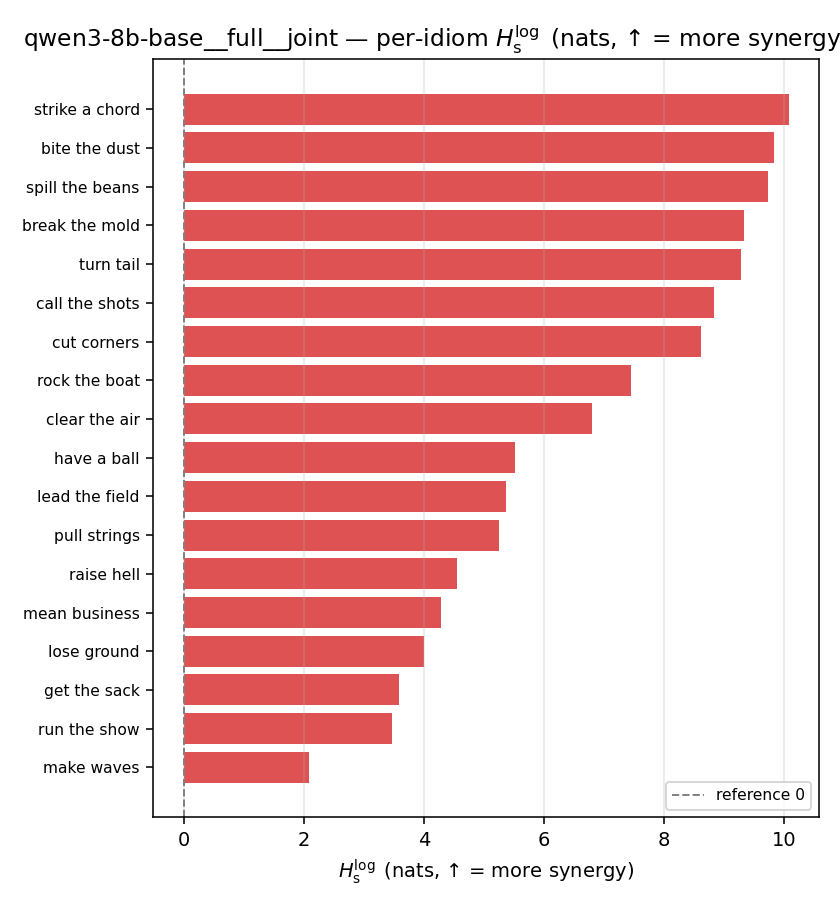 | 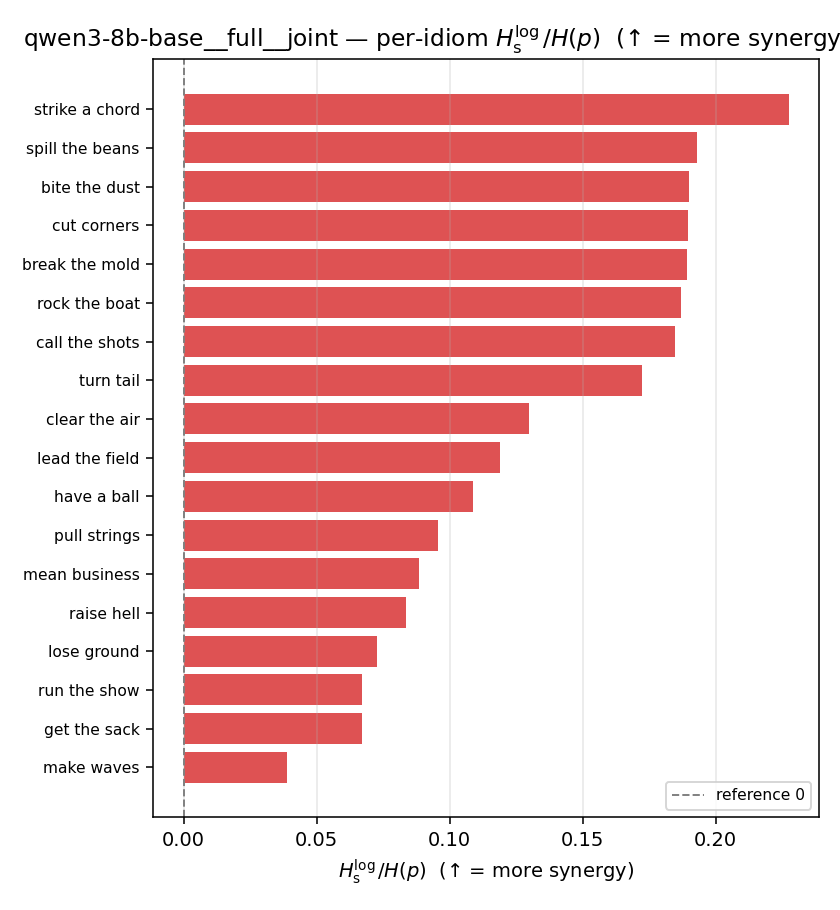 | 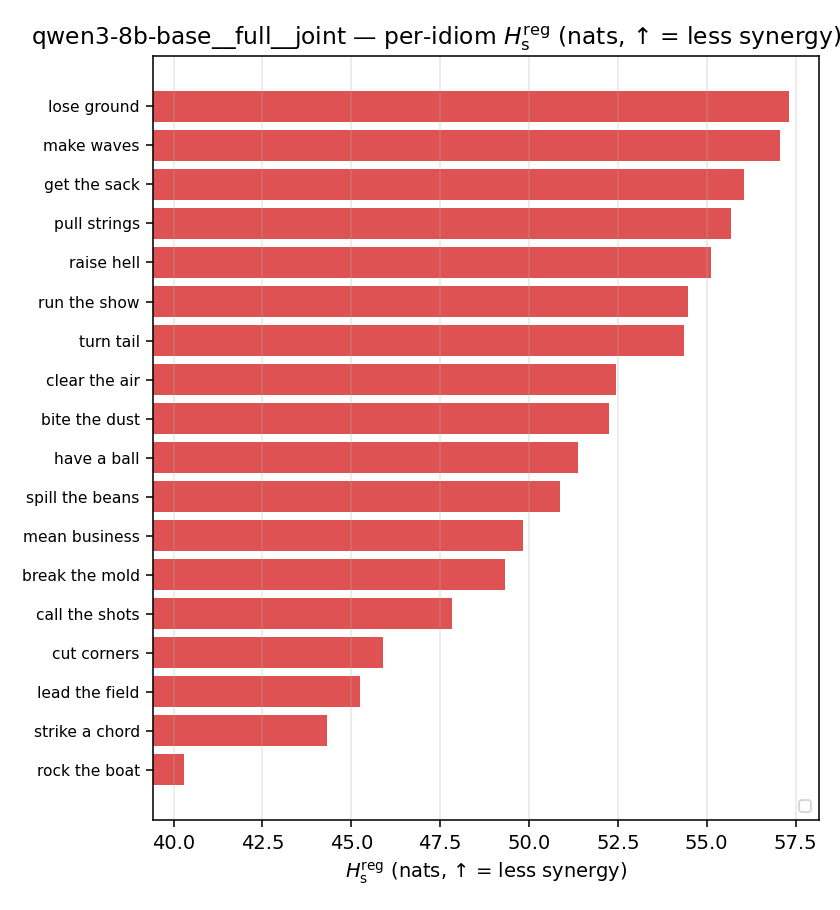 | 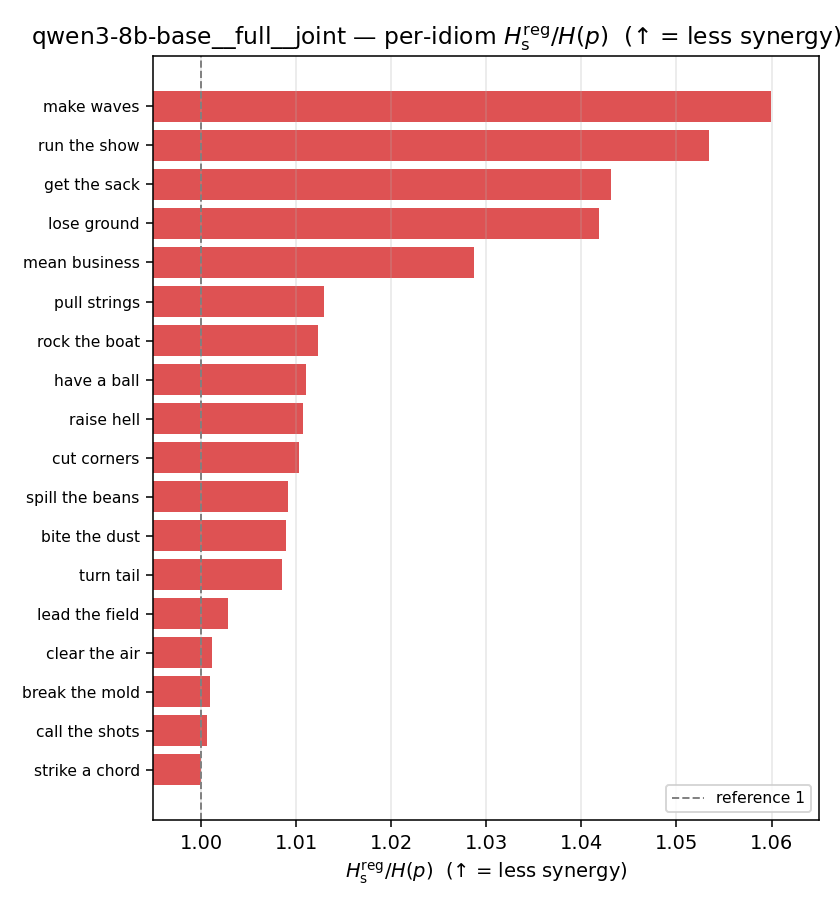 | — (no finite values) | — (no finite values) |
qwen3-8b — per-config figures
3×9 grid of figure-type × metric (↑syn = bigger means more synergy, ↓syn = bigger means less). Tables scroll horizontally; “— (no finite values)” marks the original Hs/ratio_s where every phrase was +inf. Click to zoom.
qwen3-8b · medial · geo qwen3-8b__medial__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 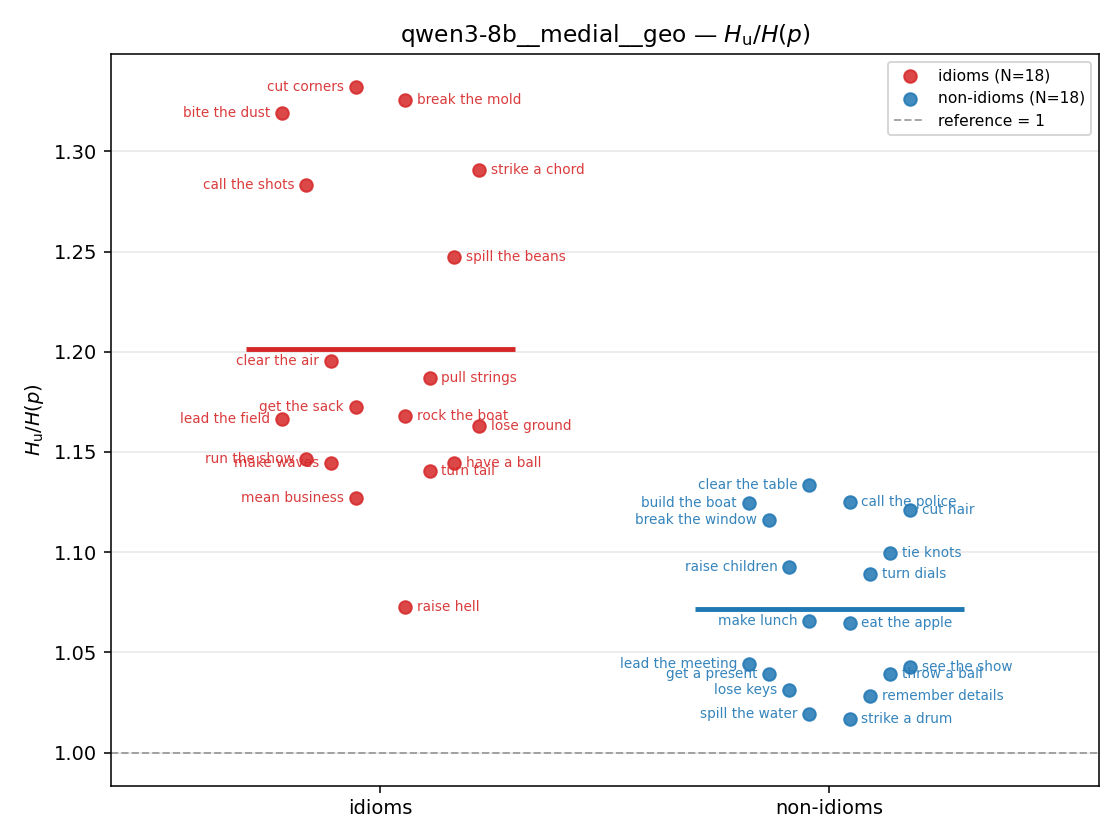 | 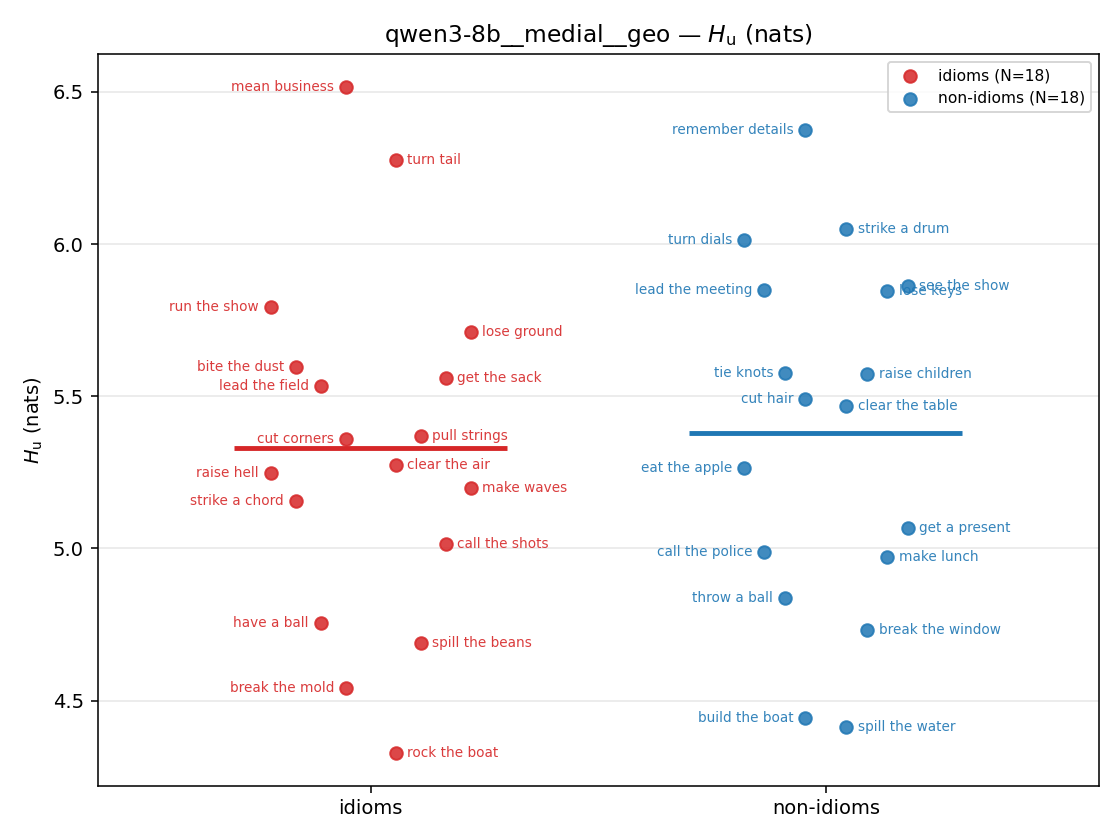 | 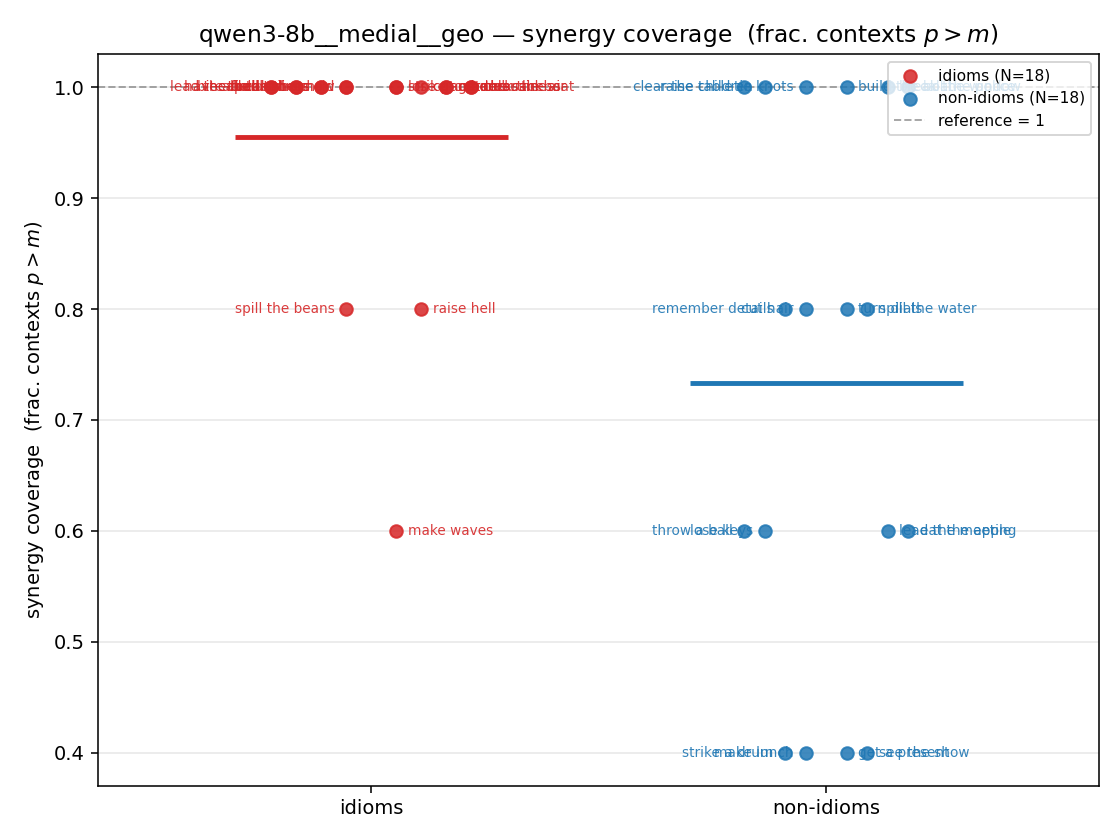 | 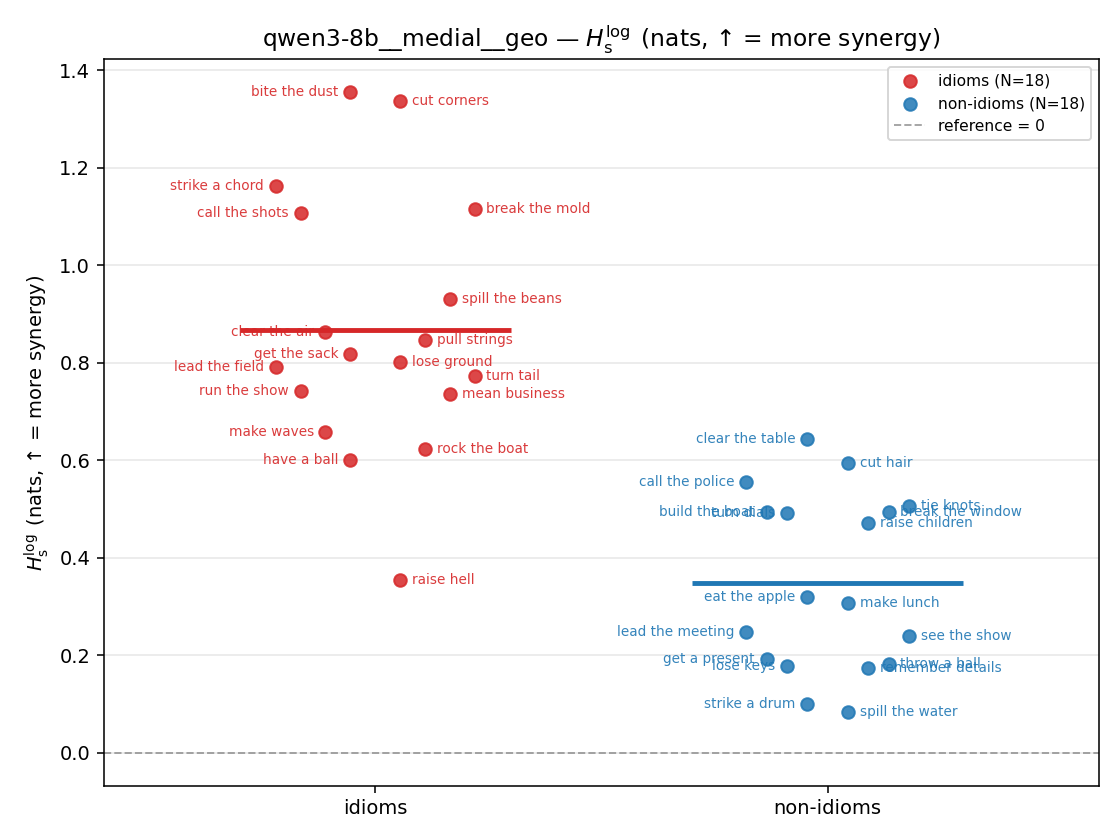 | 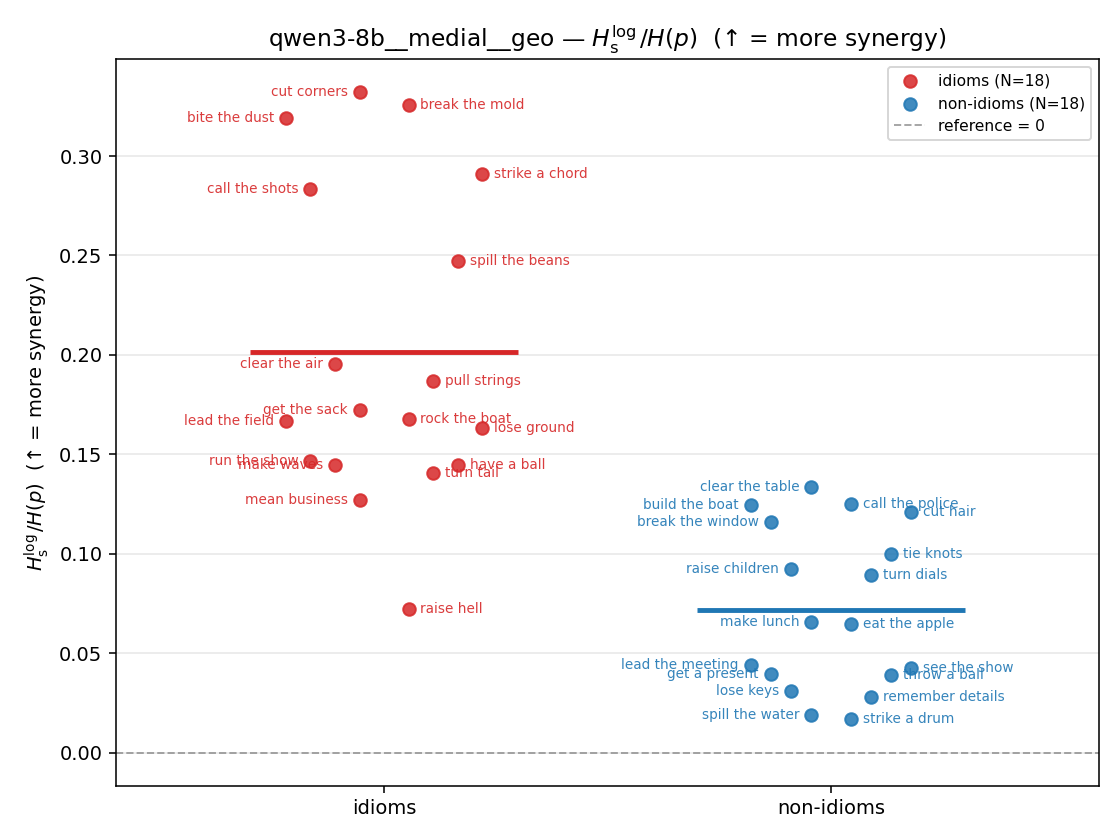 | 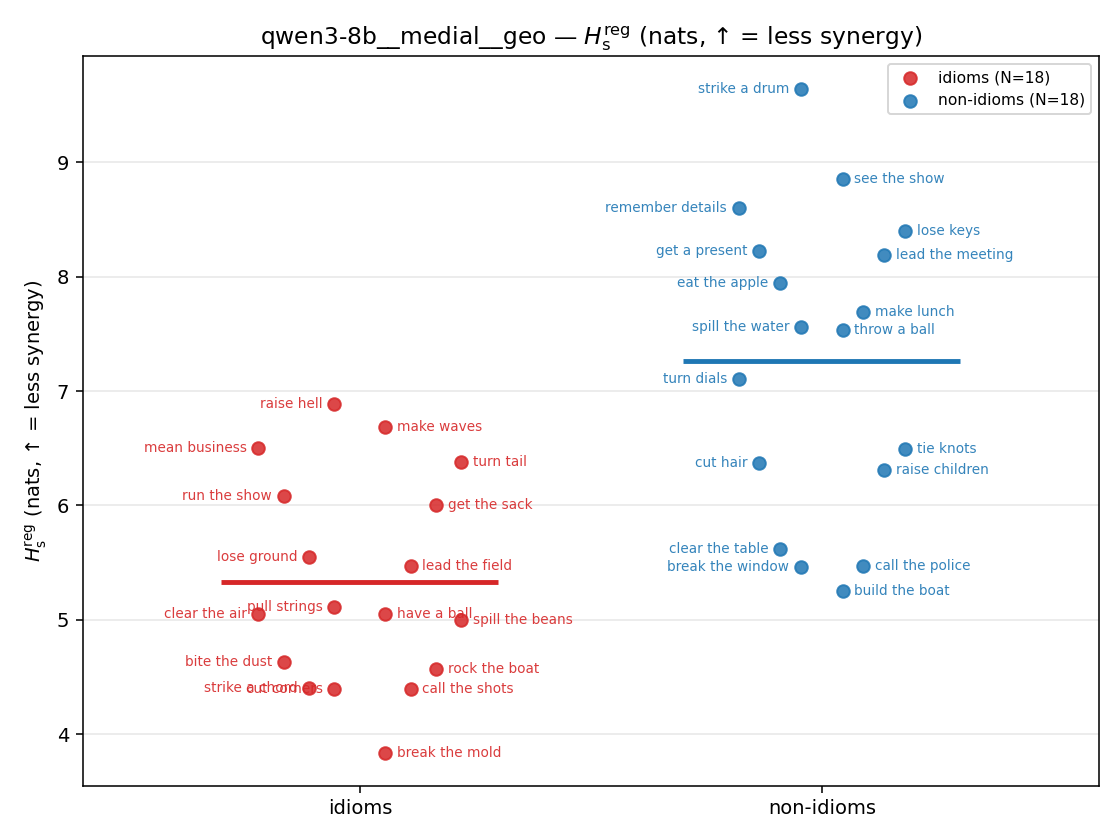 | 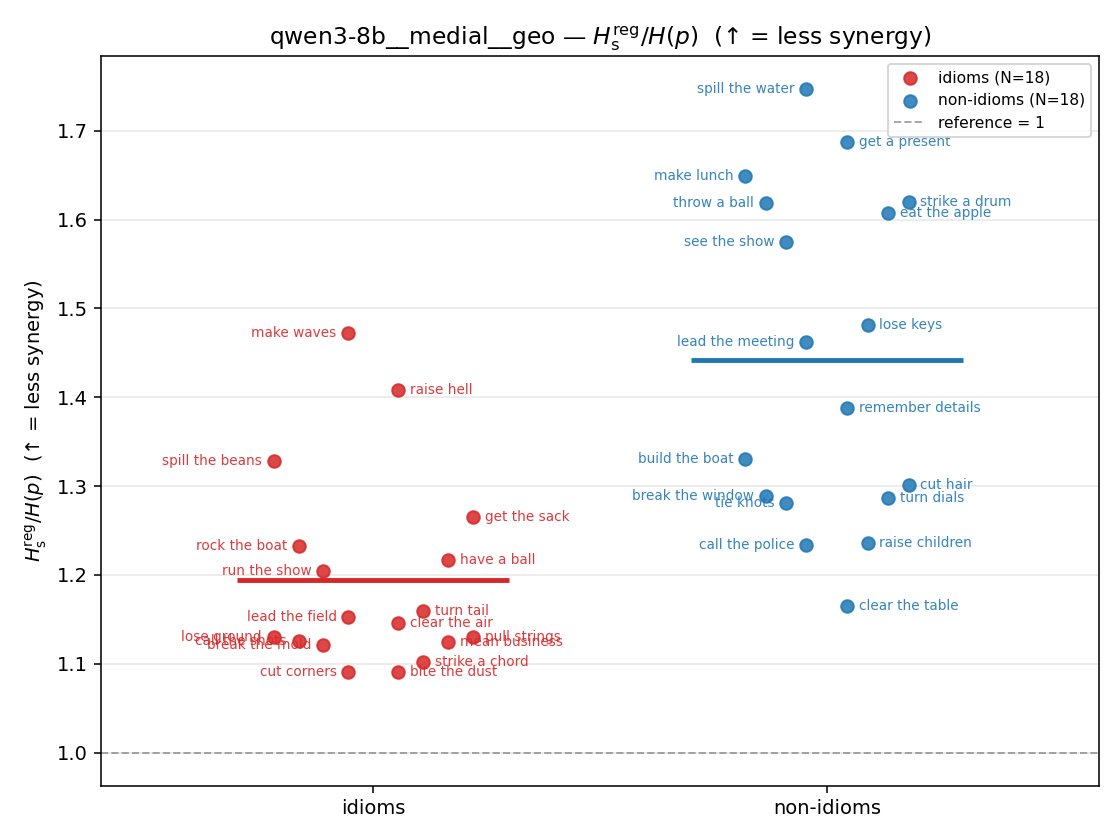 | 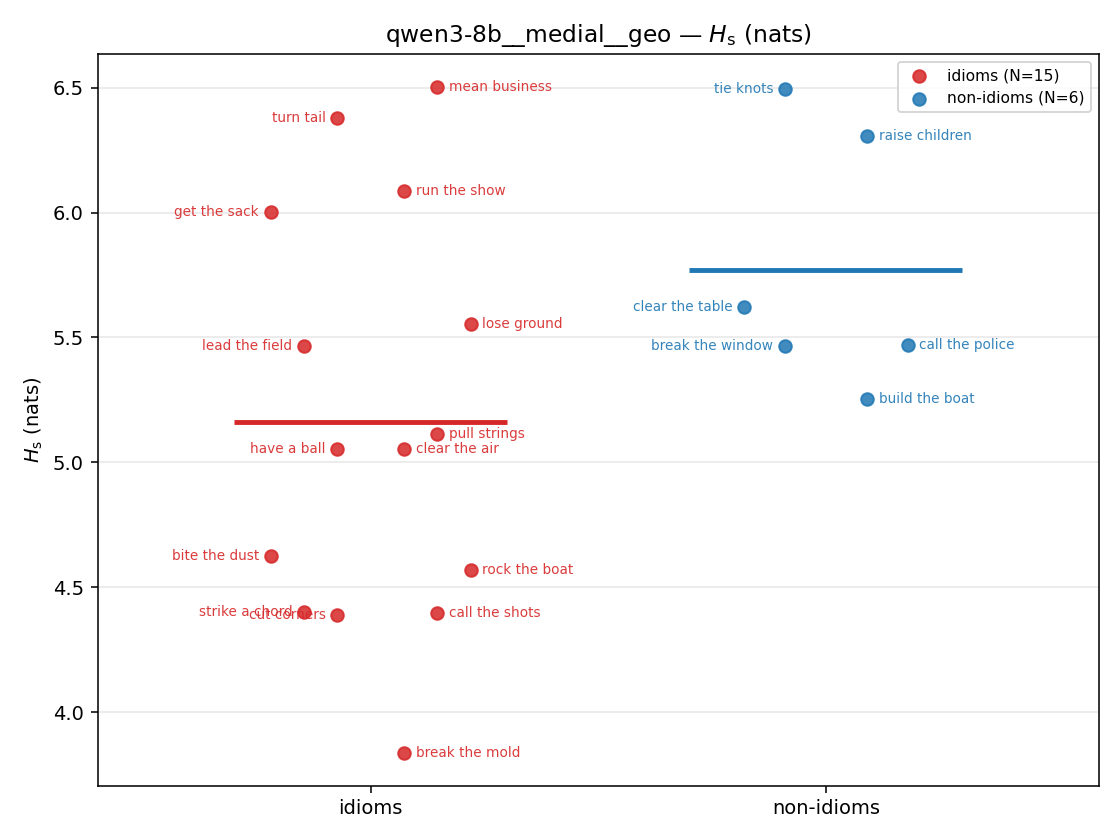 | 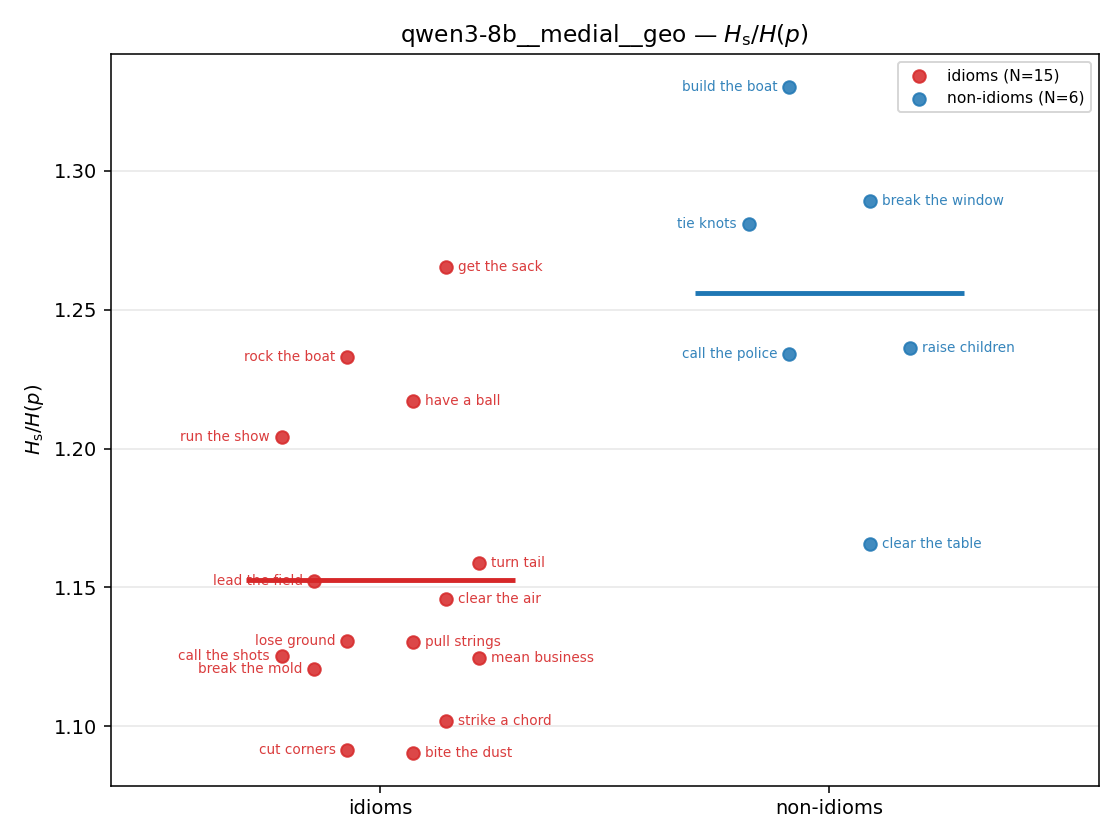 |
| mean ± 95% CI | 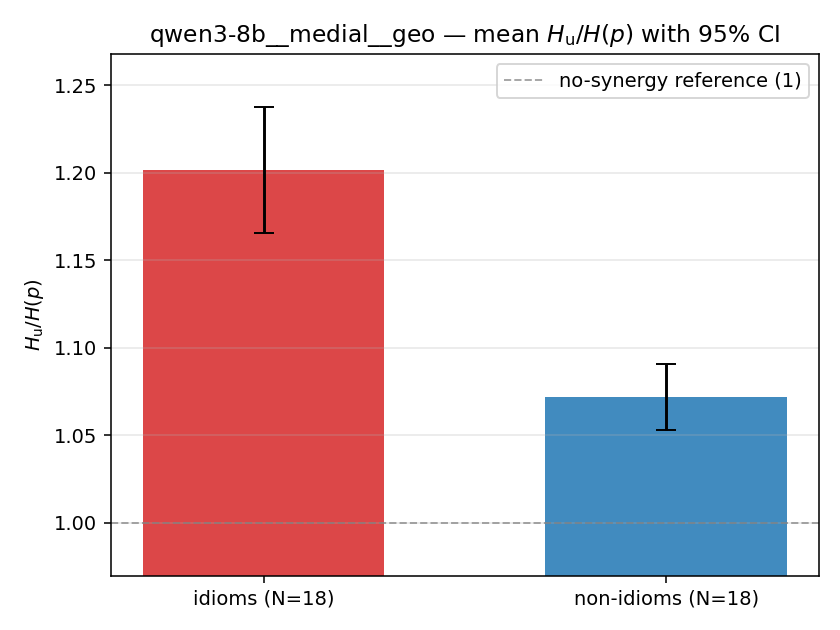 | 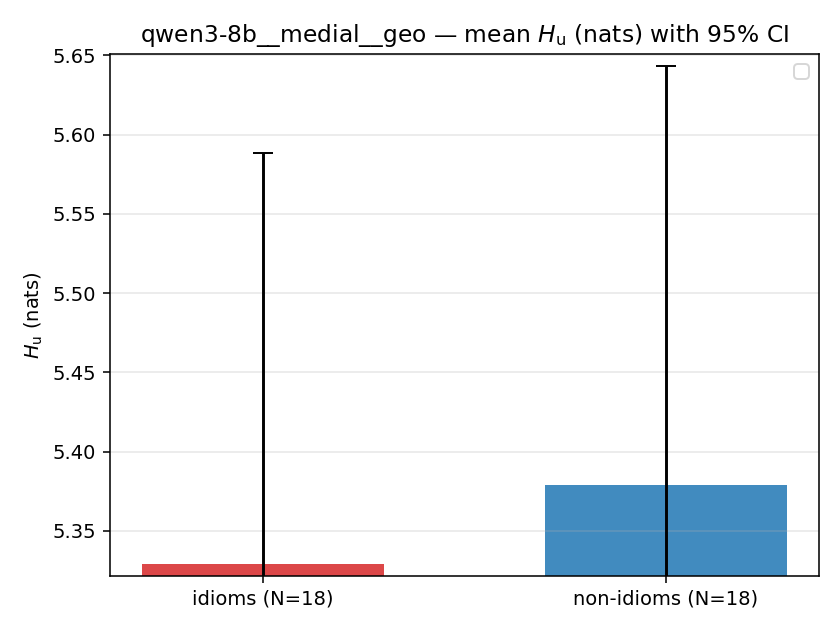 | 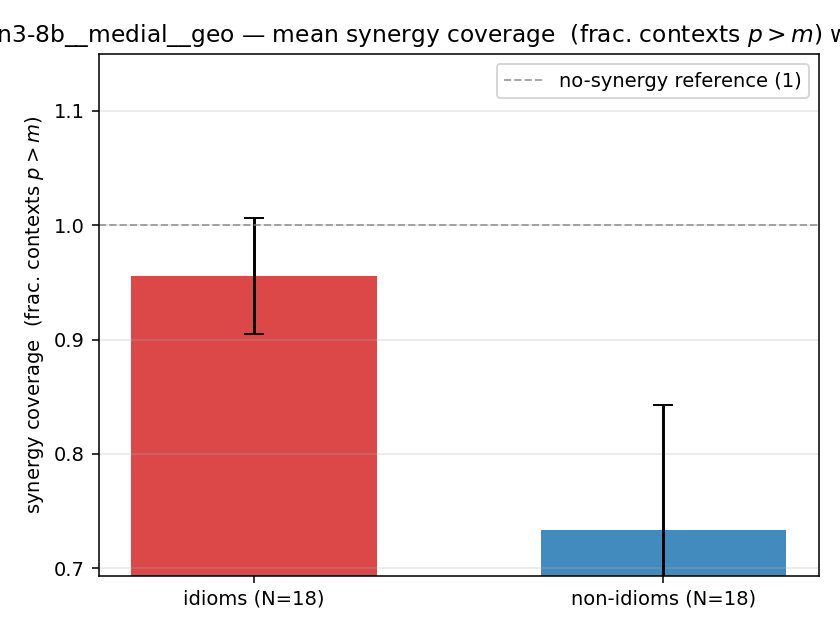 | 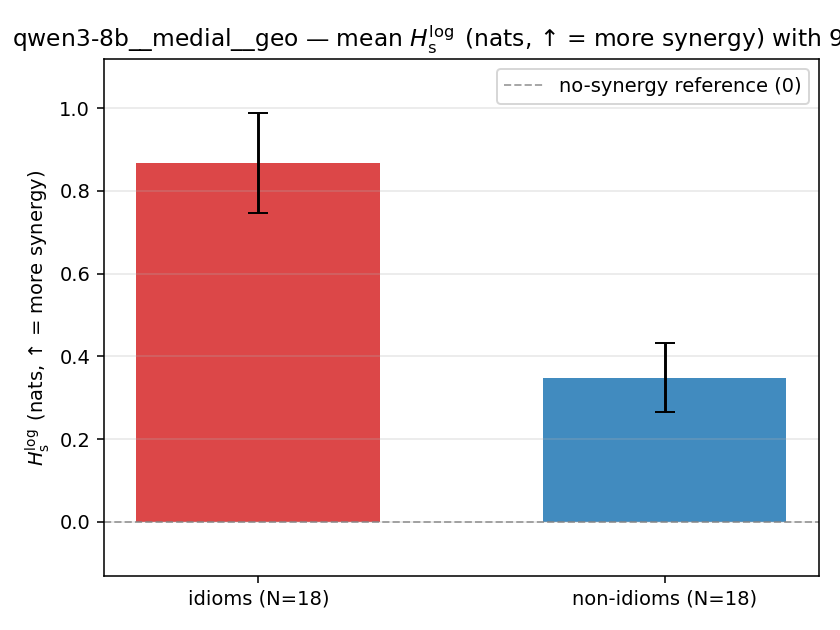 | 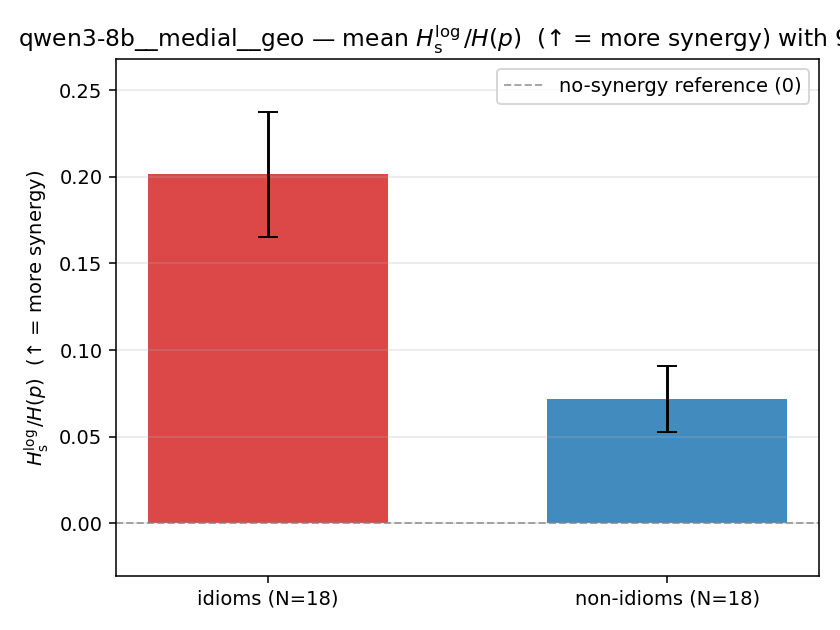 | 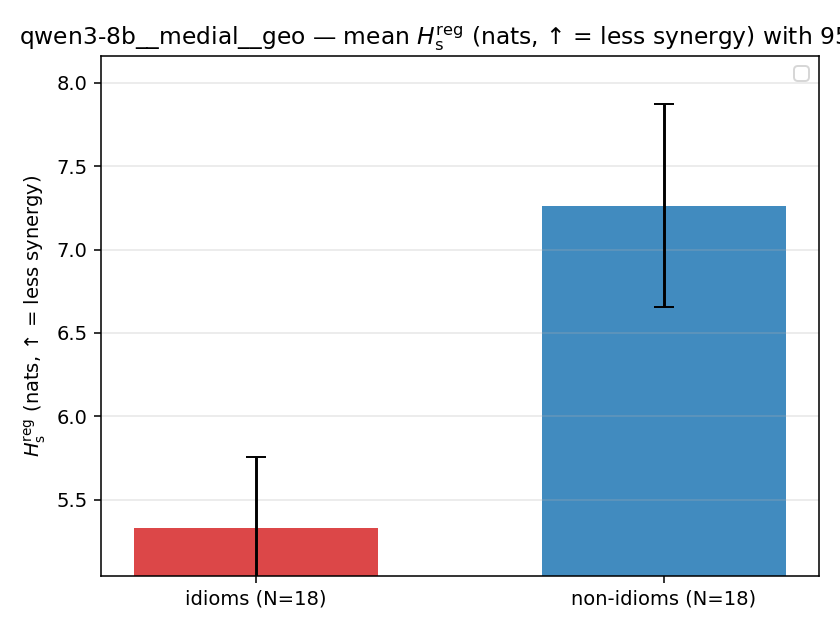 | 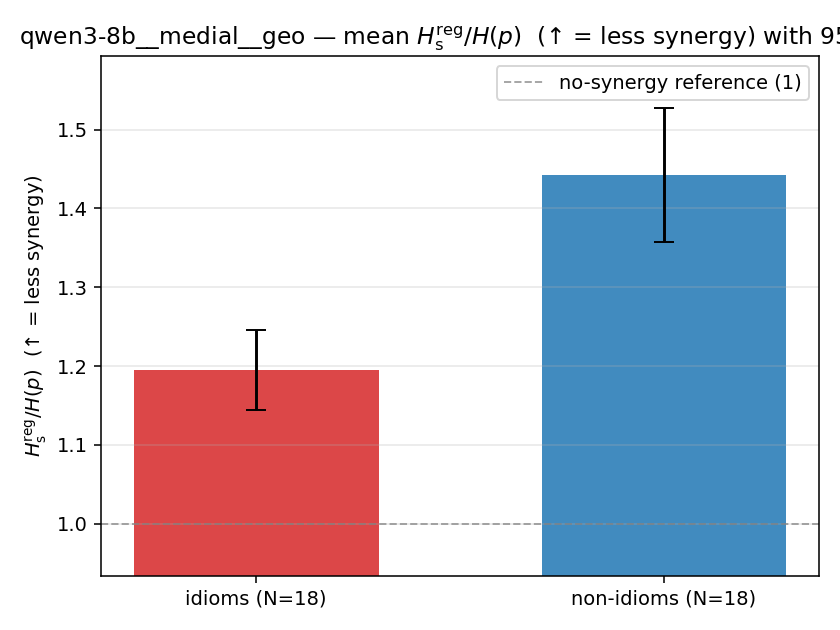 | 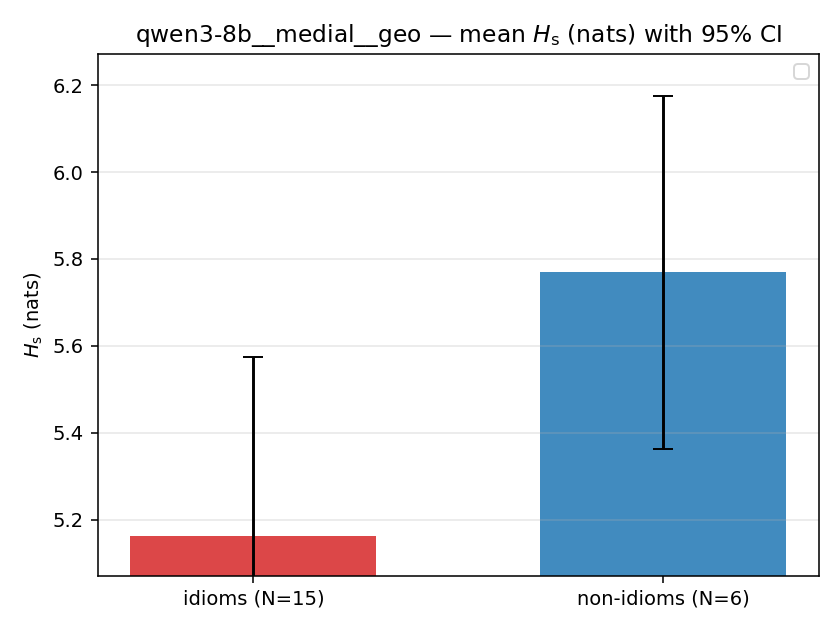 | 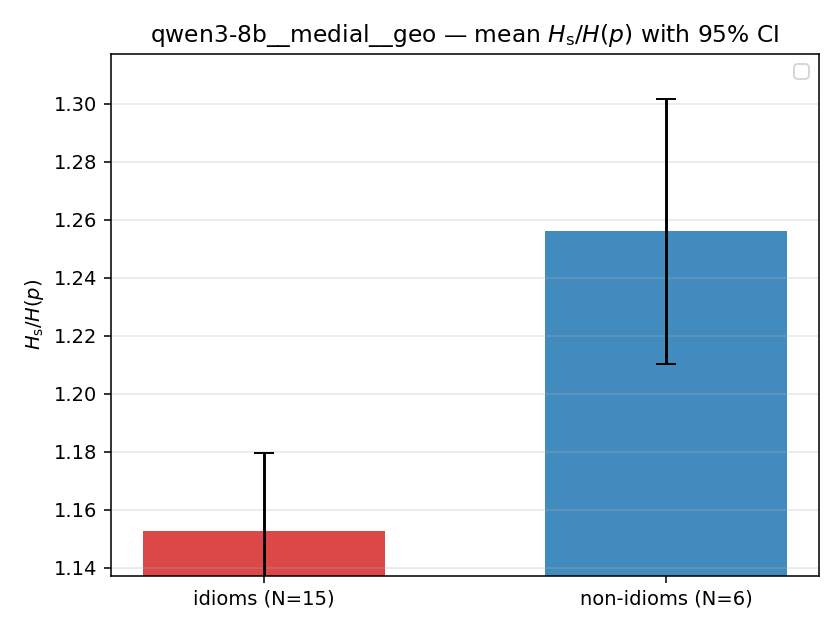 |
| per-idiom (sorted) | 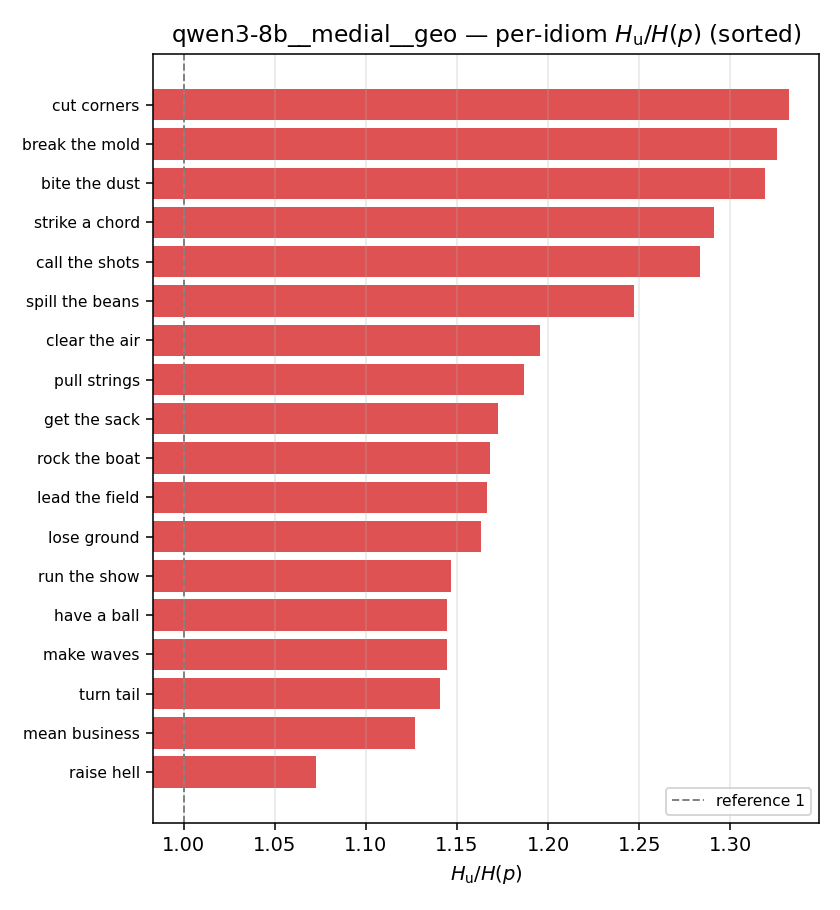 | 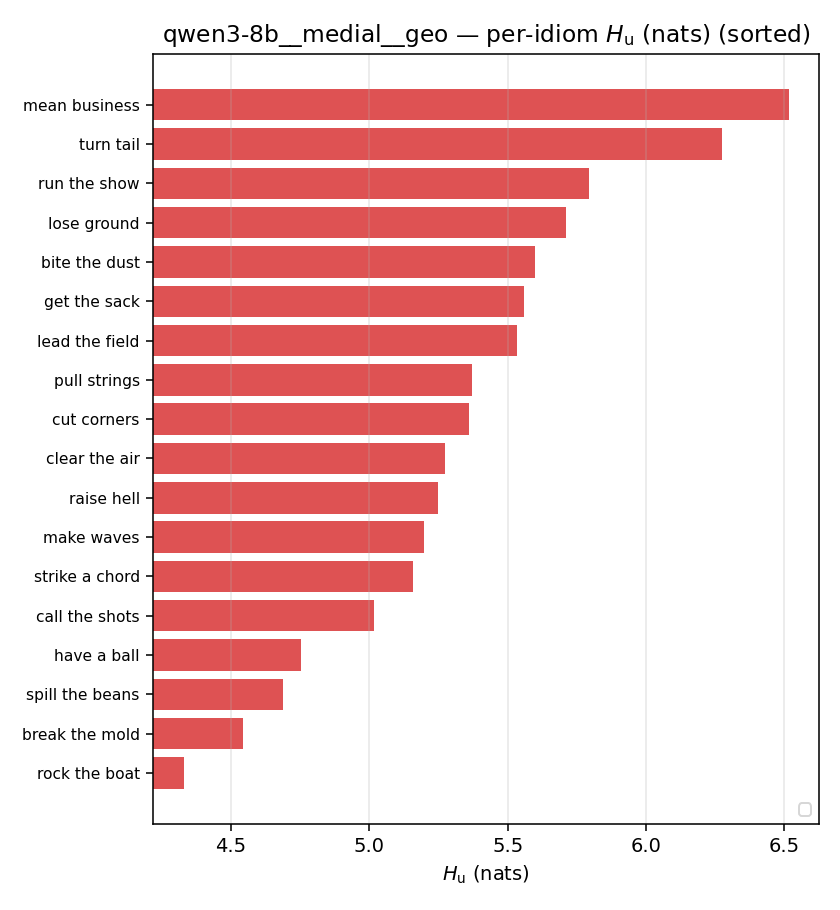 | 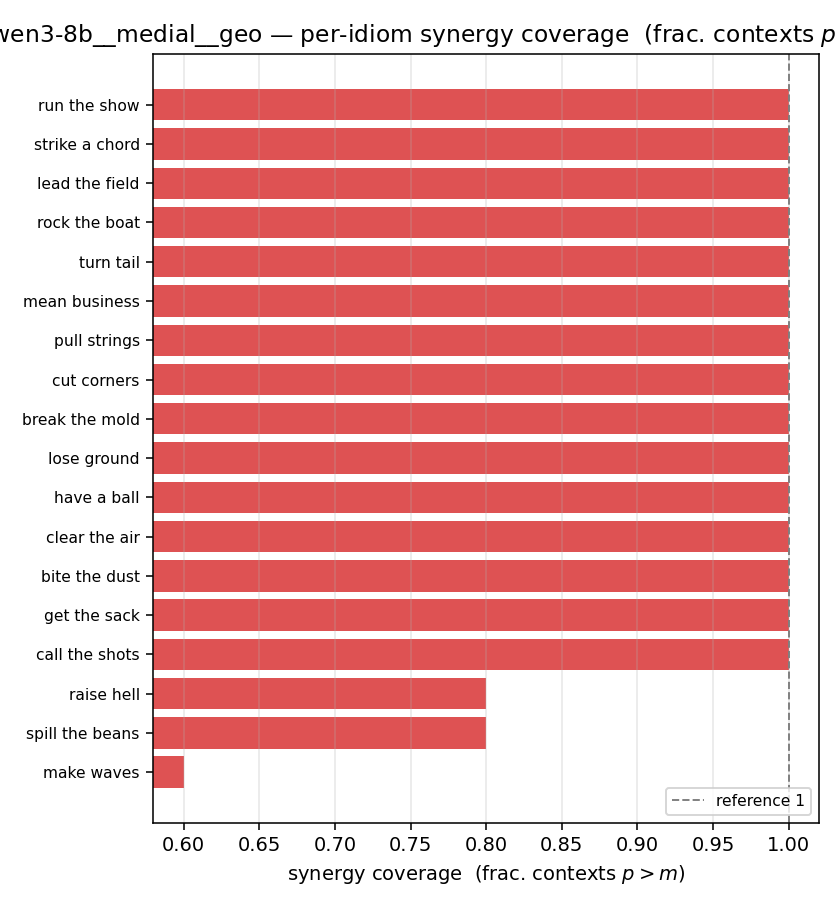 | 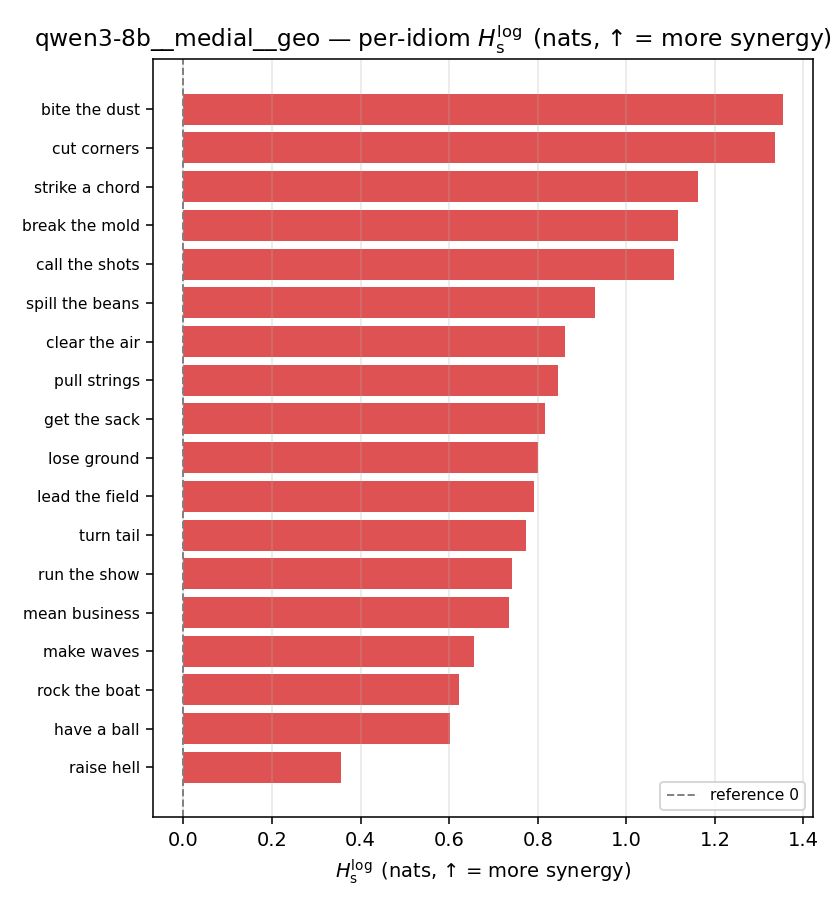 | 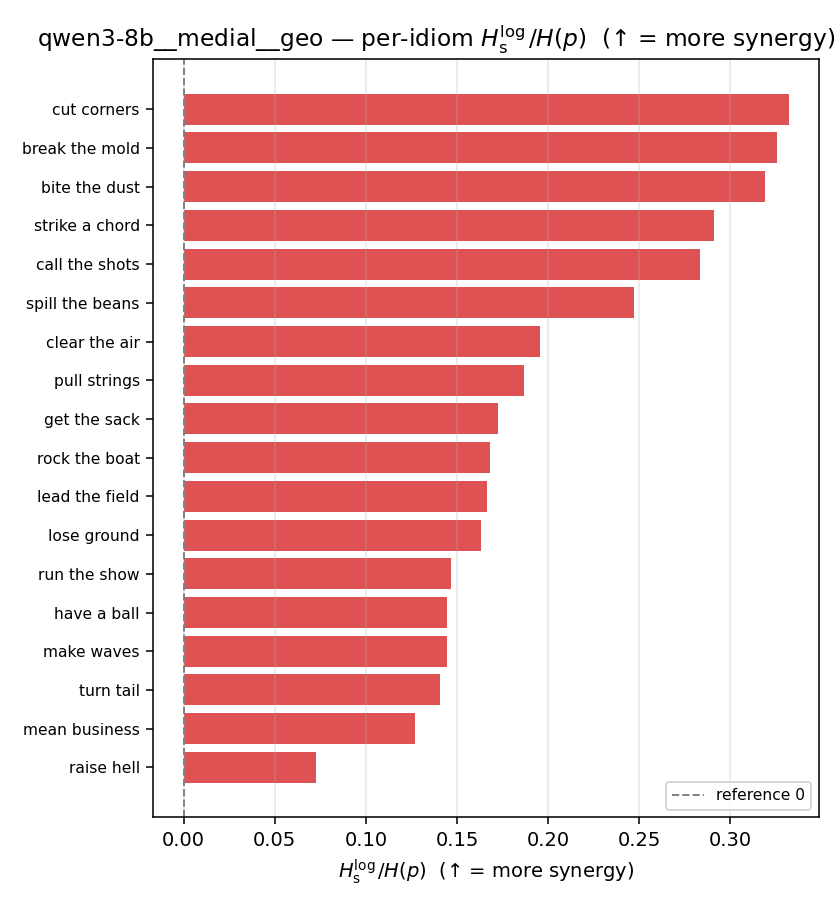 | 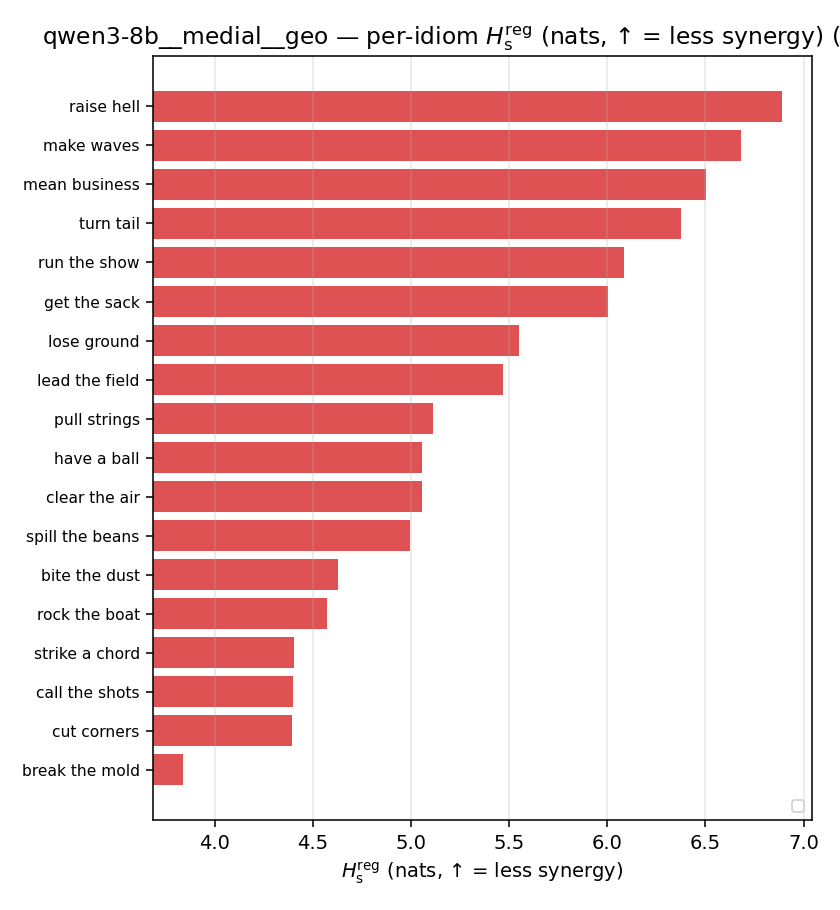 | 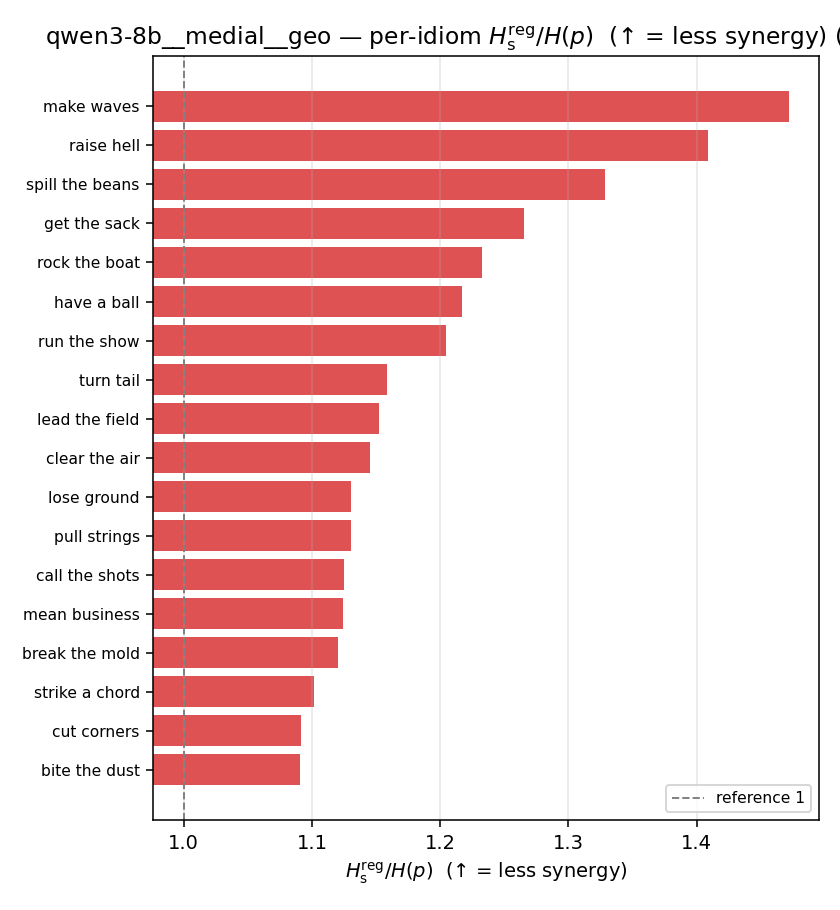 | 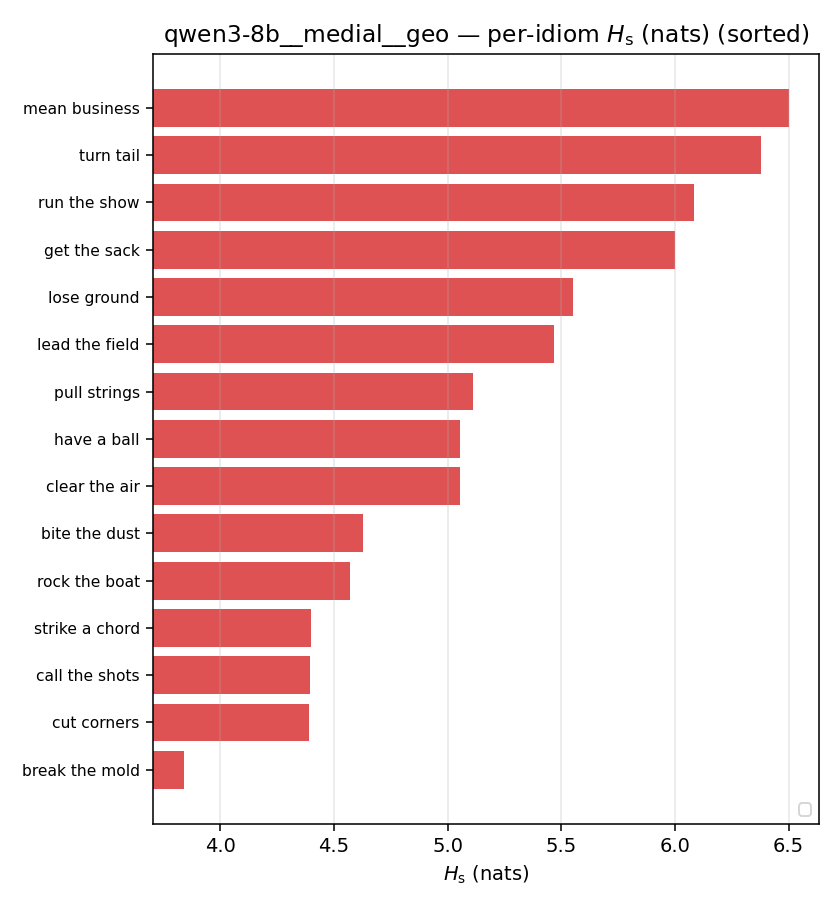 | 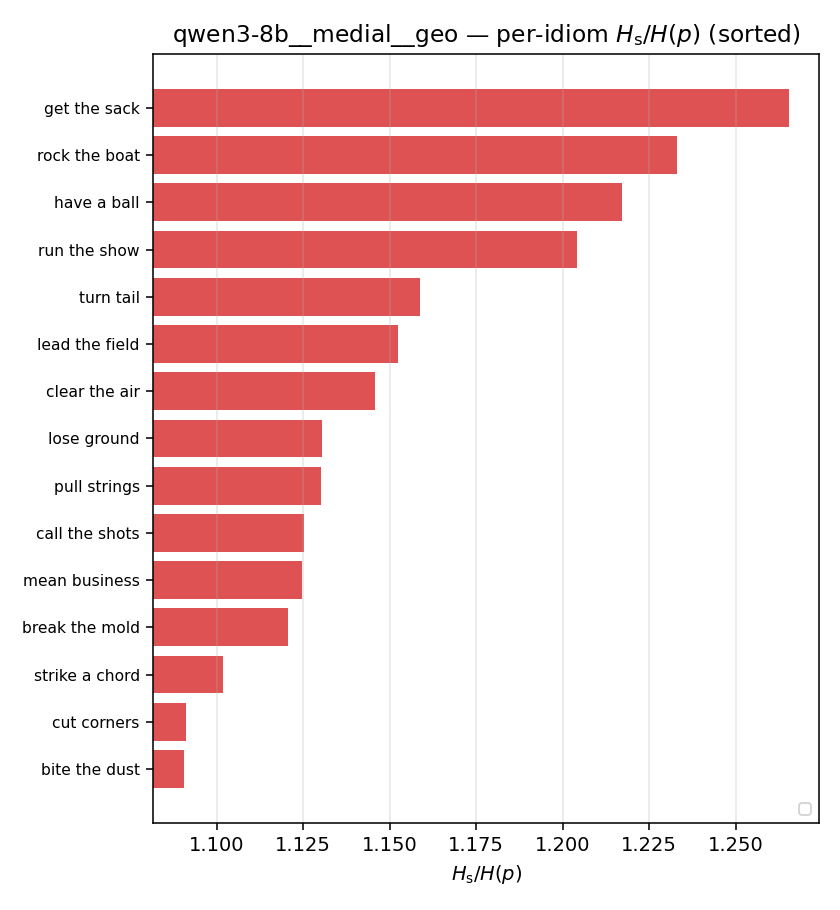 |
qwen3-8b · medial · joint qwen3-8b__medial__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 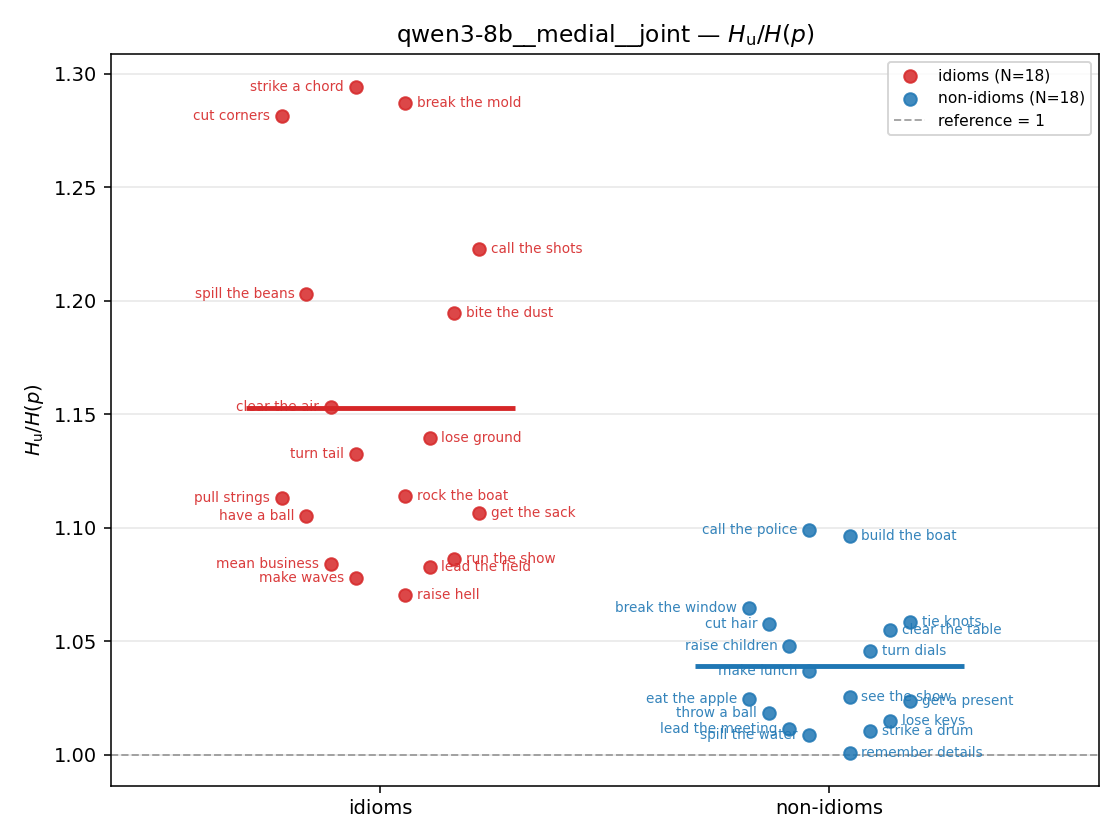 | 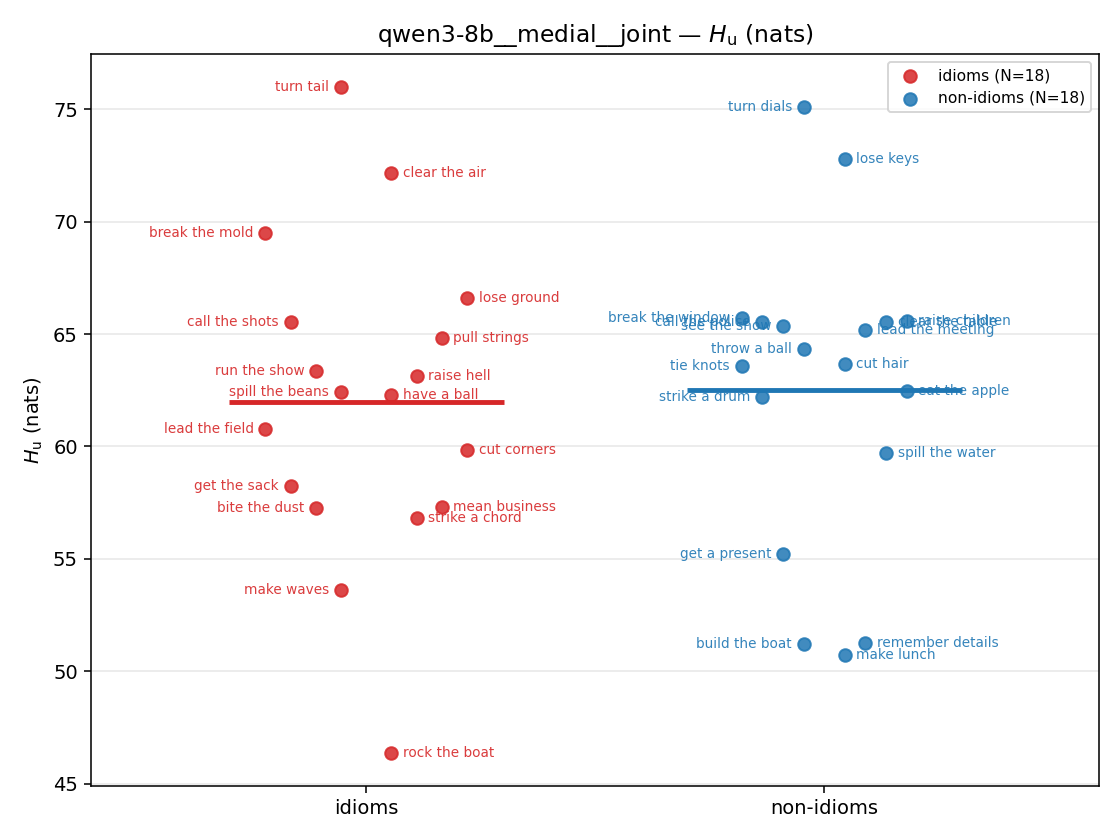 | 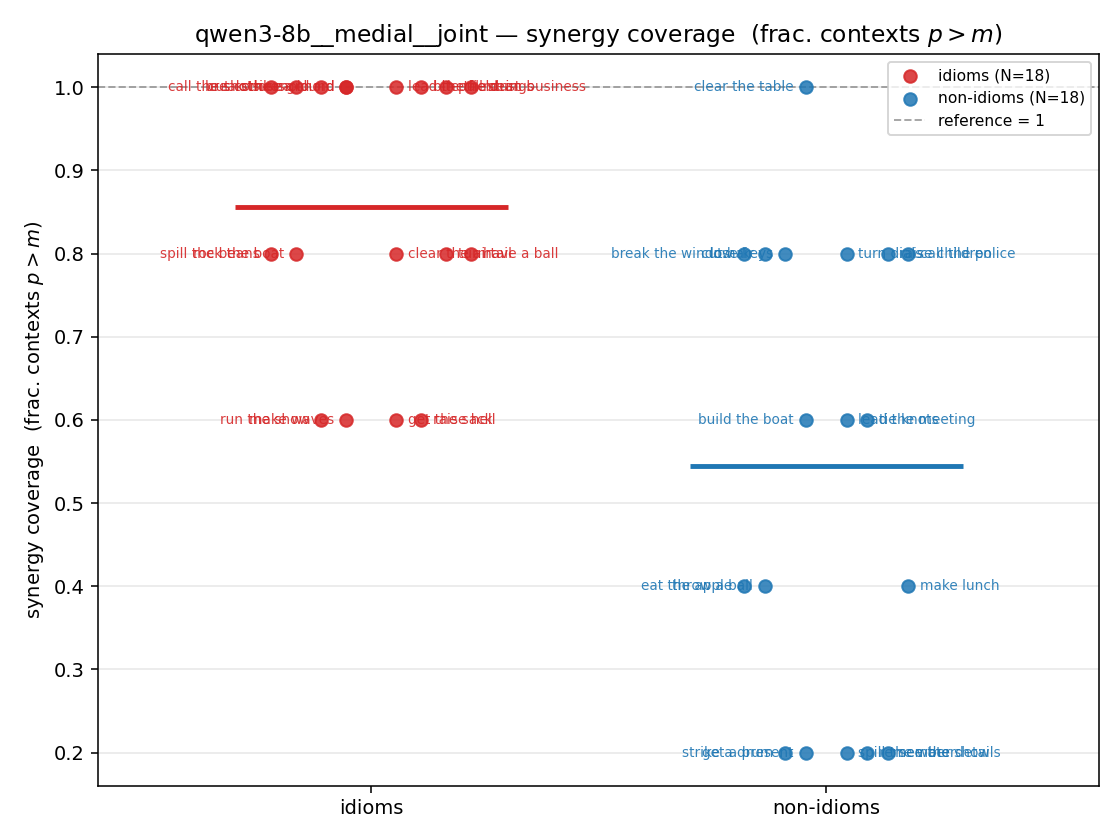 | 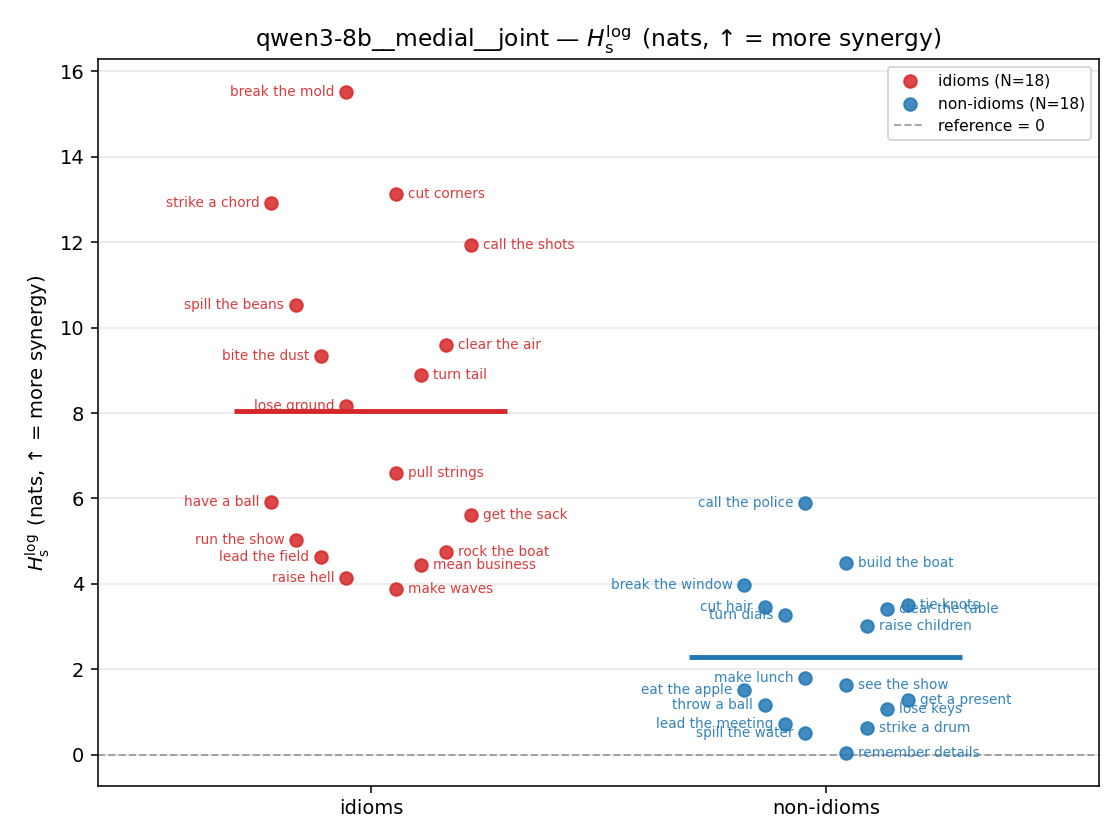 | 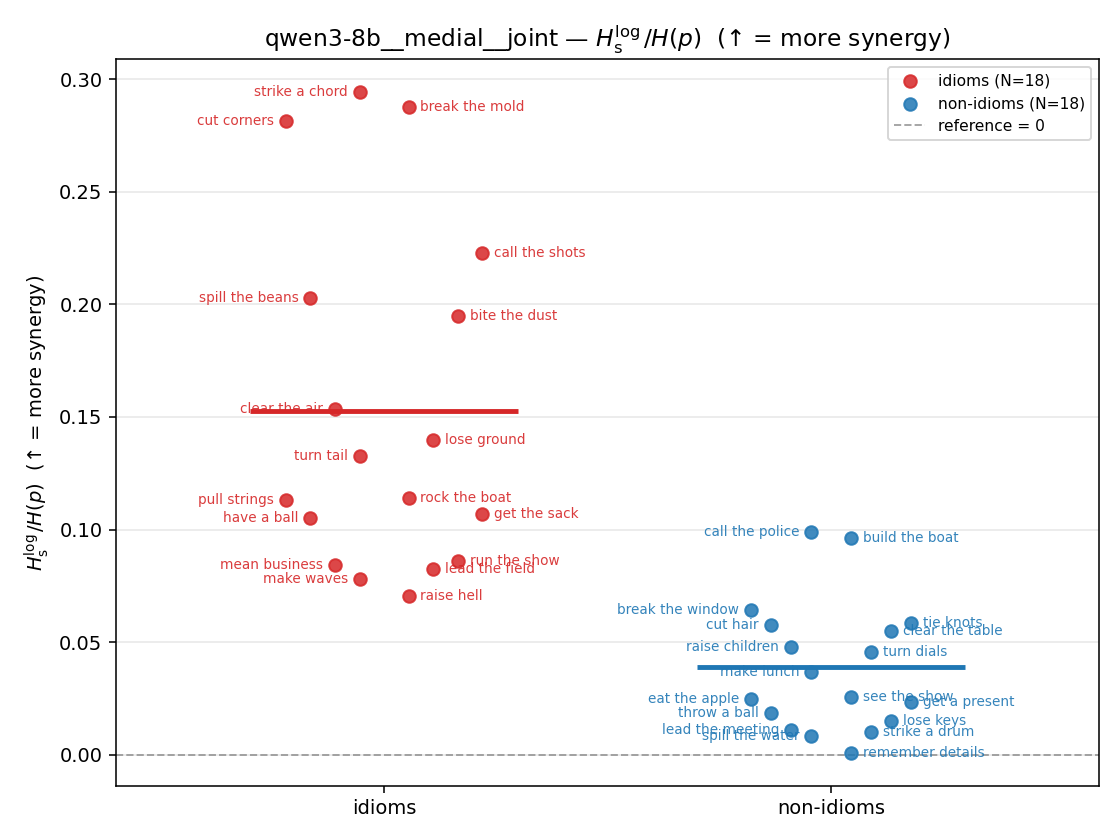 | 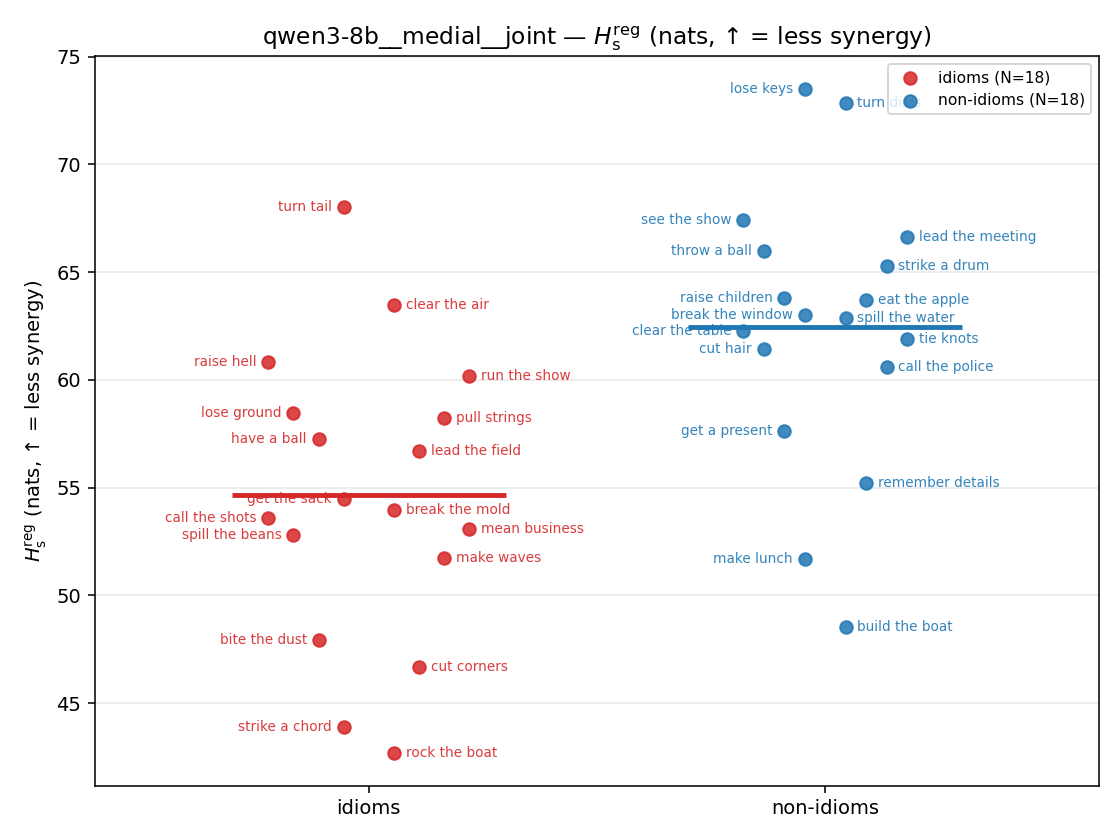 | 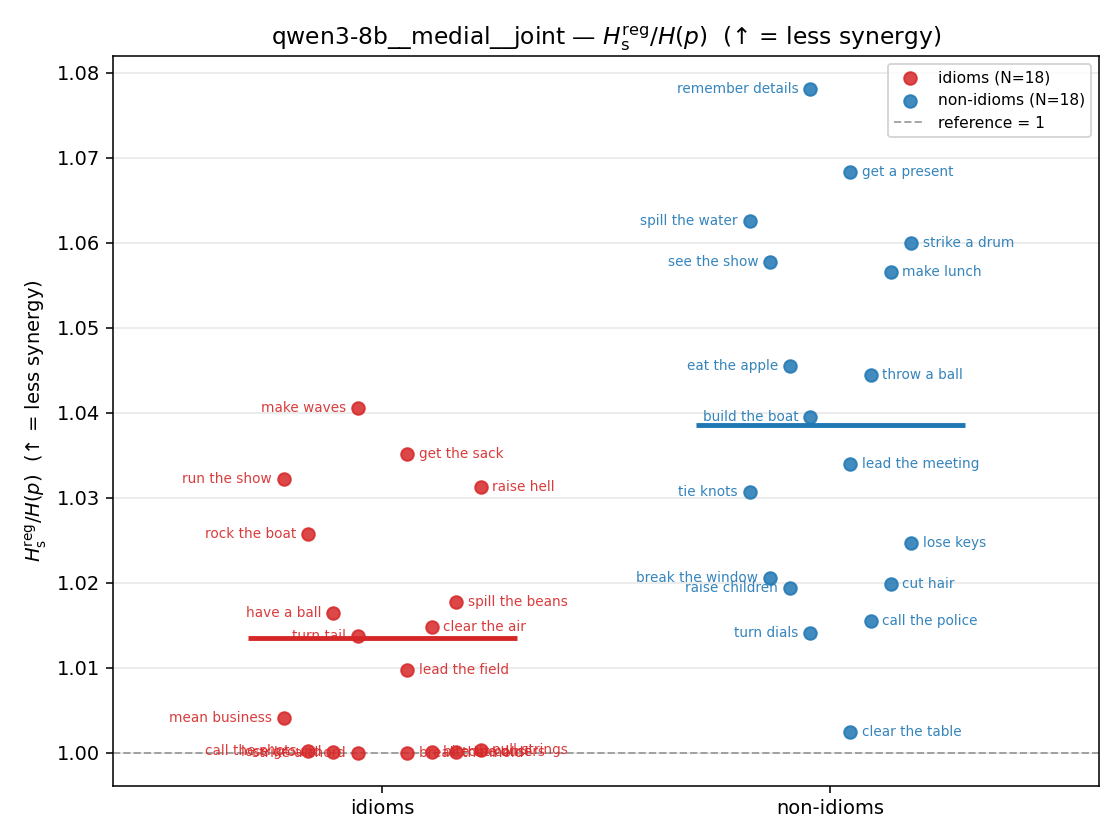 | 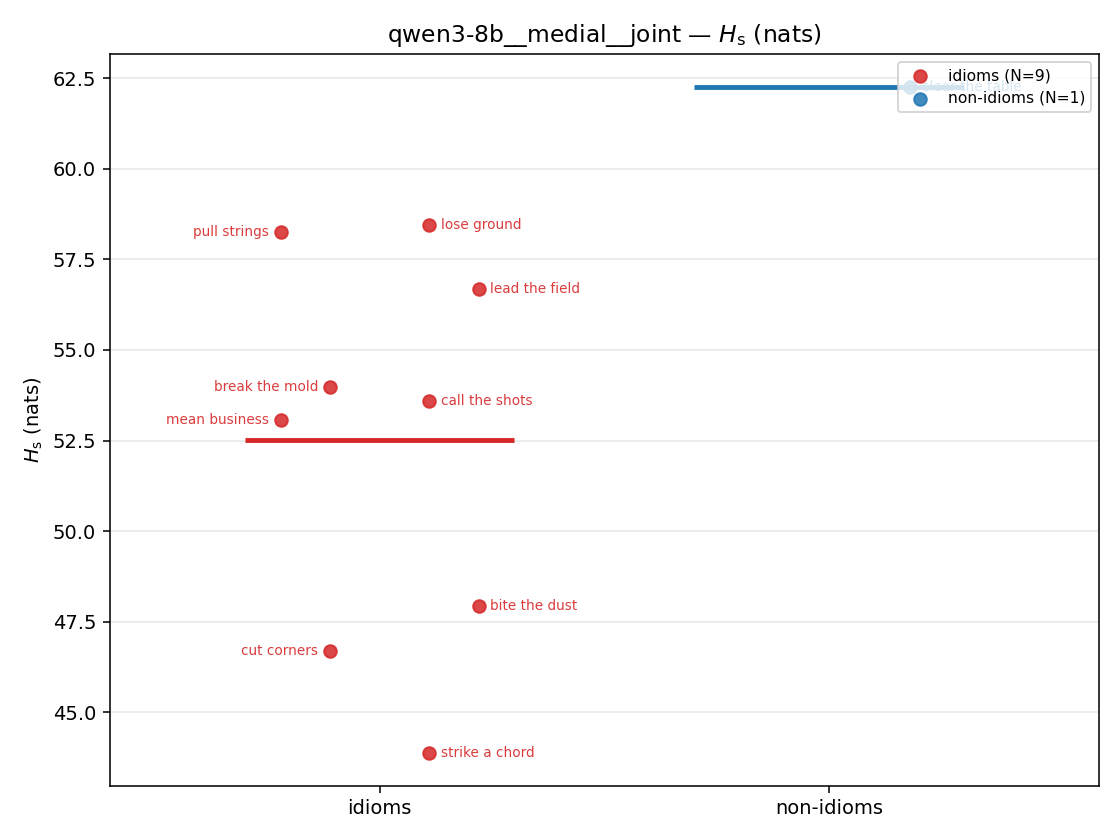 | 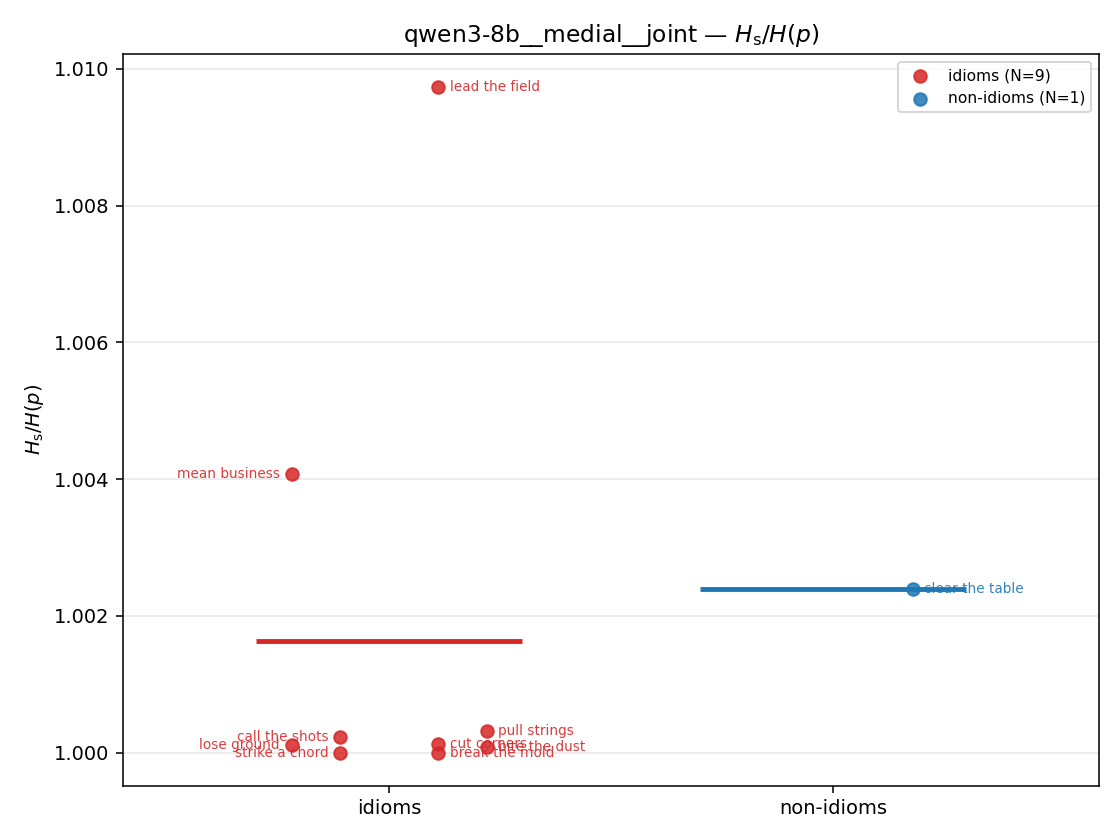 |
| mean ± 95% CI | 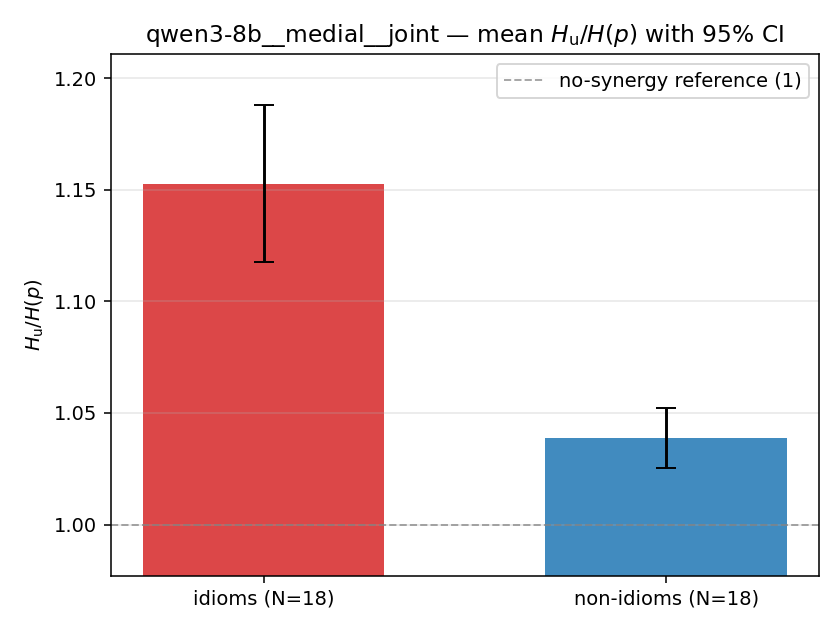 | 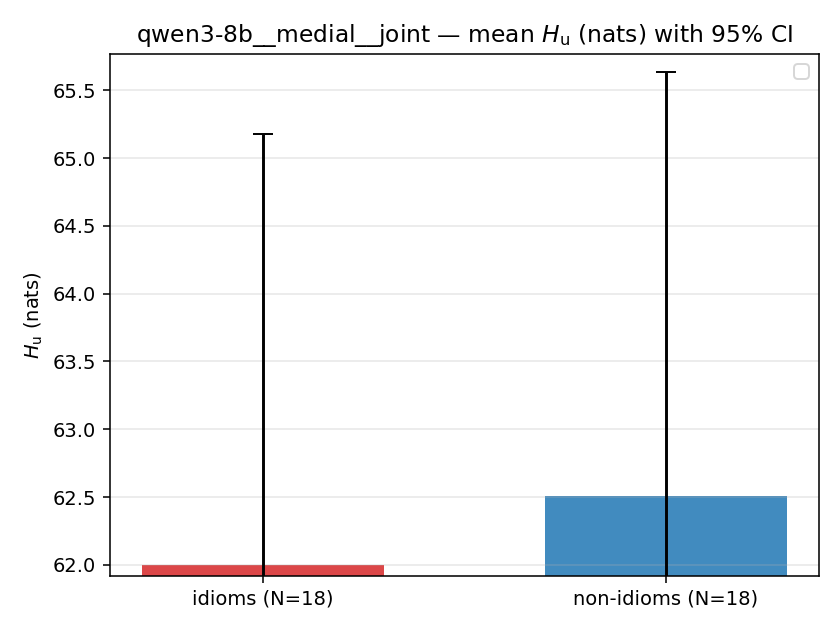 | 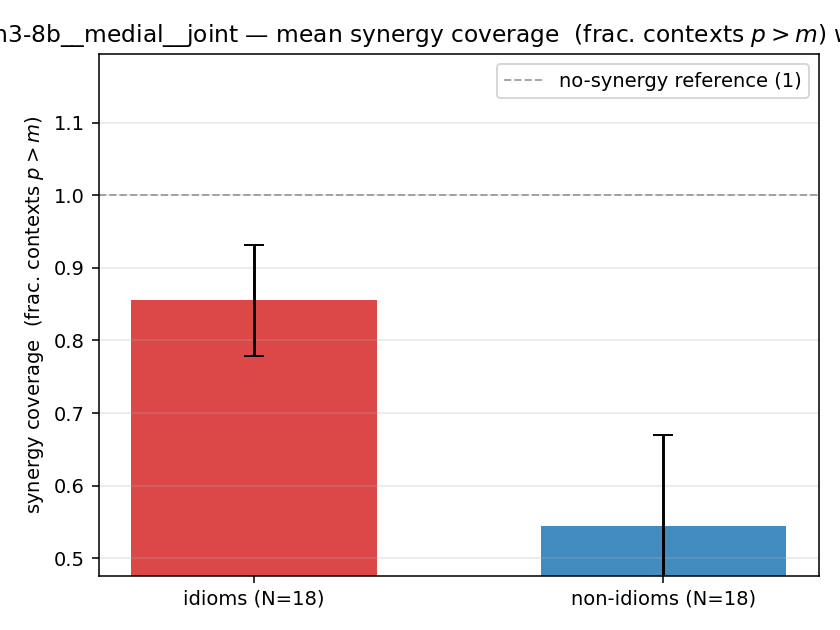 | 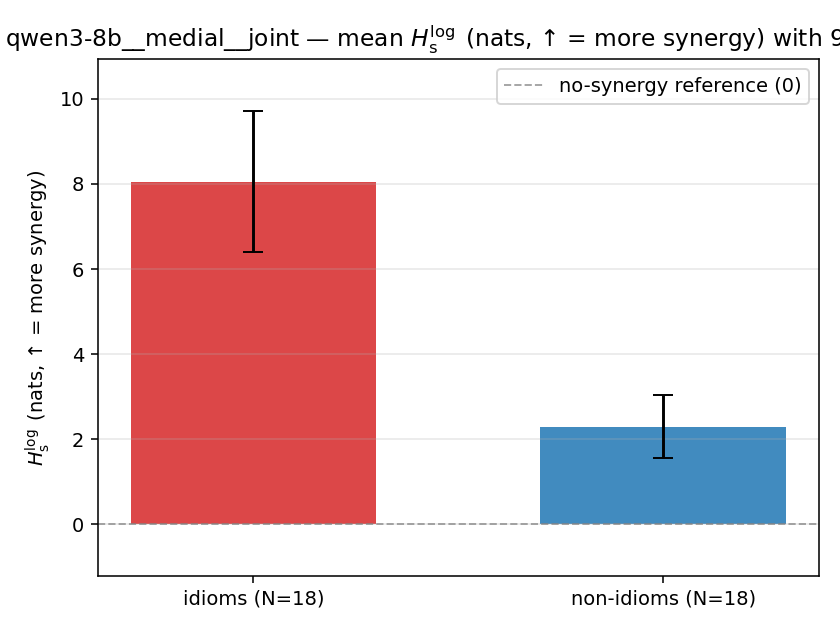 | 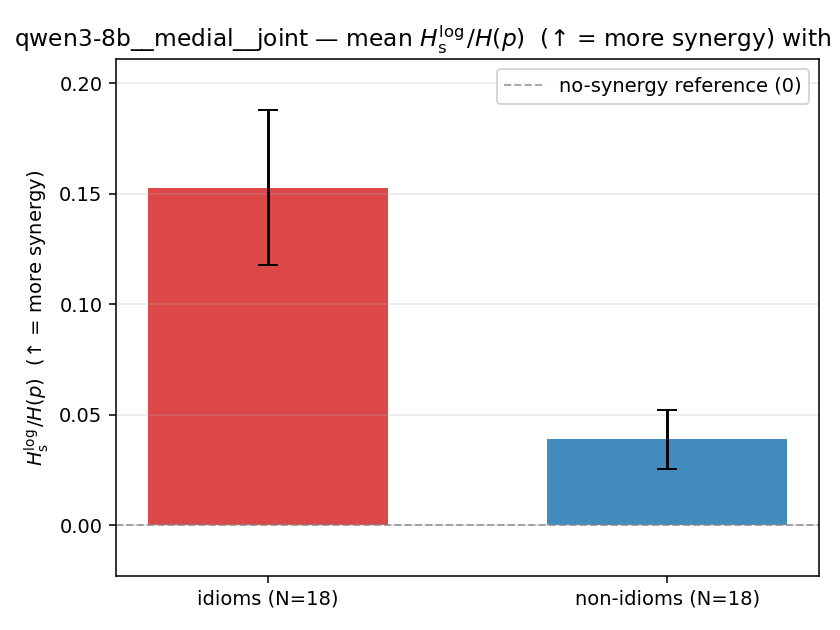 | 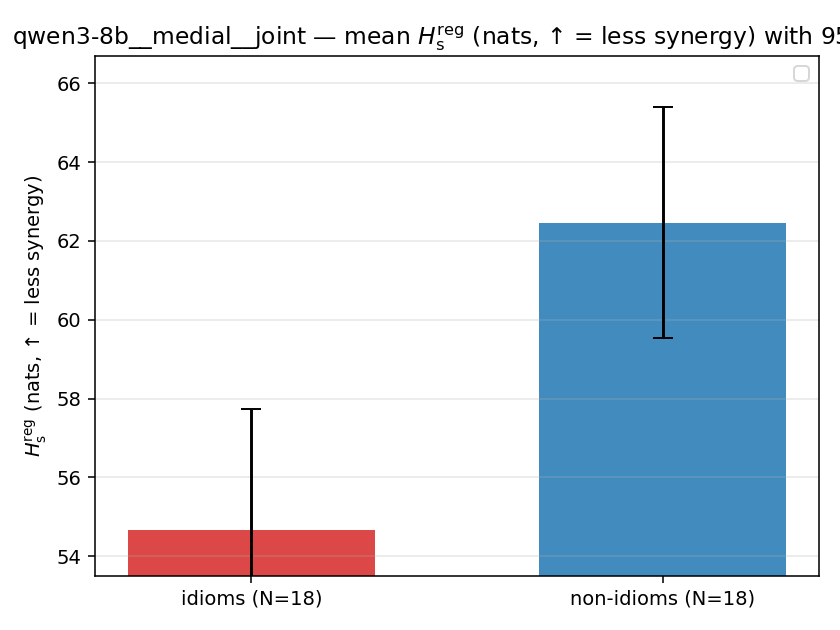 | 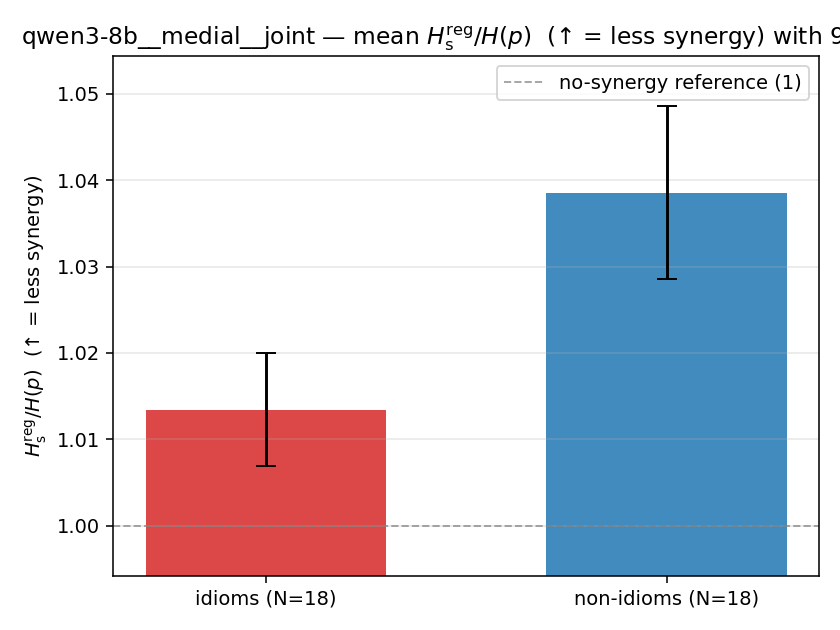 | 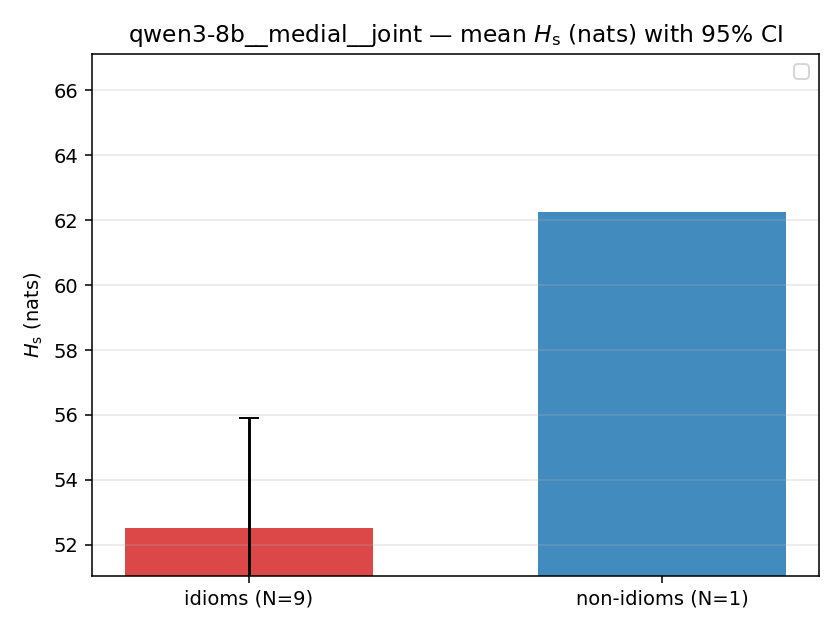 | 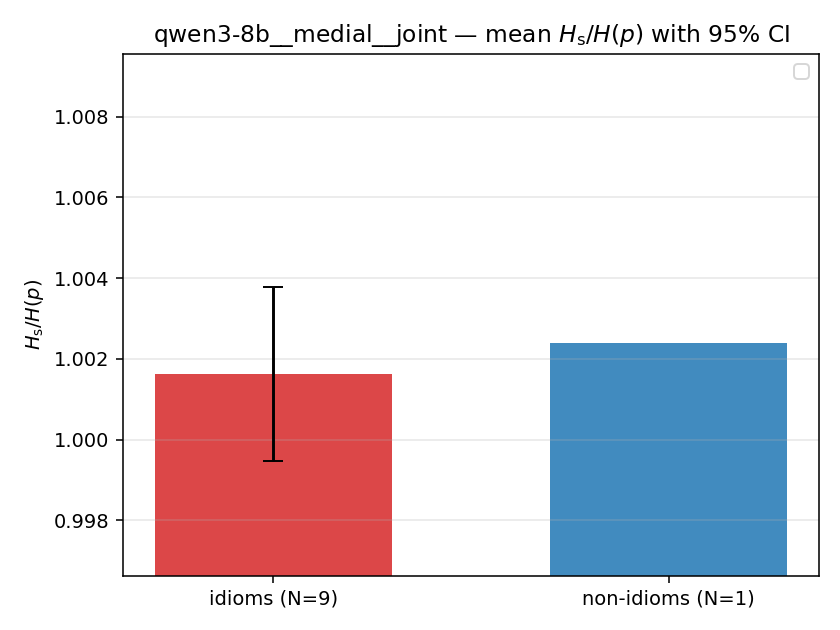 |
| per-idiom (sorted) | 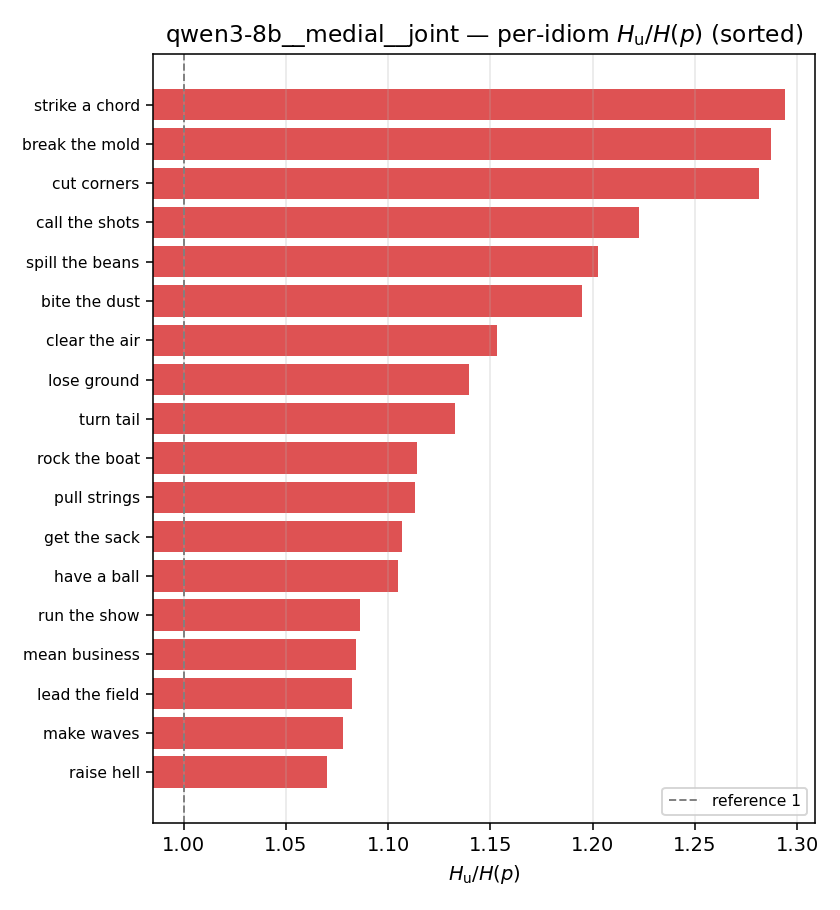 | 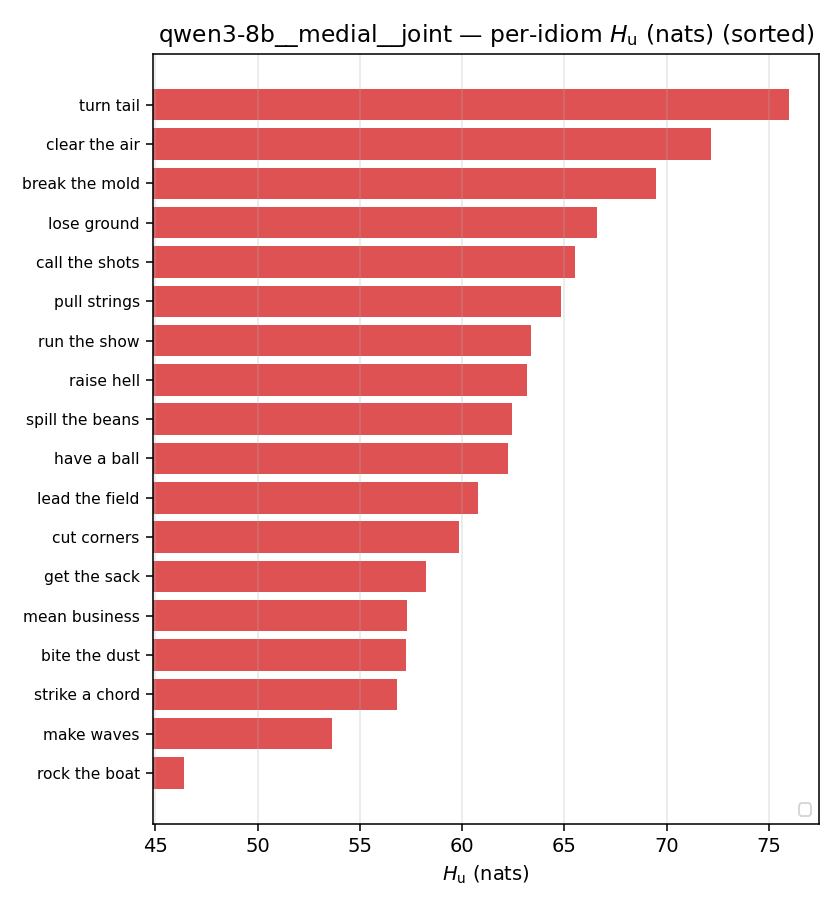 | 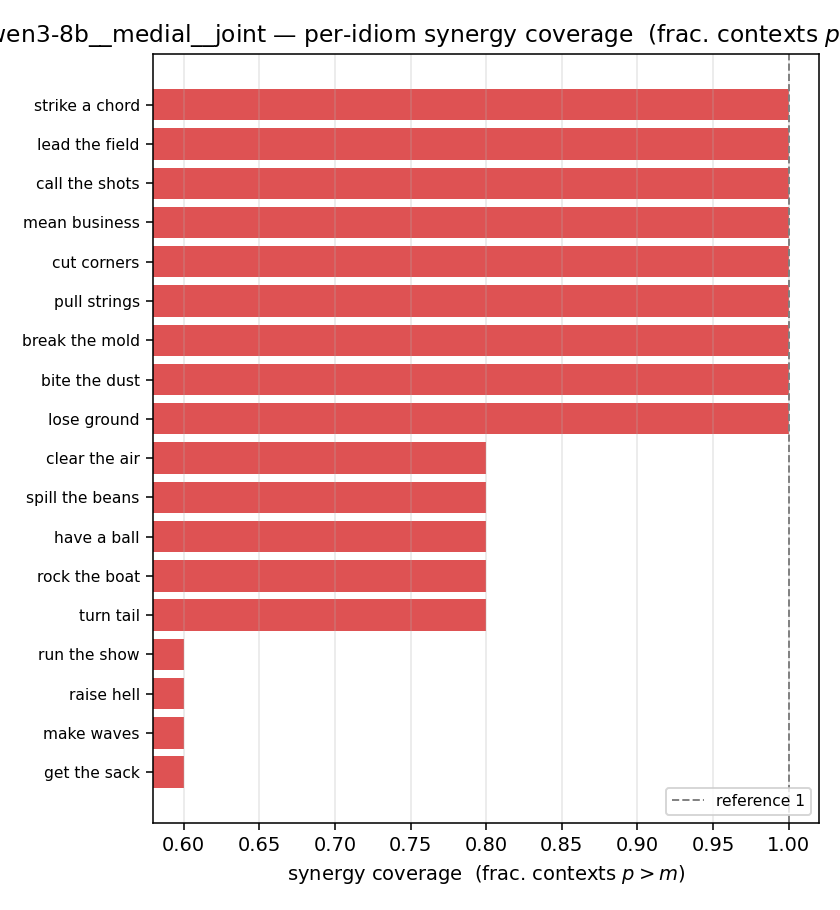 | 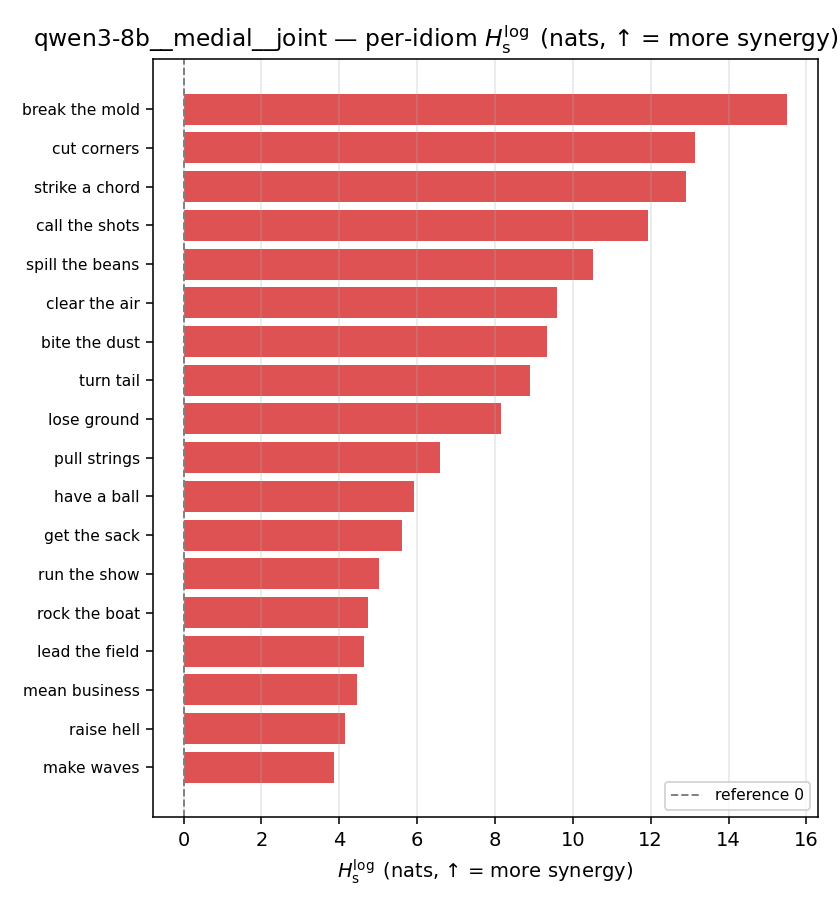 | 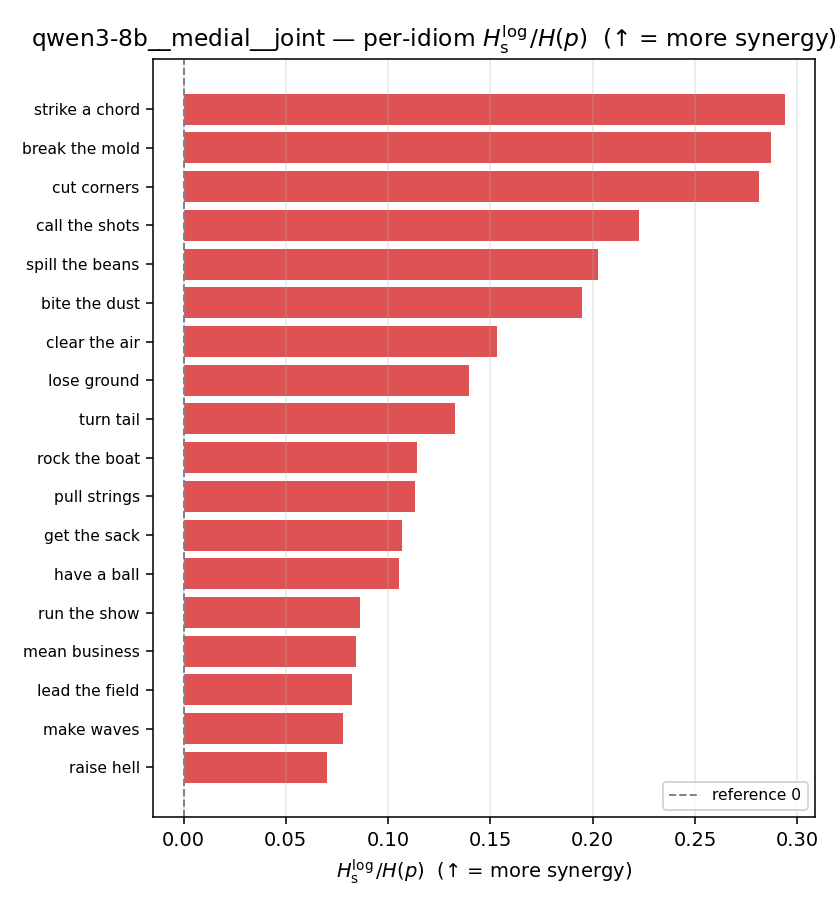 | 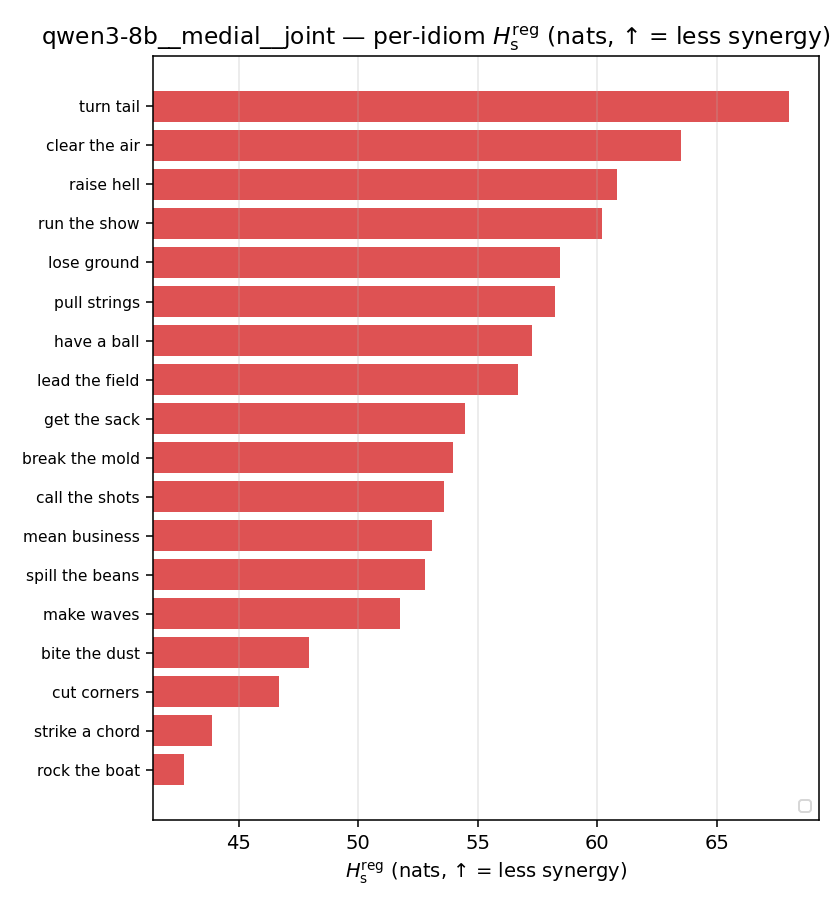 | 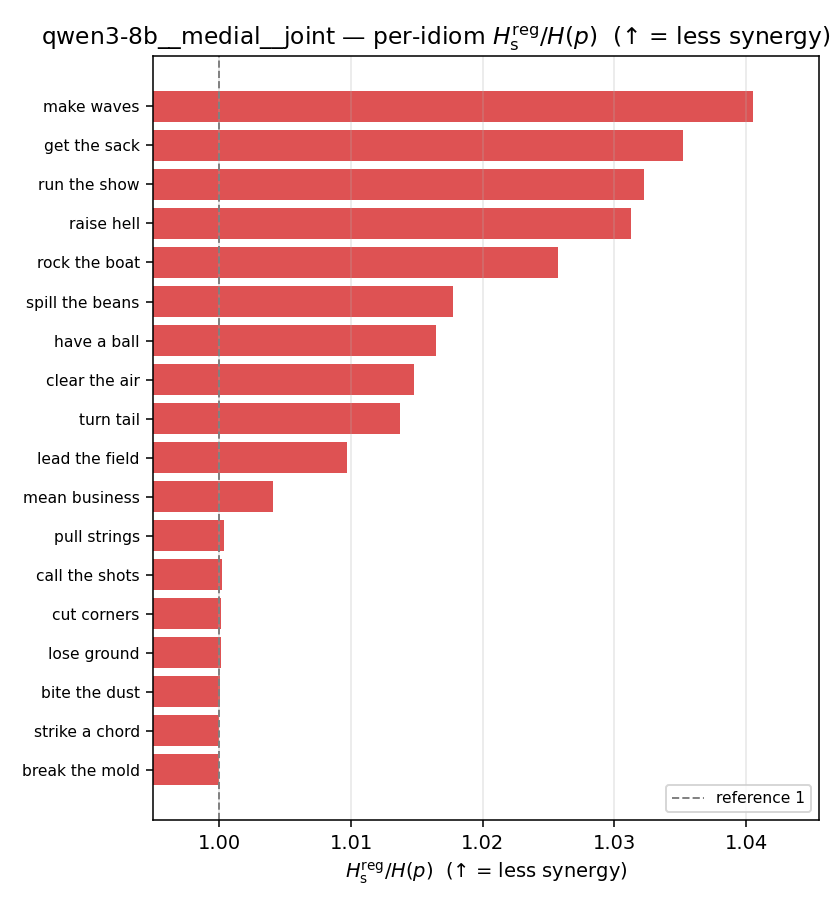 | 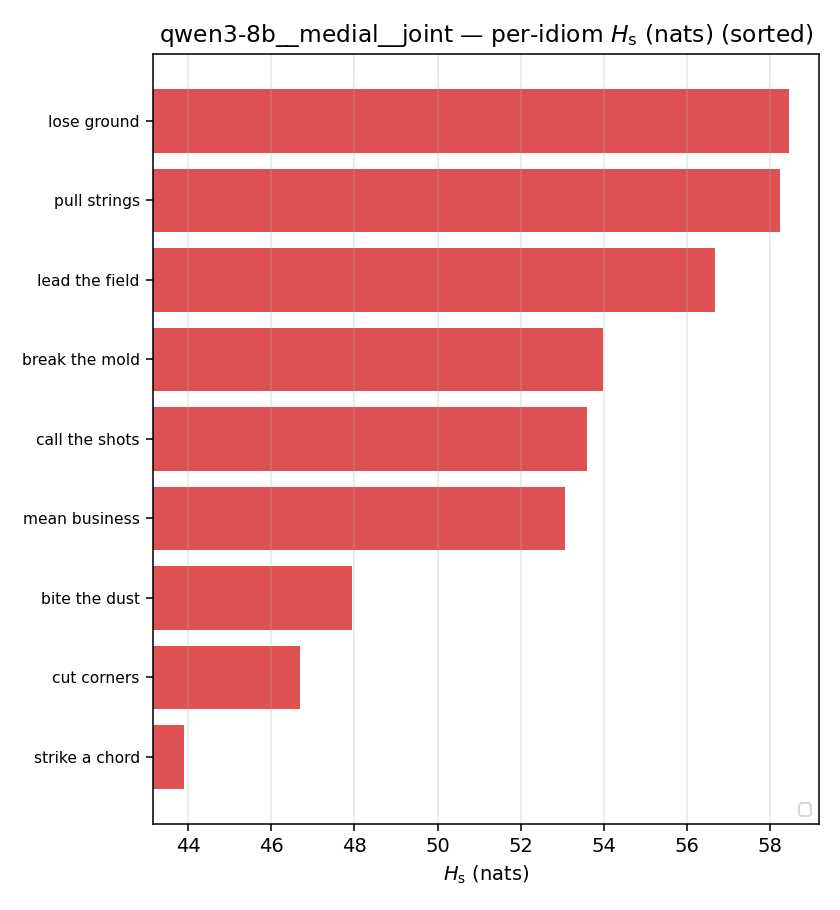 | 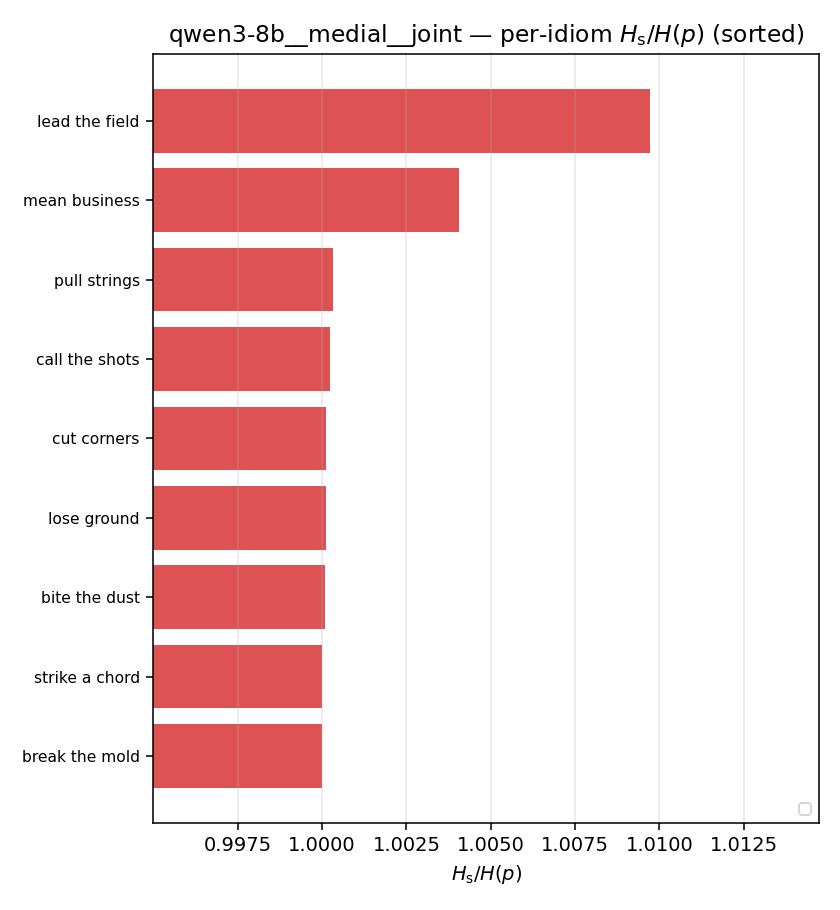 |
qwen3-8b · full · geo qwen3-8b__full__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 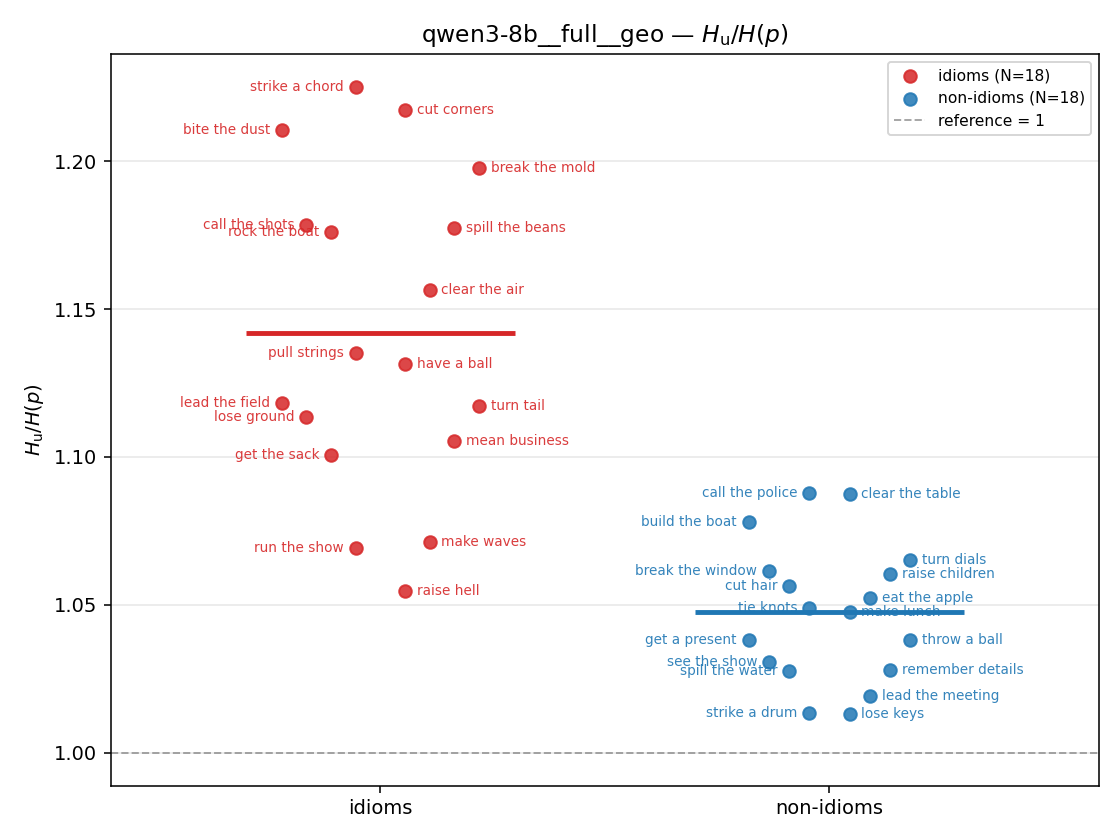 | 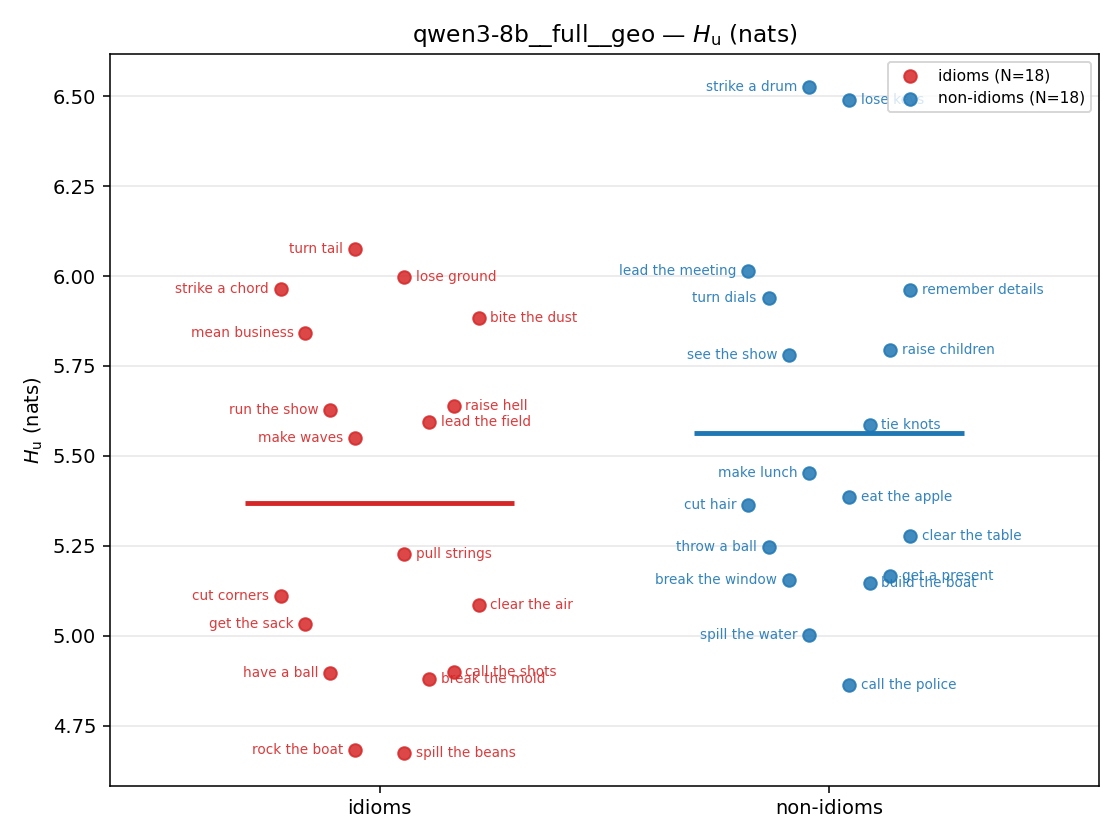 | 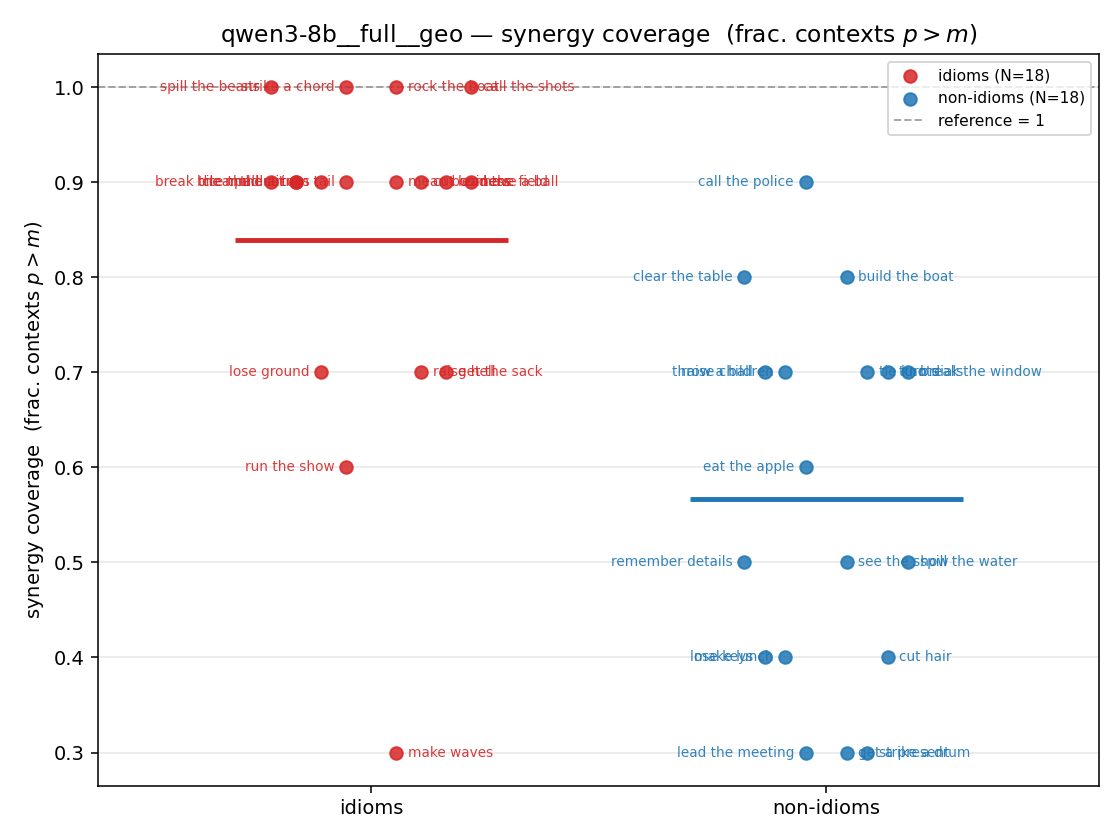 | 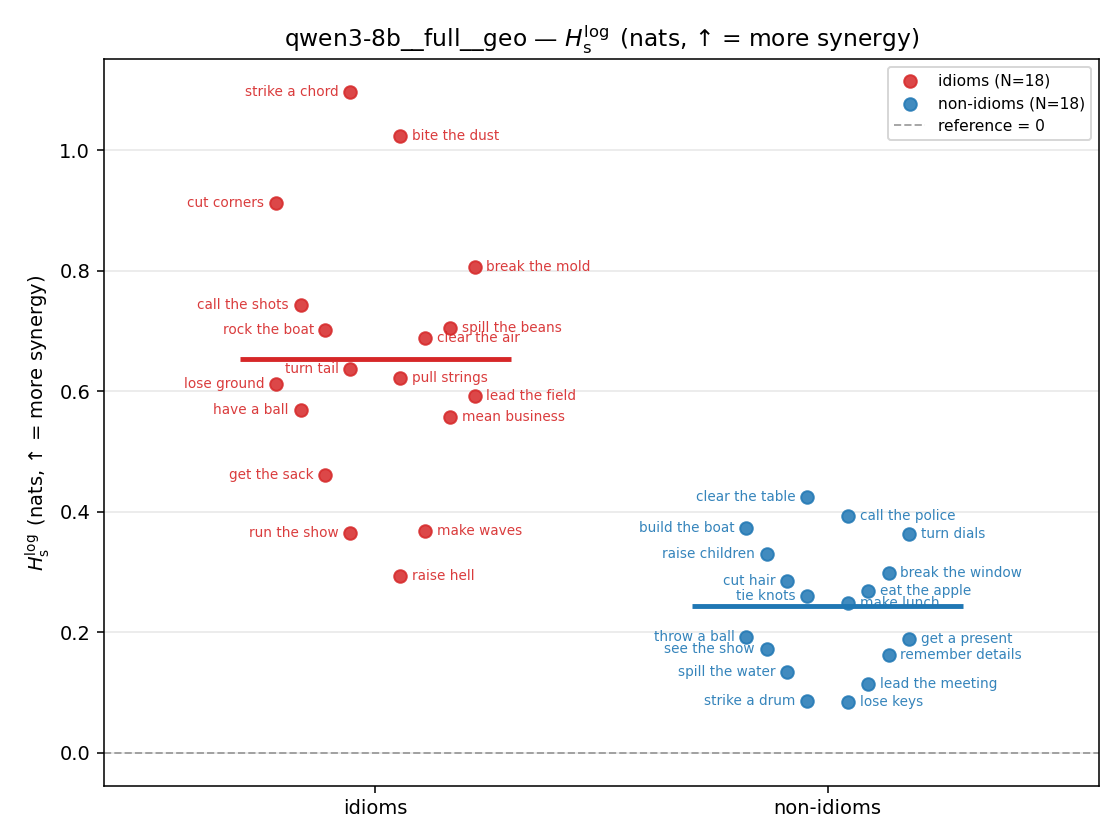 | 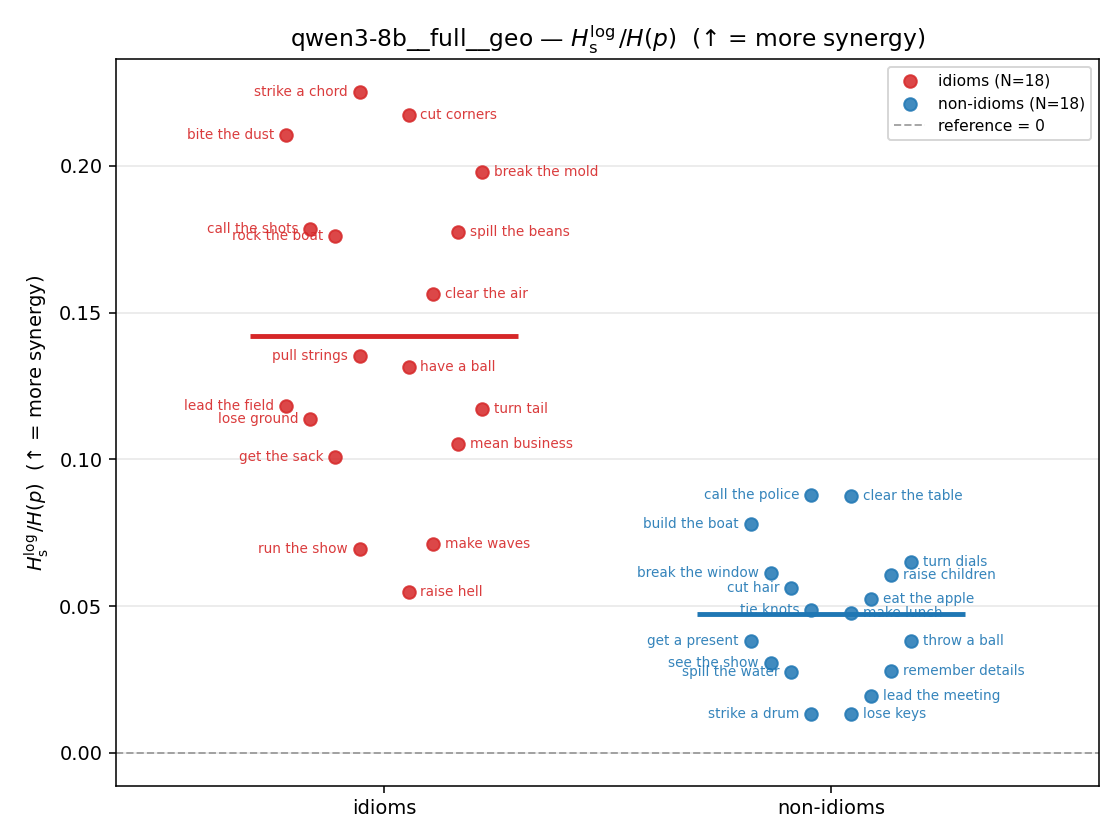 | 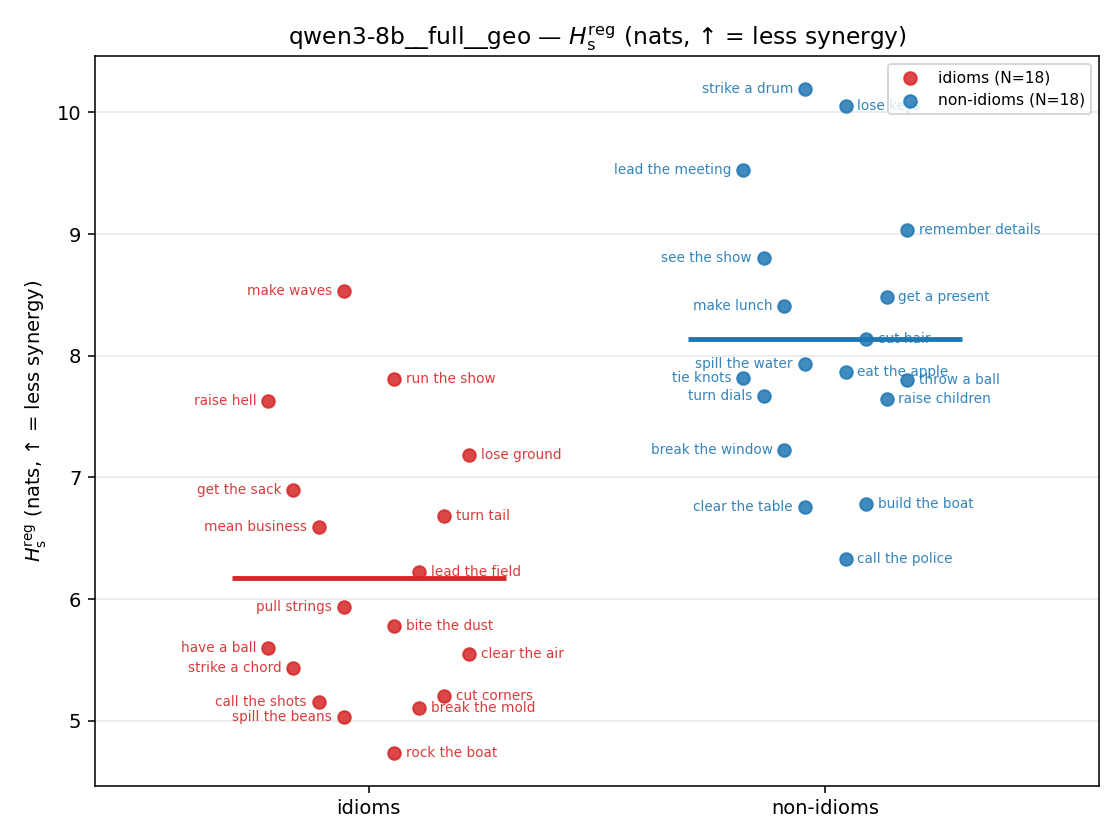 | 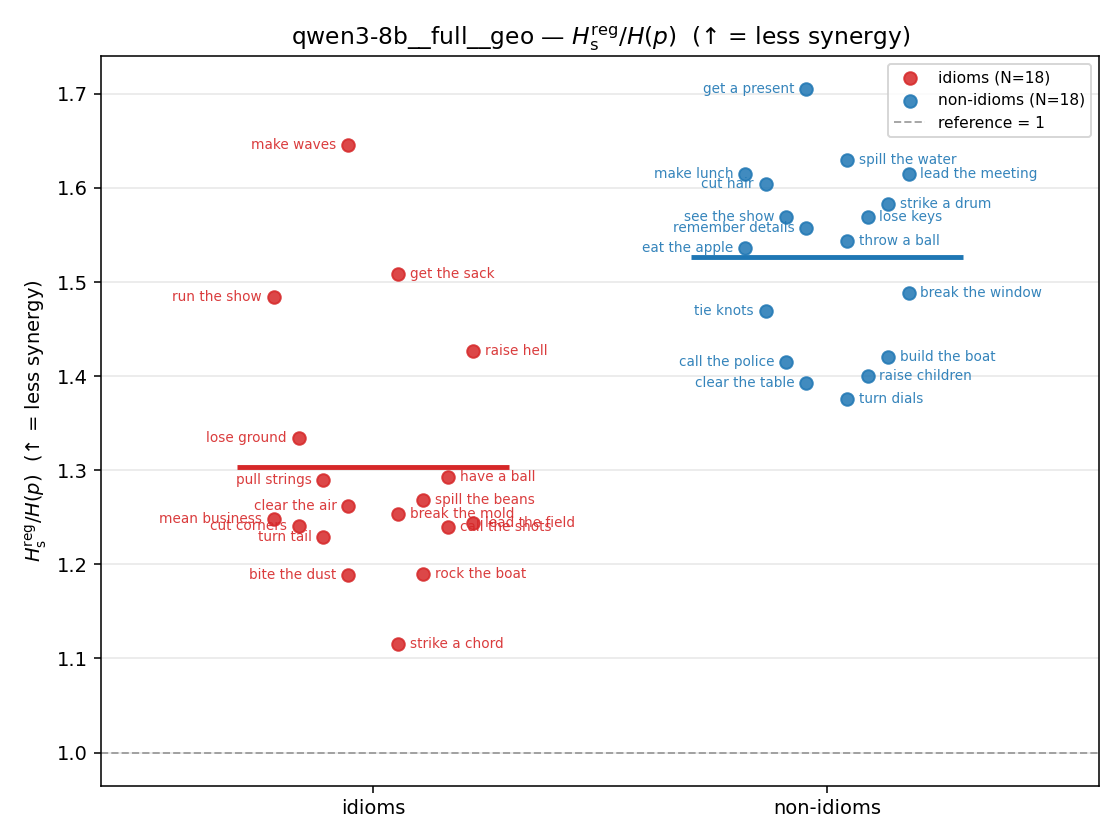 | — (no finite values) | — (no finite values) |
| mean ± 95% CI | 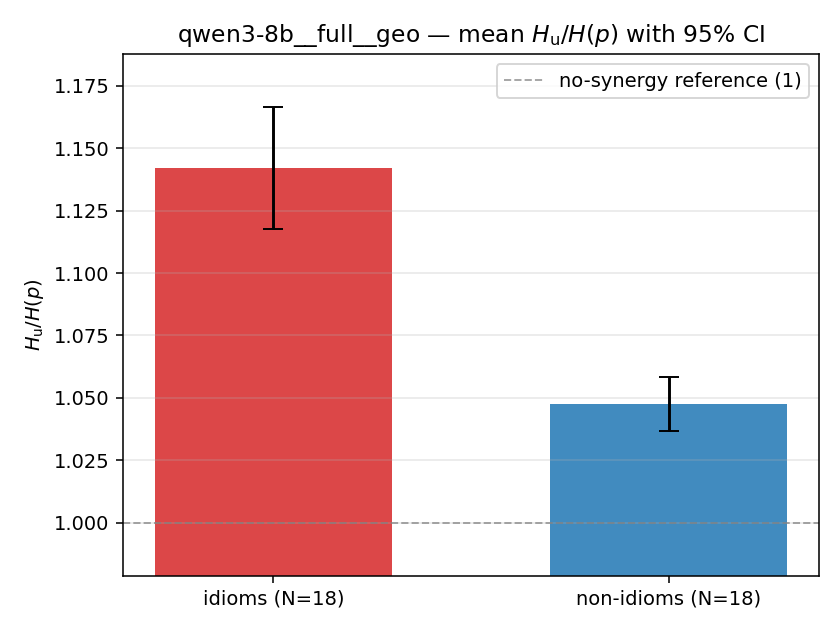 | 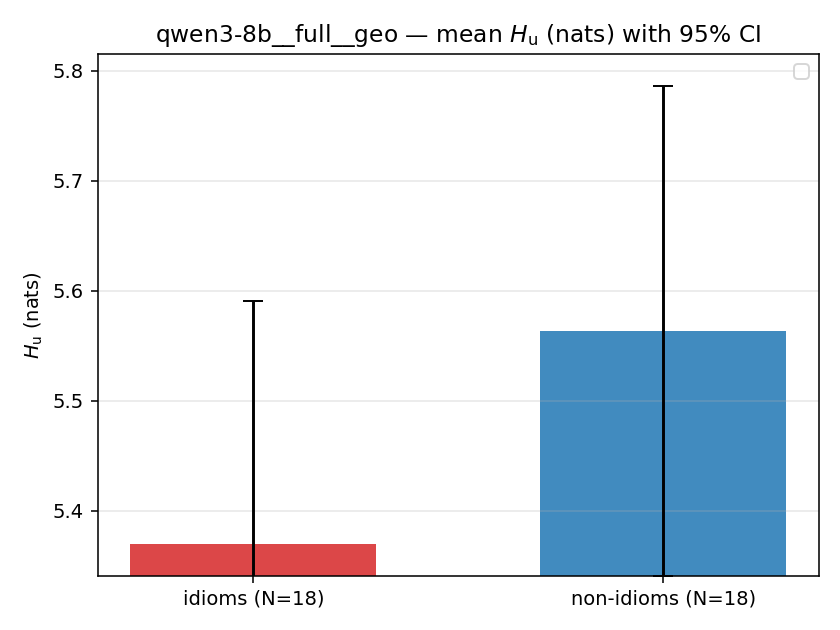 | 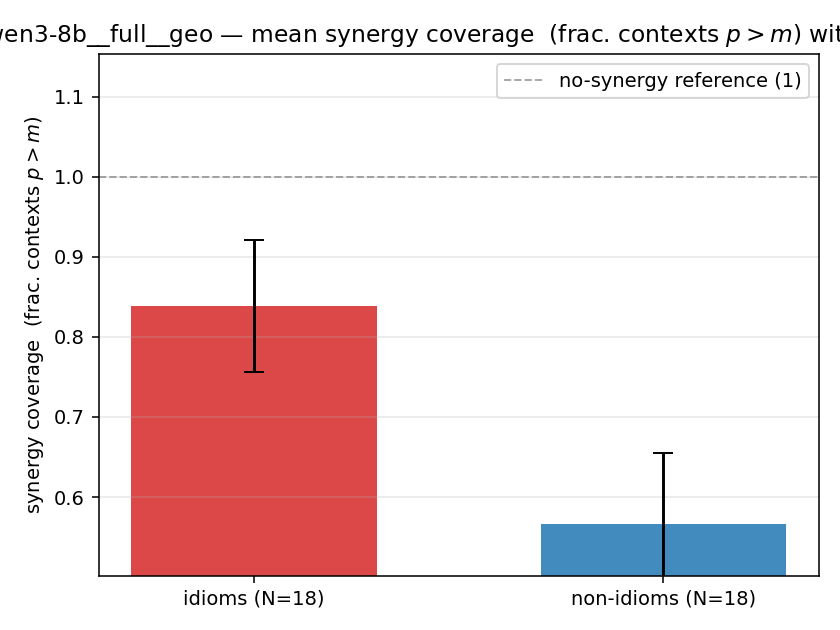 | 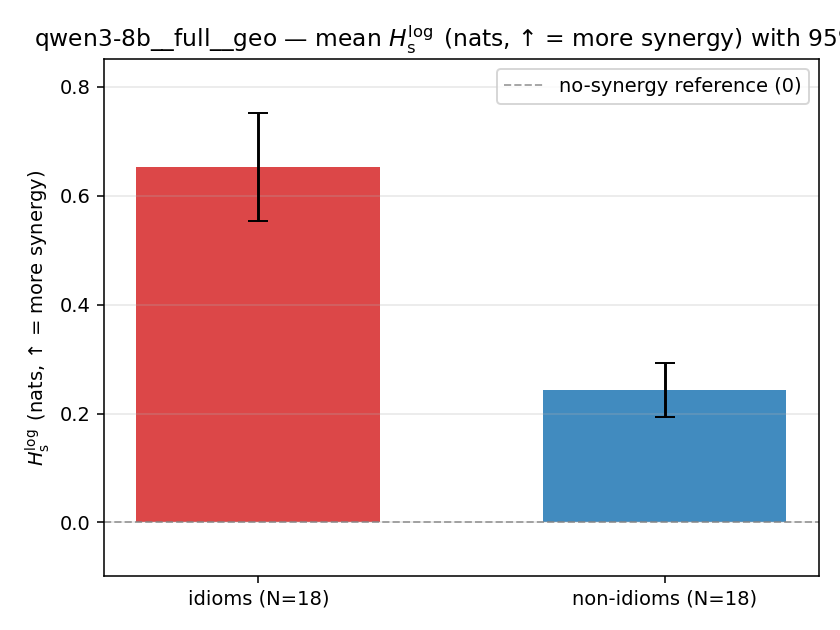 | 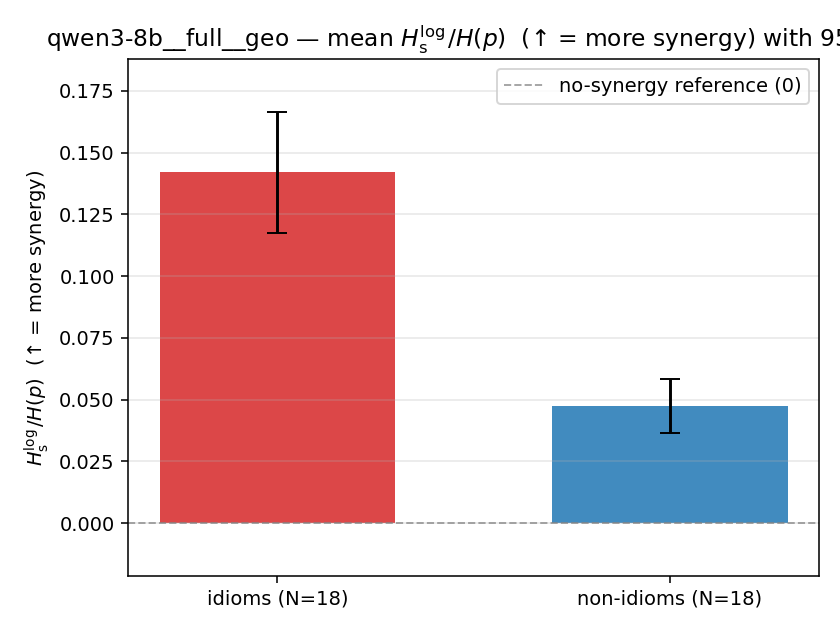 | 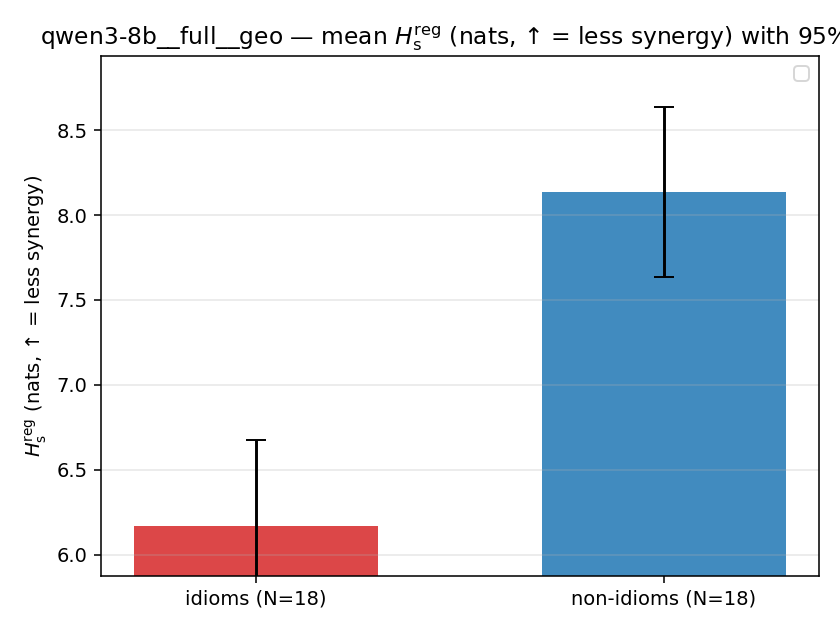 | 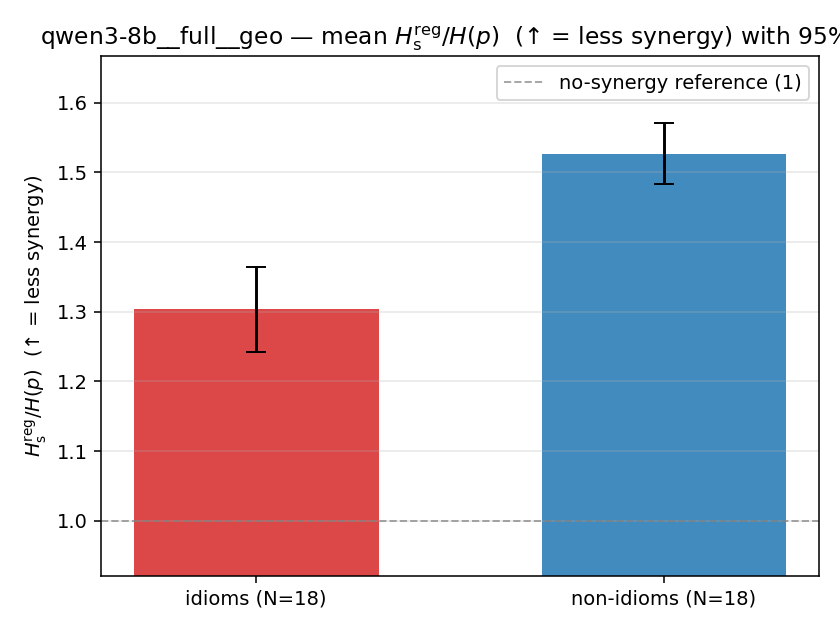 | — (no finite values) | — (no finite values) |
| per-idiom (sorted) | 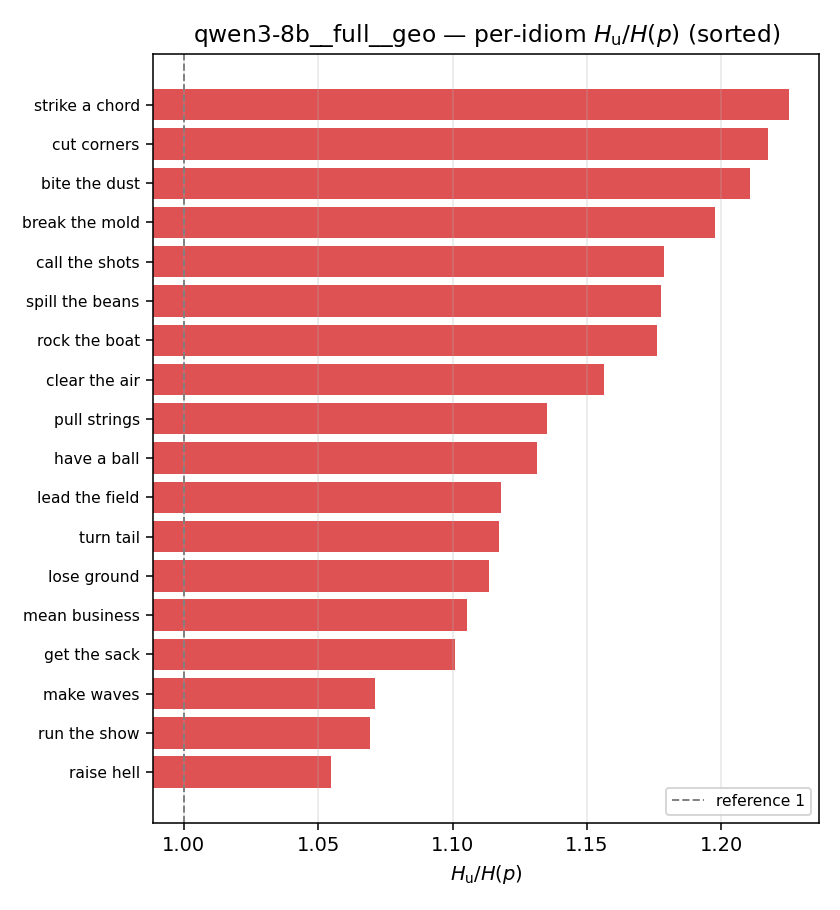 | 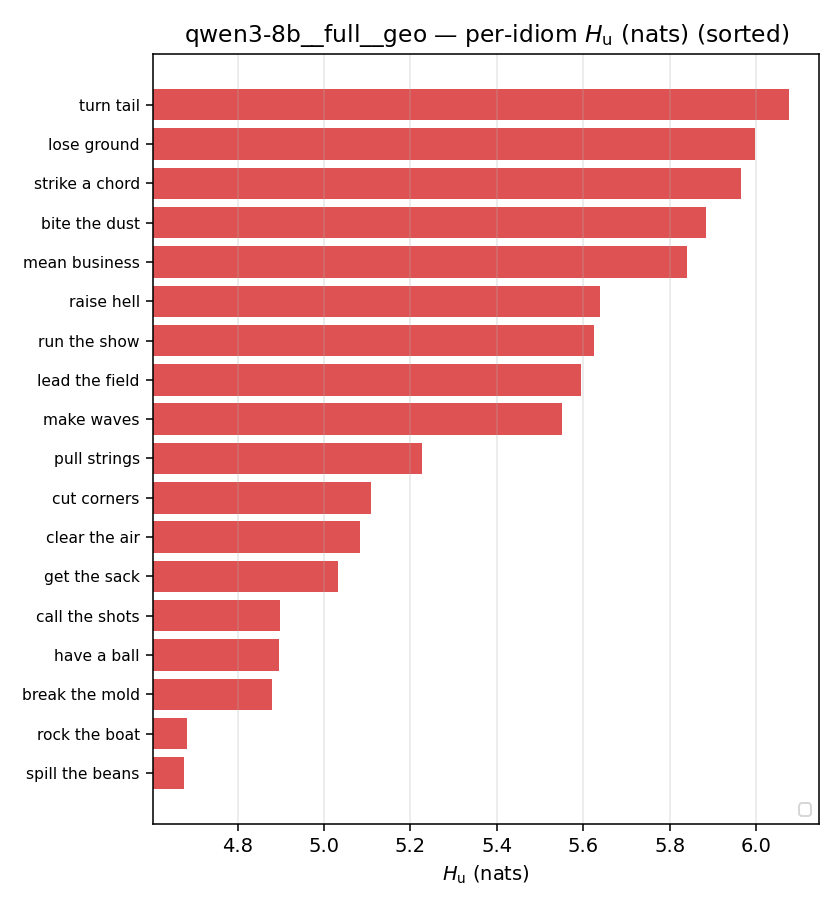 | 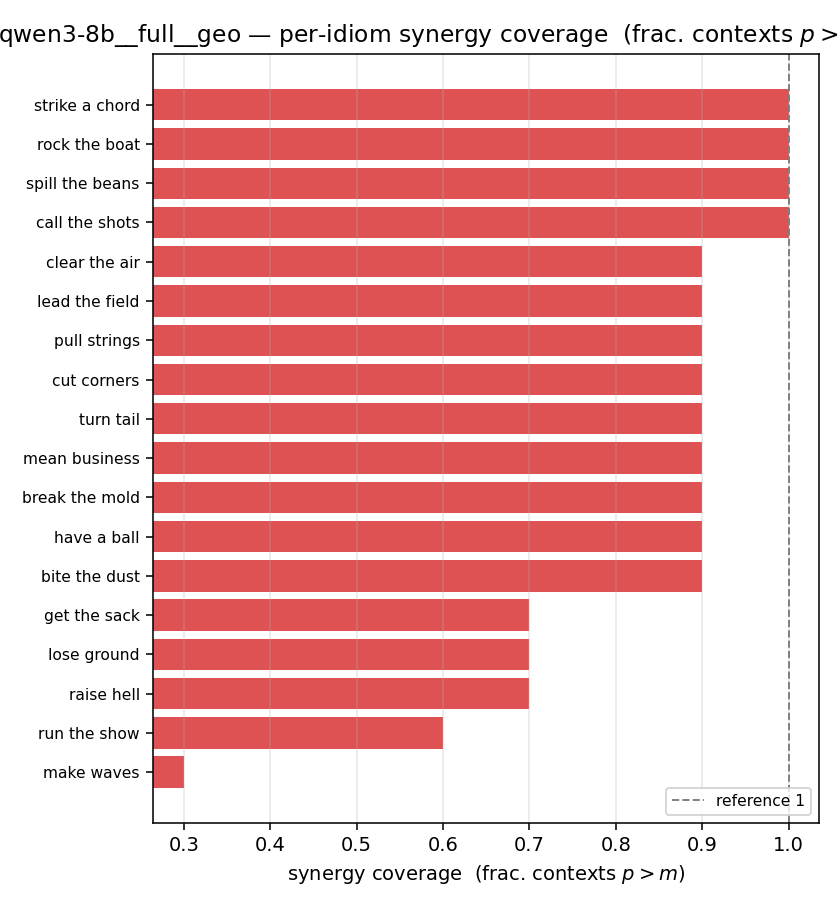 | 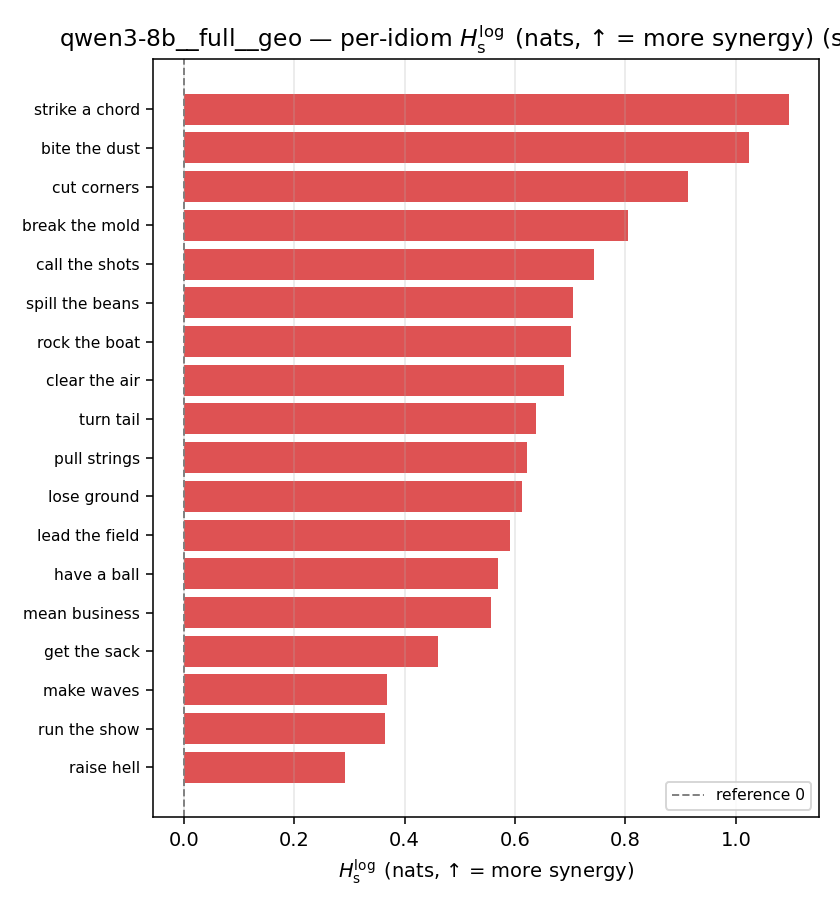 | 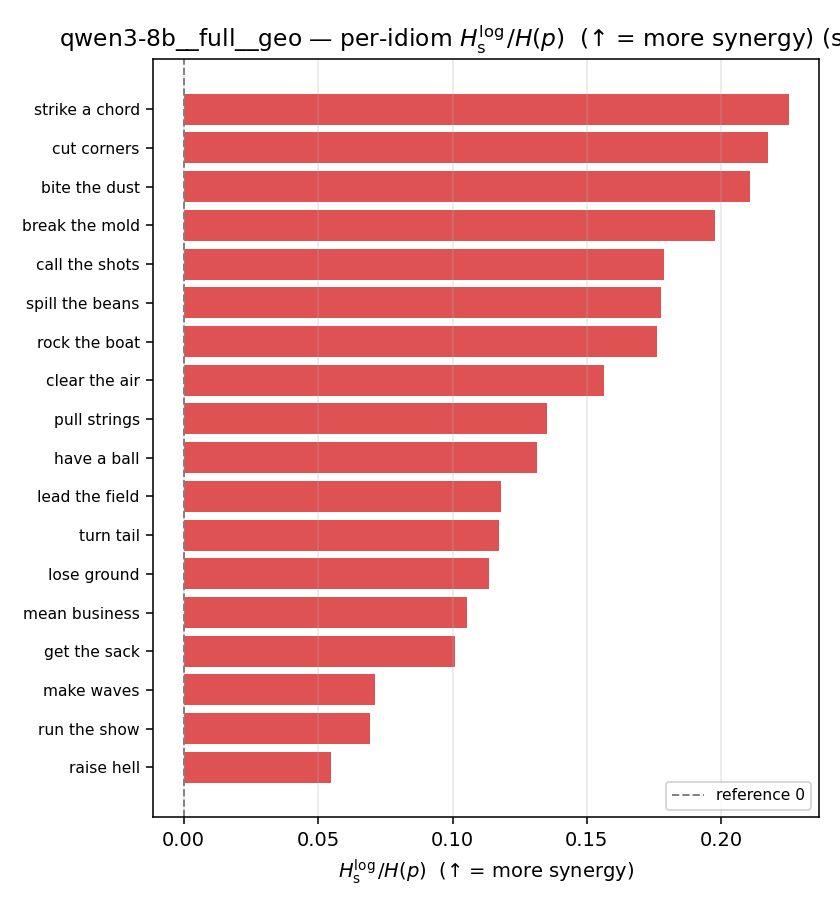 | 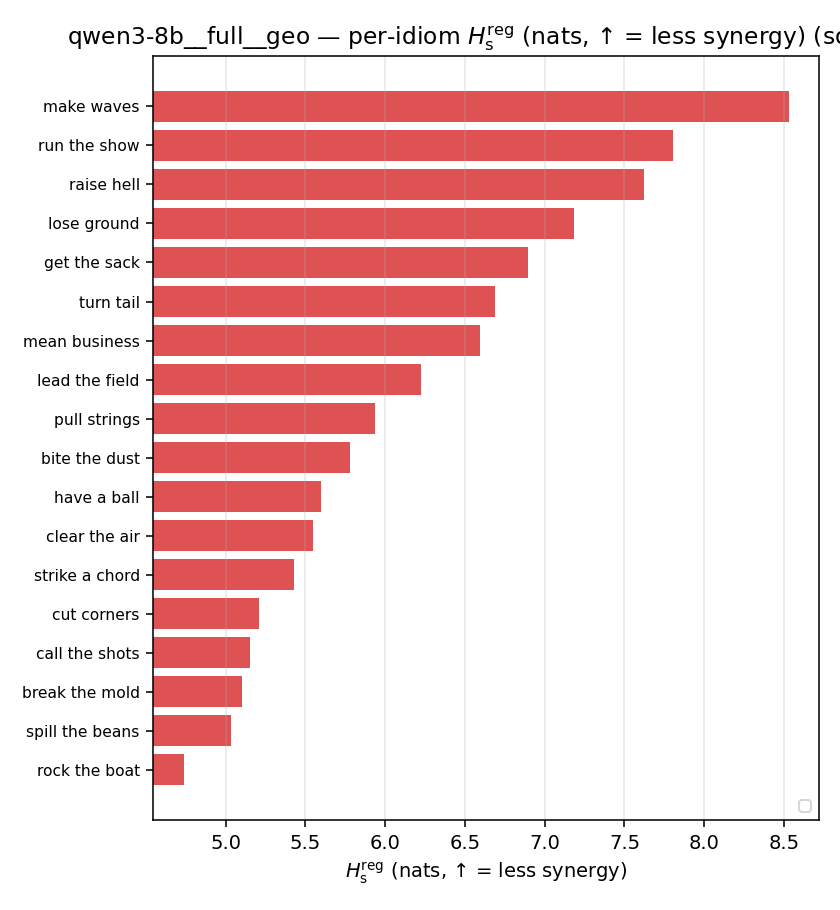 | 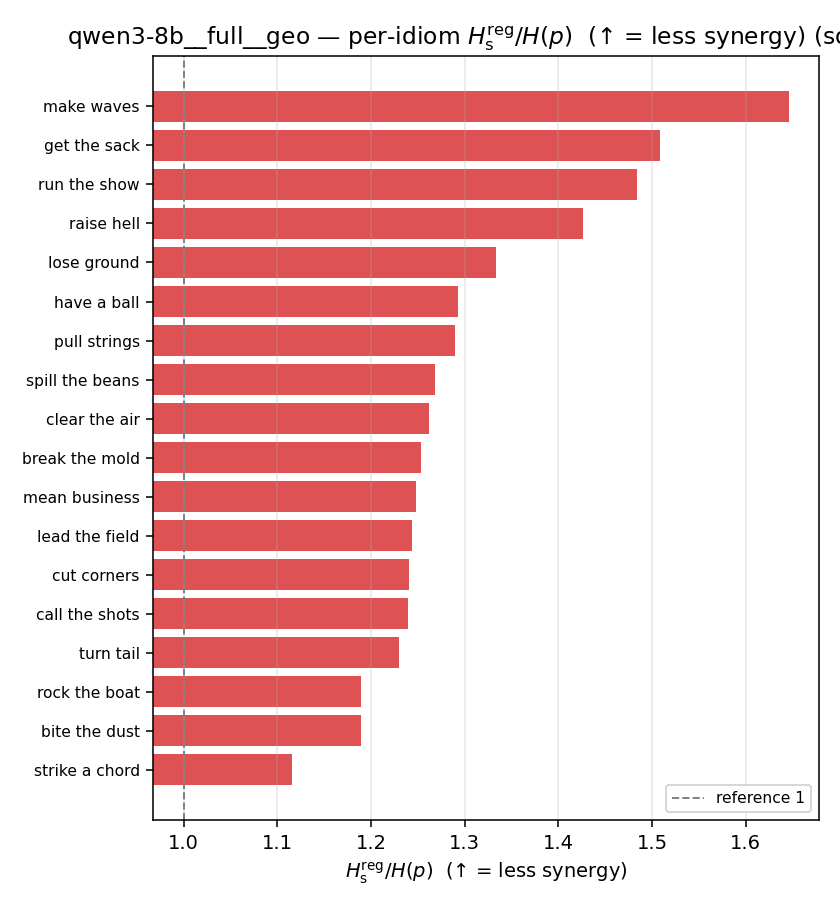 | — (no finite values) | — (no finite values) |
qwen3-8b · full · joint qwen3-8b__full__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 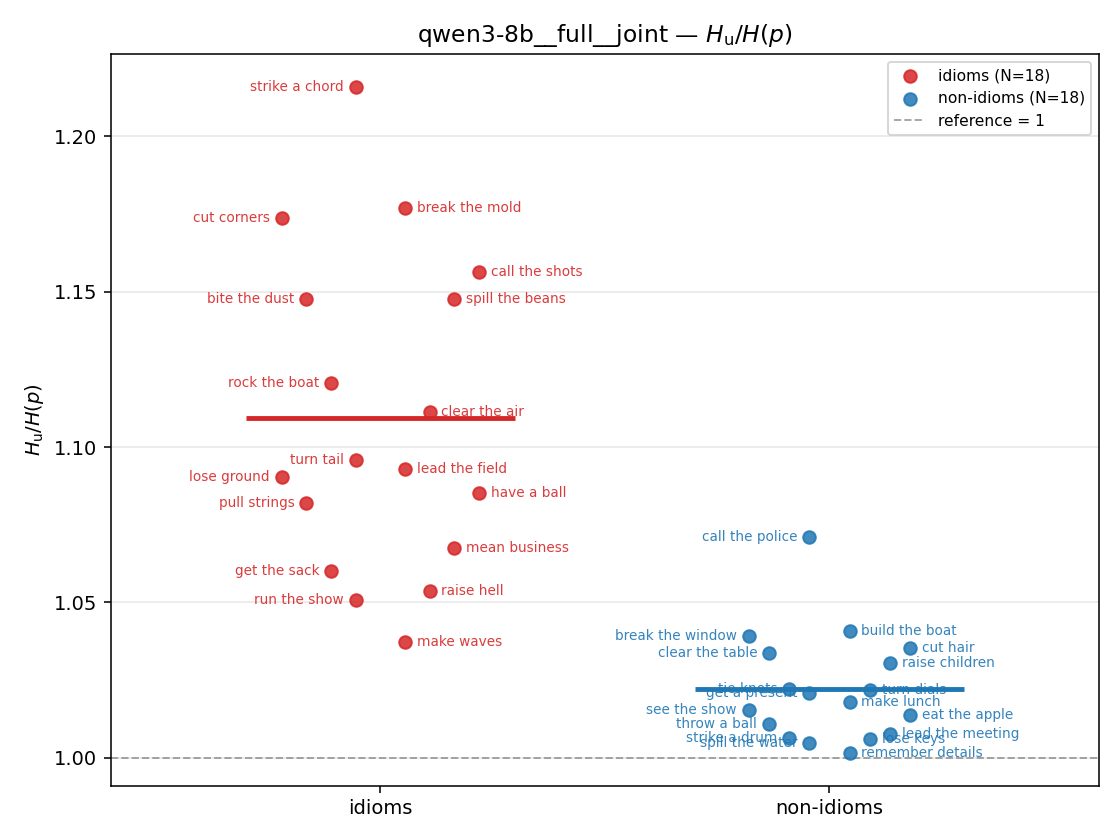 | 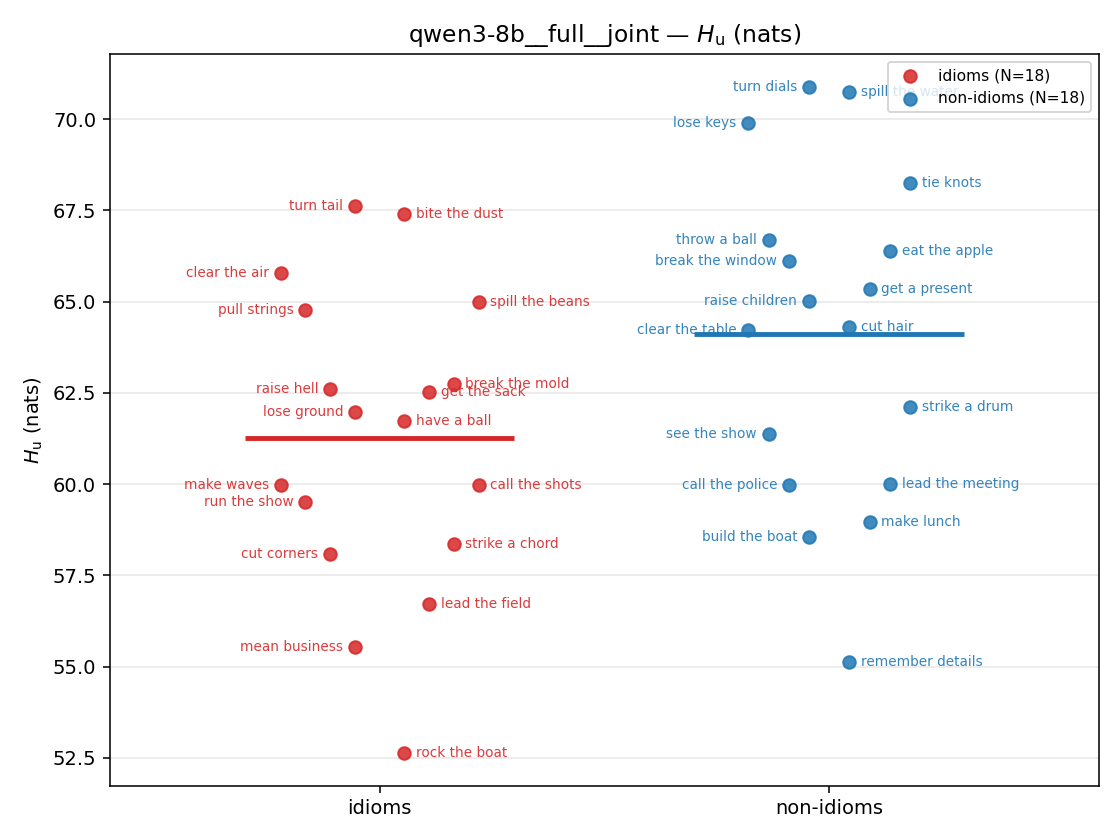 | 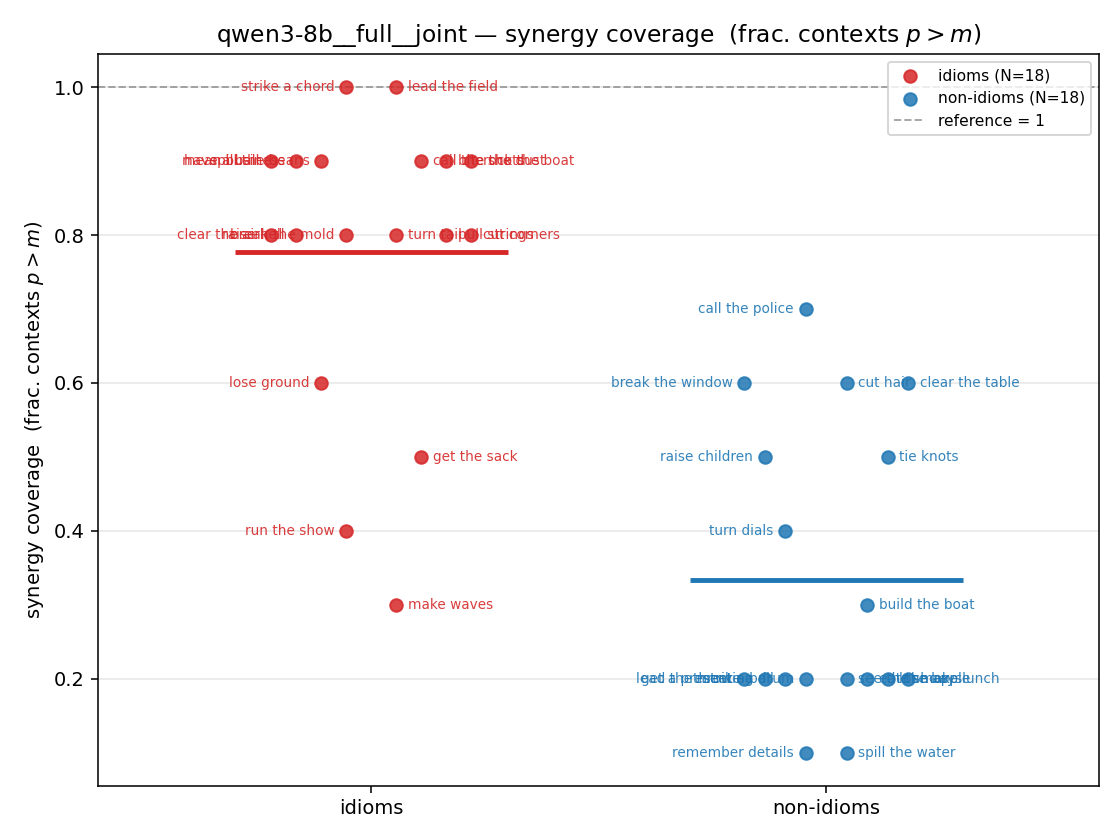 | 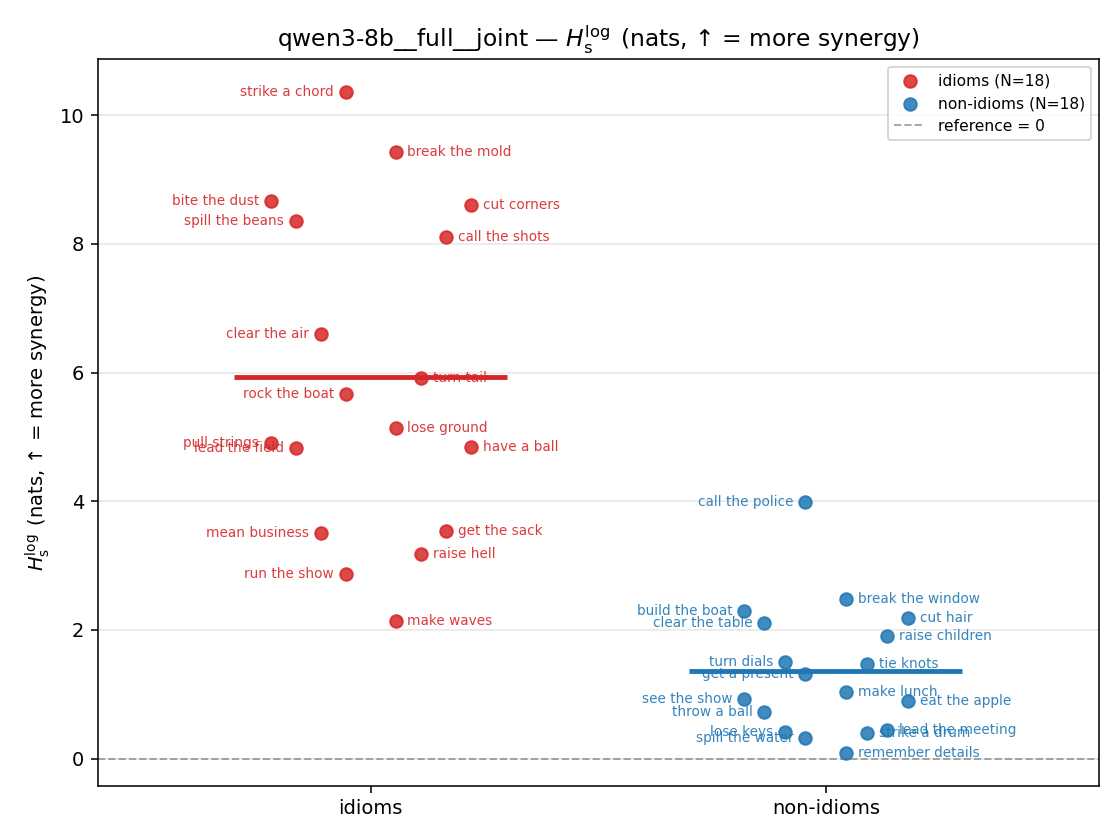 | 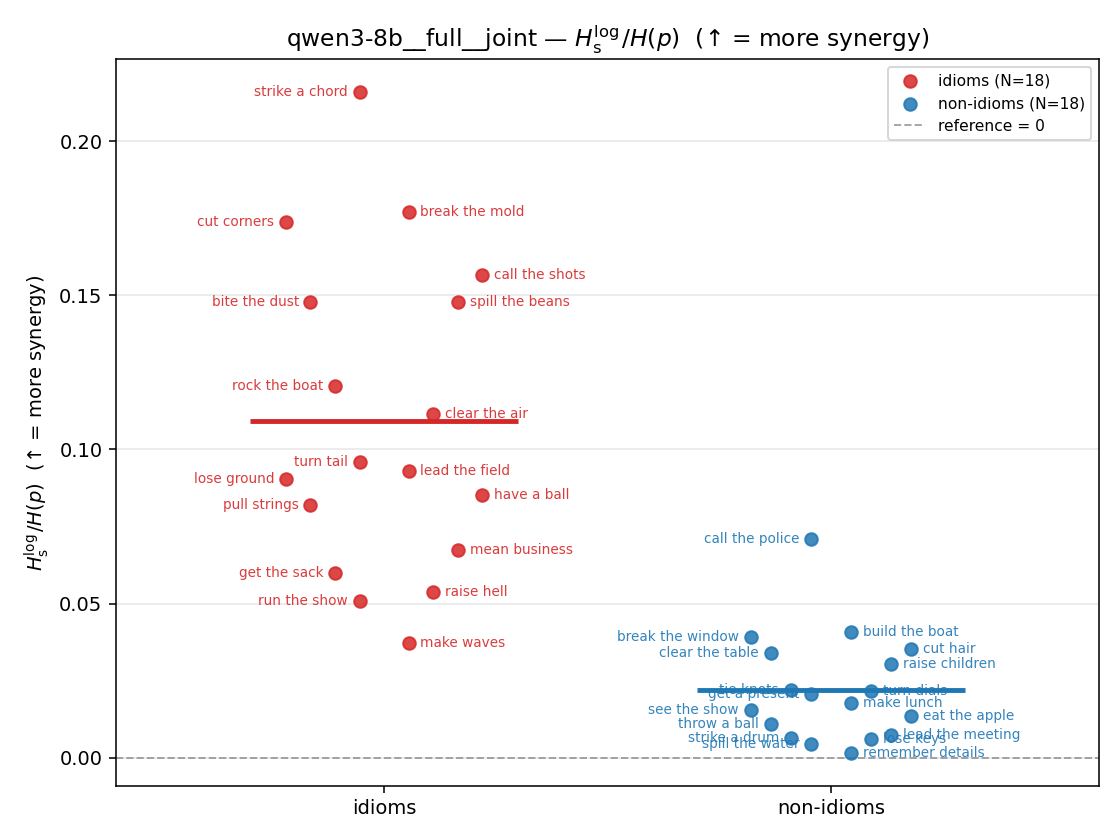 | 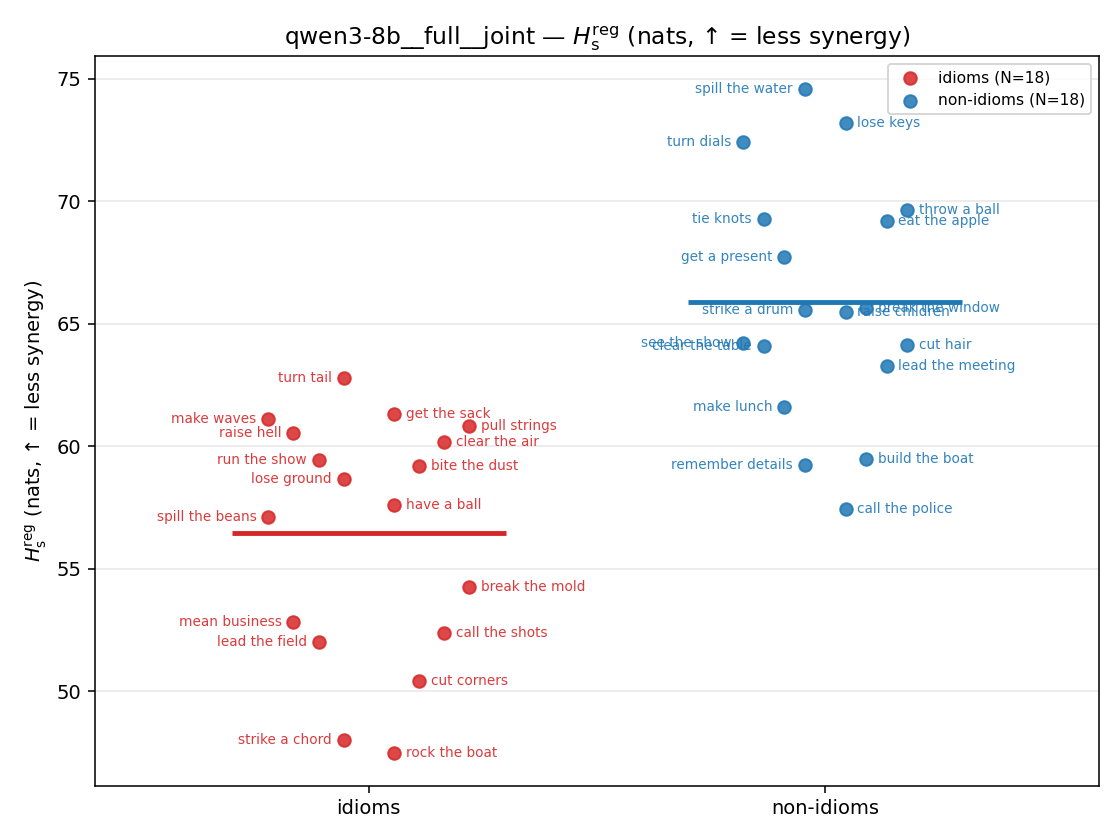 | 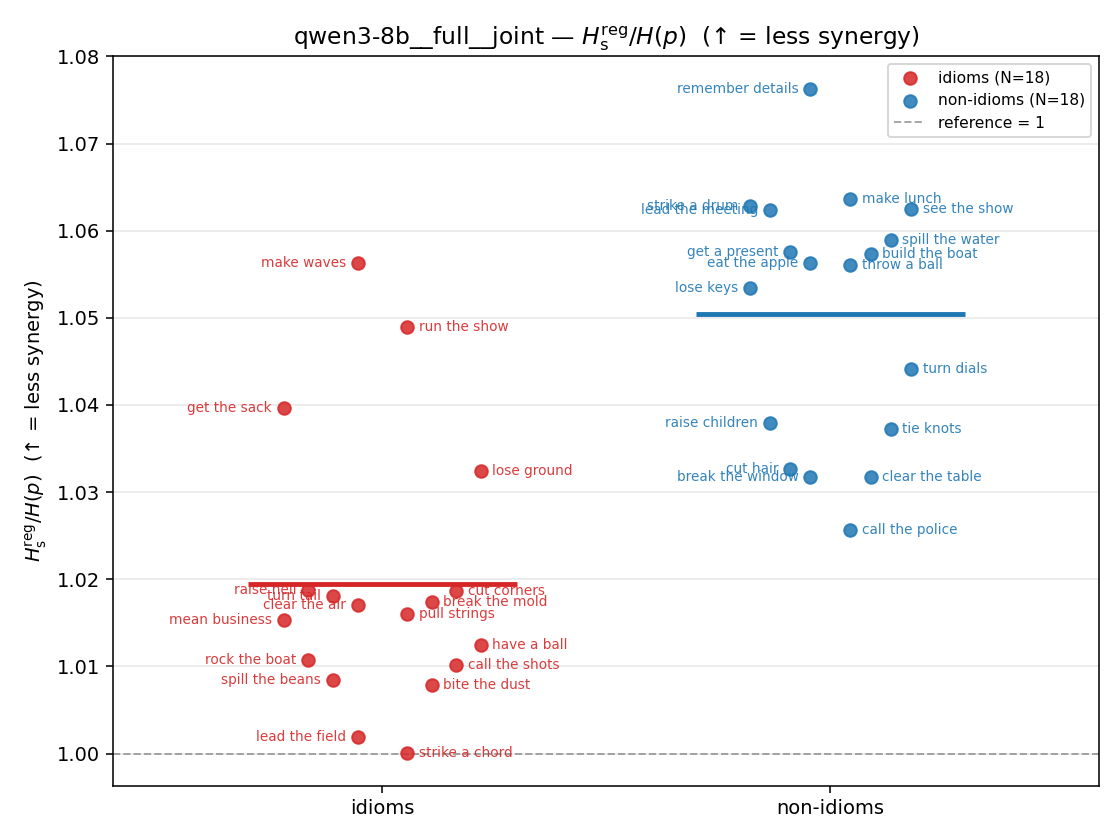 | — (no finite values) | — (no finite values) |
| mean ± 95% CI | 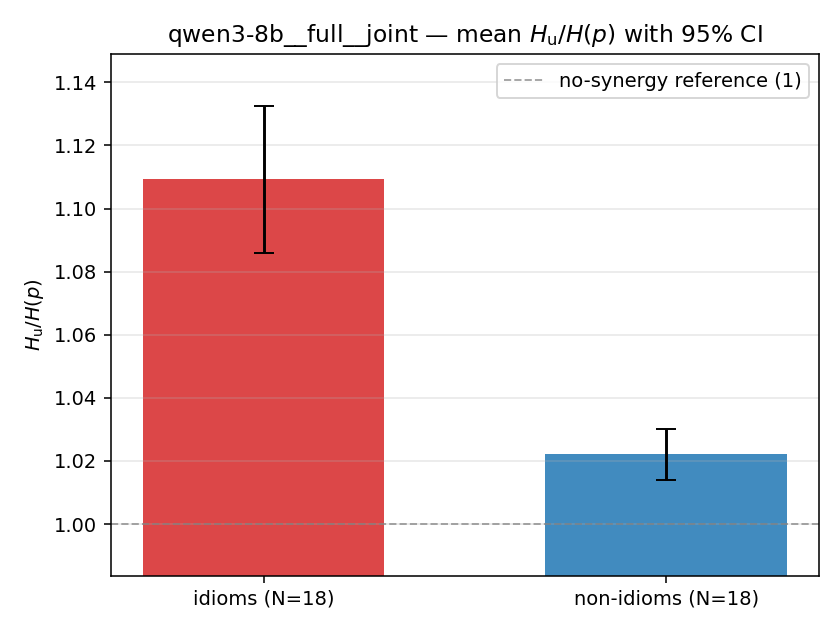 | 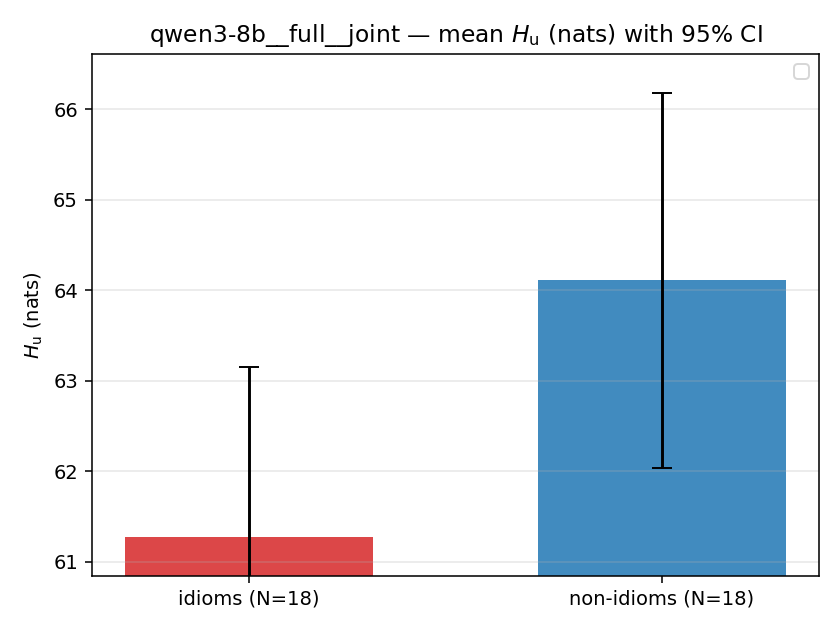 | 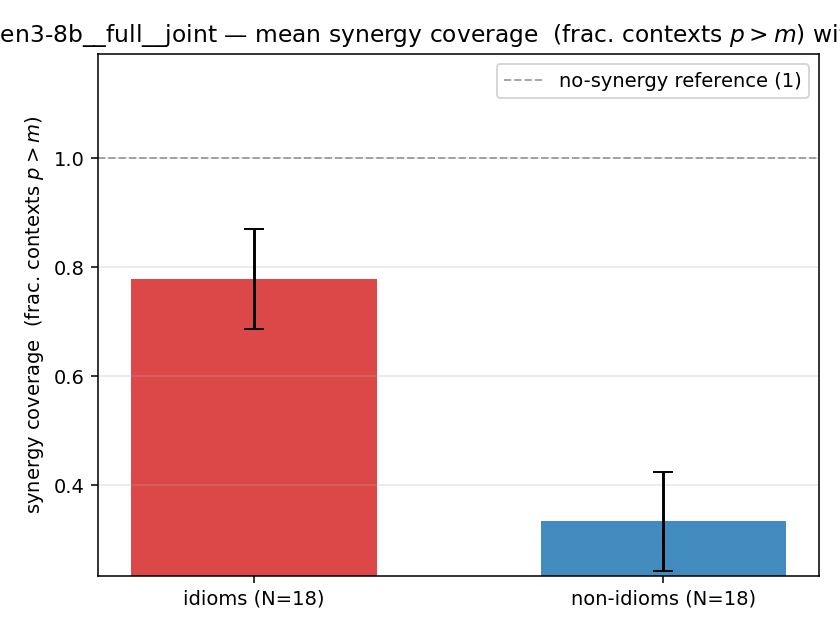 | 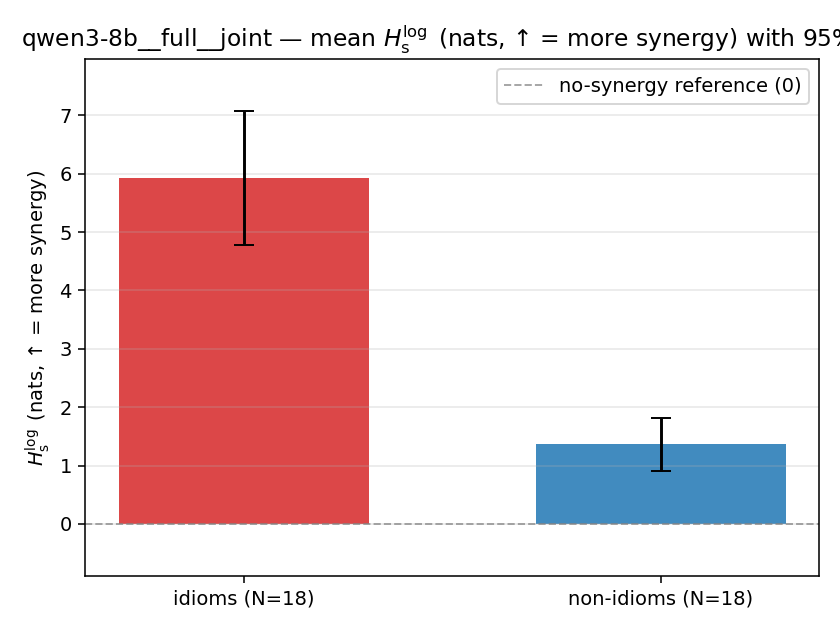 | 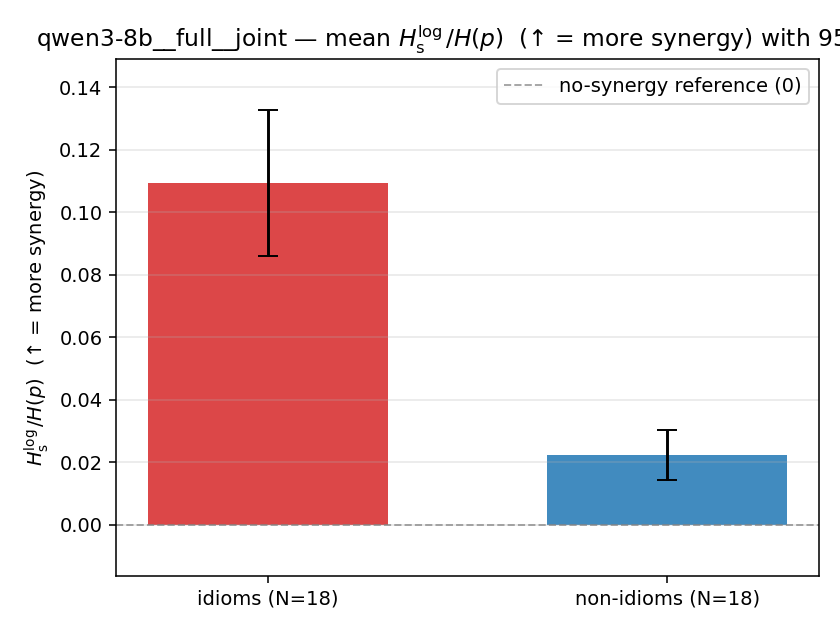 | 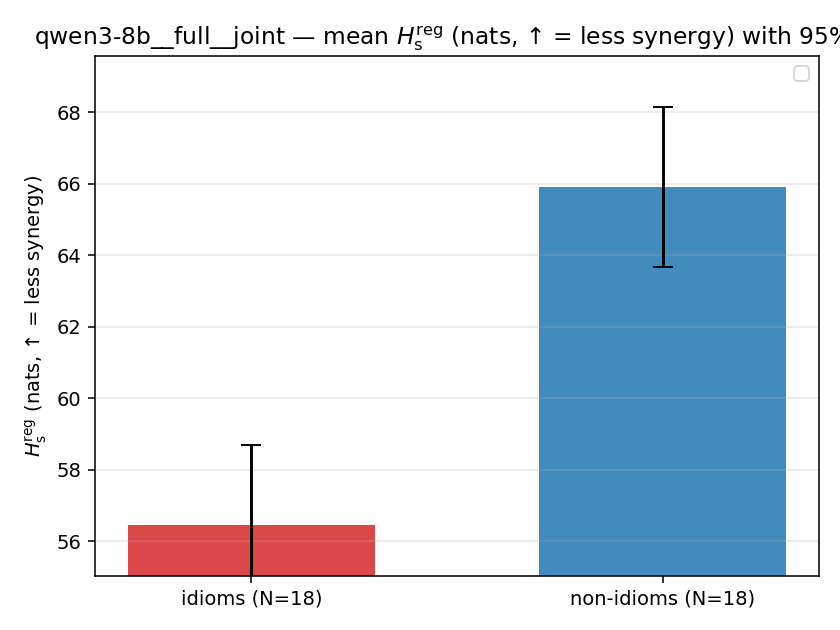 | 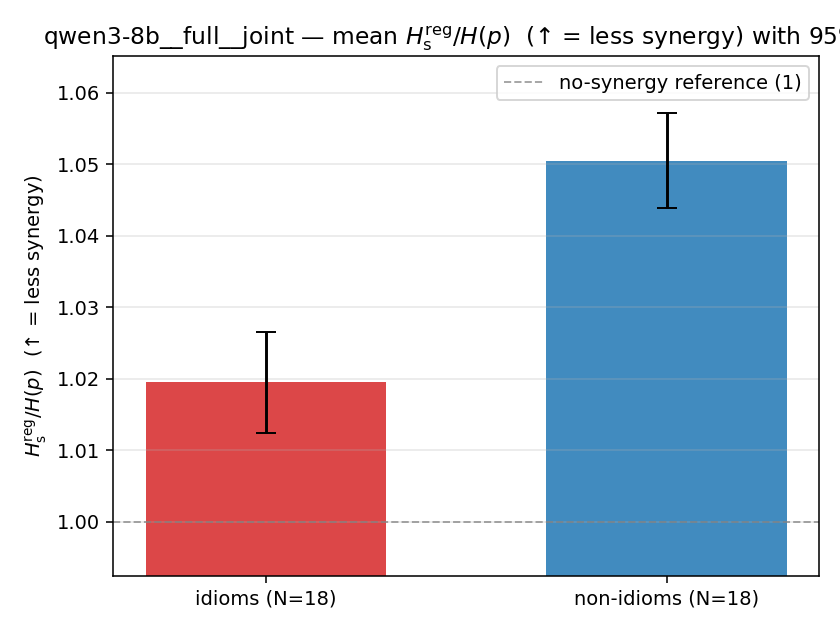 | — (no finite values) | — (no finite values) |
| per-idiom (sorted) | 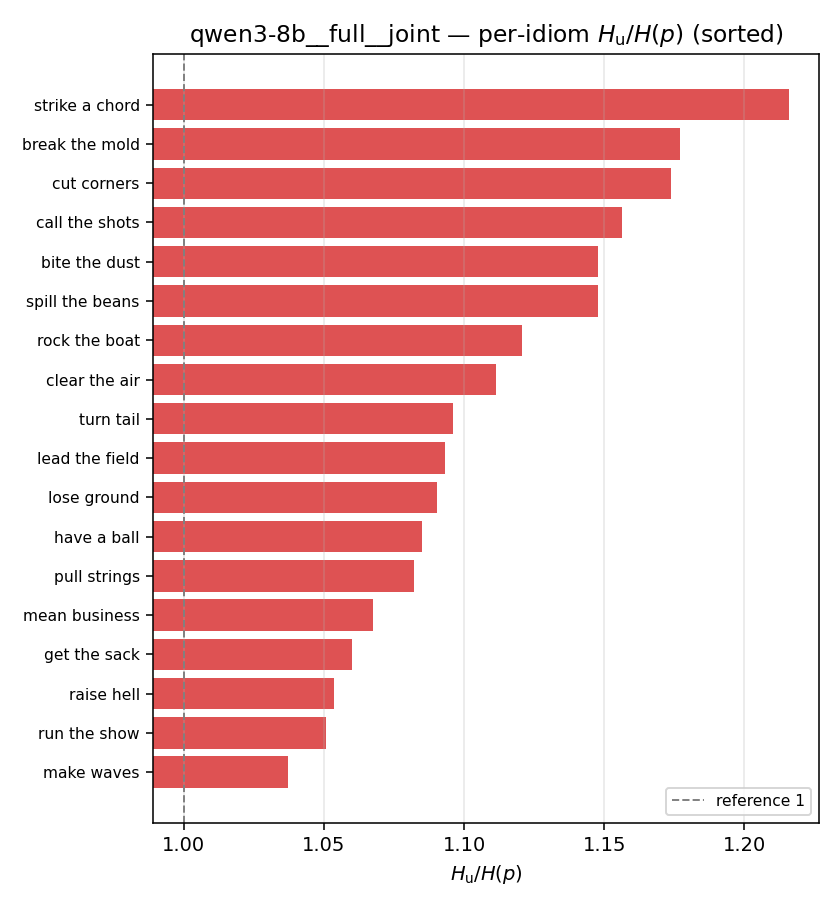 | 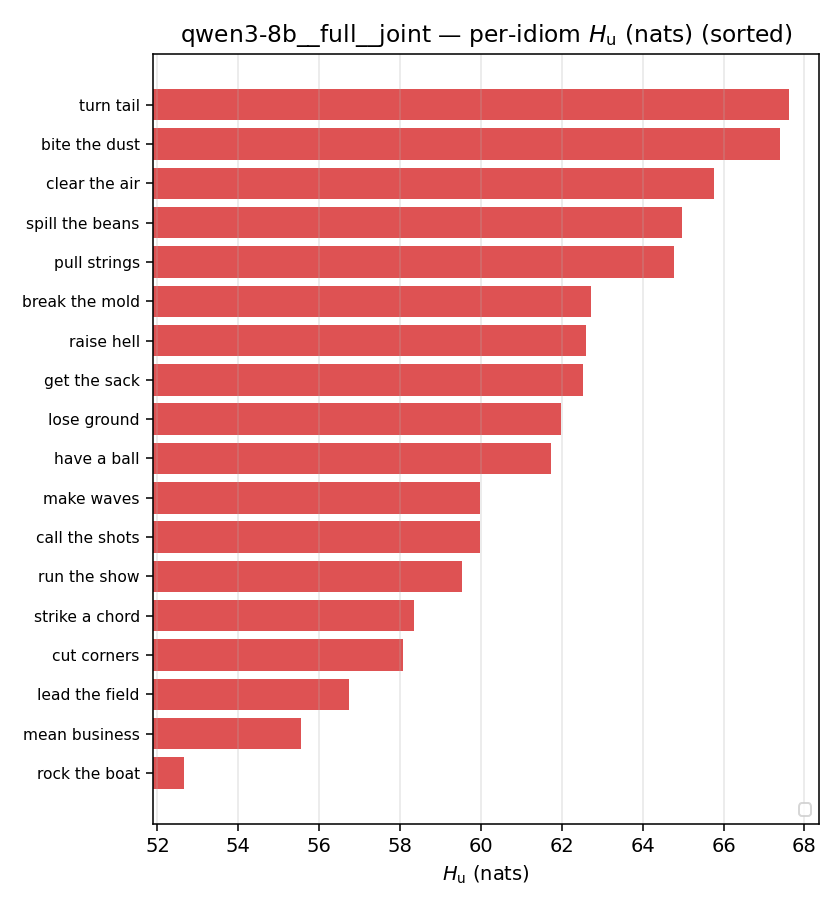 | 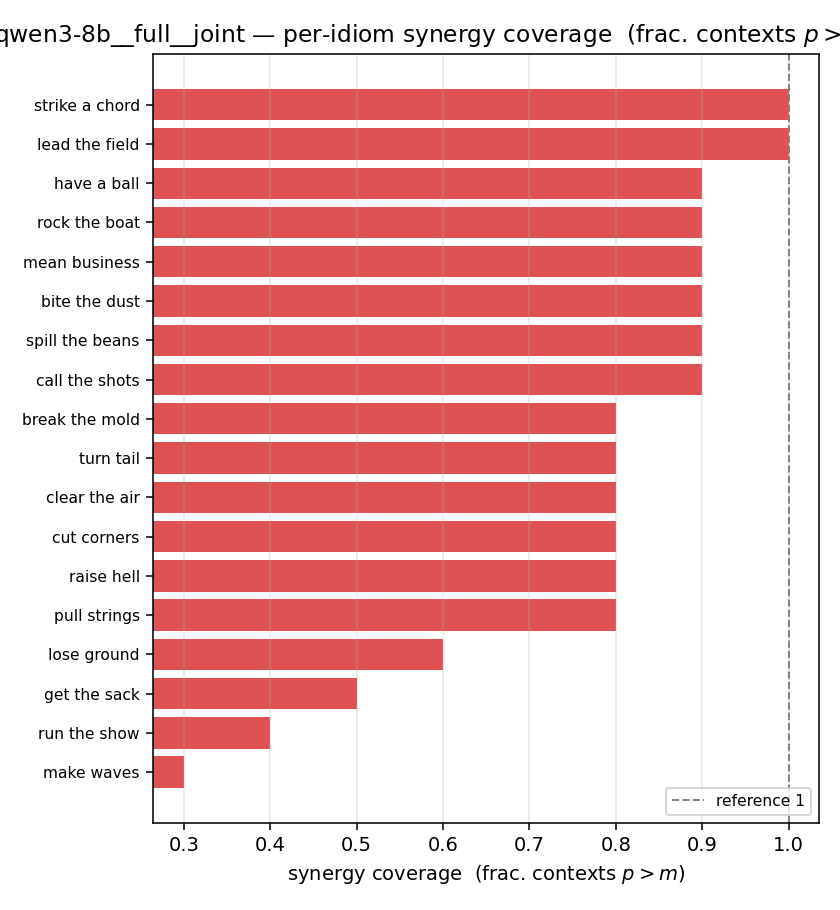 | 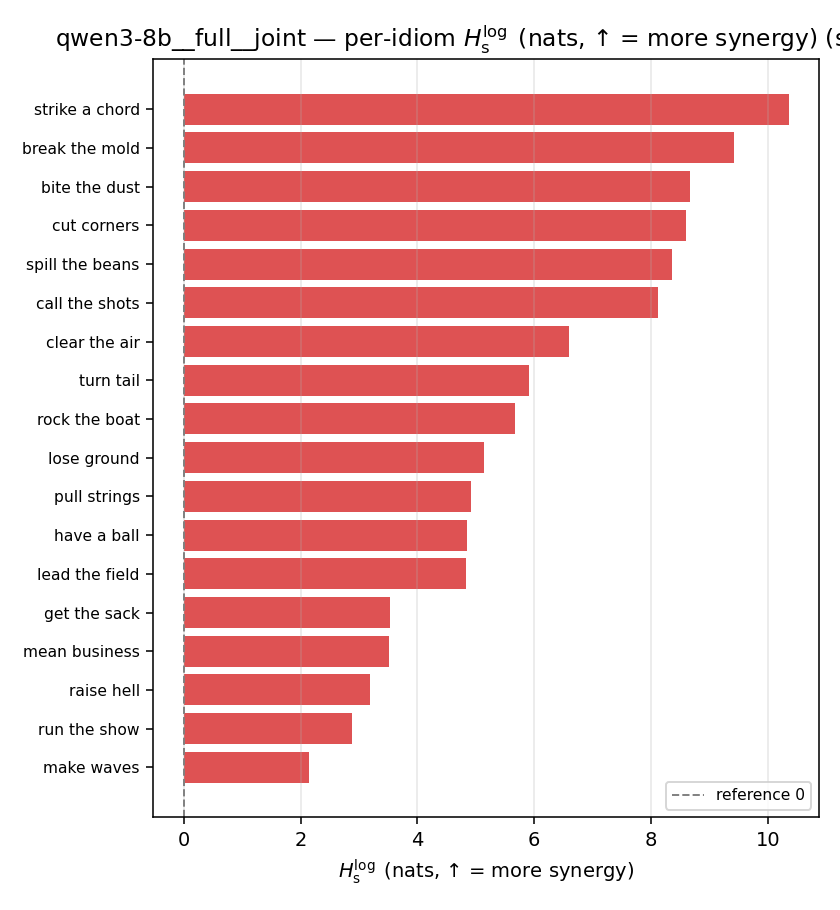 | 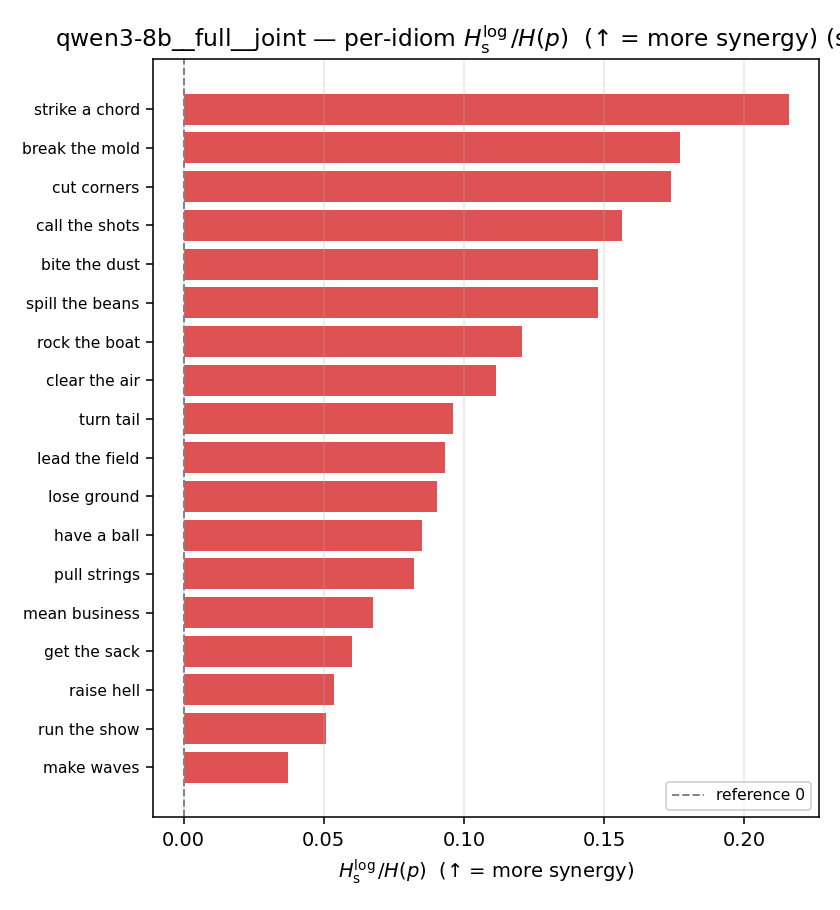 | 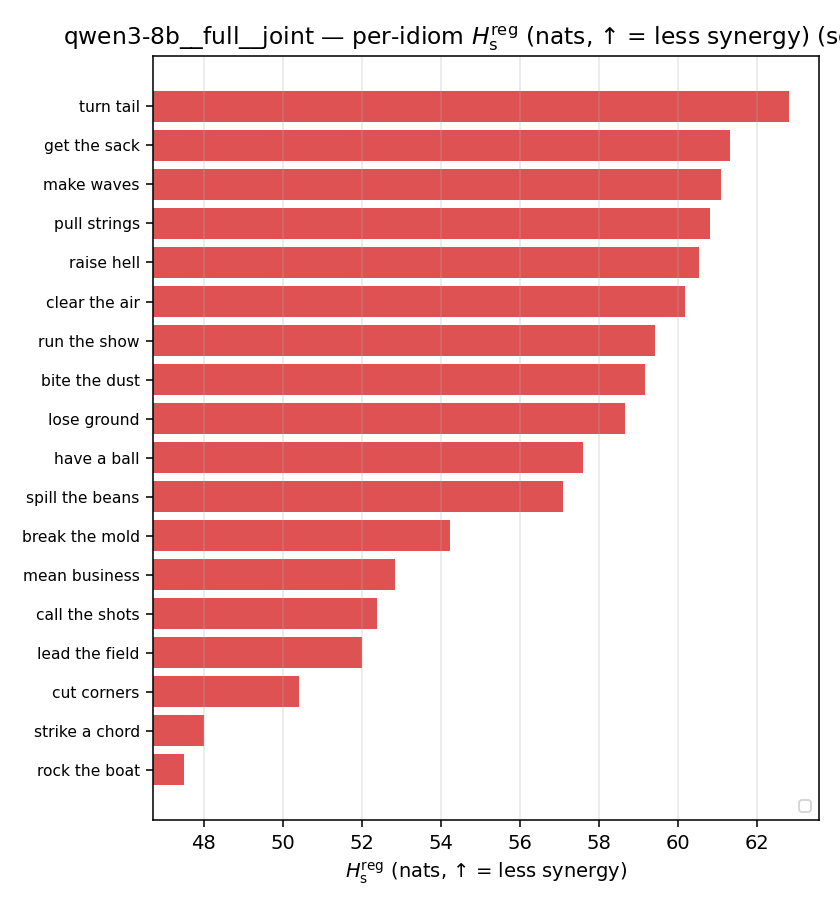 | 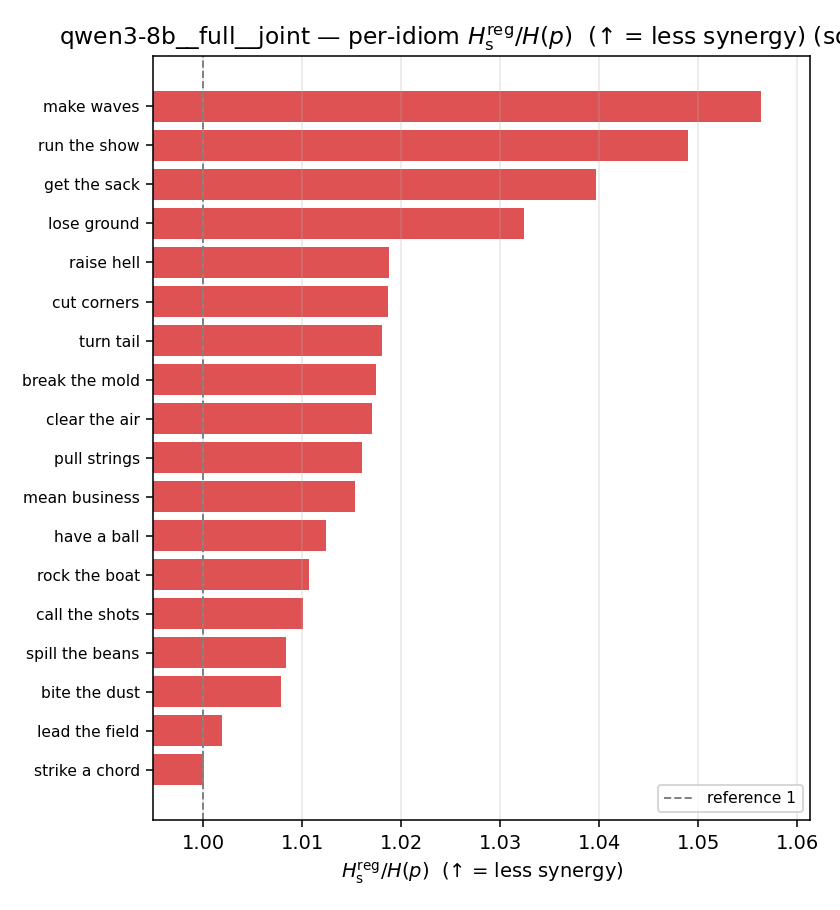 | — (no finite values) | — (no finite values) |
llama3.1-8b — per-config figures
3×9 grid of figure-type × metric (↑syn = bigger means more synergy, ↓syn = bigger means less). Tables scroll horizontally; “— (no finite values)” marks the original Hs/ratio_s where every phrase was +inf. Click to zoom.
llama3.1-8b · medial · geo llama3.1-8b__medial__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 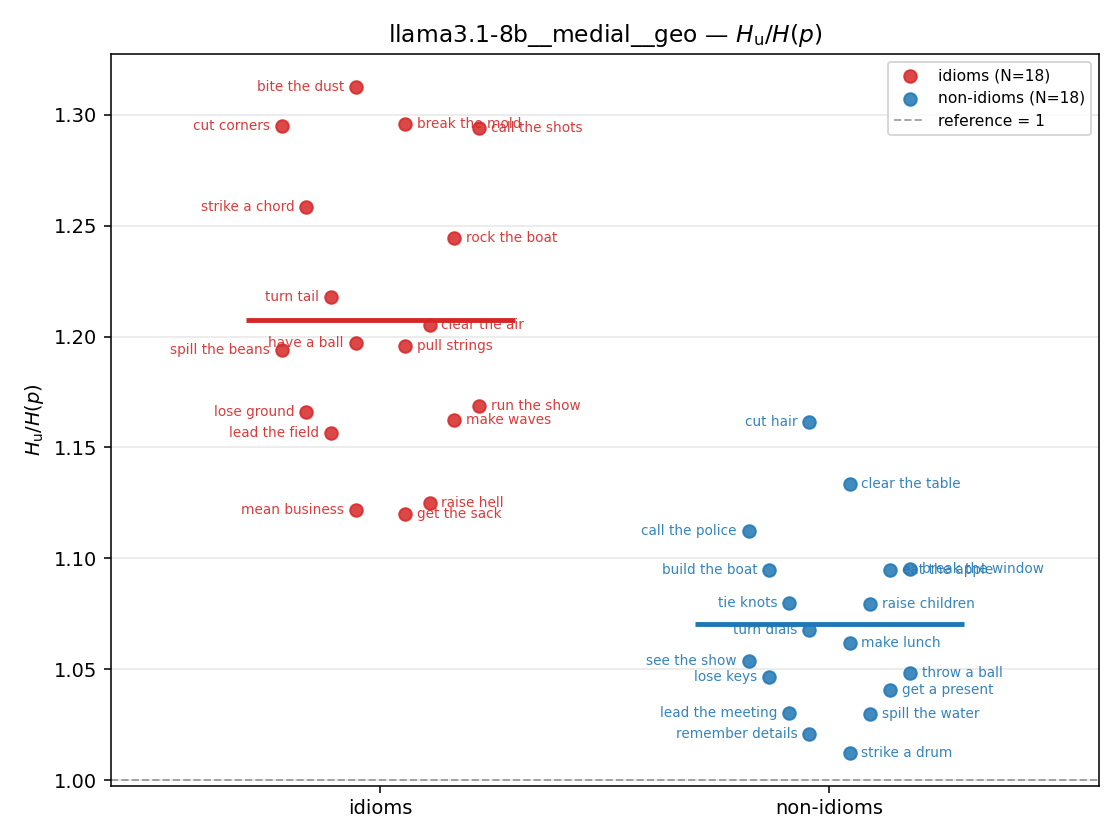 | 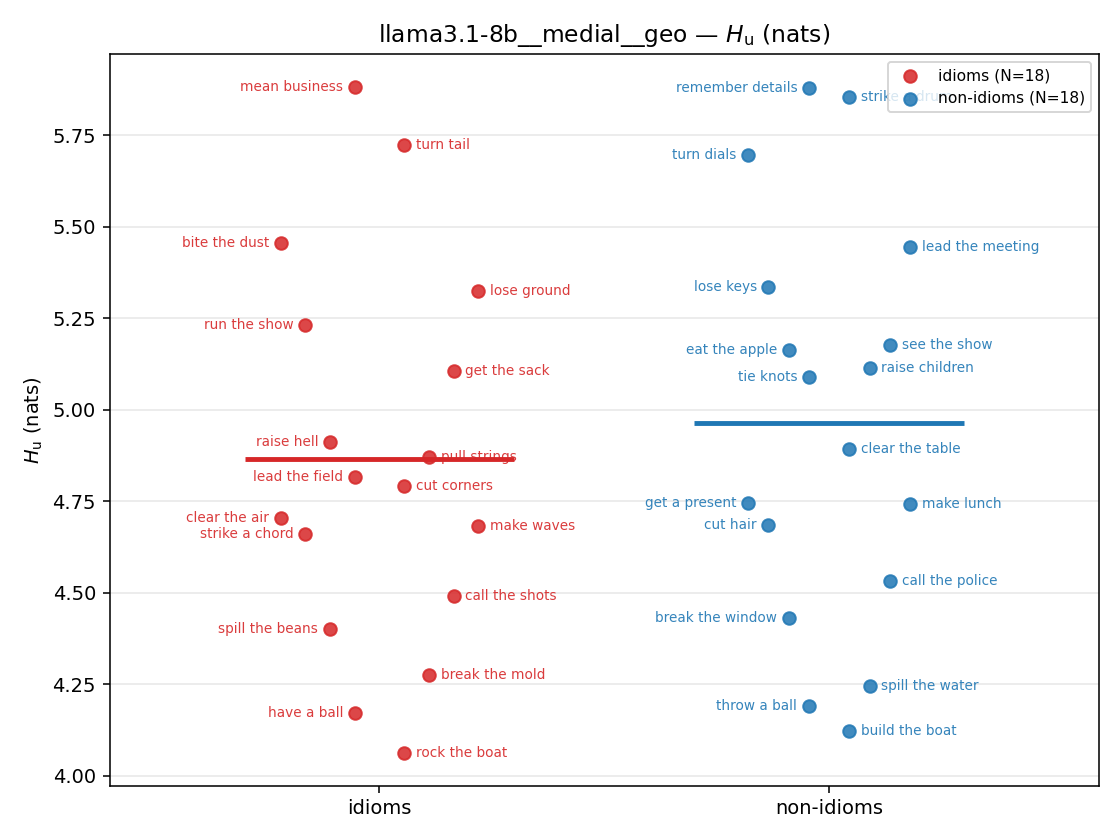 | 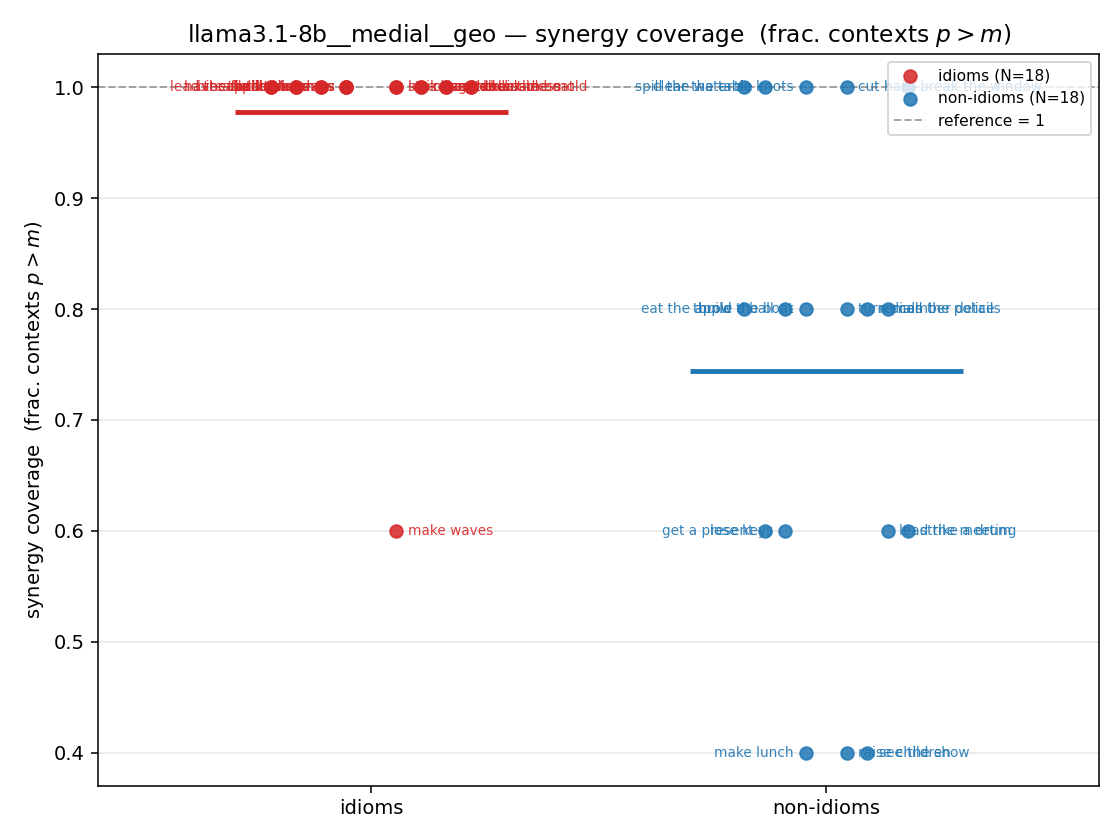 | 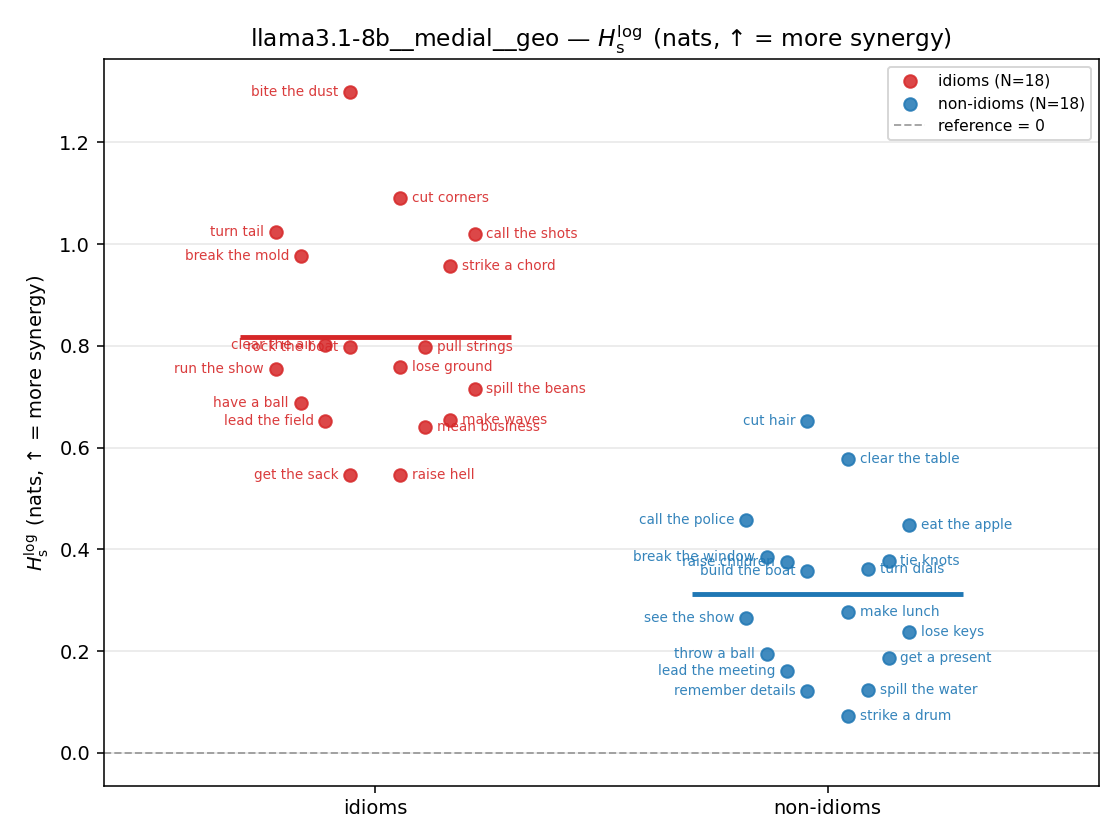 | 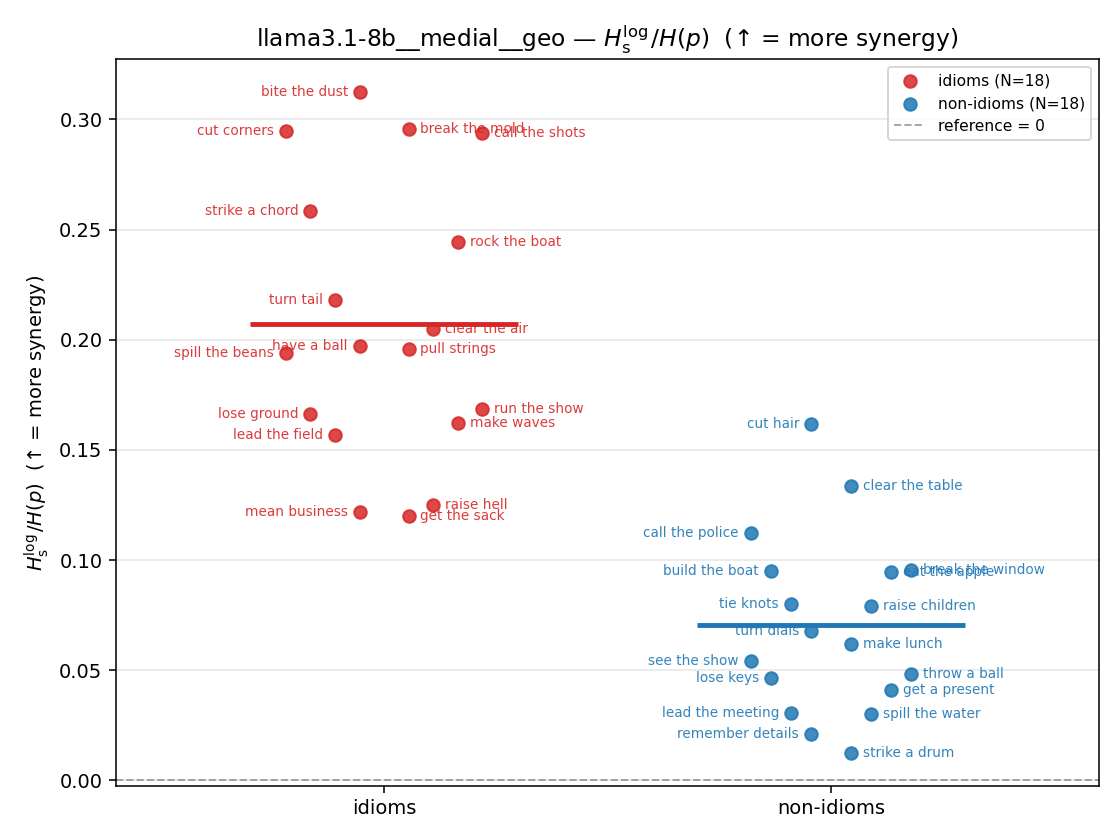 | 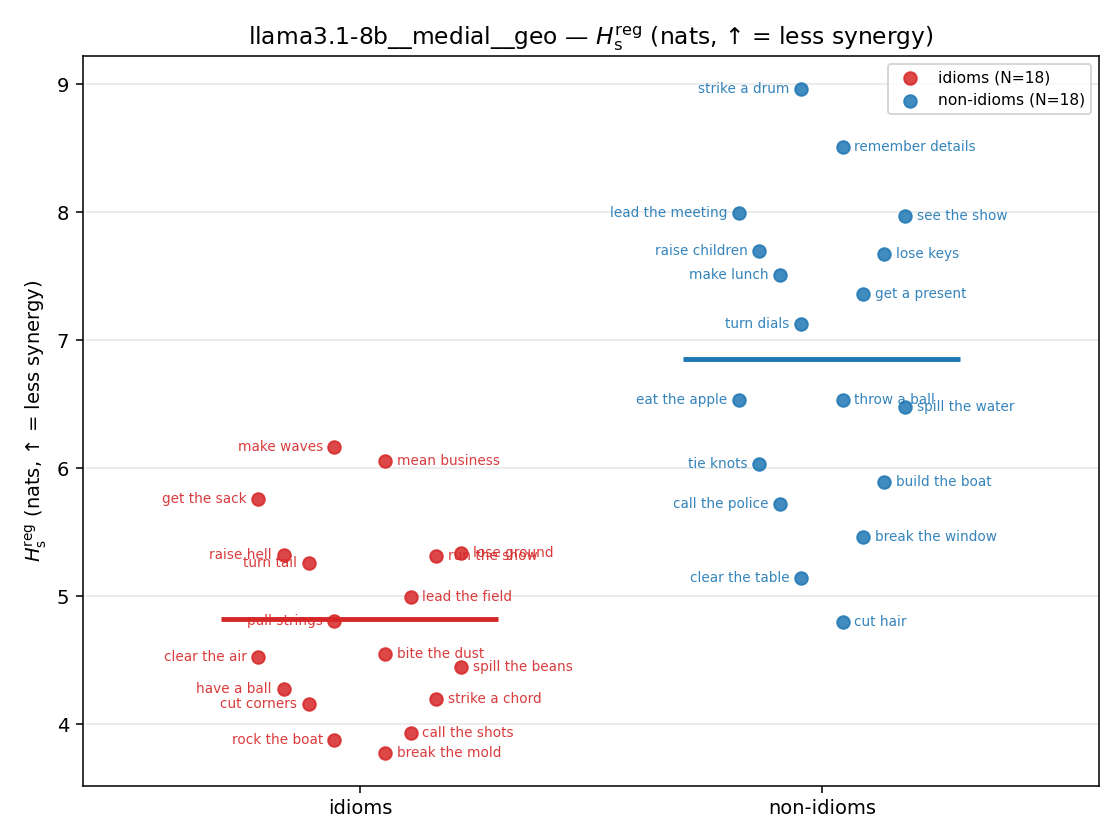 | 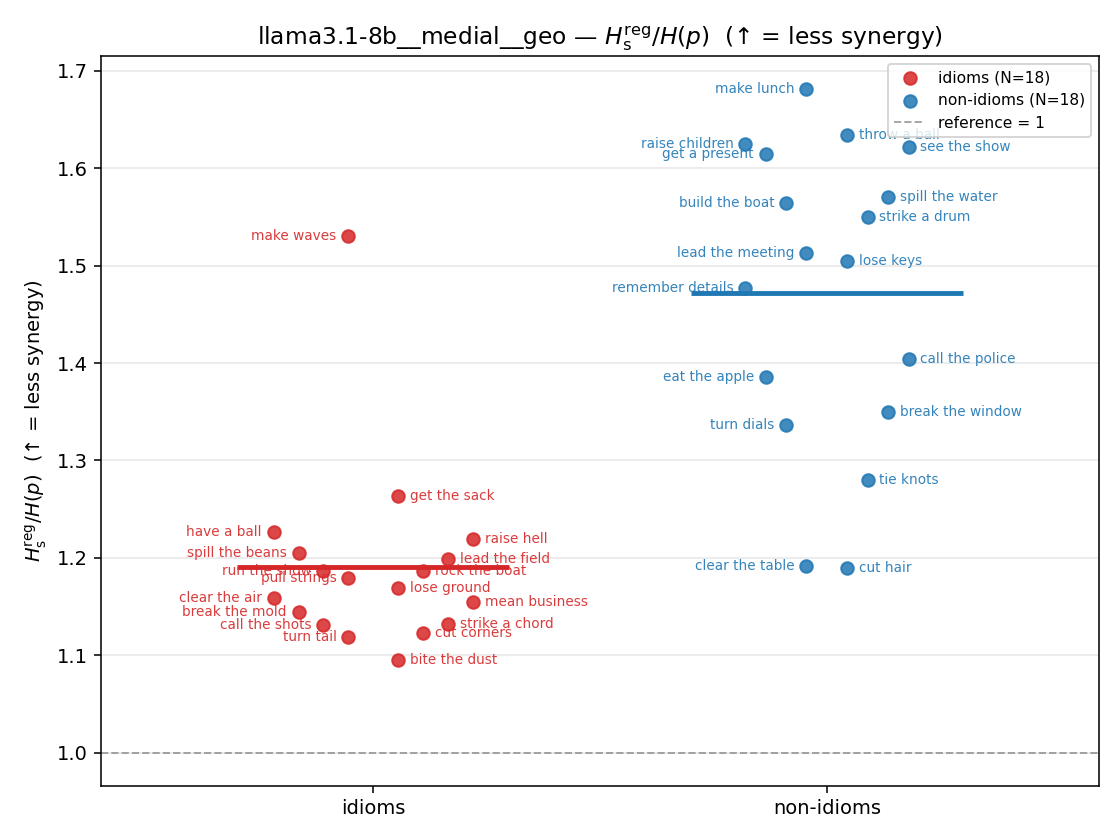 | 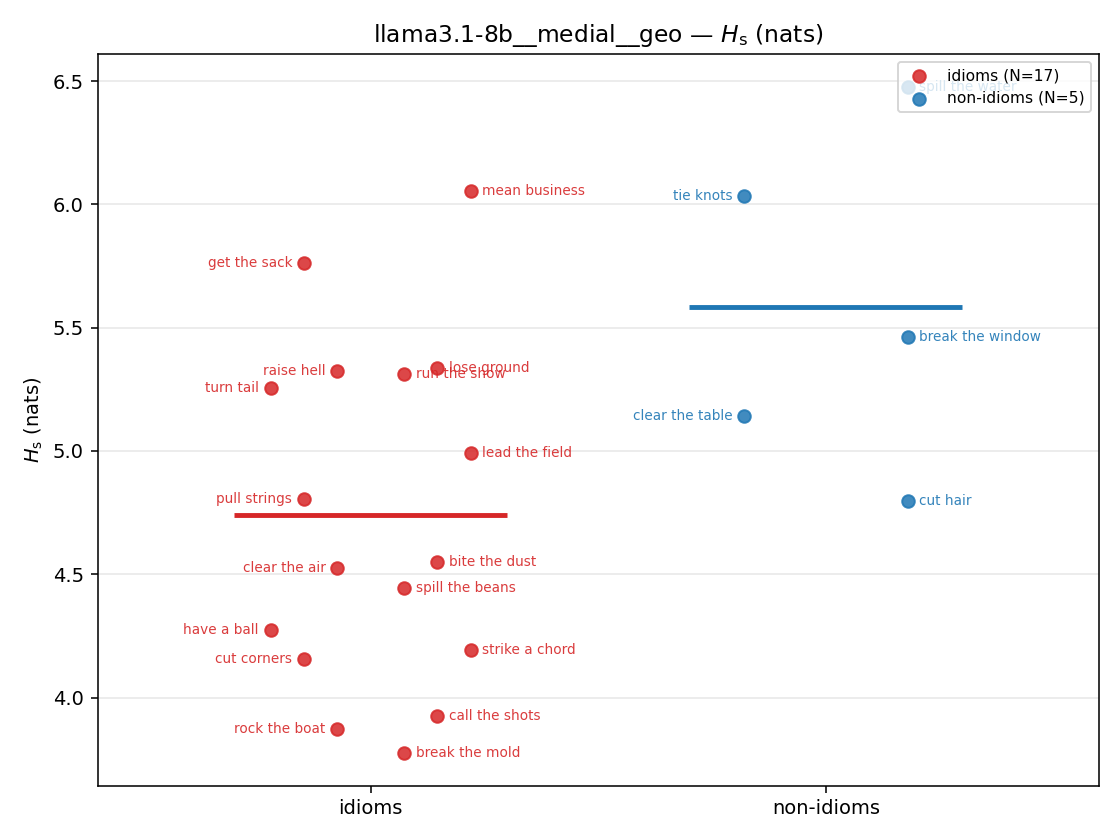 | 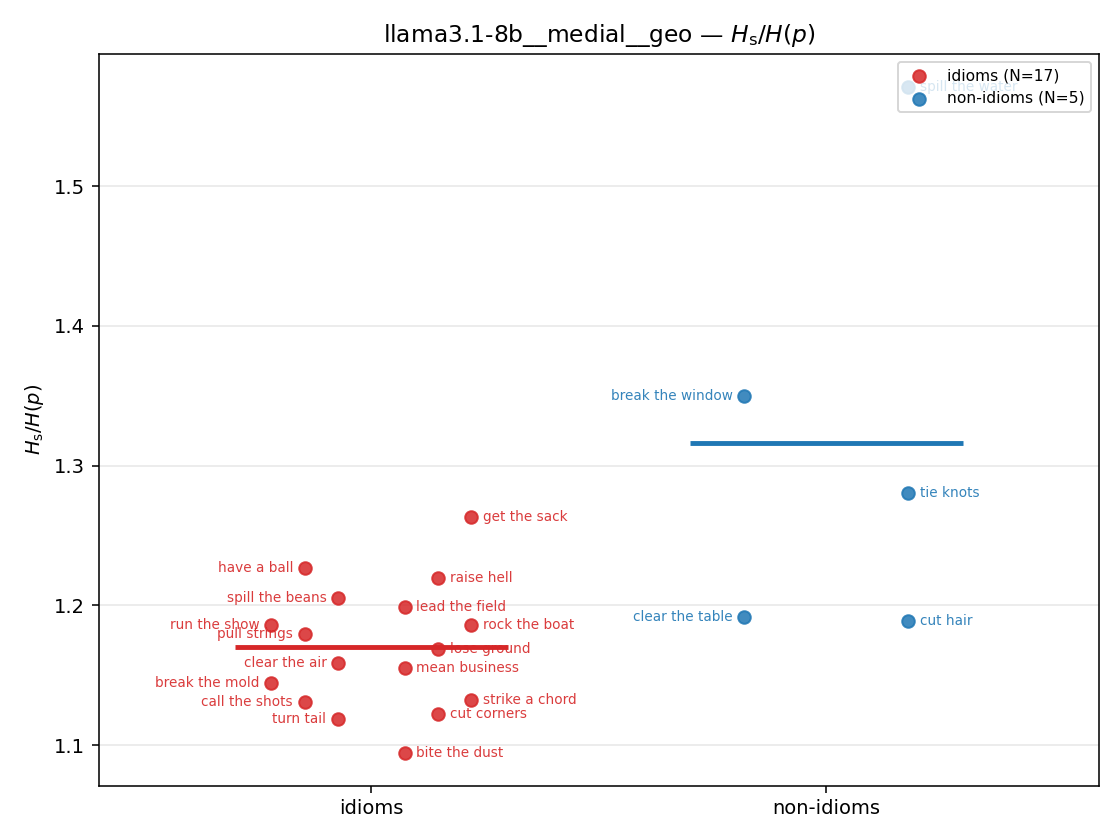 |
| mean ± 95% CI | 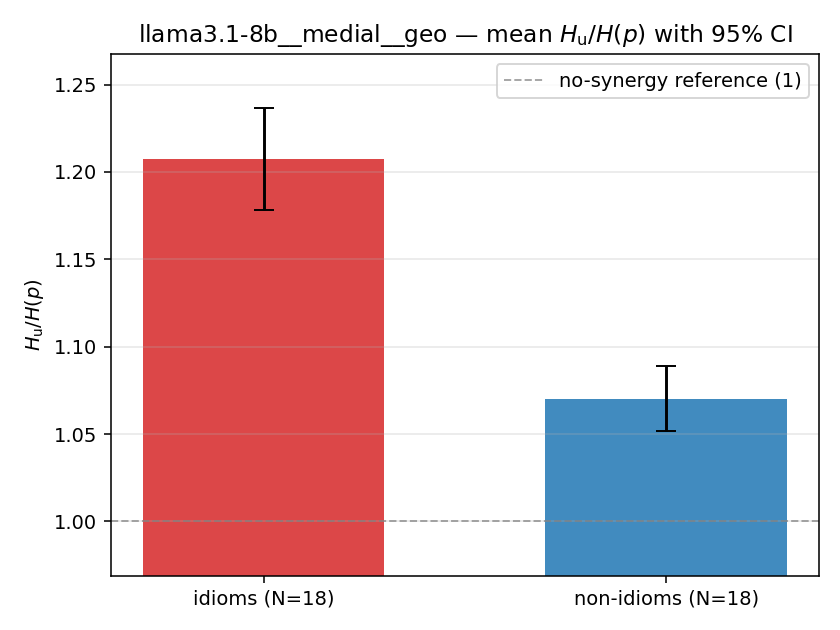 | 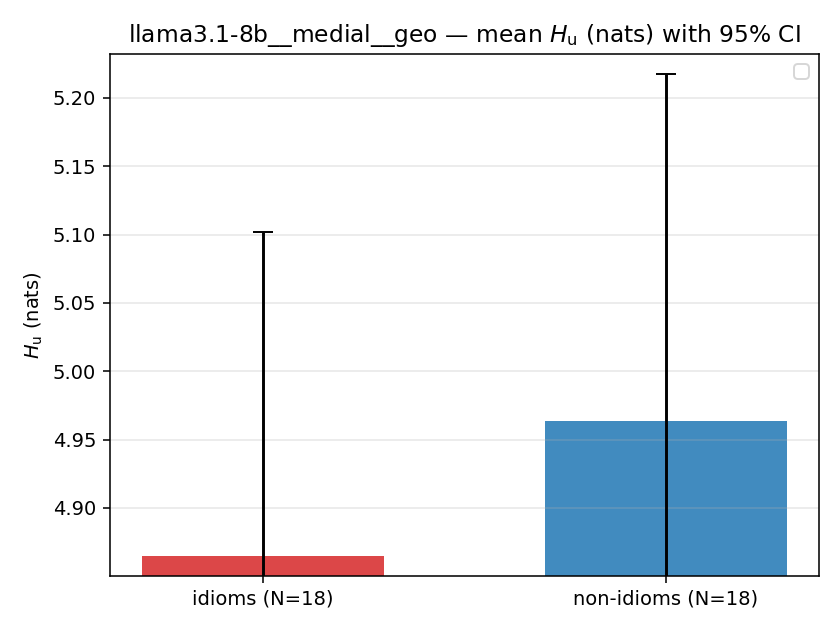 | 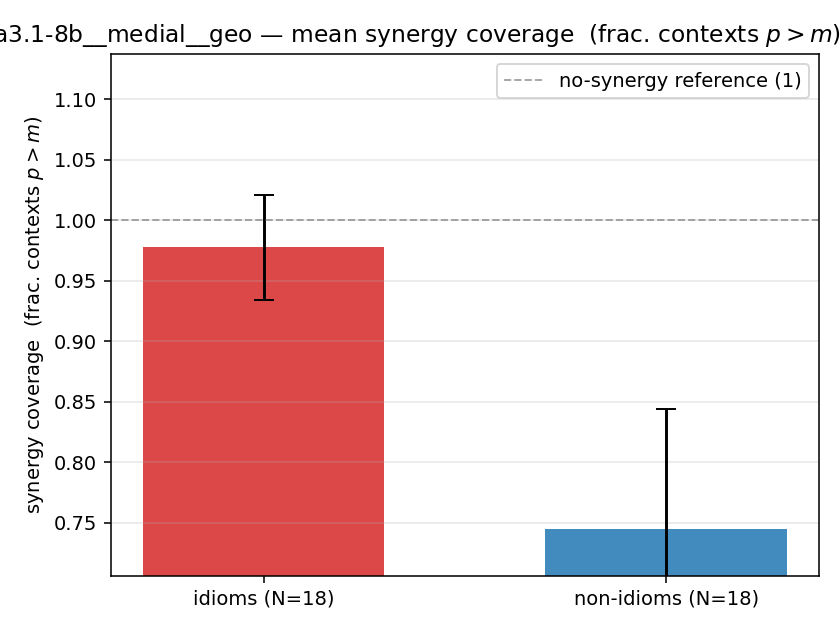 | 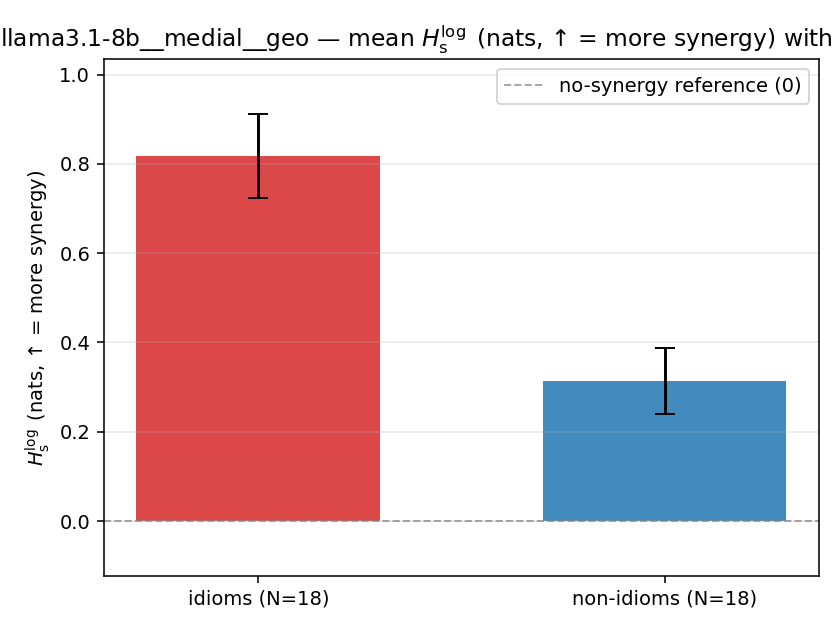 | 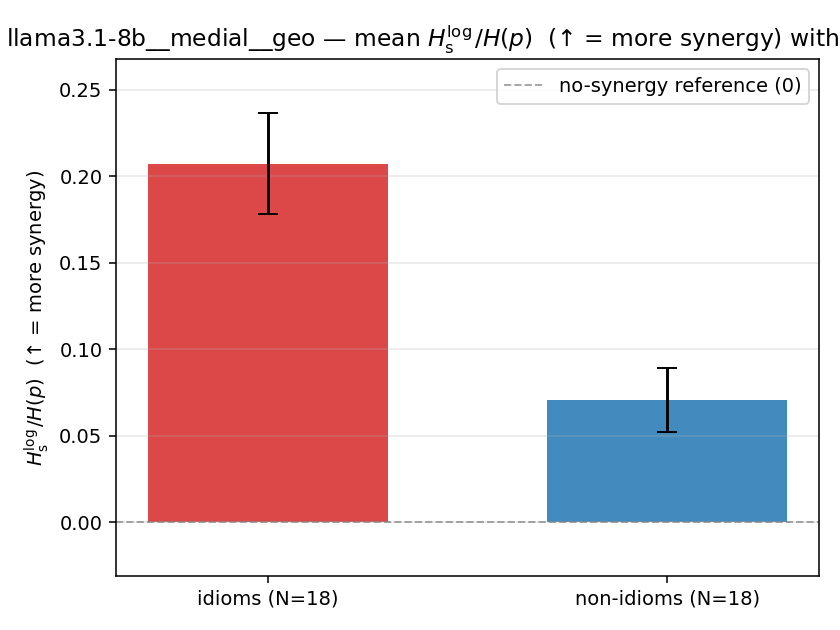 | 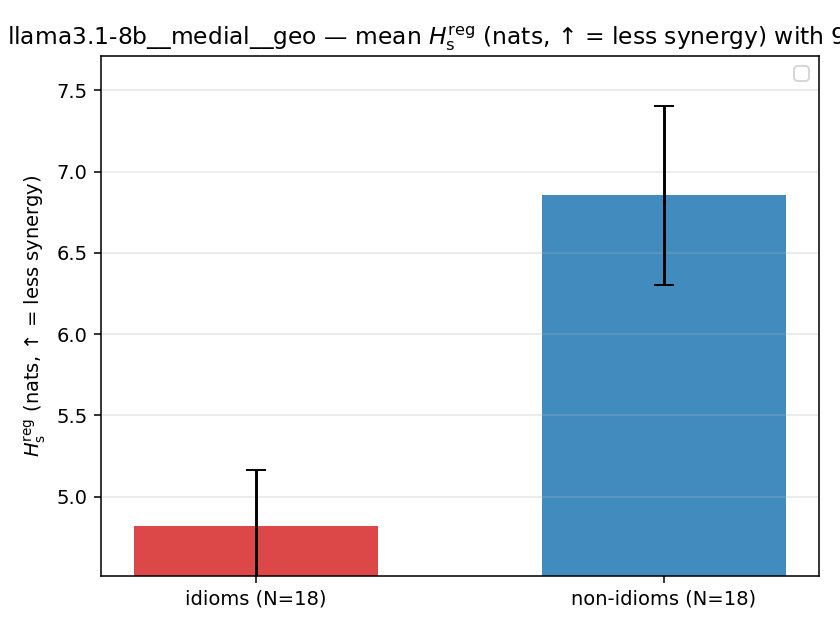 | 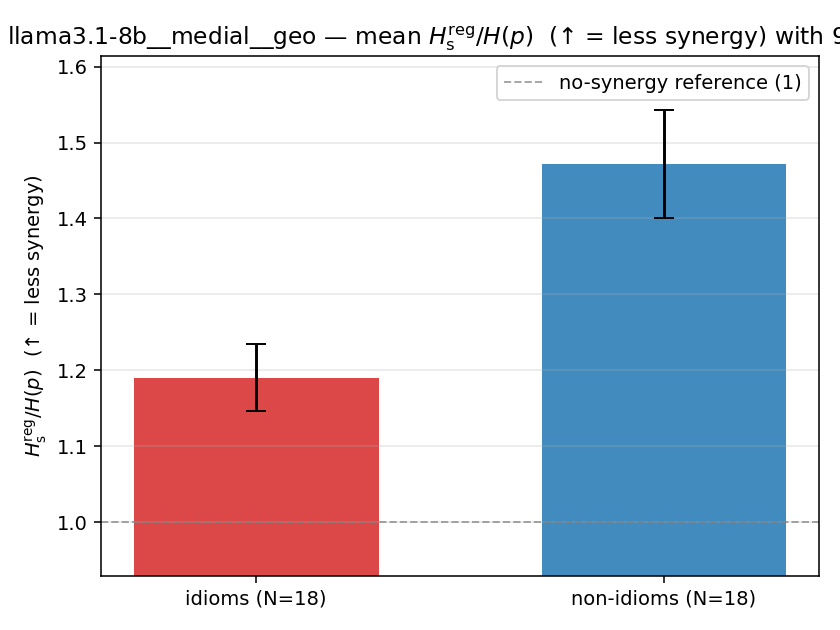 | 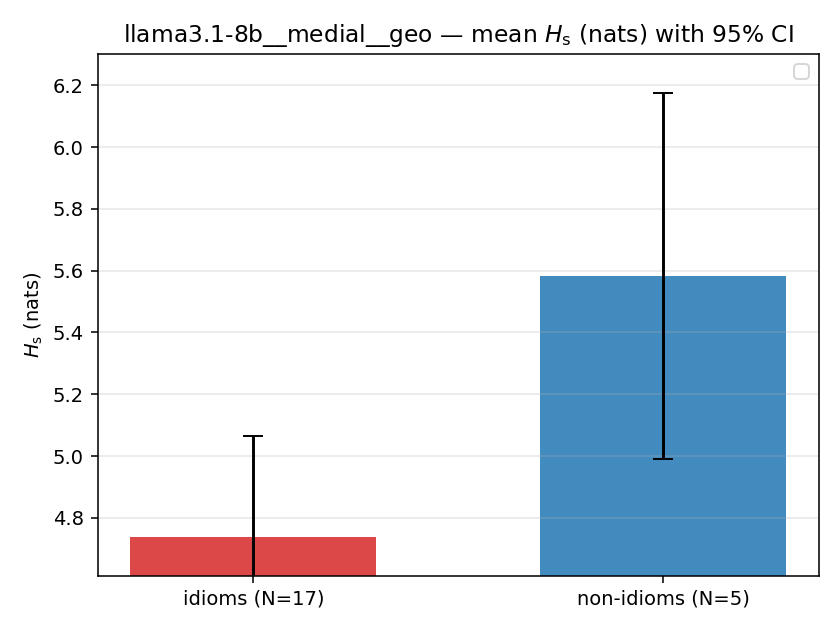 | 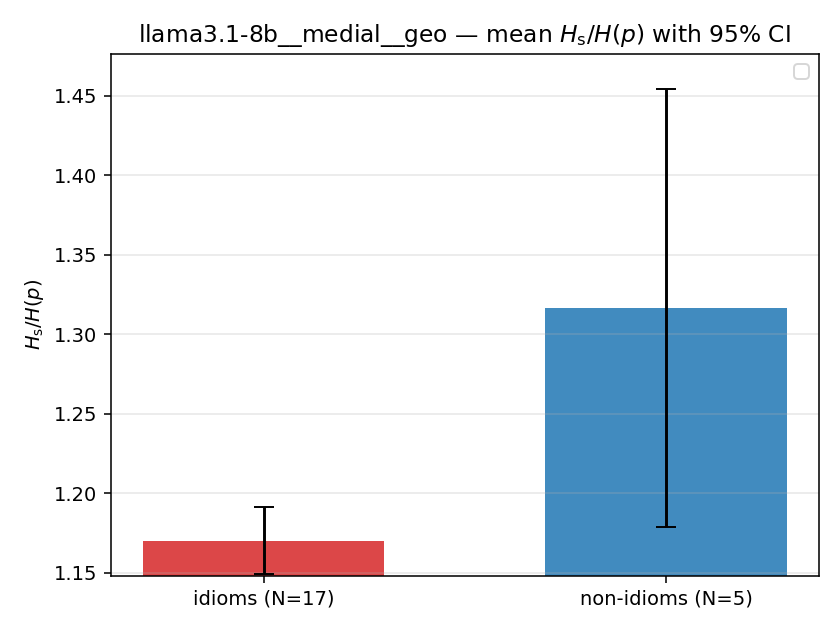 |
| per-idiom (sorted) | 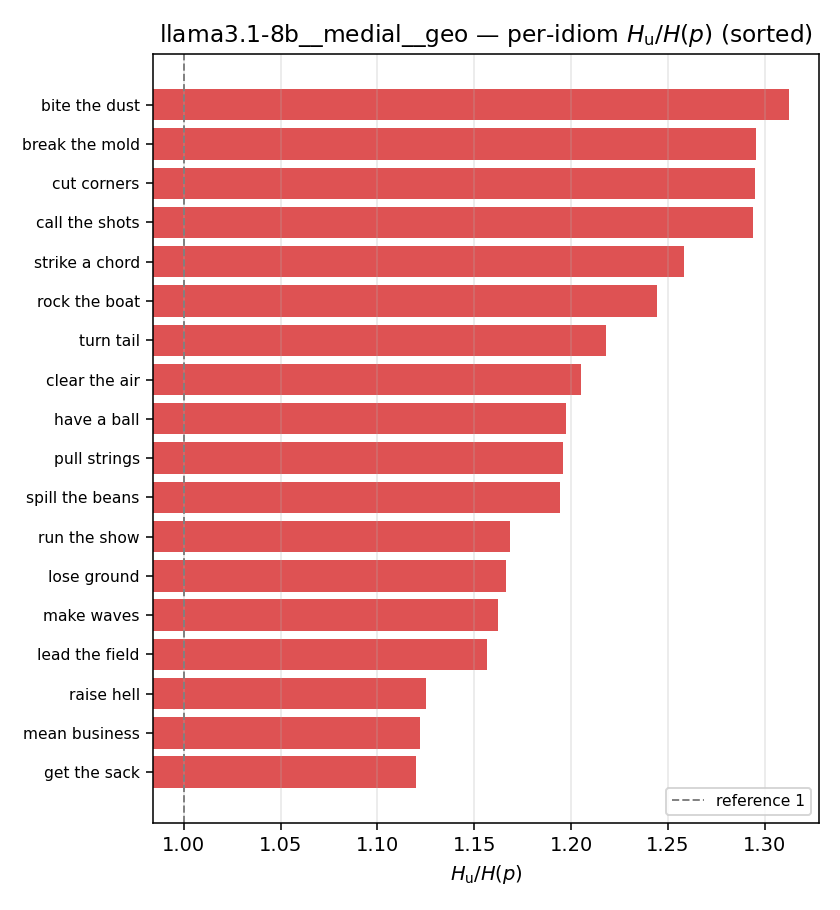 | 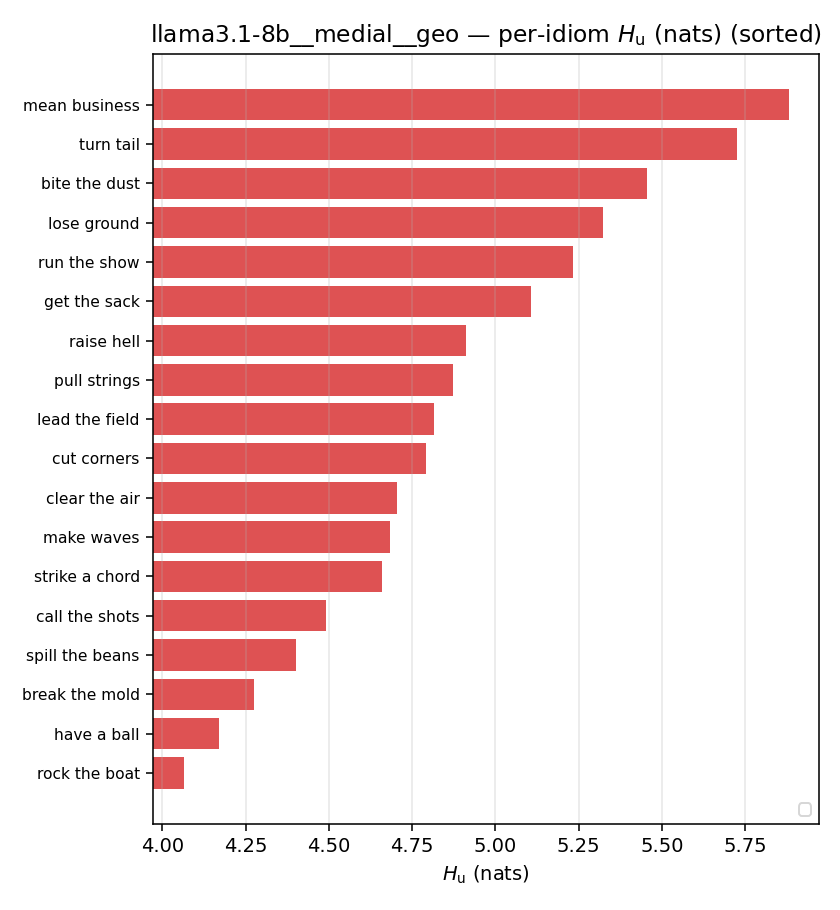 | 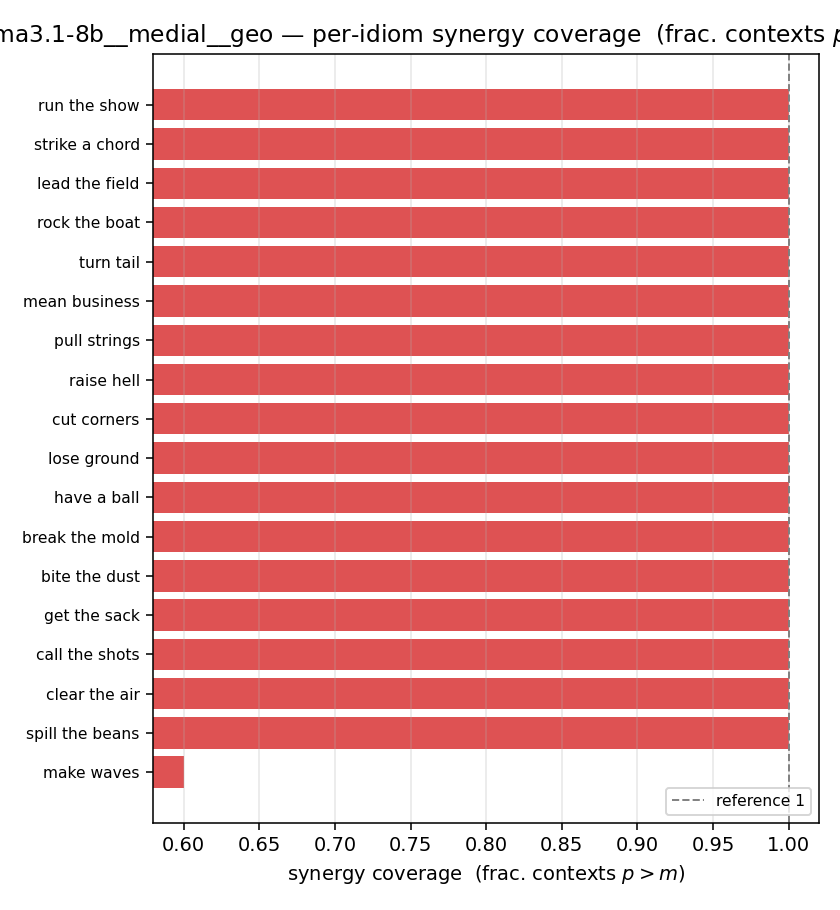 | 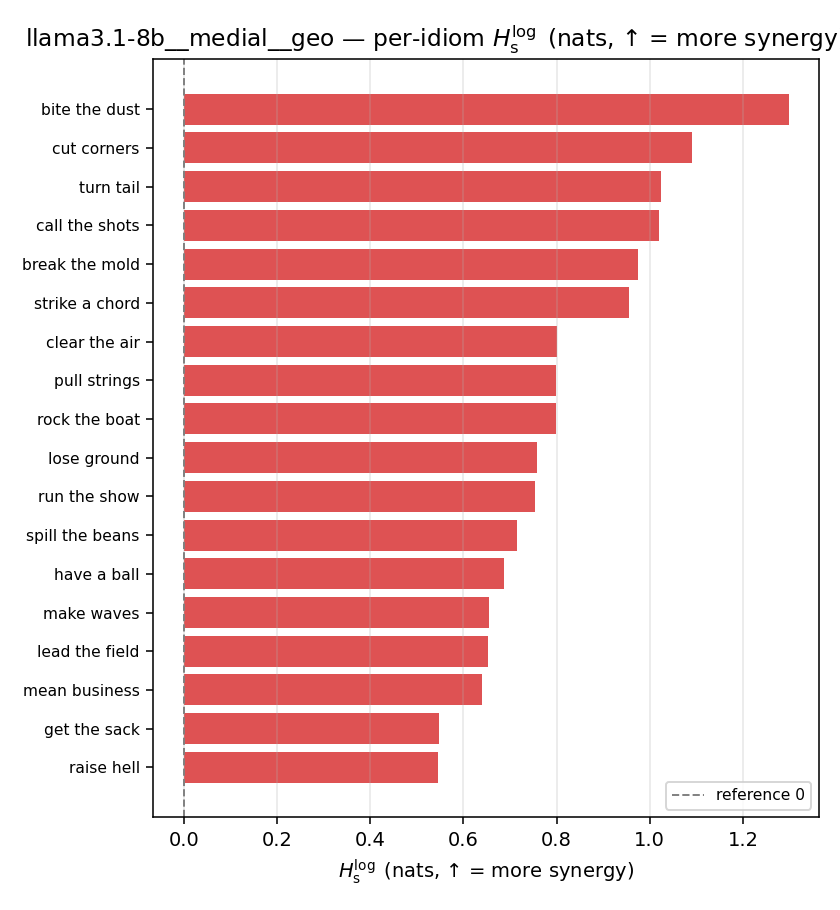 | 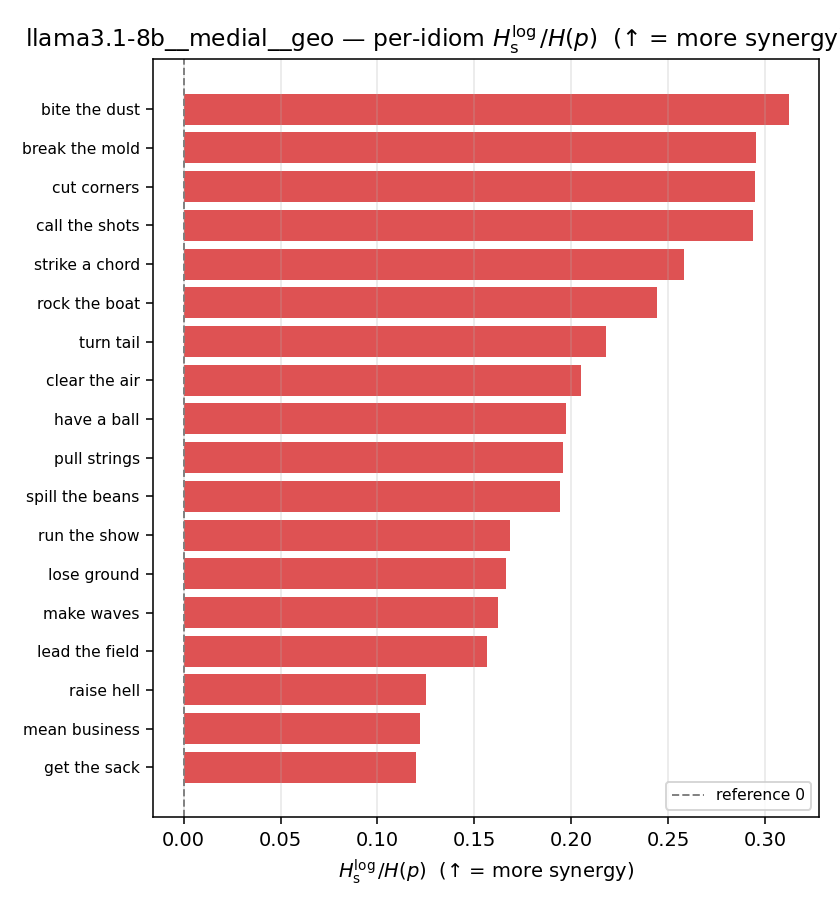 | 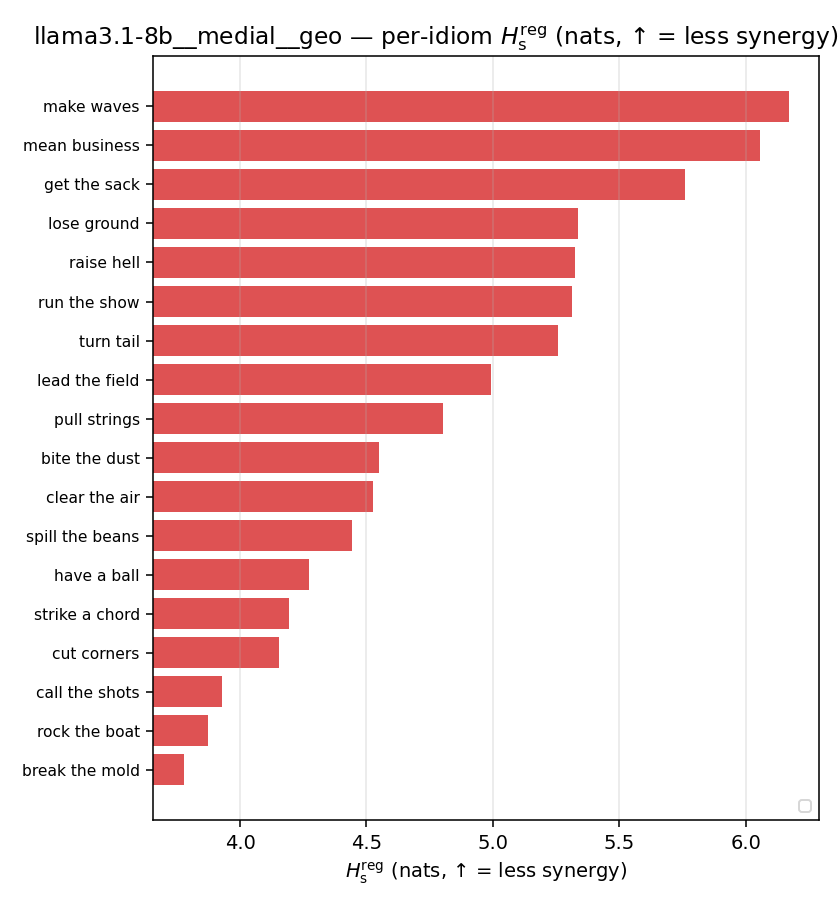 | 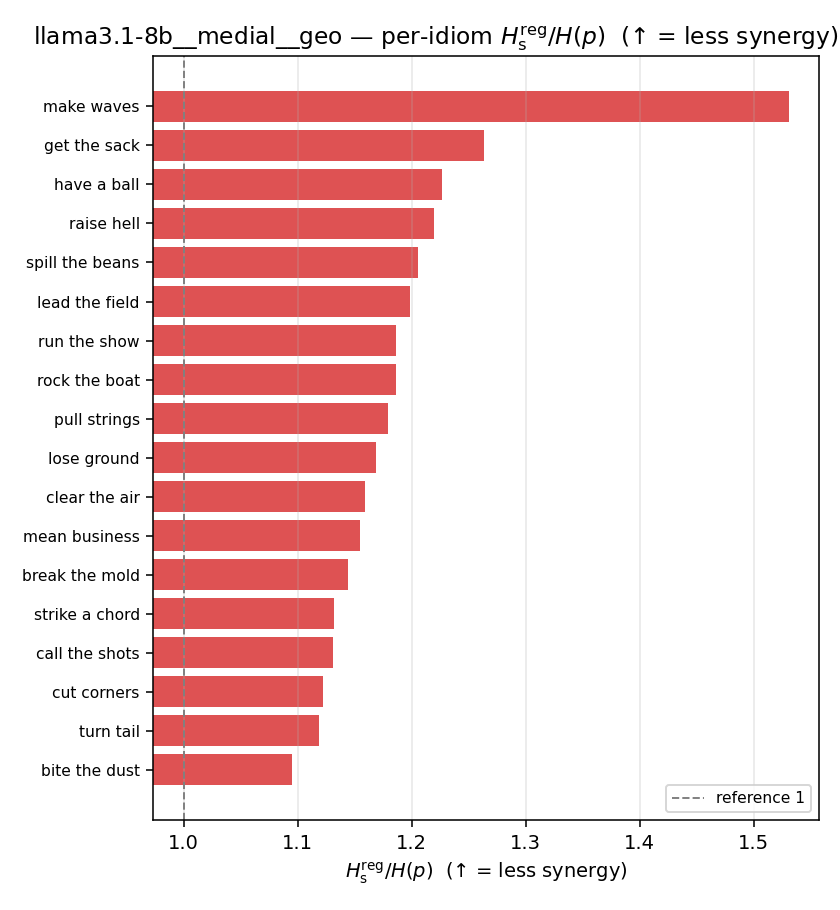 | 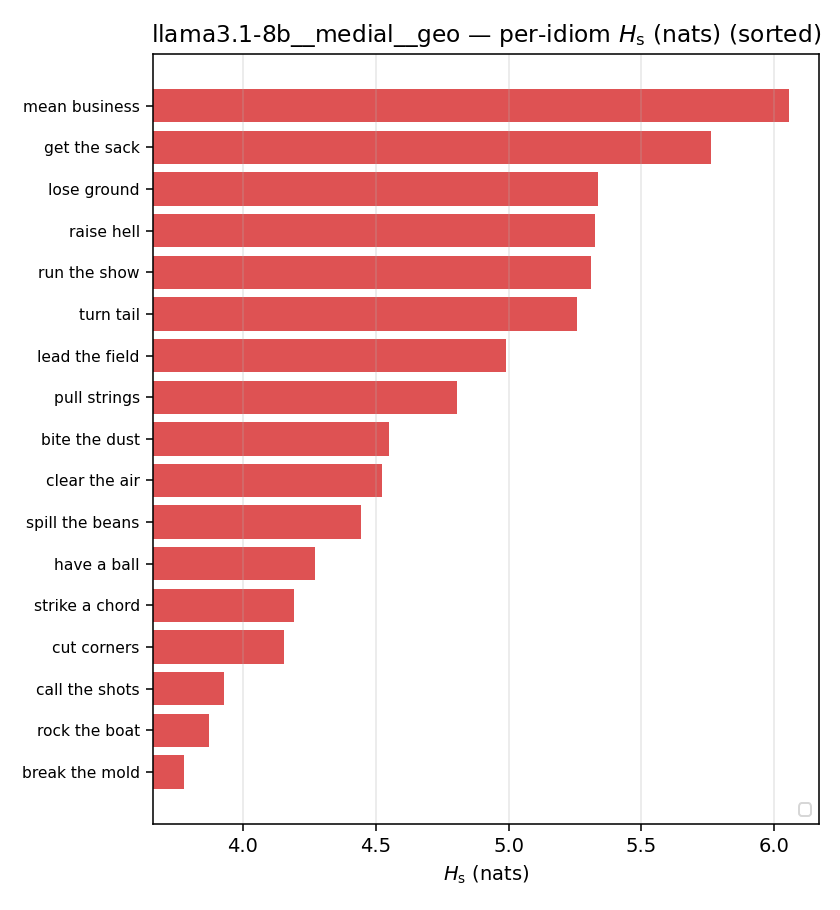 | 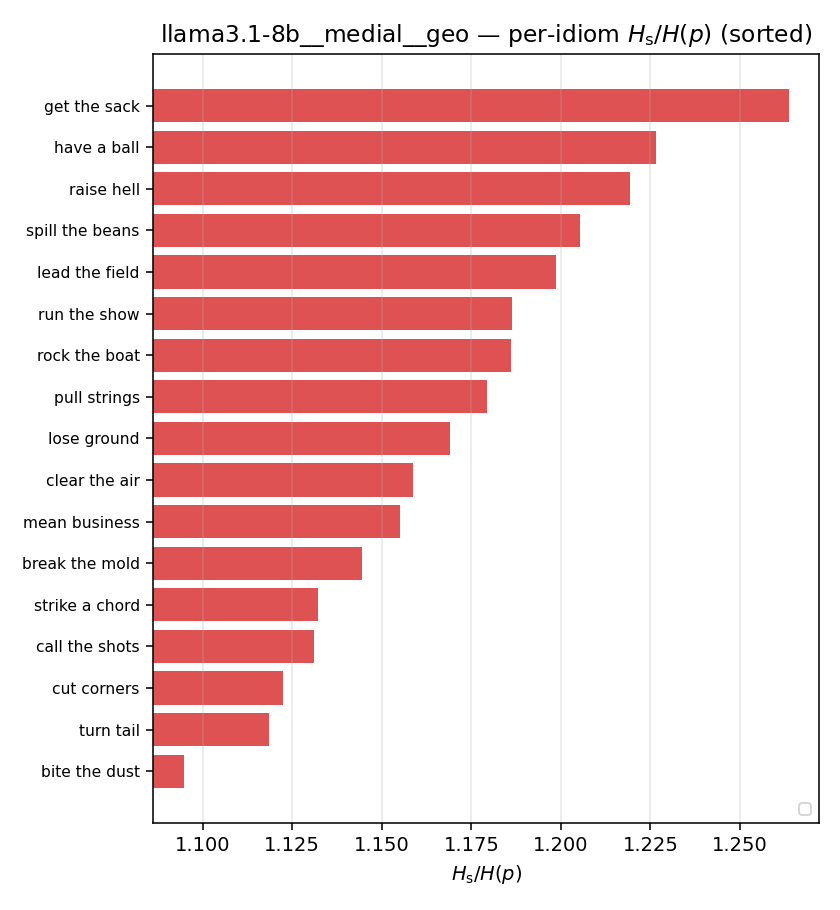 |
llama3.1-8b · medial · joint llama3.1-8b__medial__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 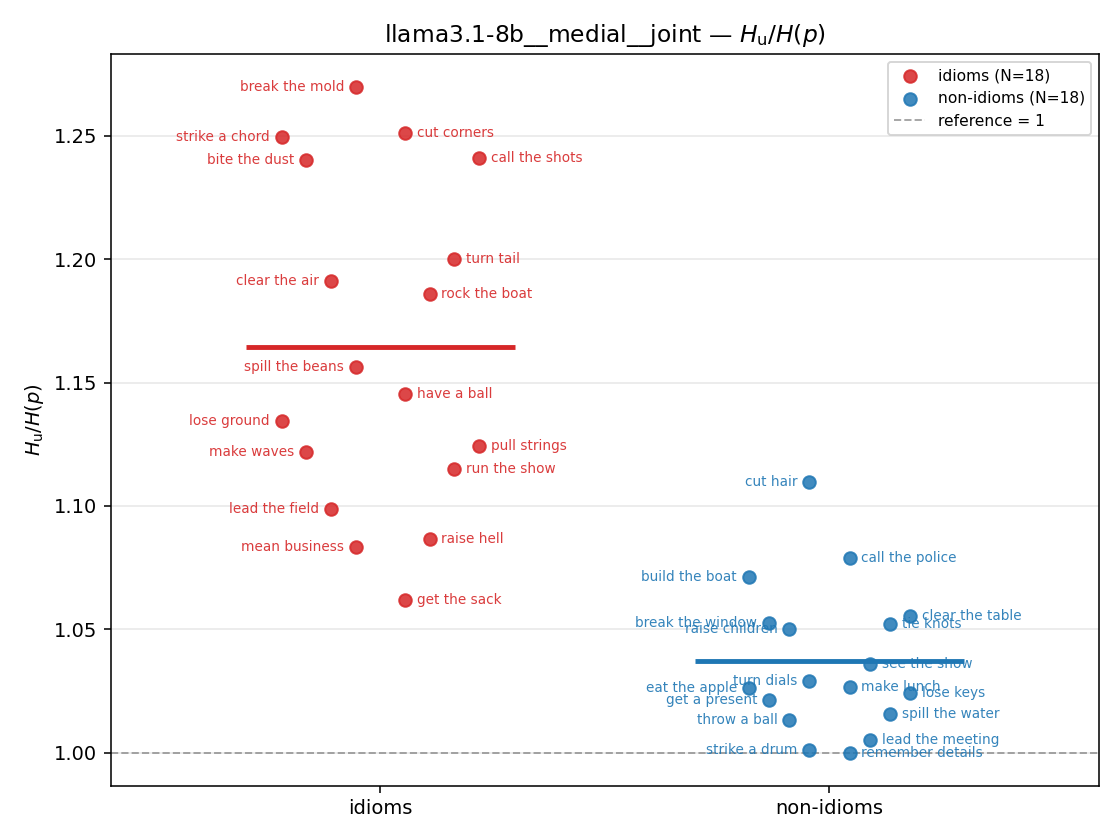 | 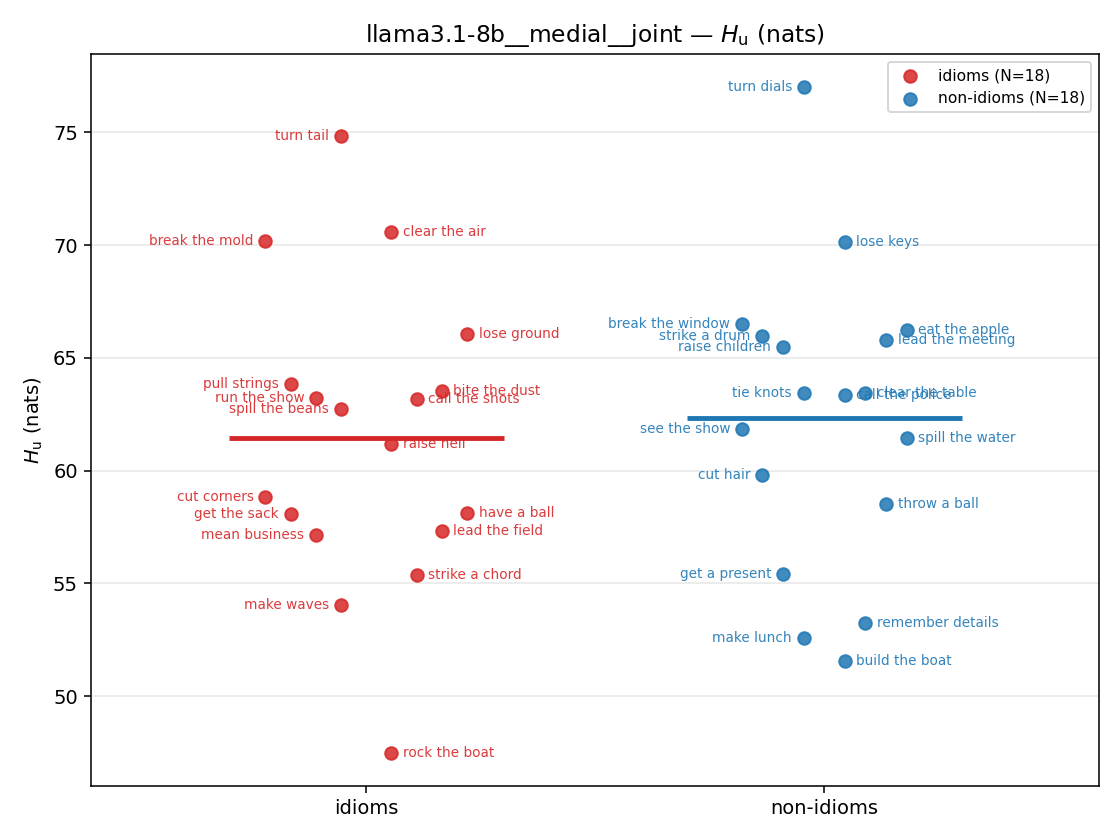 | 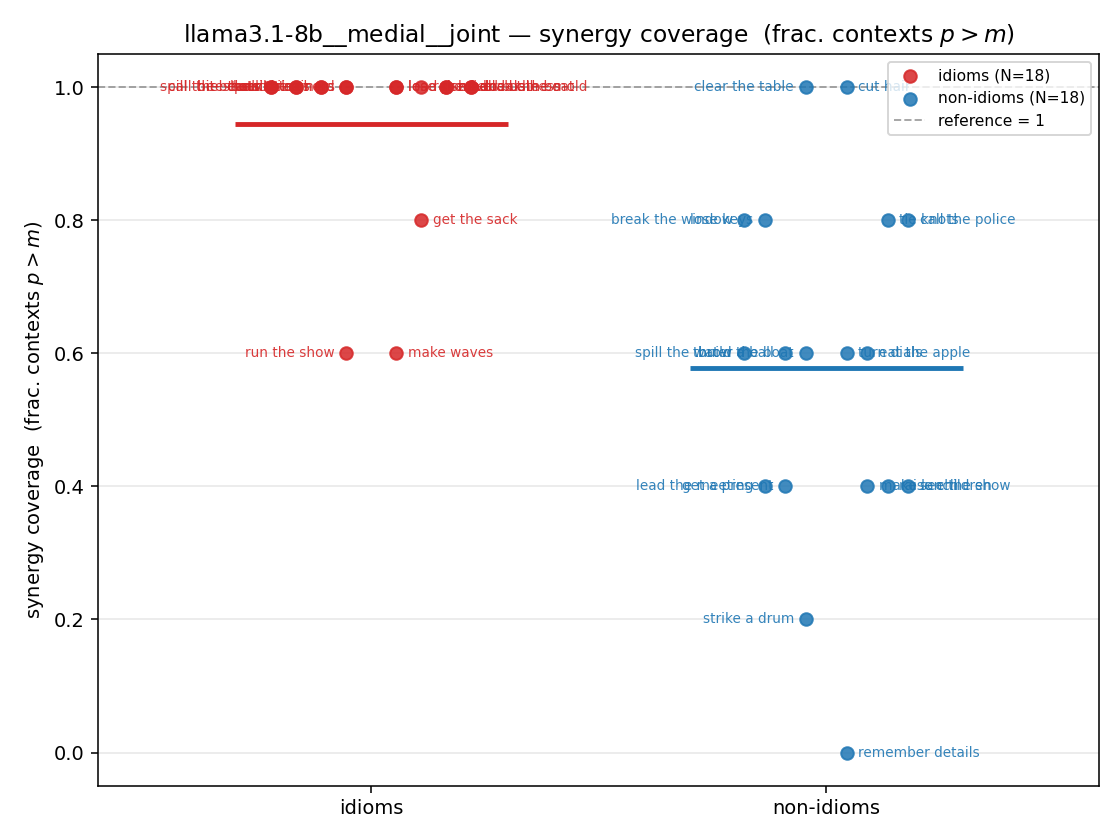 | 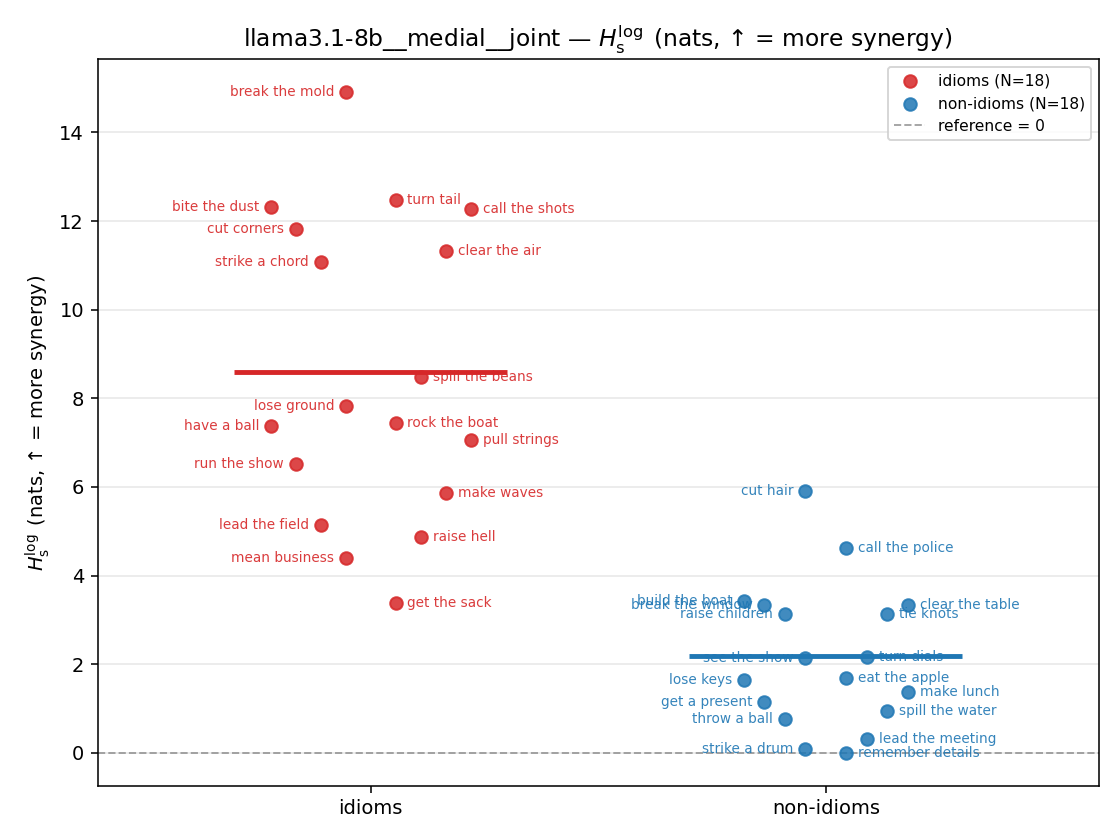 | 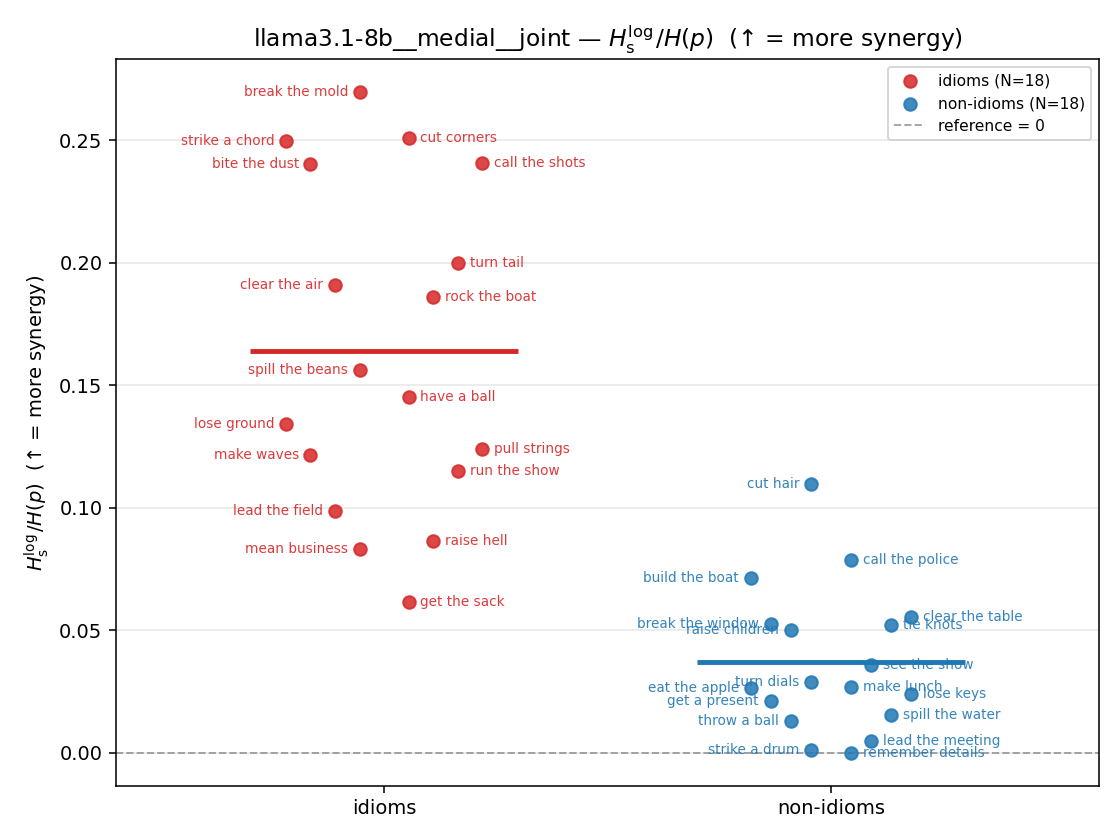 | 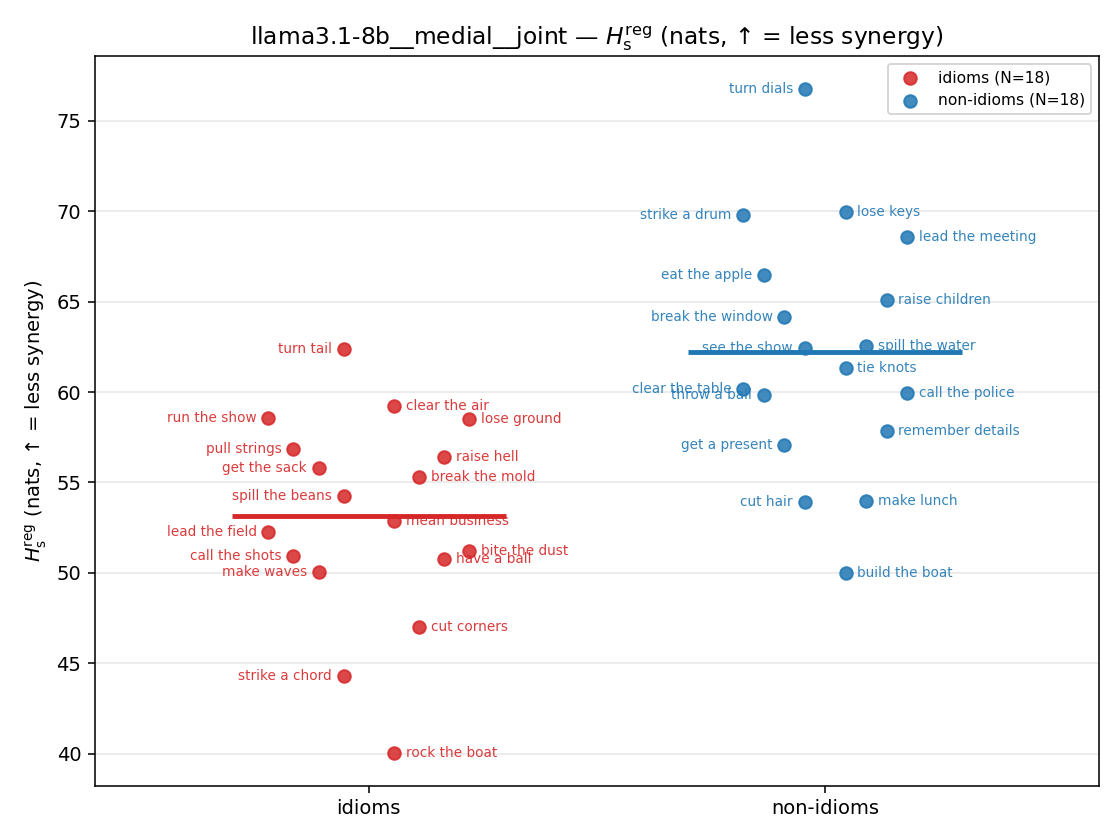 | 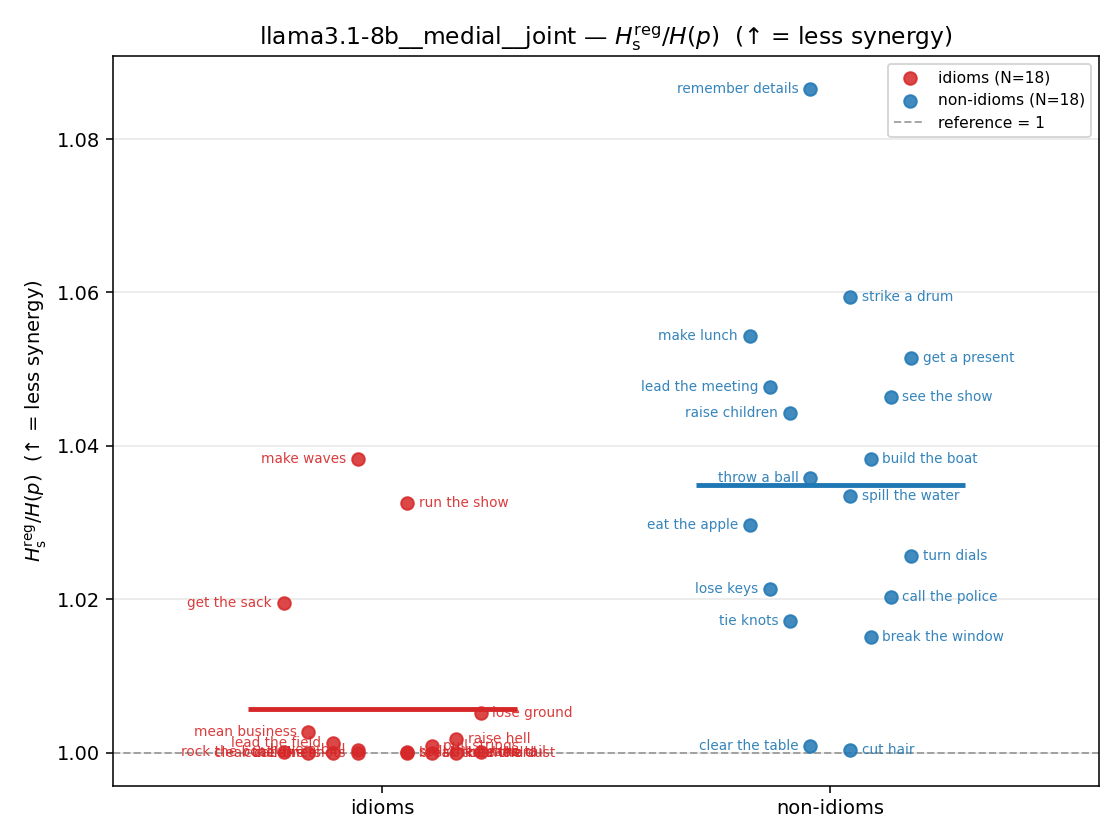 | 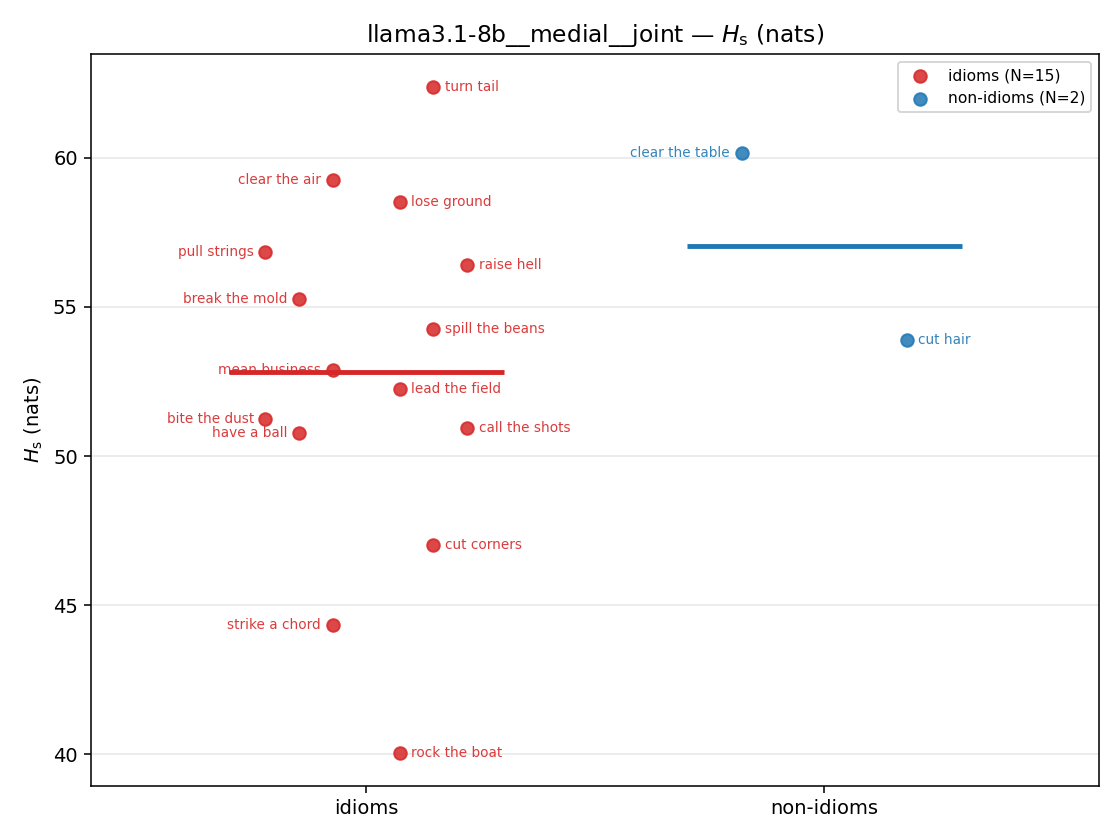 | 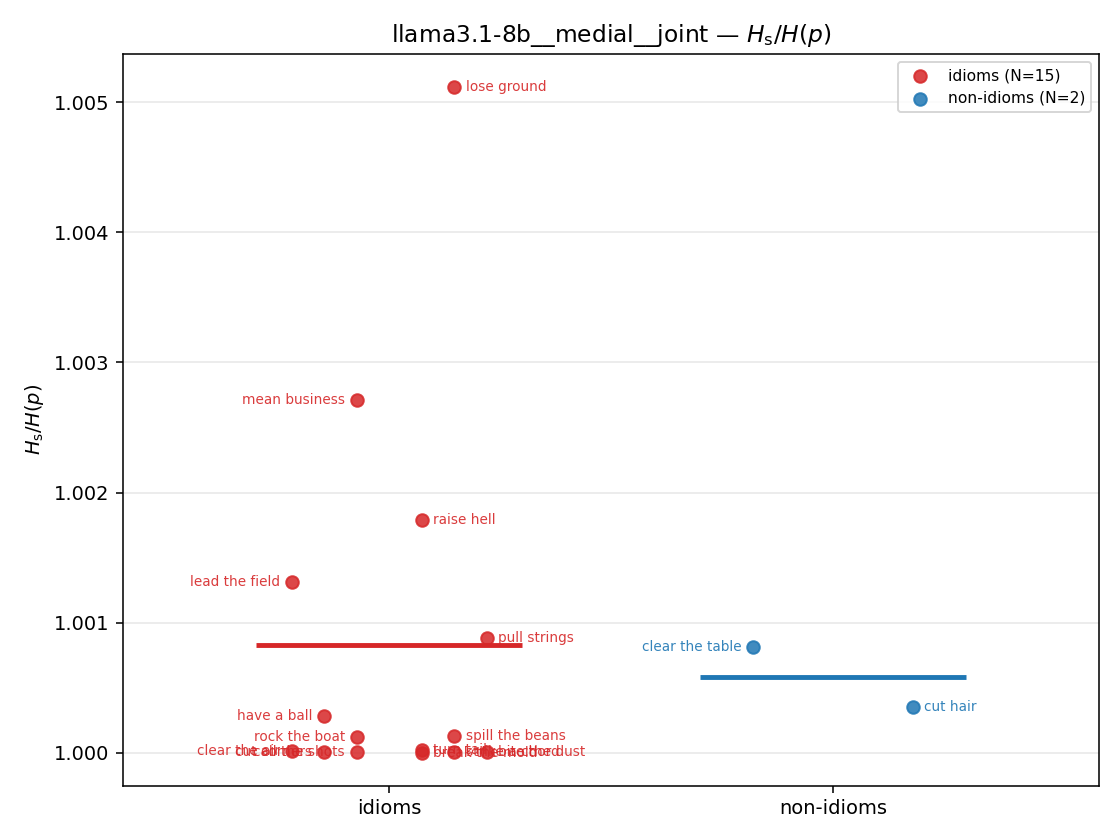 |
| mean ± 95% CI | 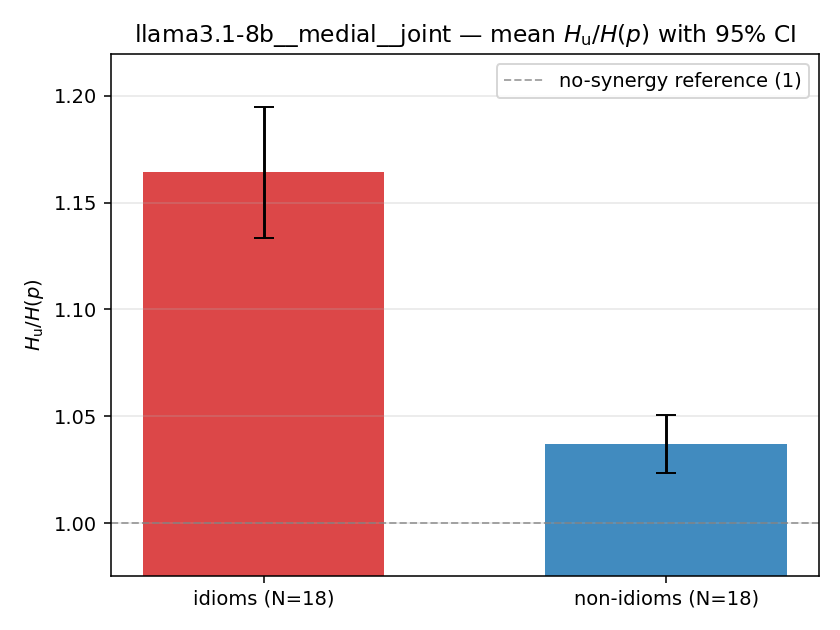 | 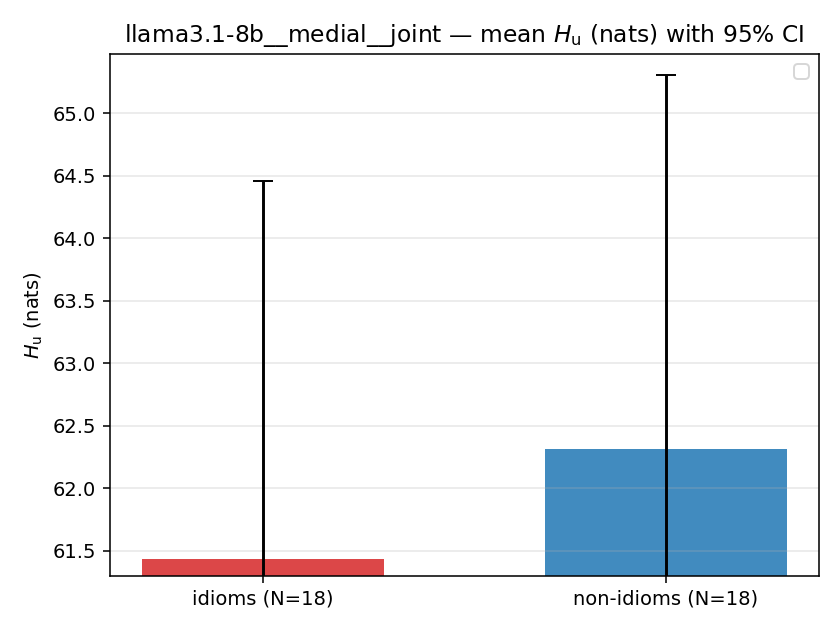 | 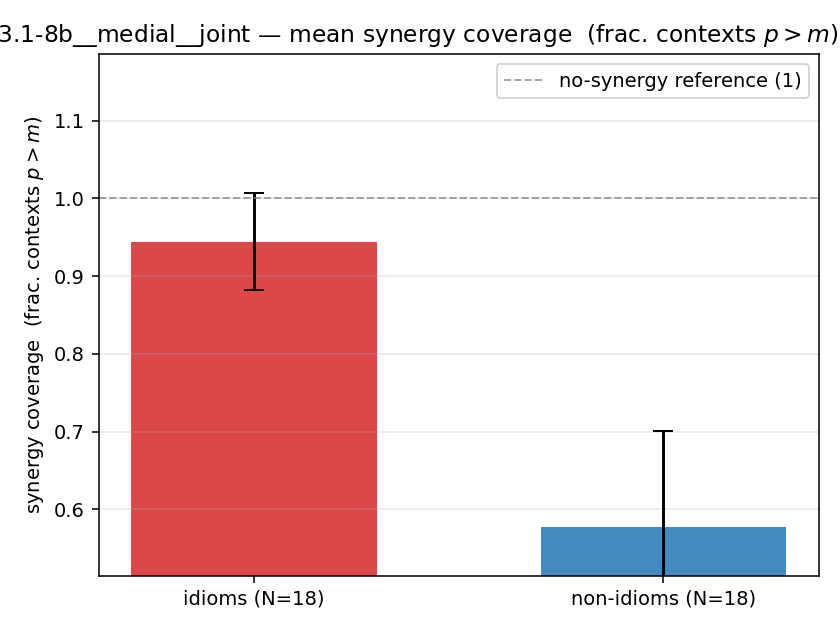 | 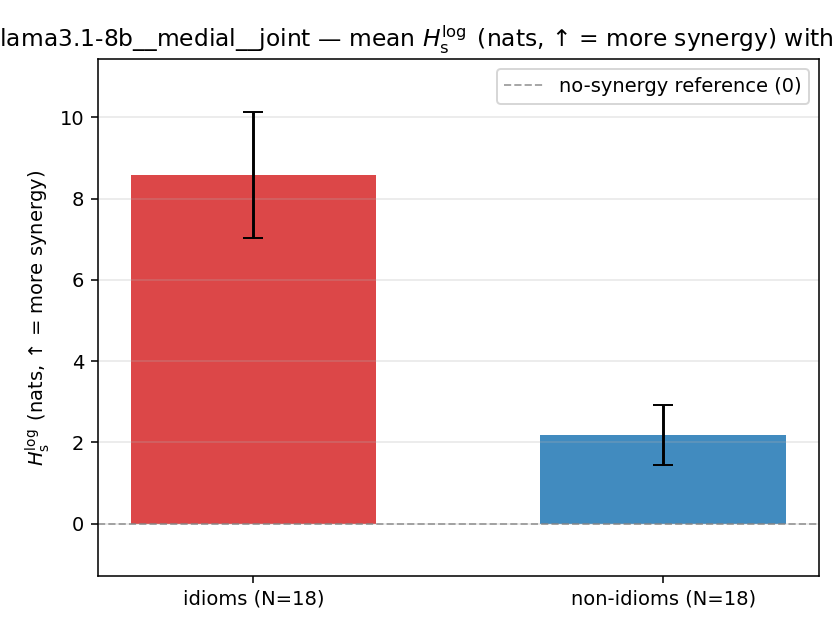 | 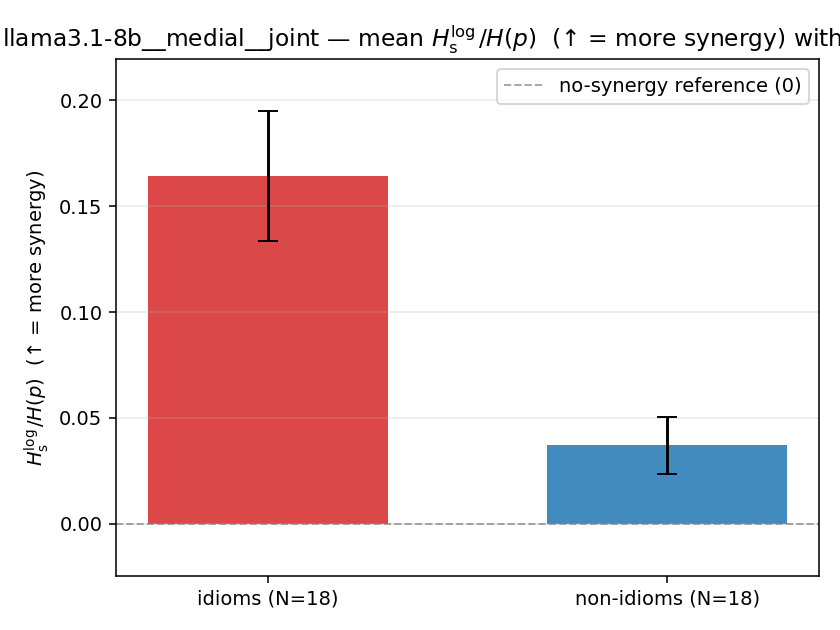 | 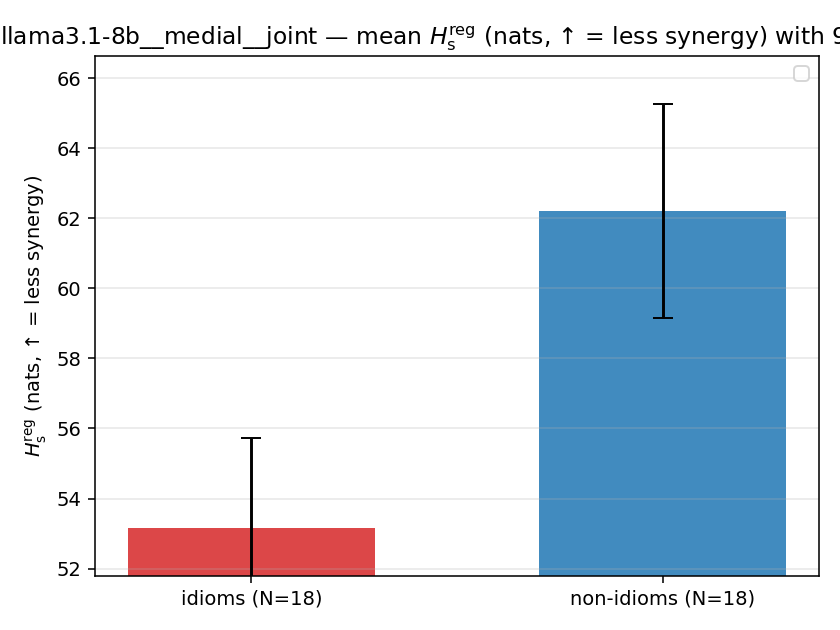 | 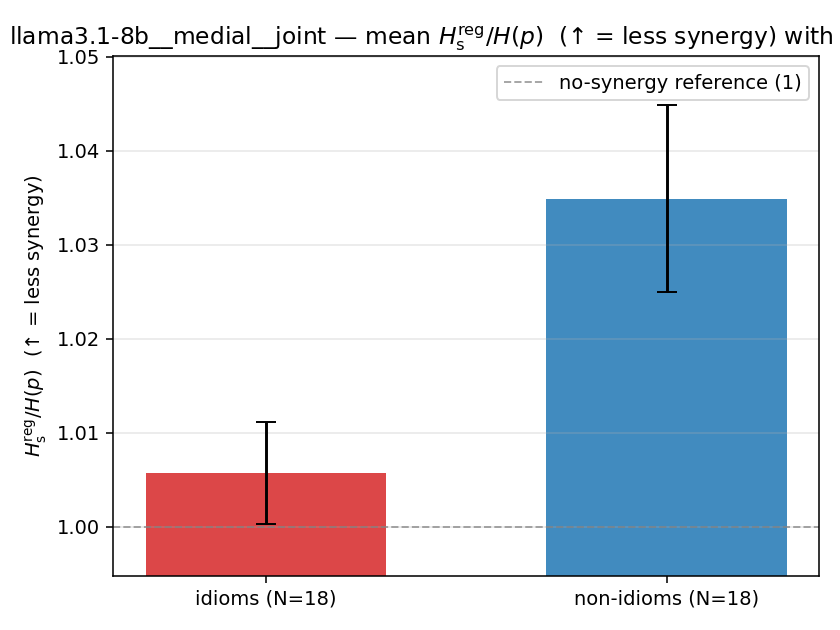 | 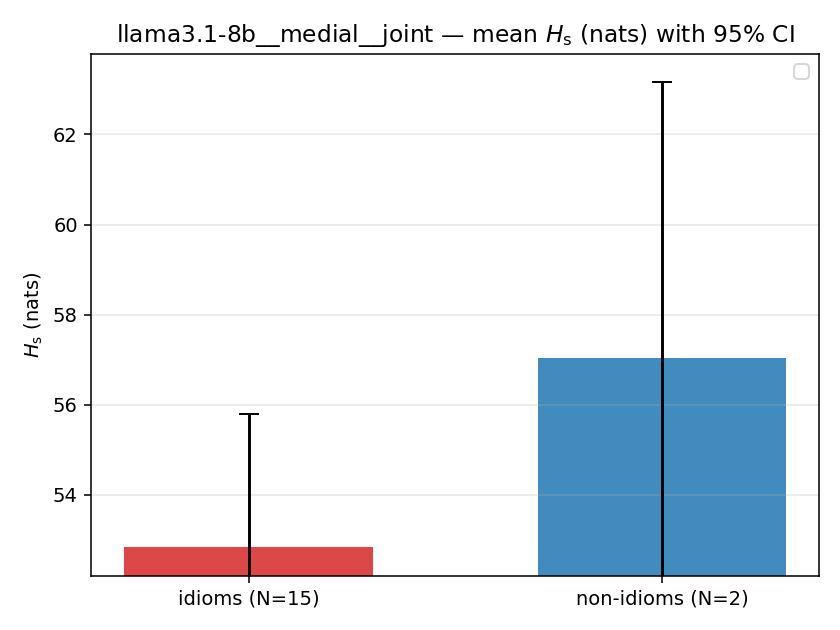 | 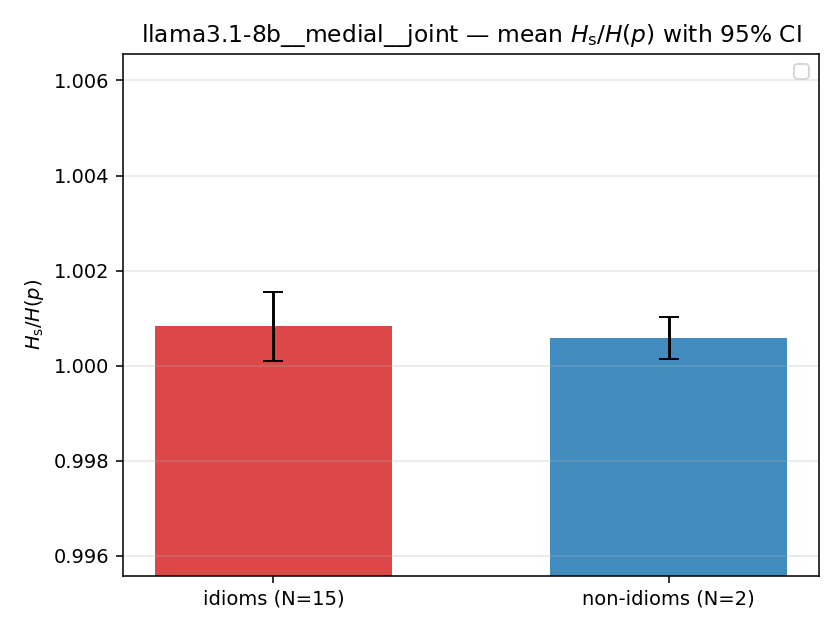 |
| per-idiom (sorted) | 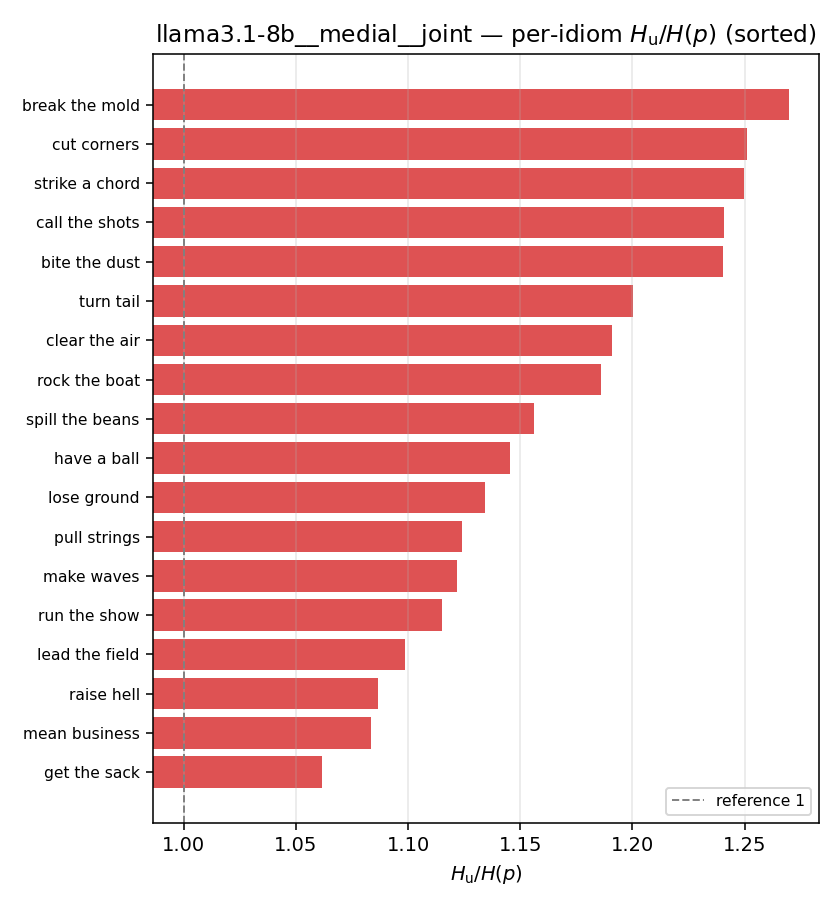 | 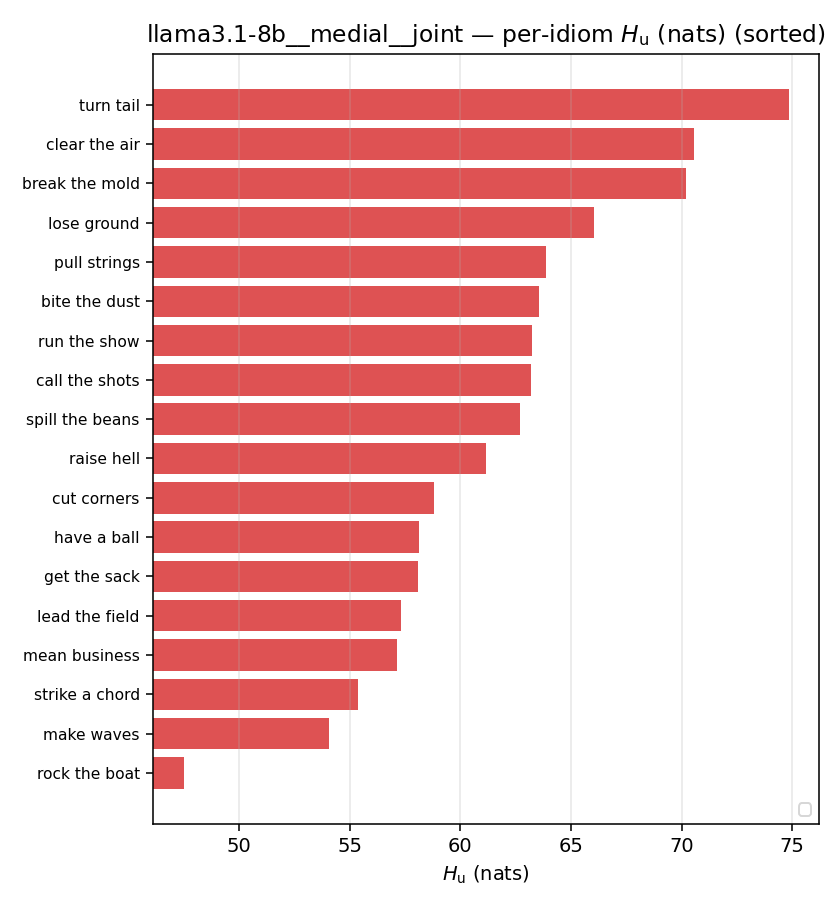 | 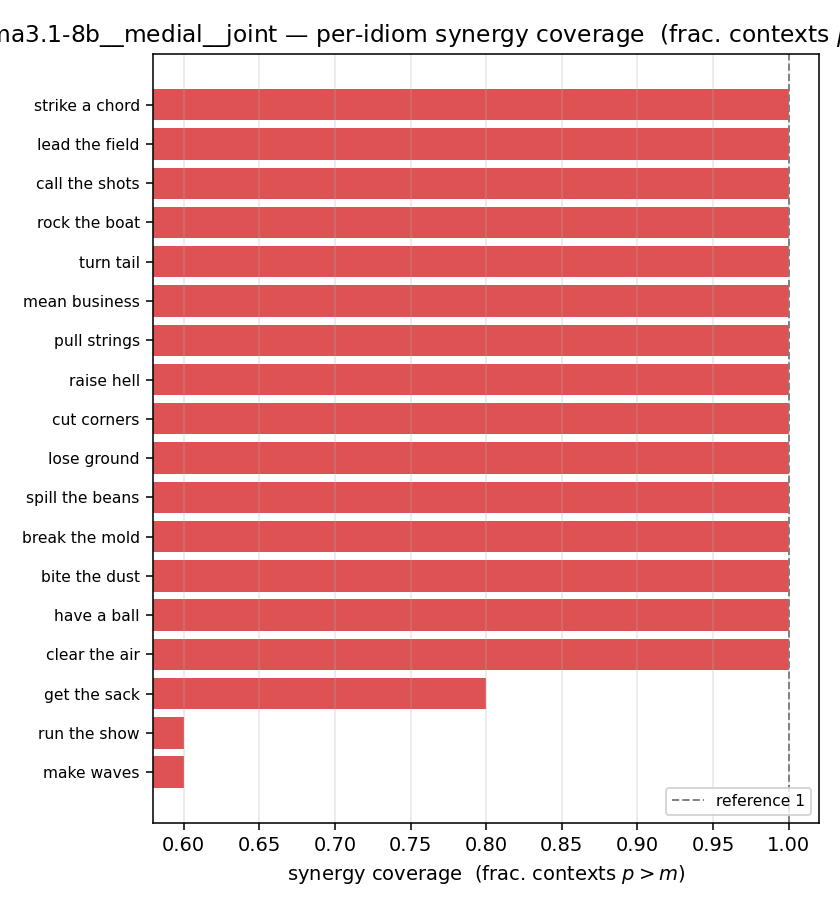 | 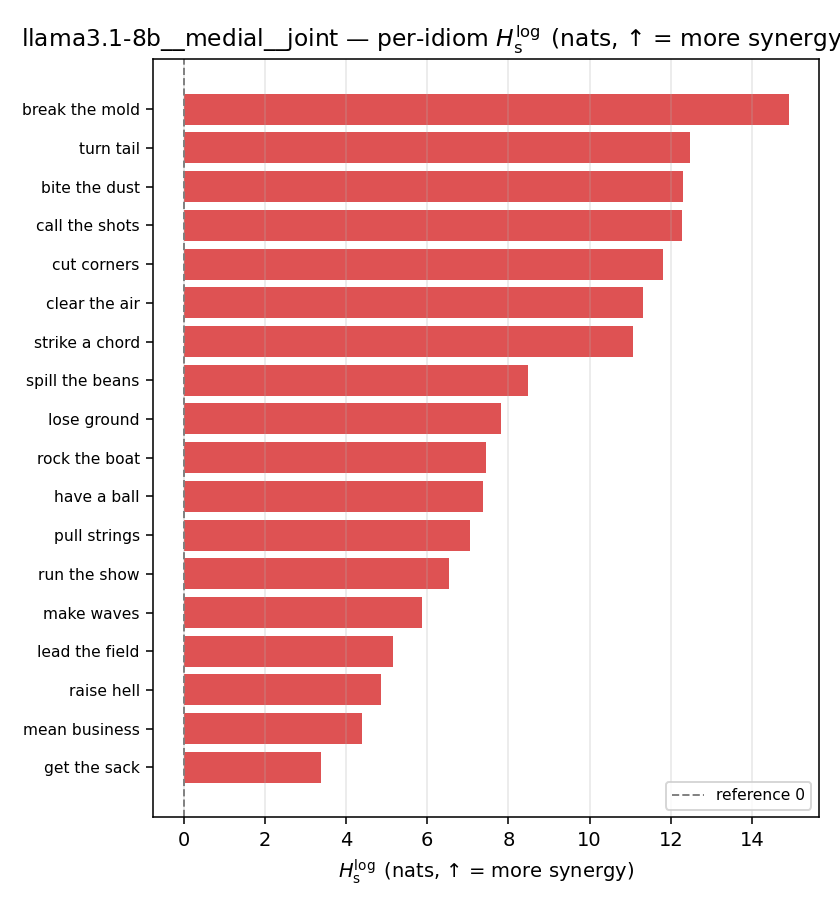 | 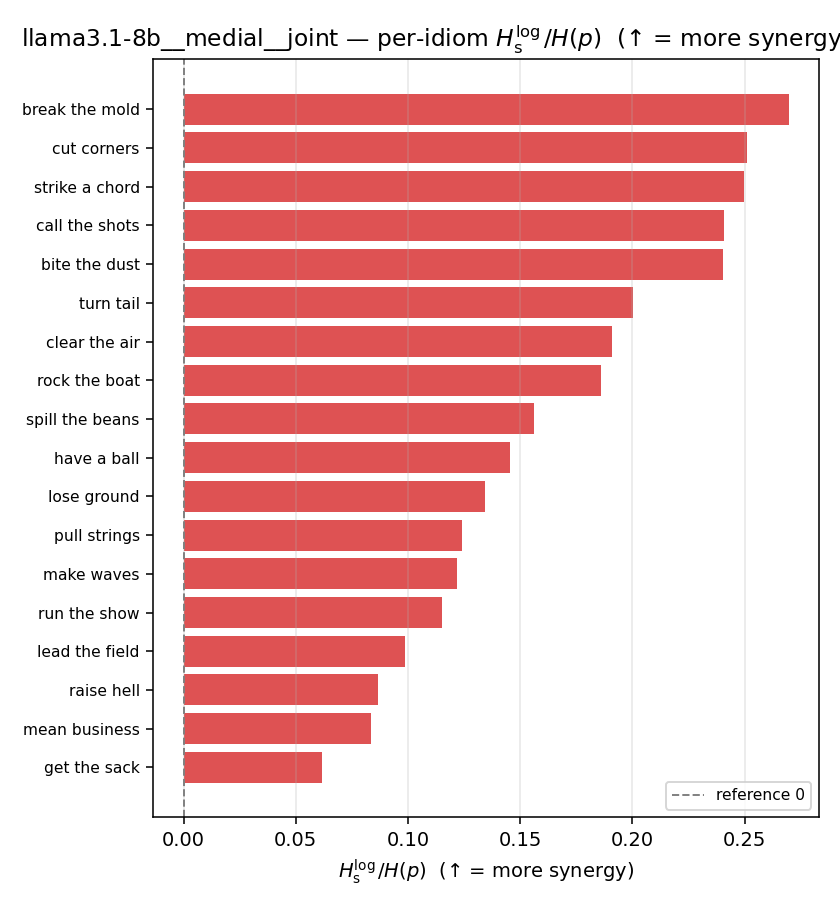 | 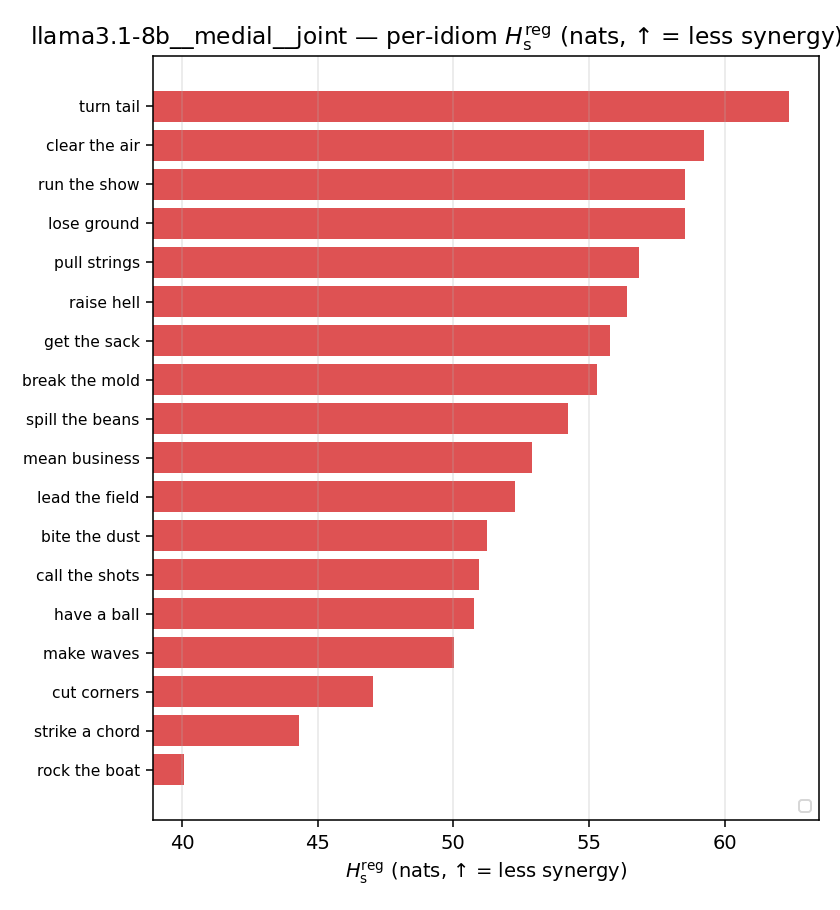 | 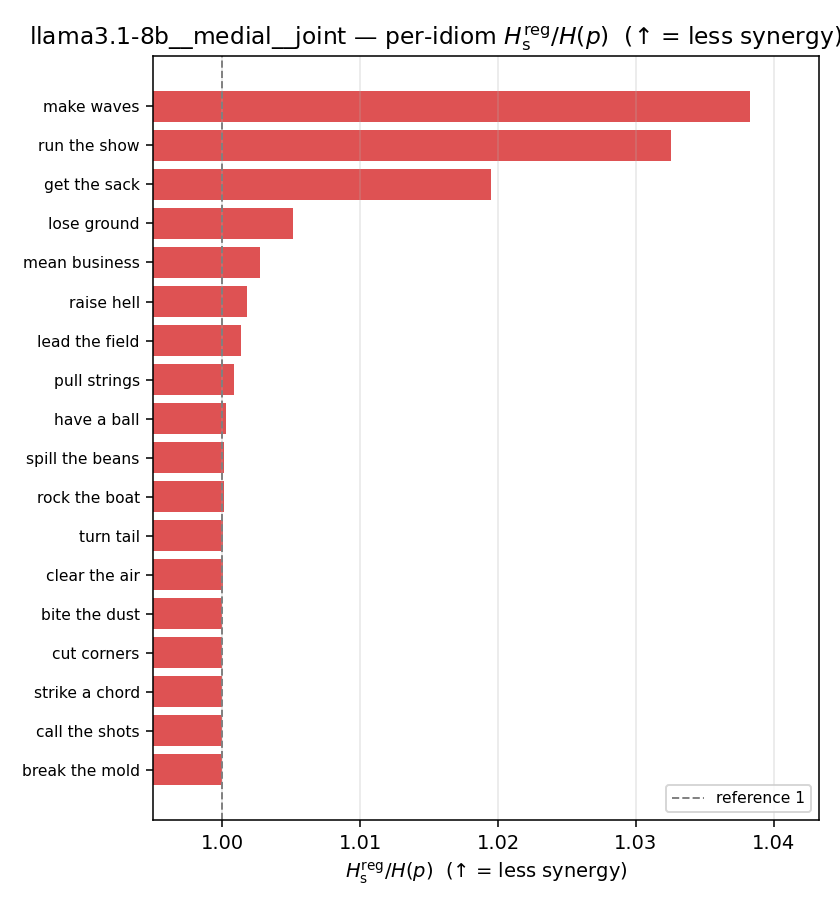 | 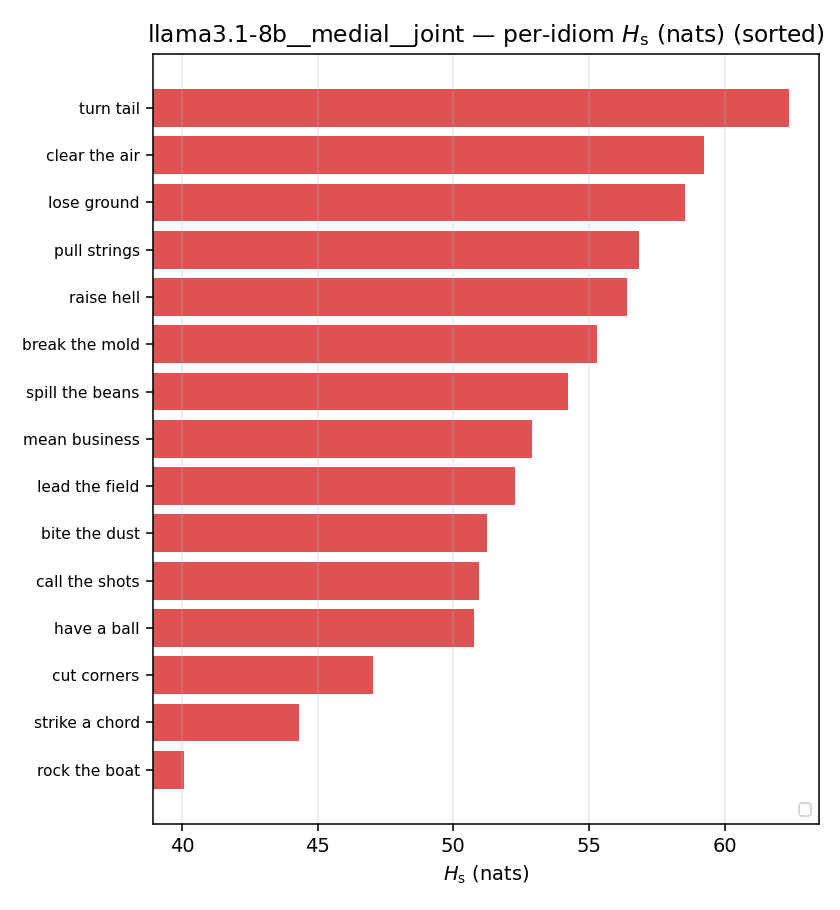 | 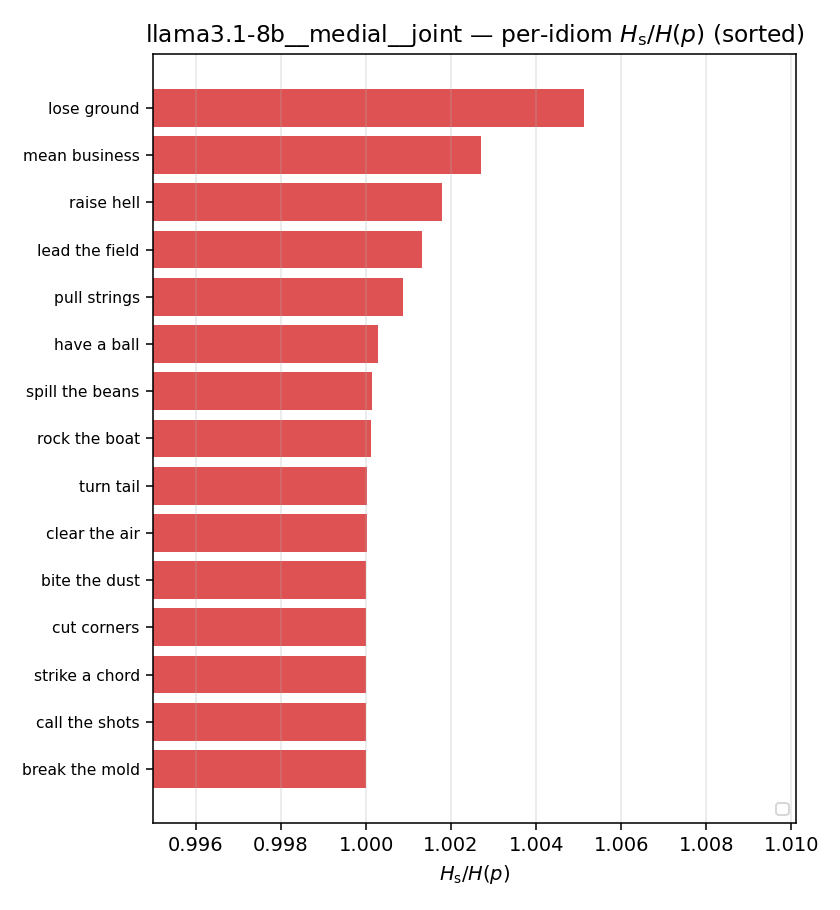 |
llama3.1-8b · full · geo llama3.1-8b__full__geo
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 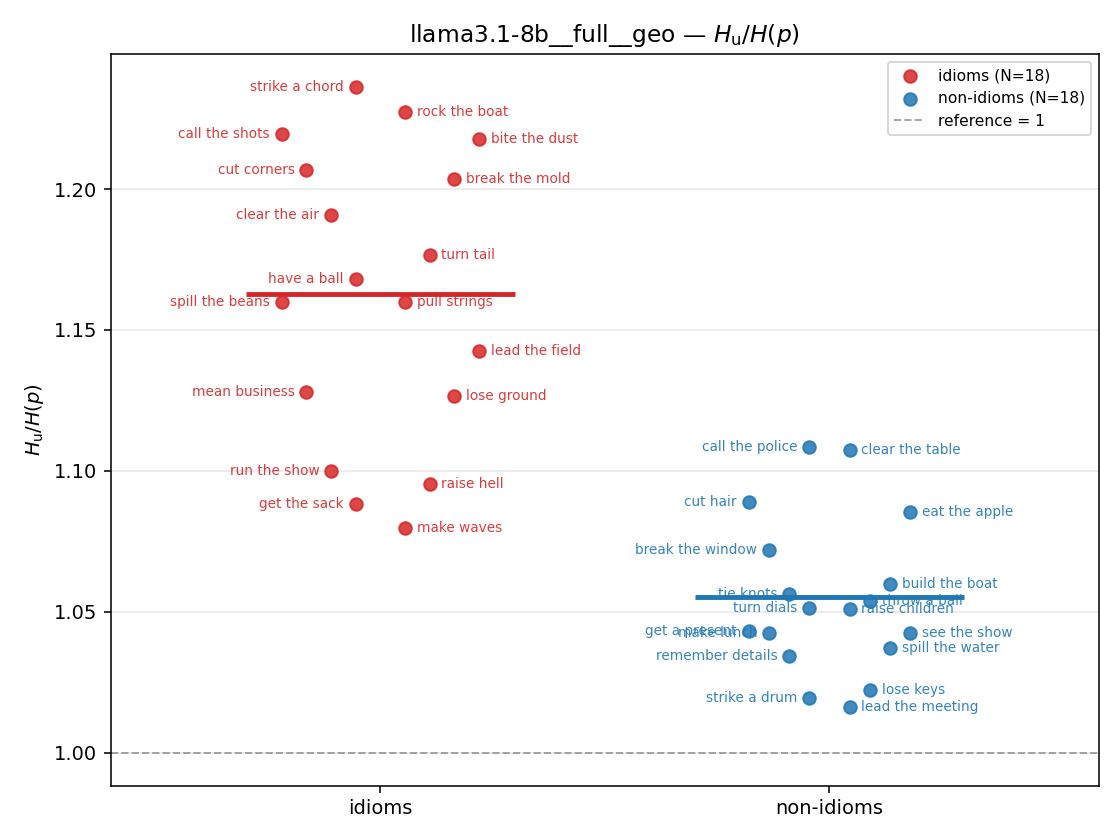 | 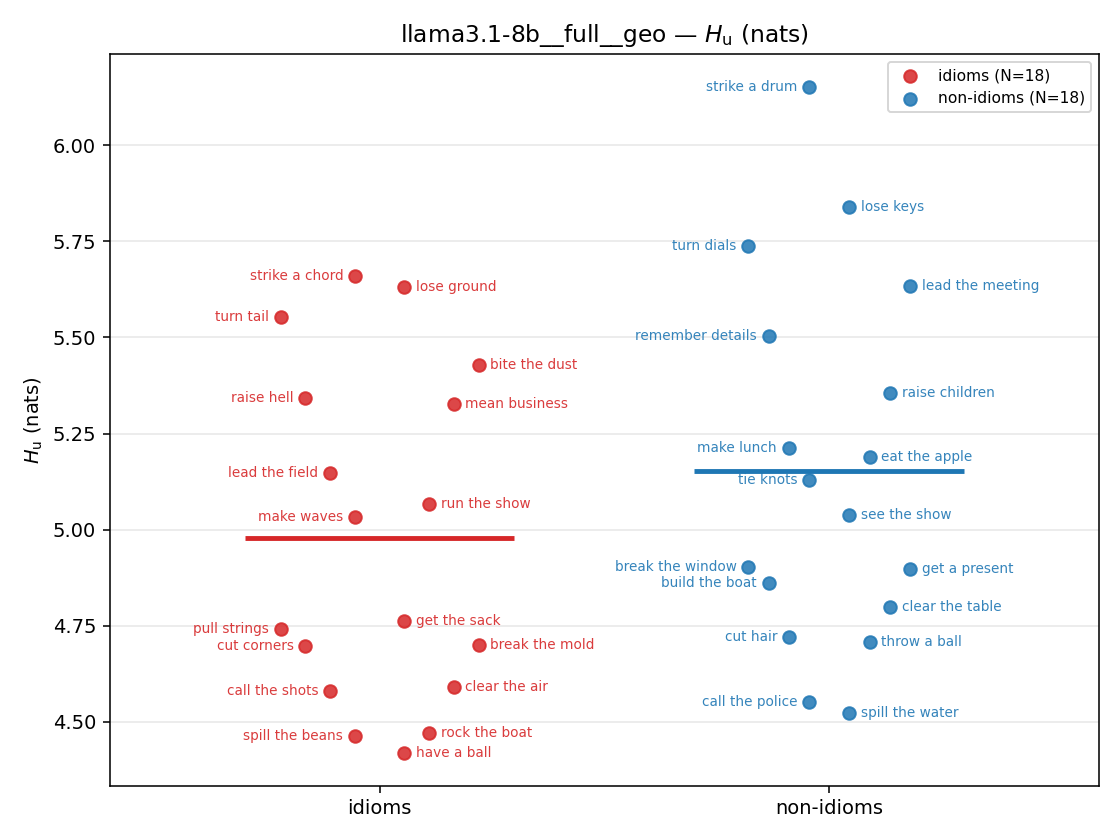 | 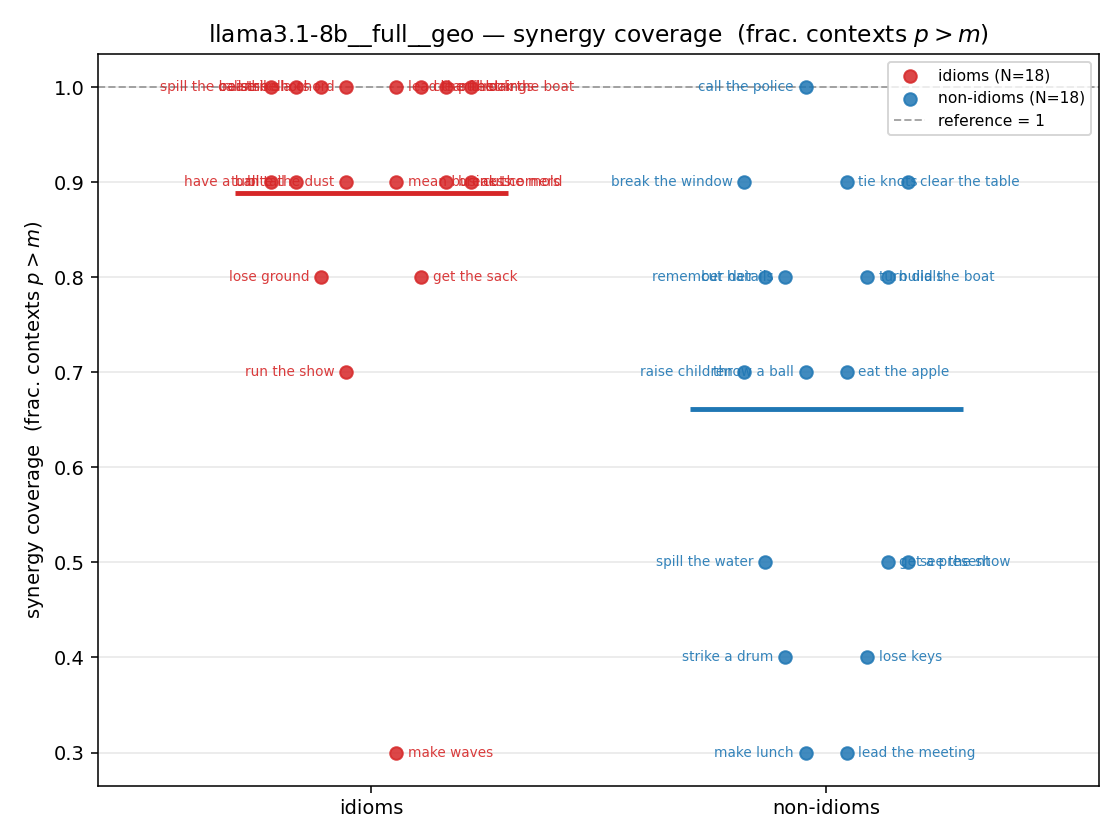 | 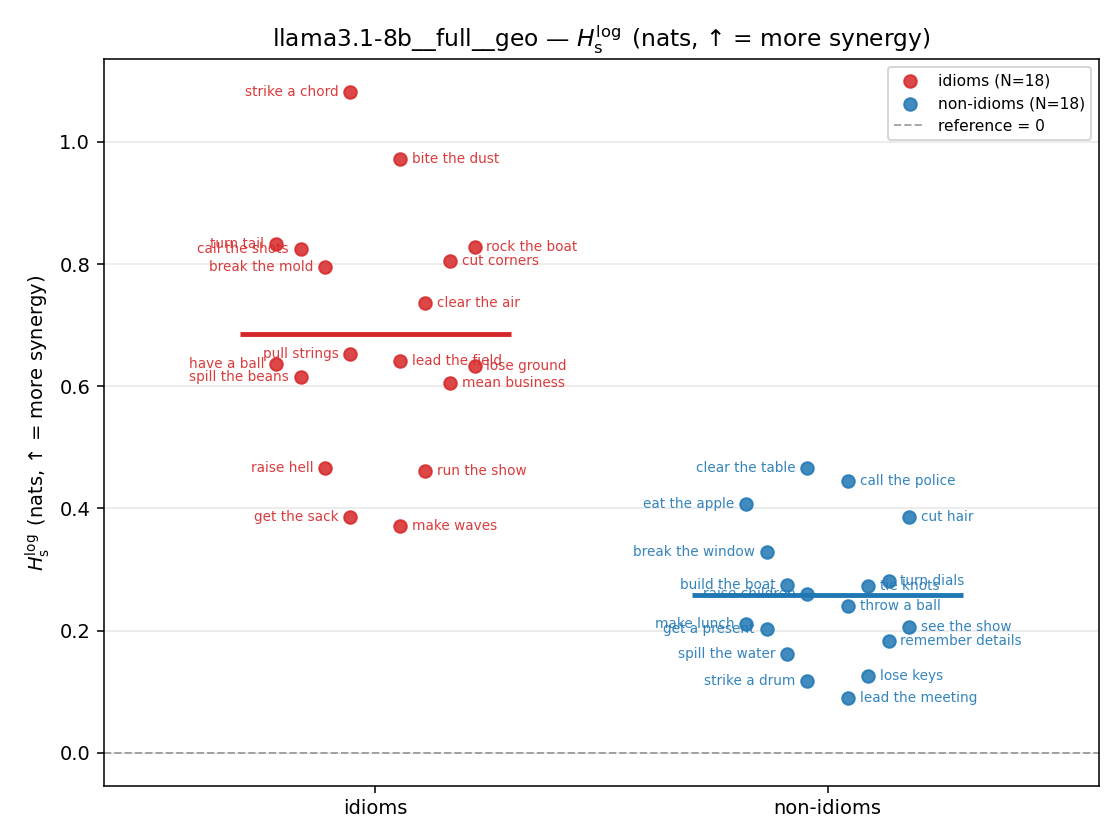 | 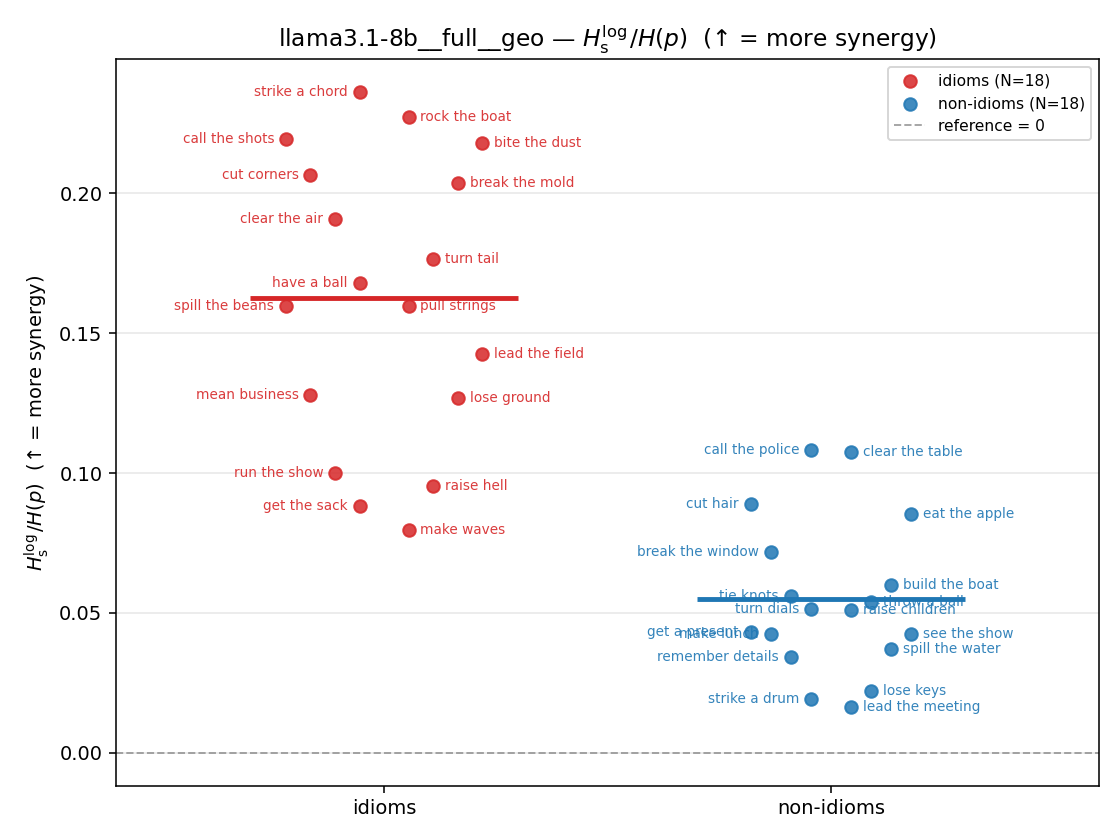 | 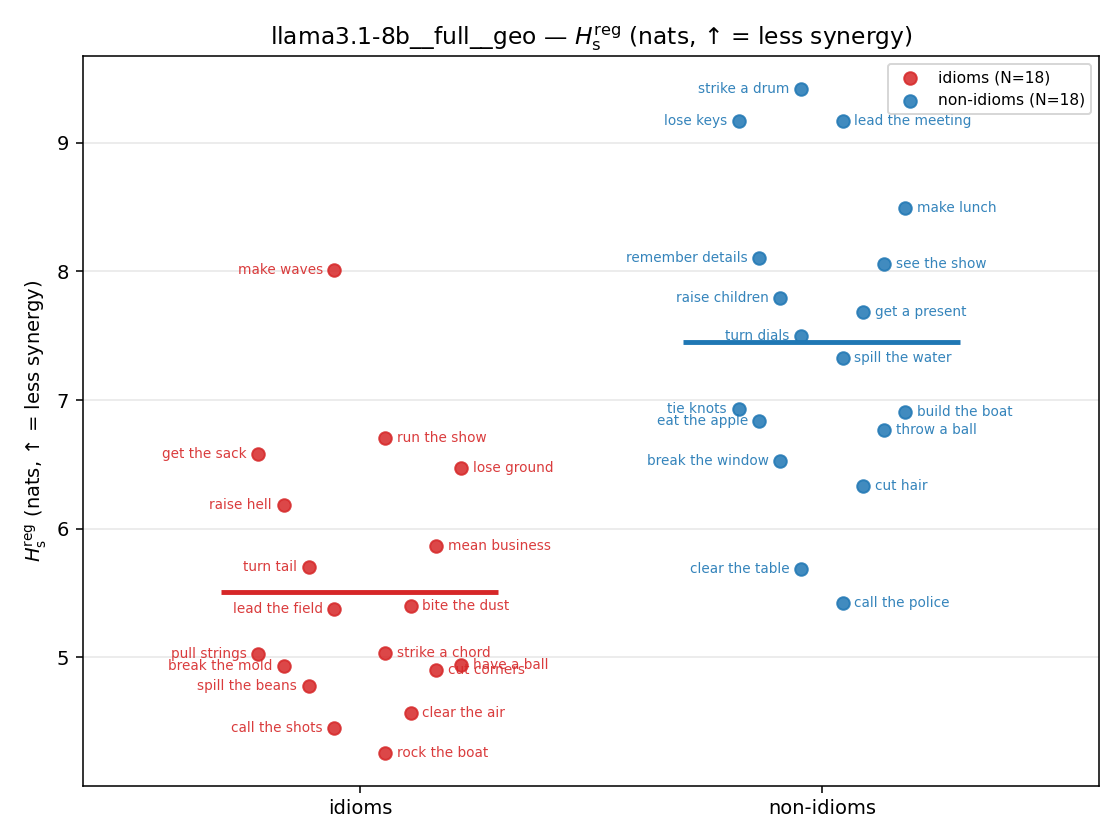 | 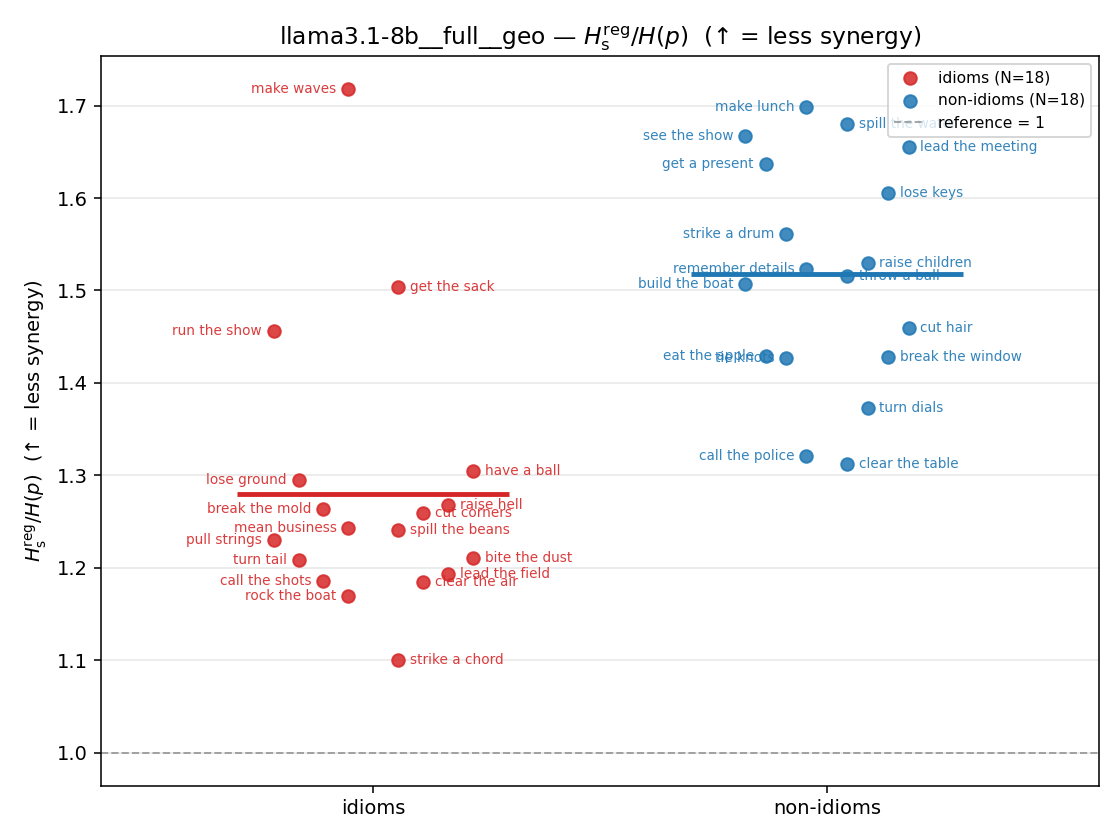 | 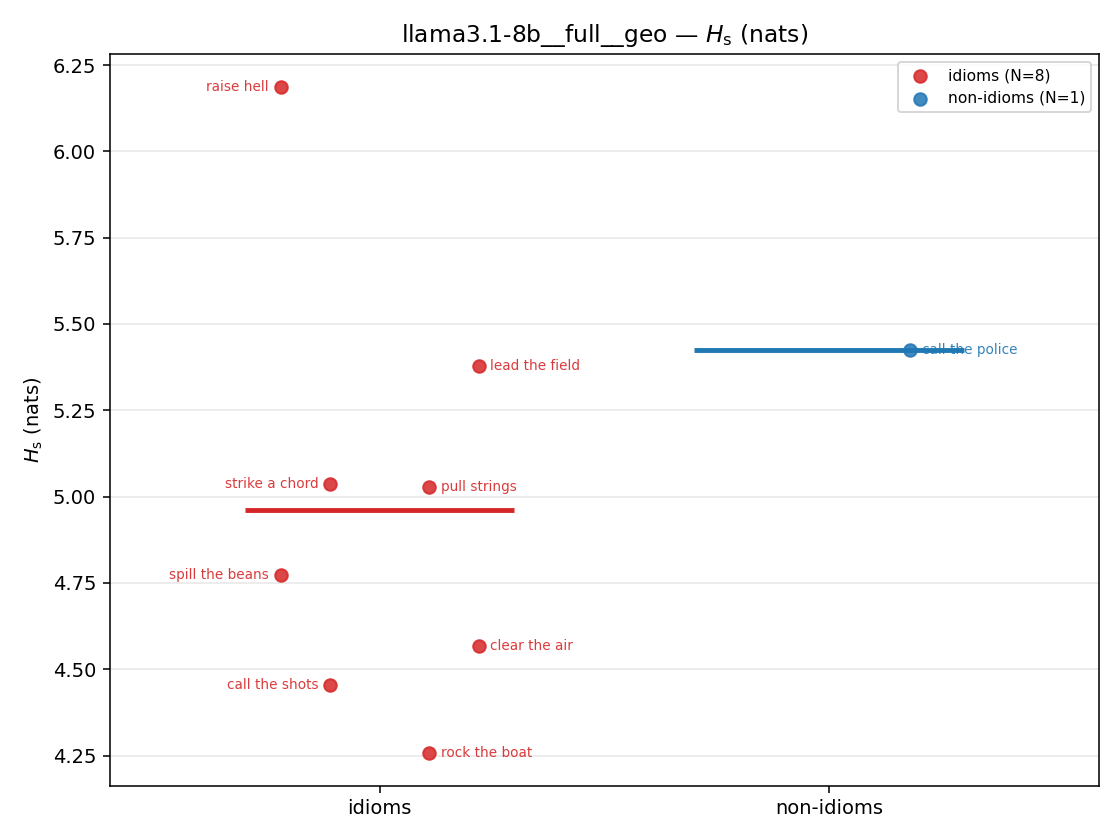 | 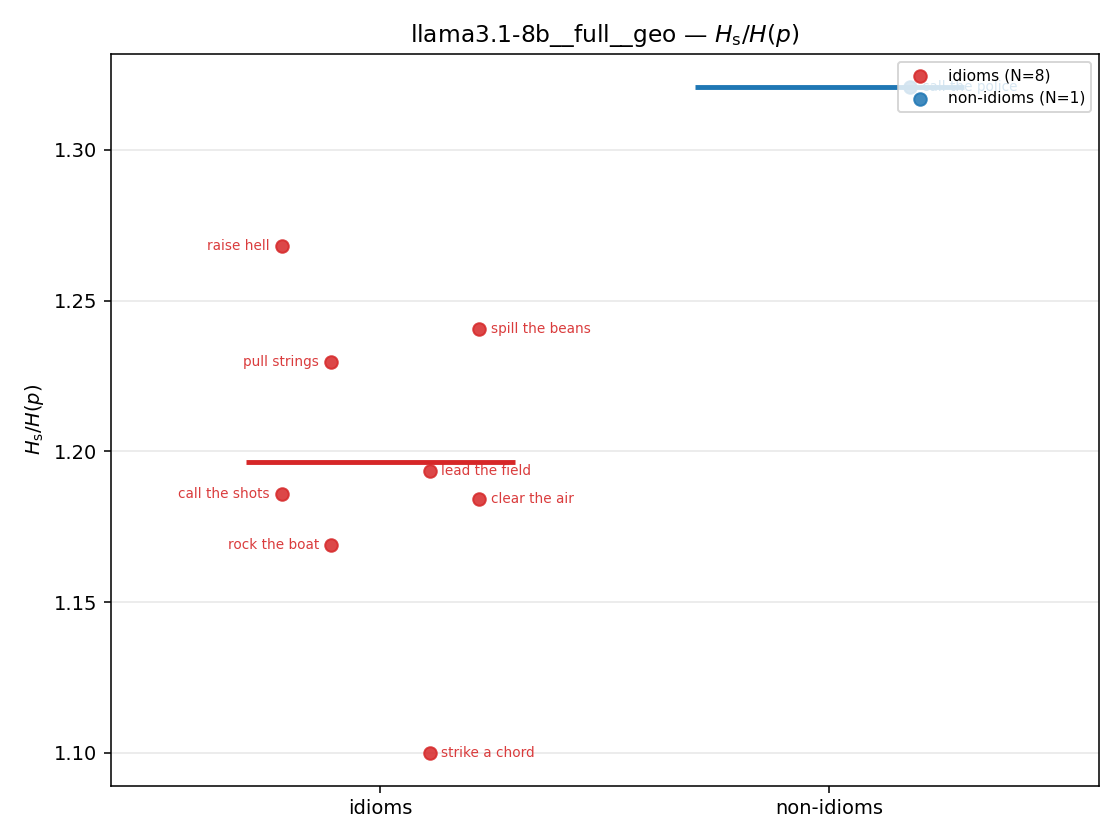 |
| mean ± 95% CI | 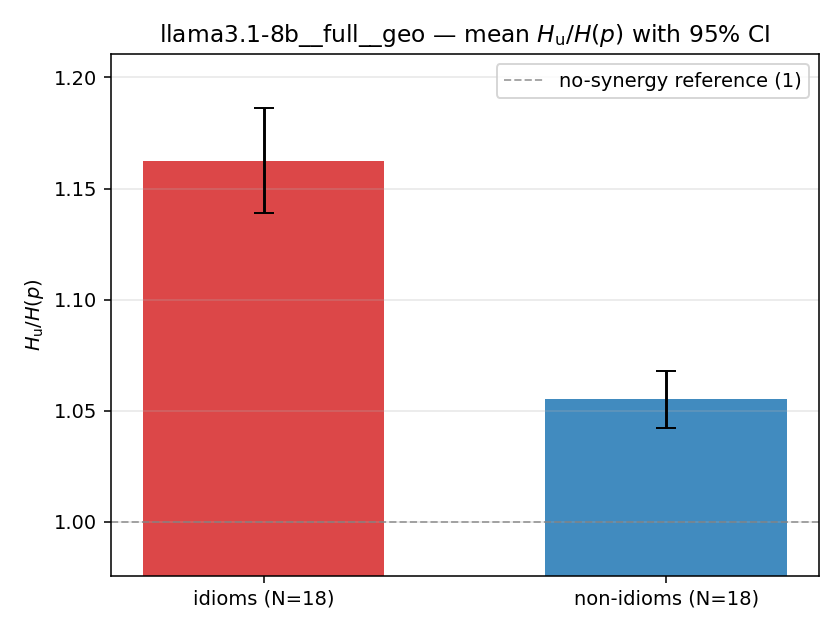 | 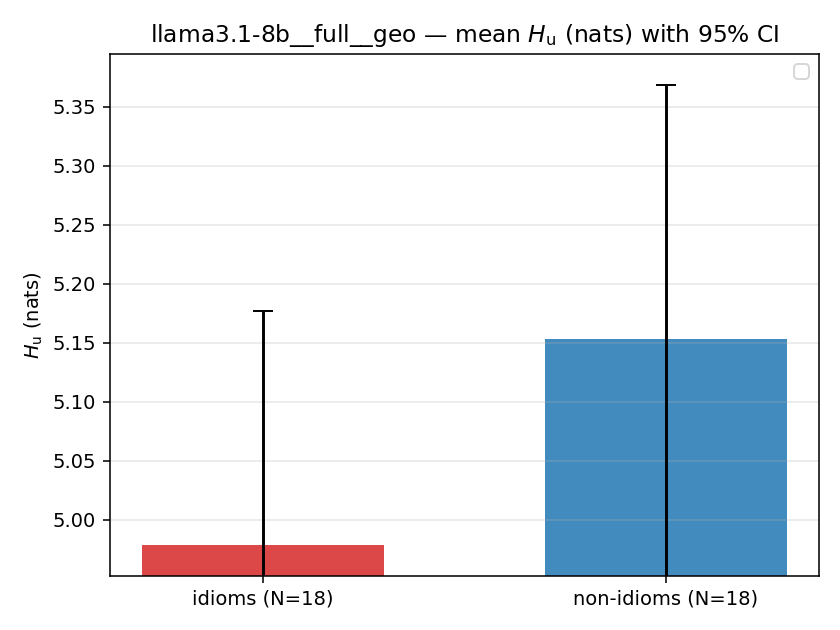 | 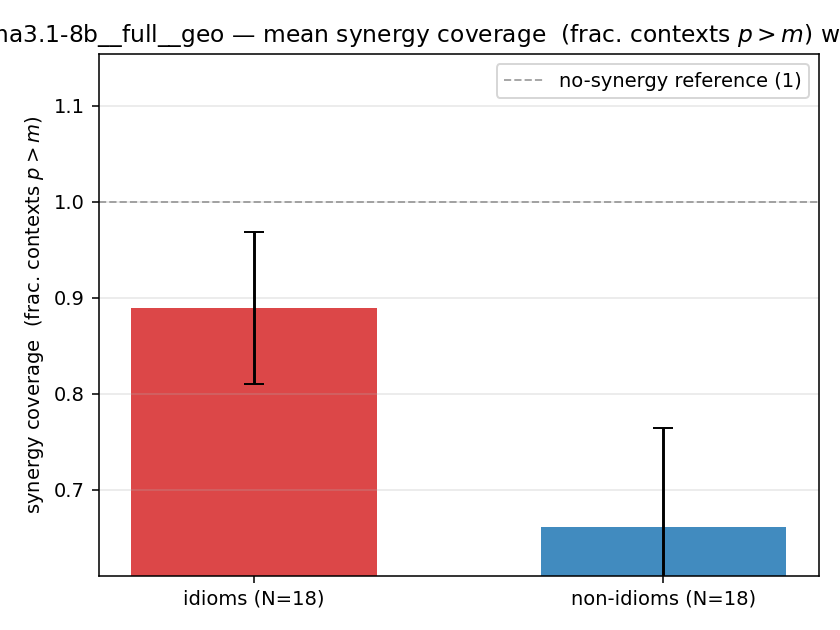 | 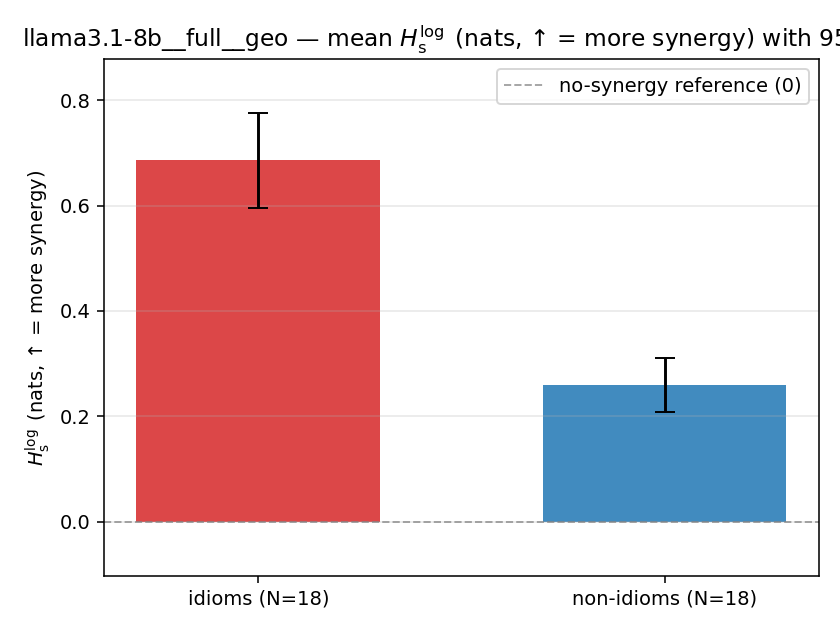 | 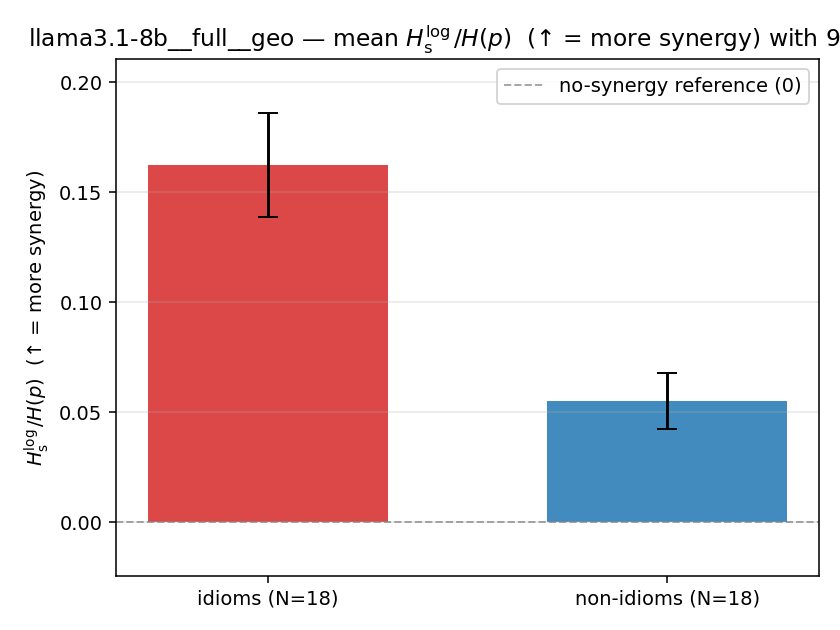 | 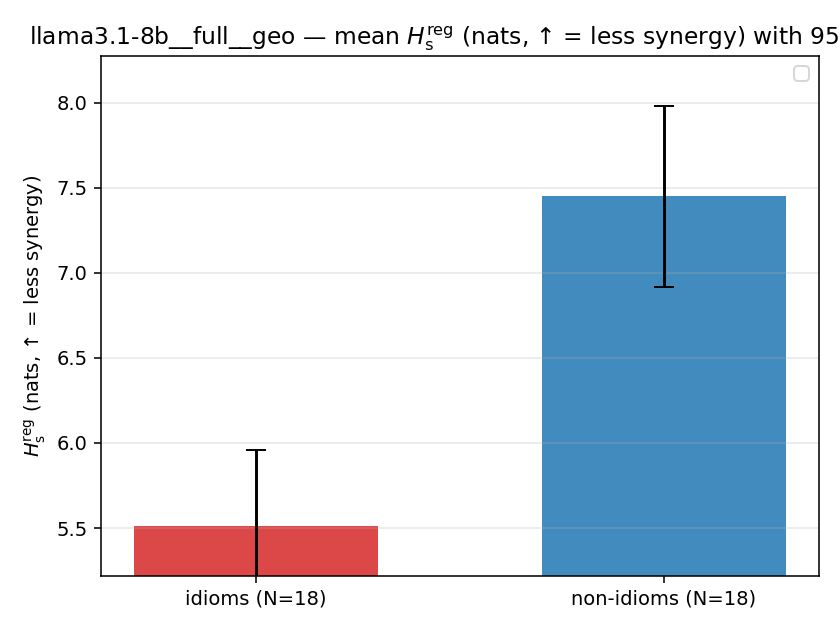 | 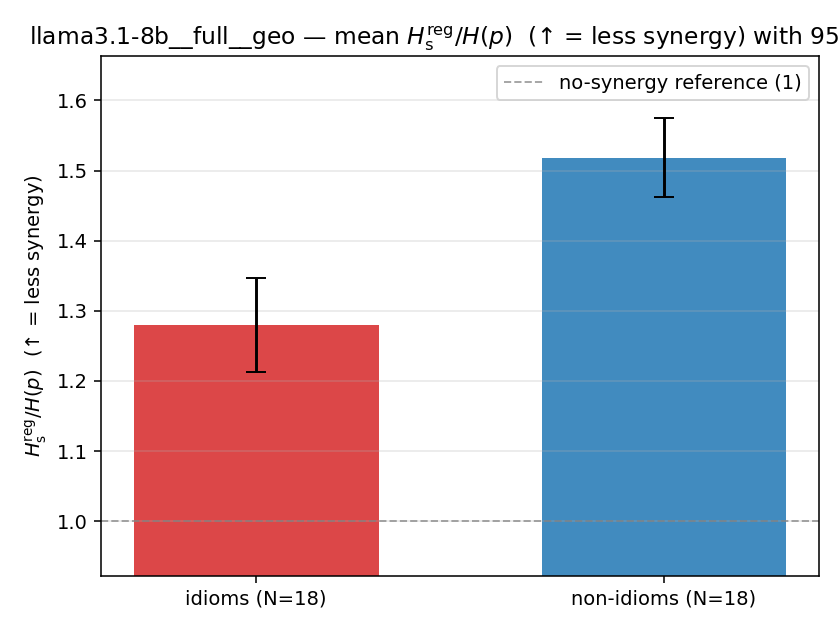 | 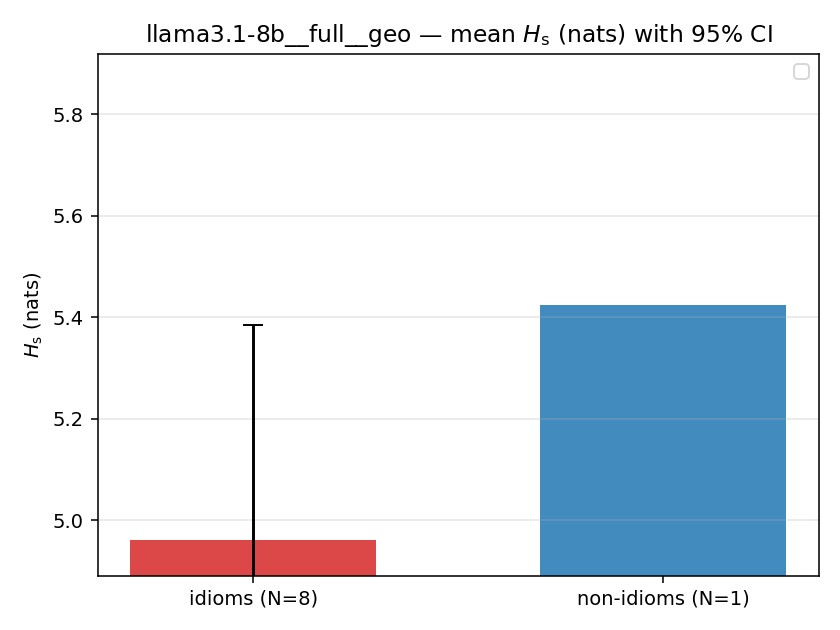 | 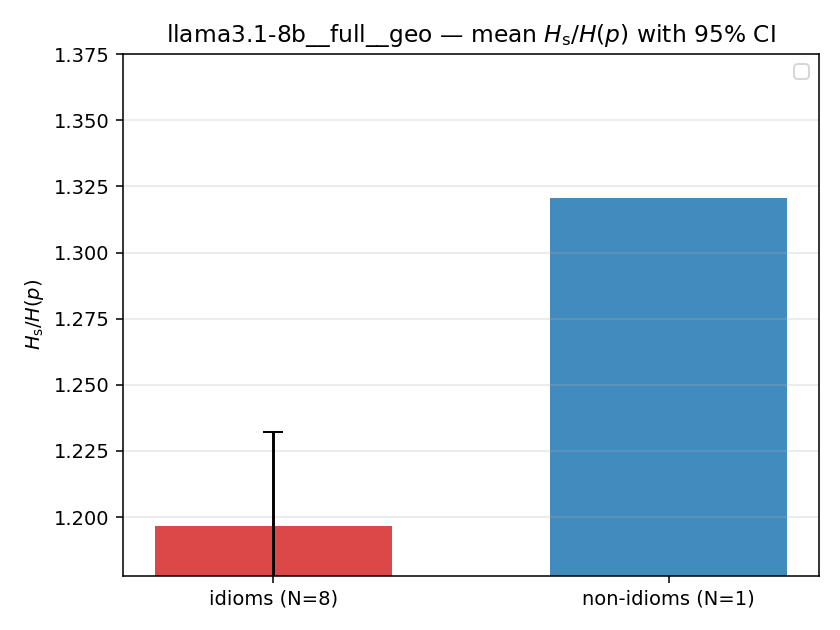 |
| per-idiom (sorted) | 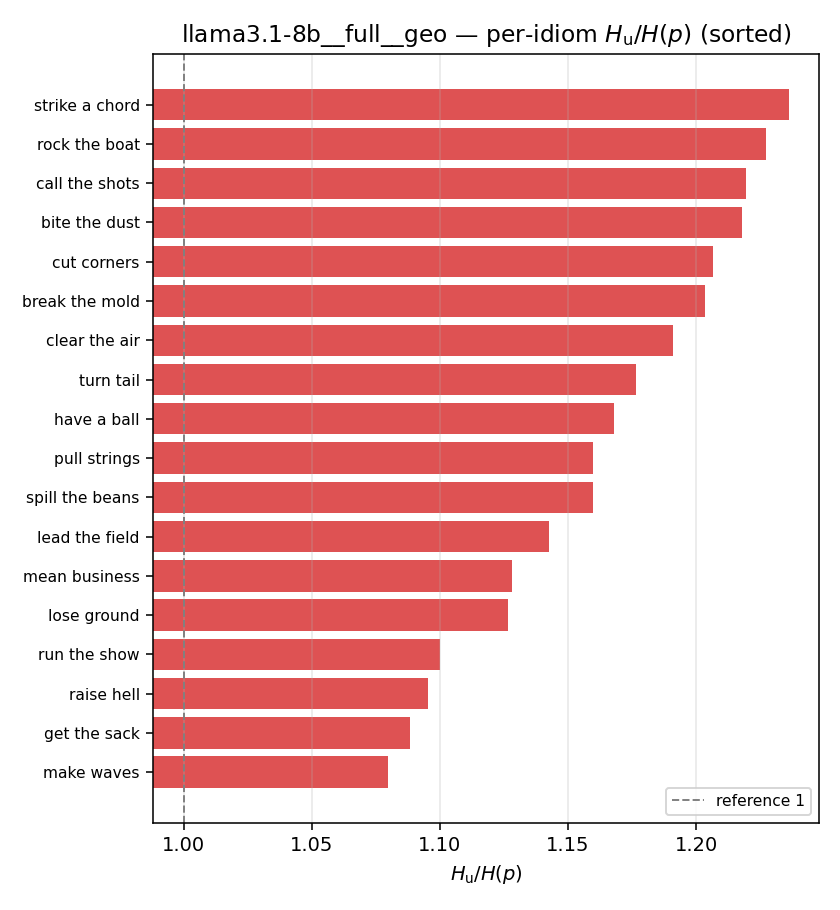 | 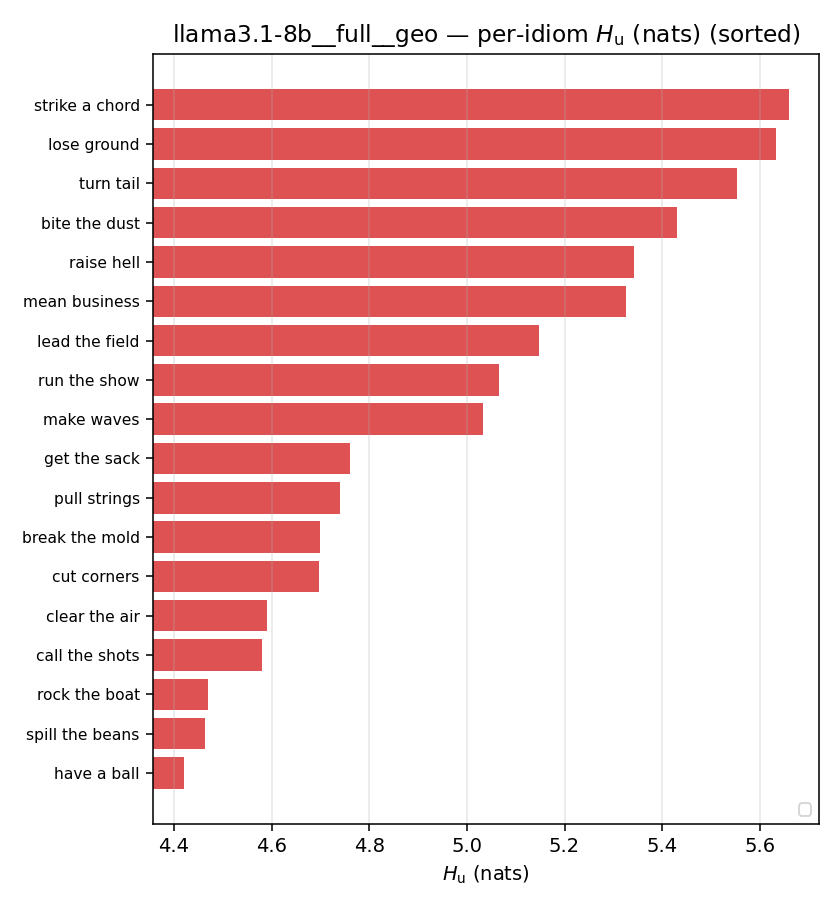 | 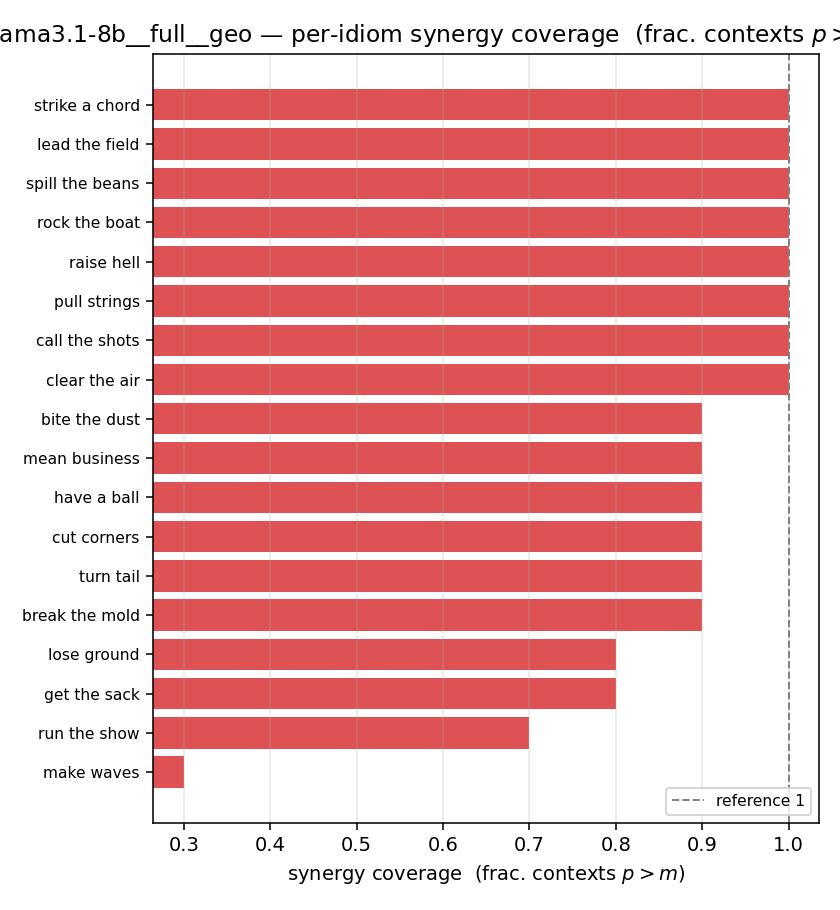 | 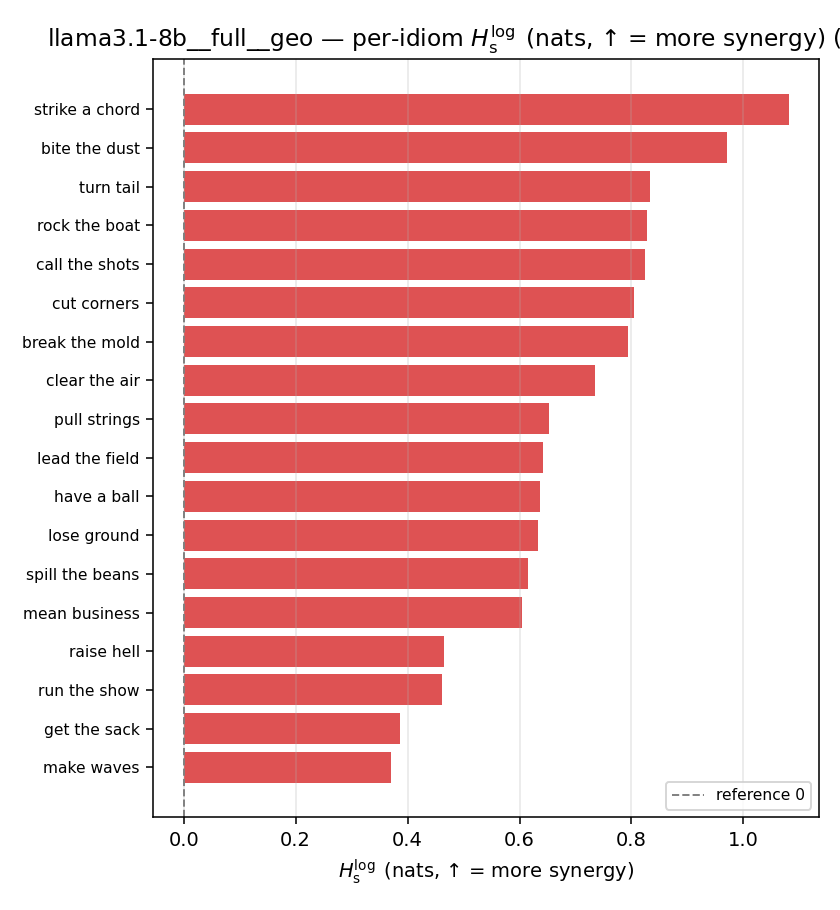 | 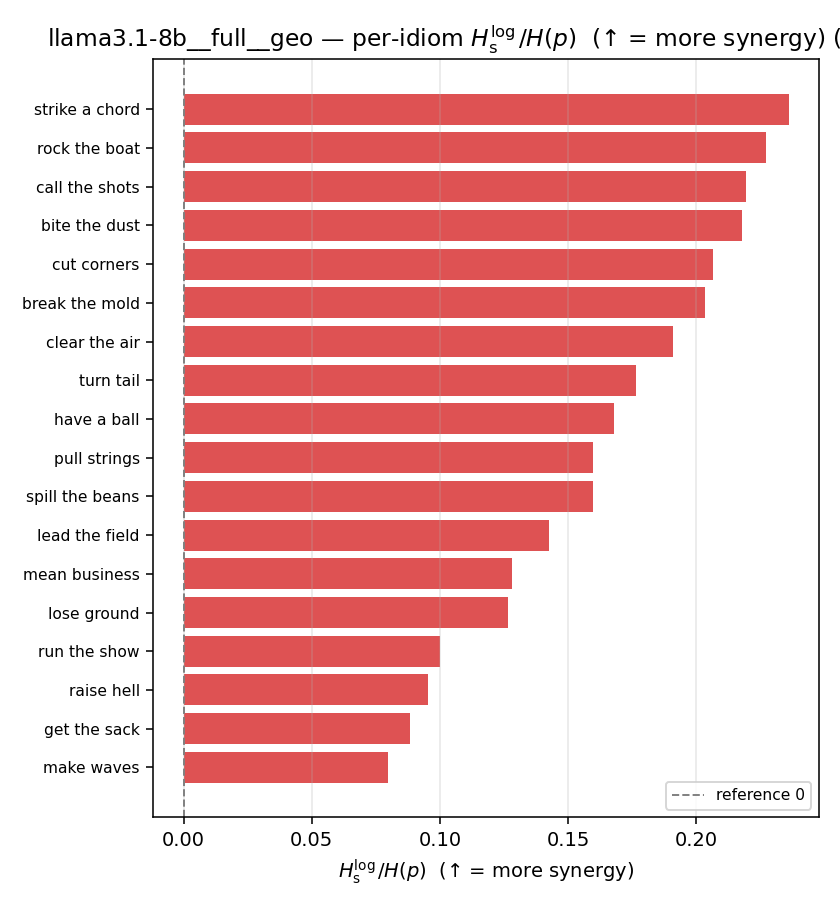 | 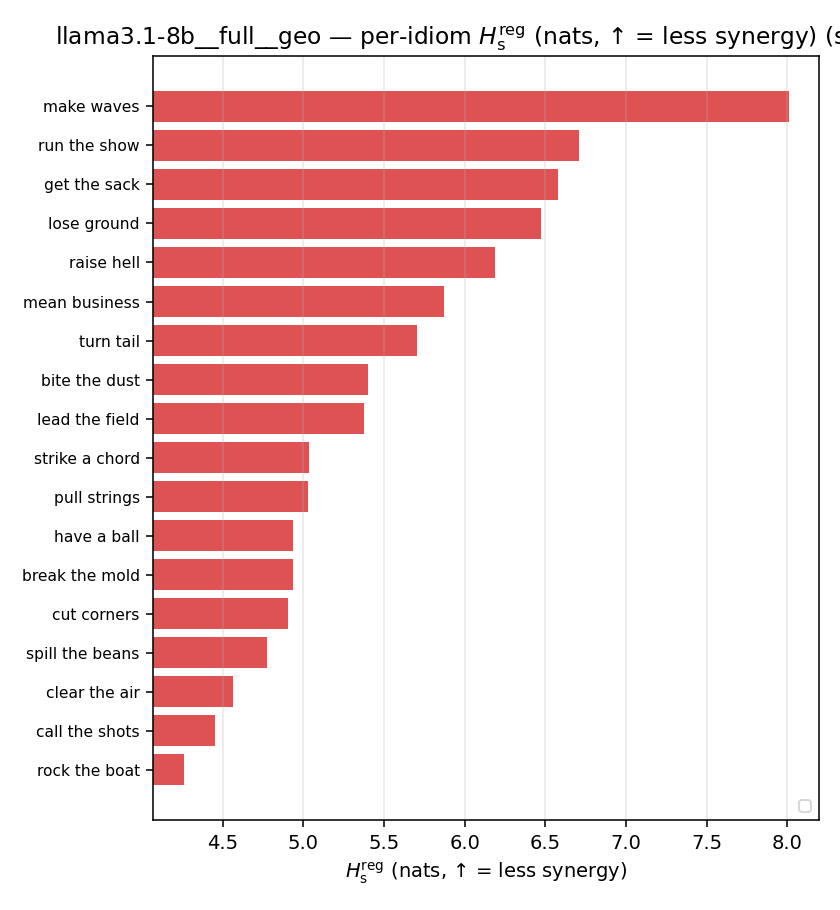 | 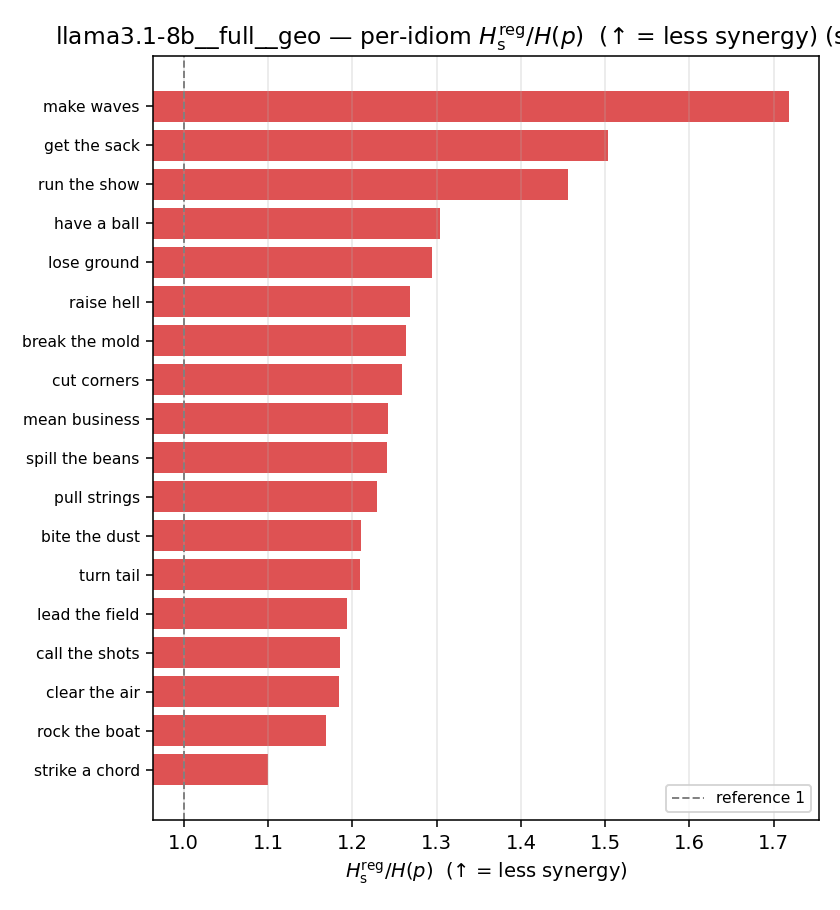 | 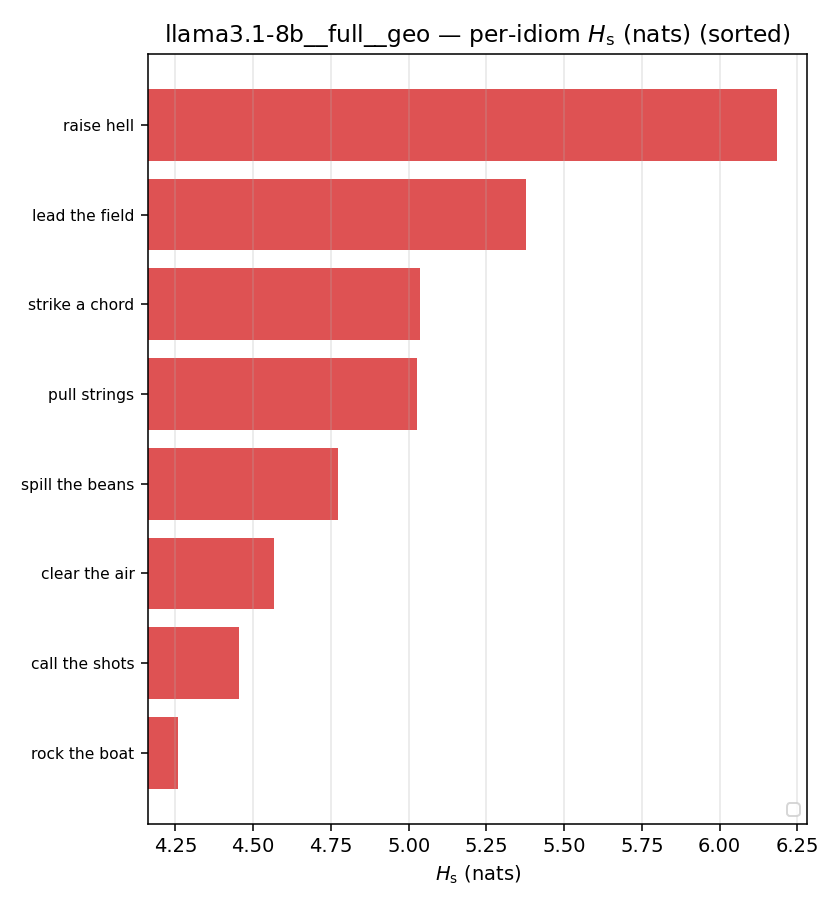 | 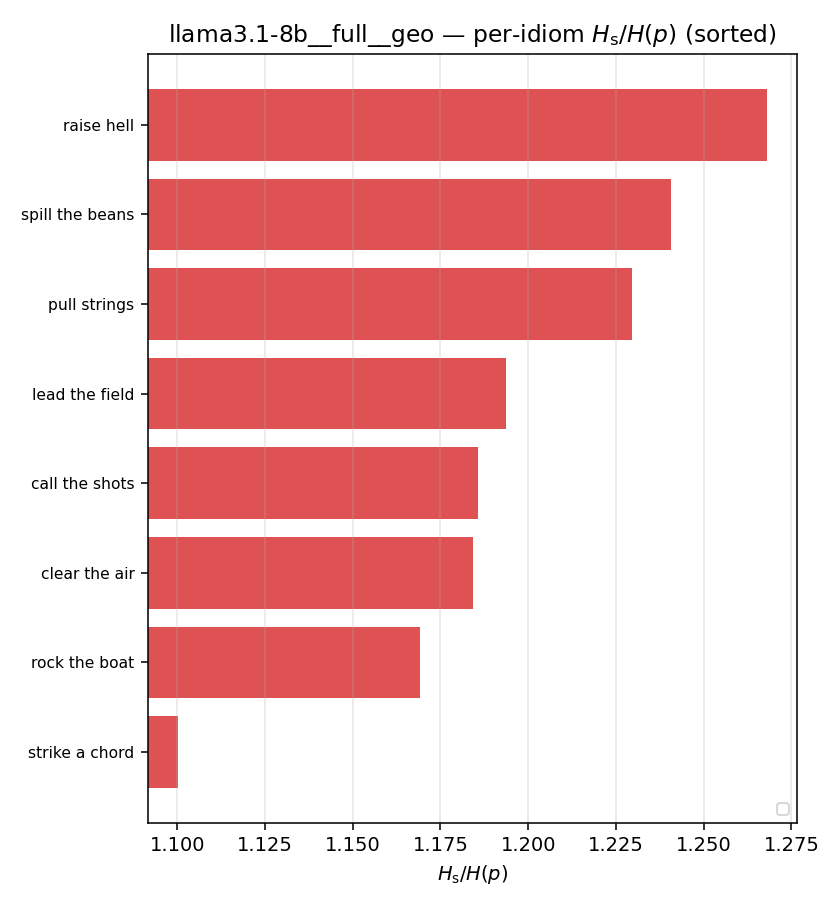 |
llama3.1-8b · full · joint llama3.1-8b__full__joint
| Hu/H ↑syn | Hu | syn_frac ↑syn | Hslog ↑syn | Hslog/H ↑syn | Hsreg ↓syn | Hsreg/H ↓syn | Hs orig | Hs/H orig | |
|---|---|---|---|---|---|---|---|---|---|
| strip (per-phrase) | 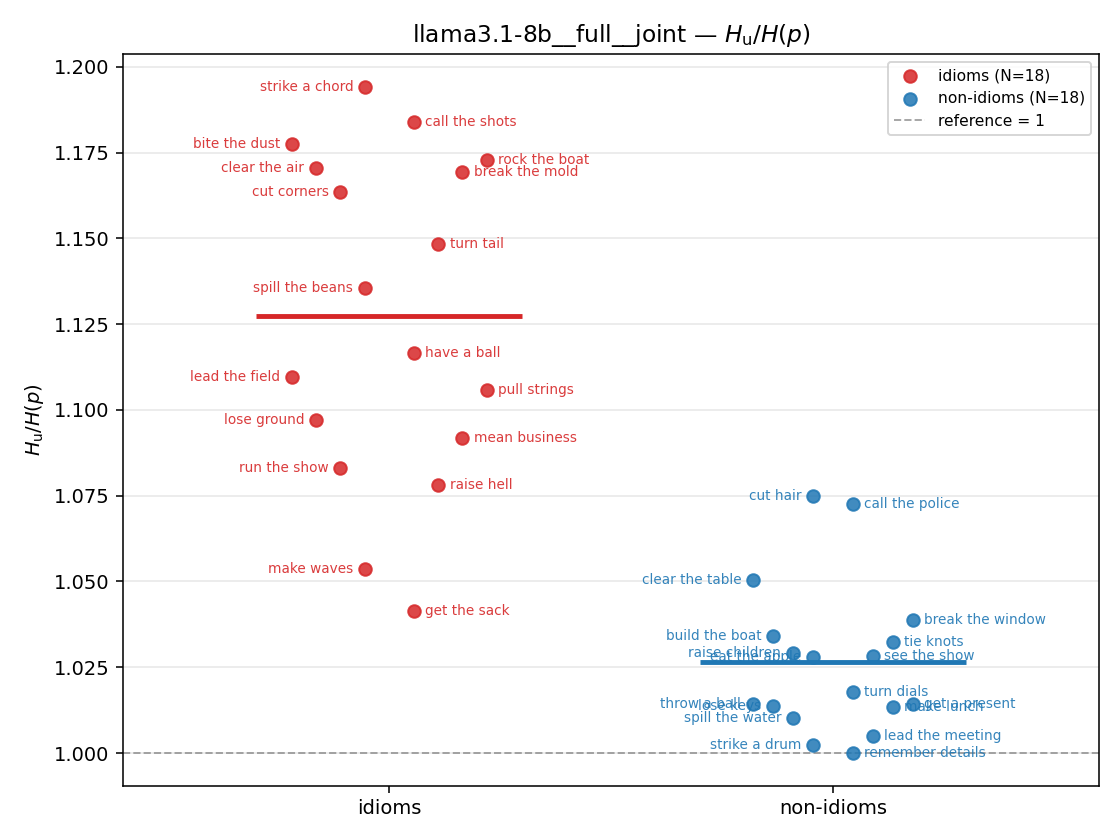 | 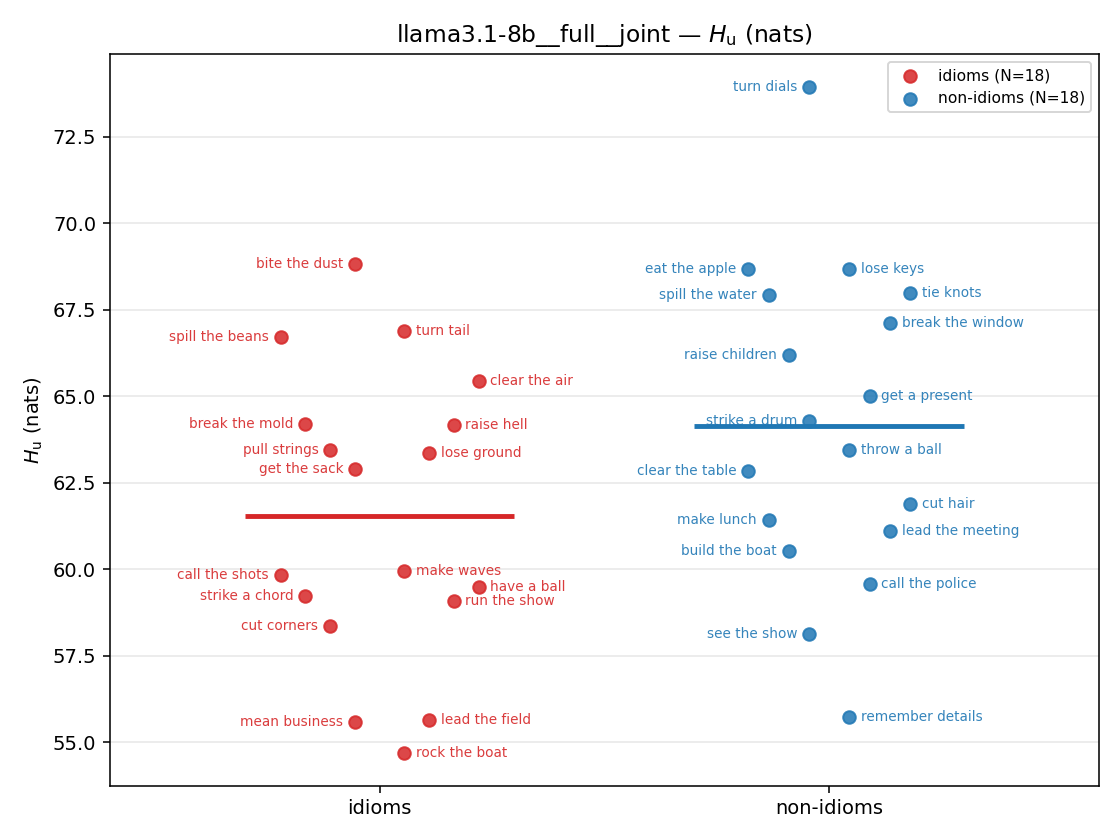 | 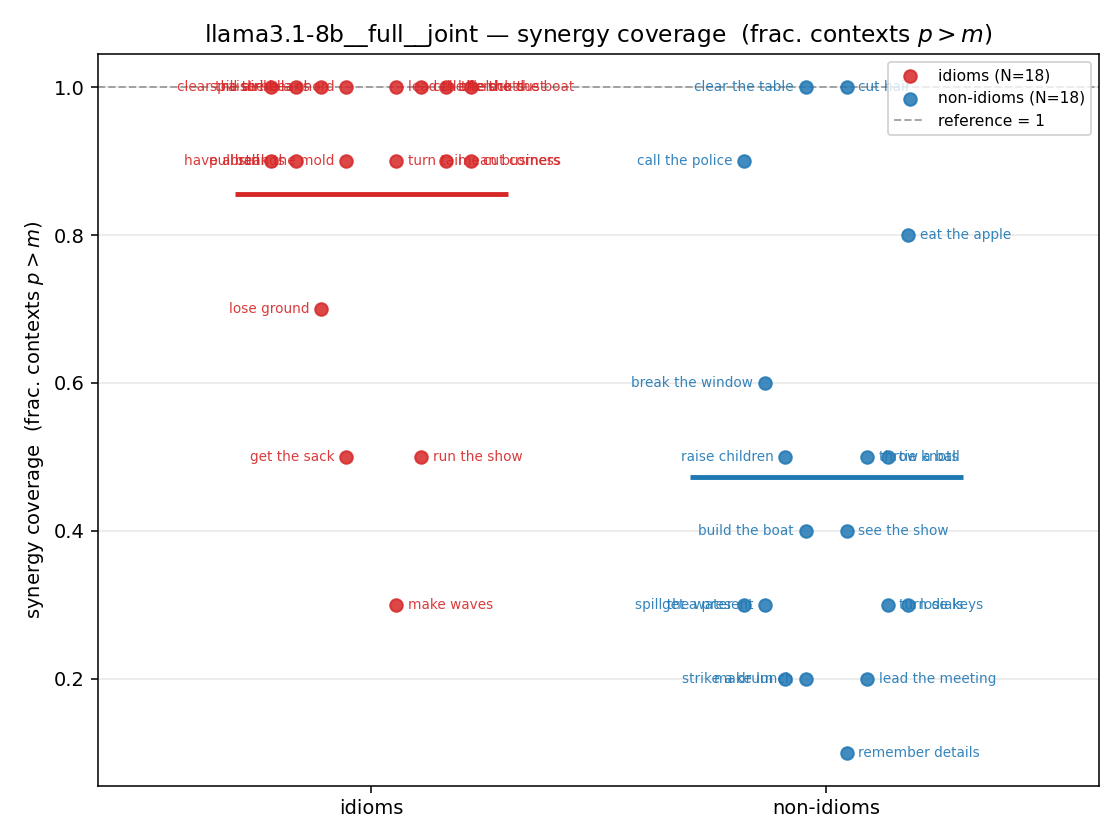 | 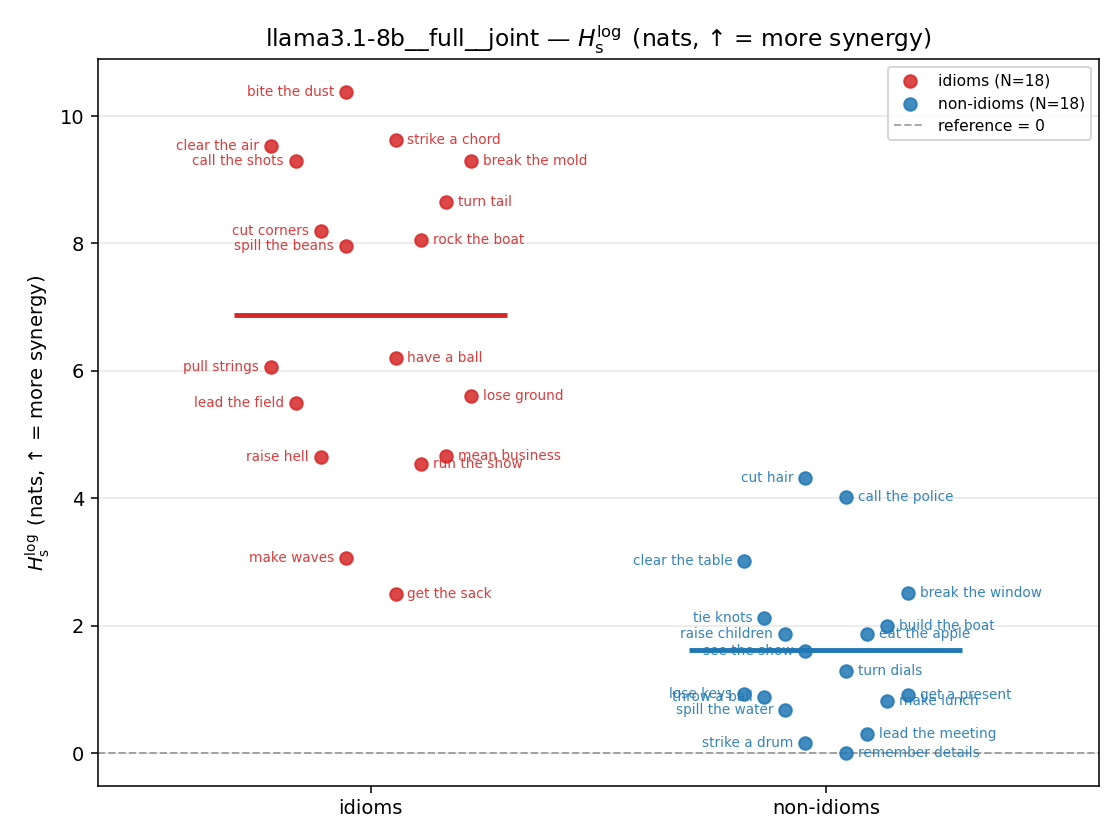 | 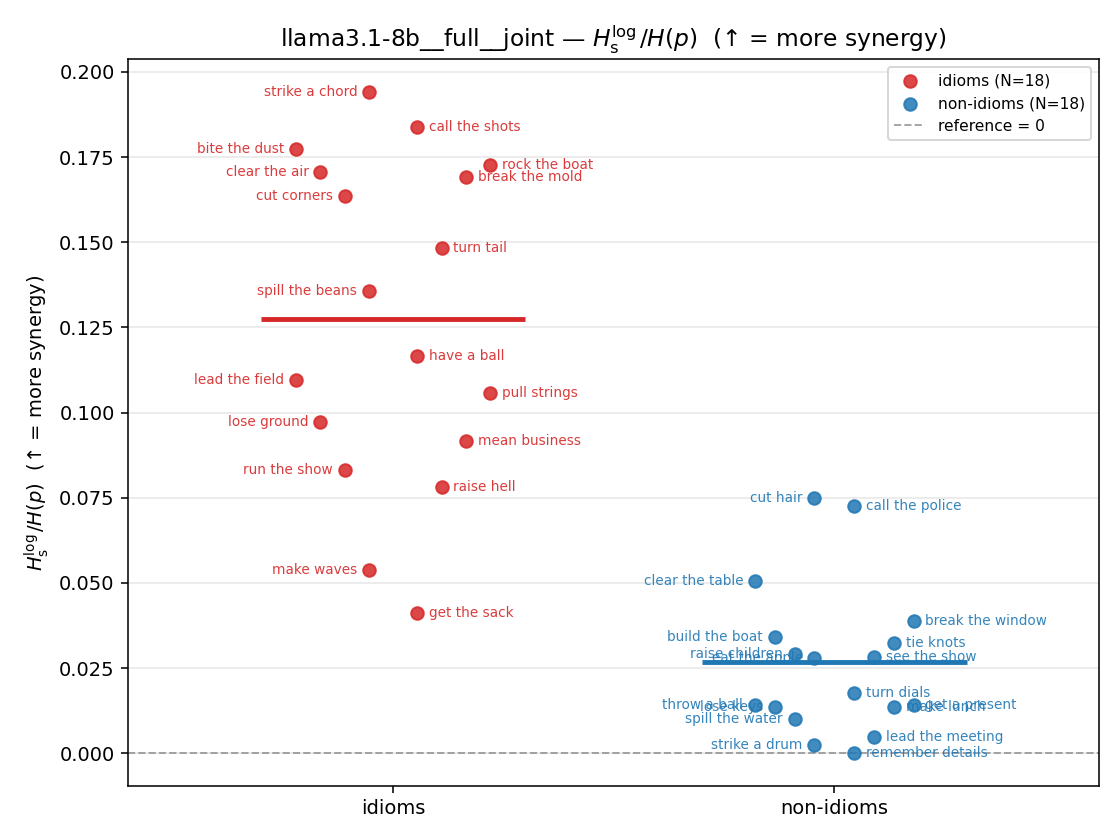 | 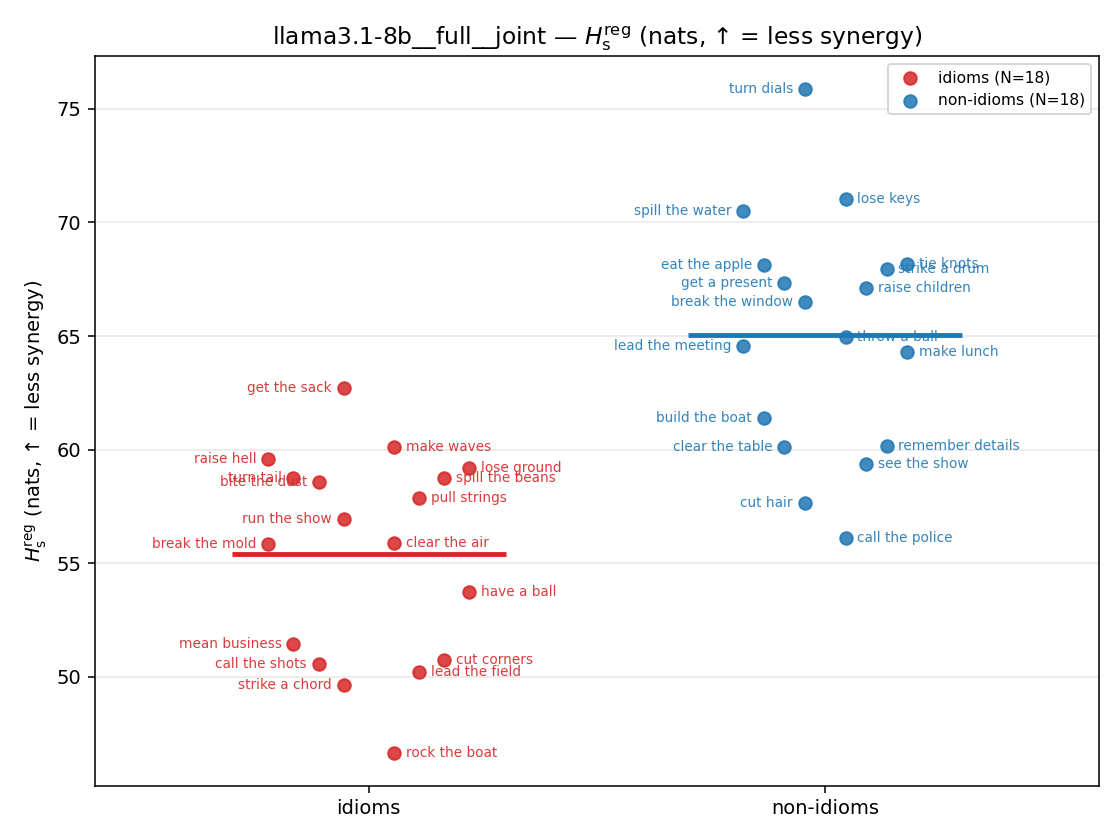 | 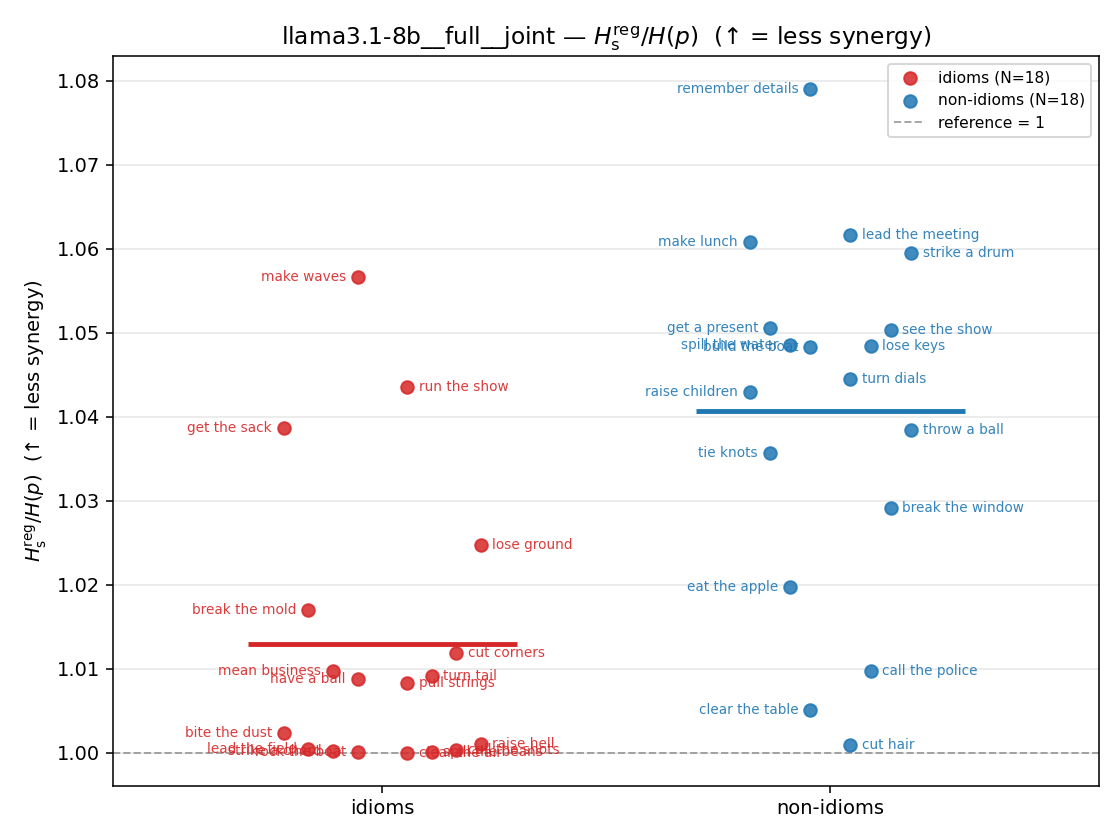 | 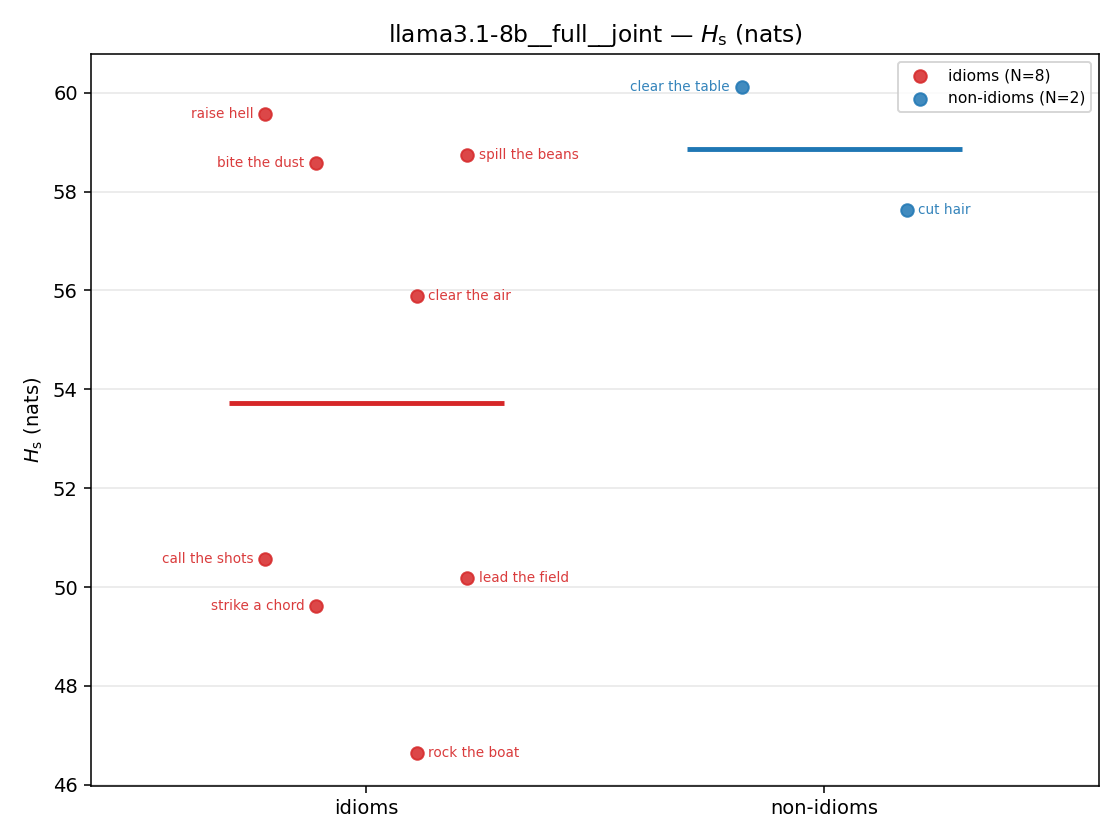 | 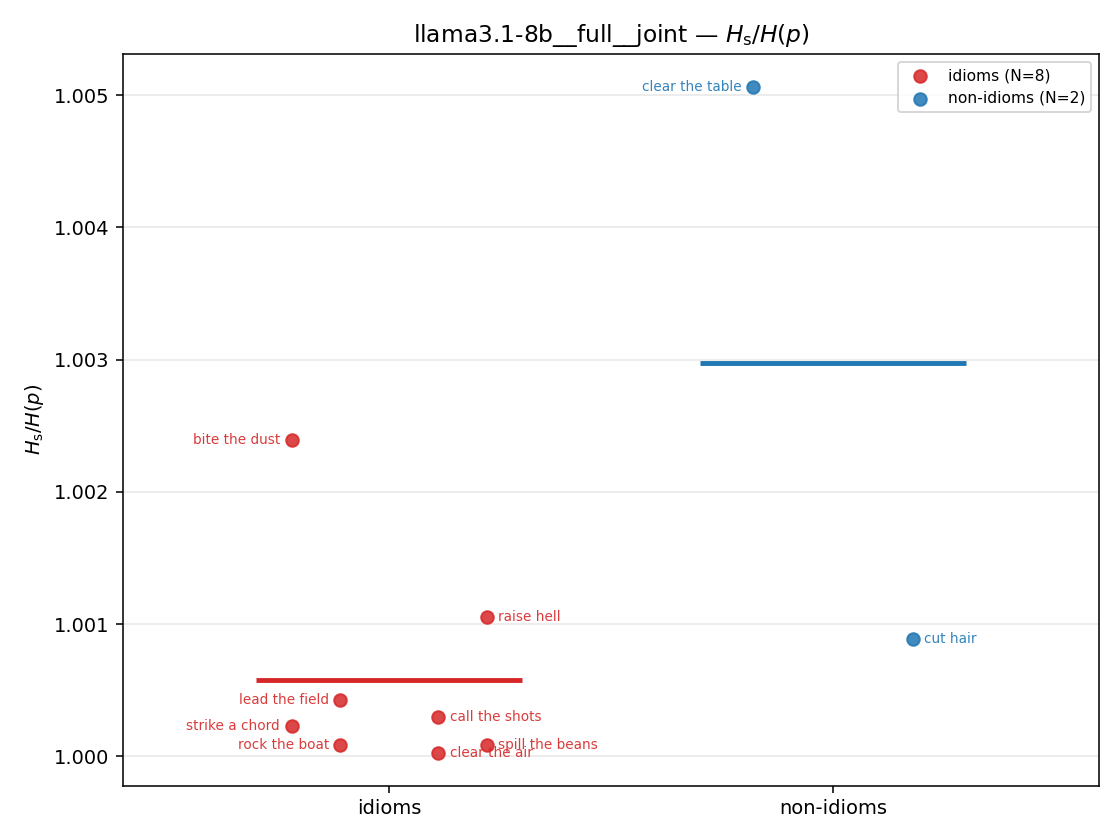 |
| mean ± 95% CI | 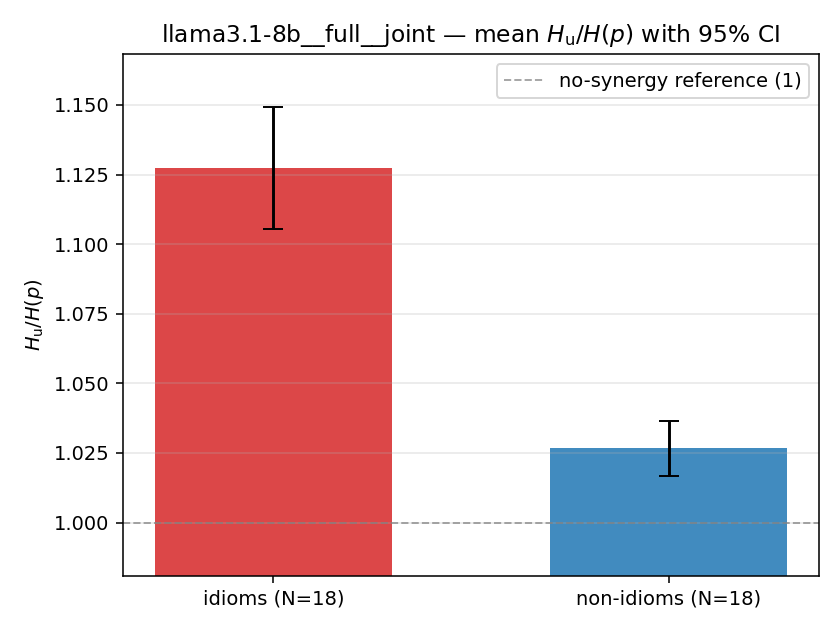 | 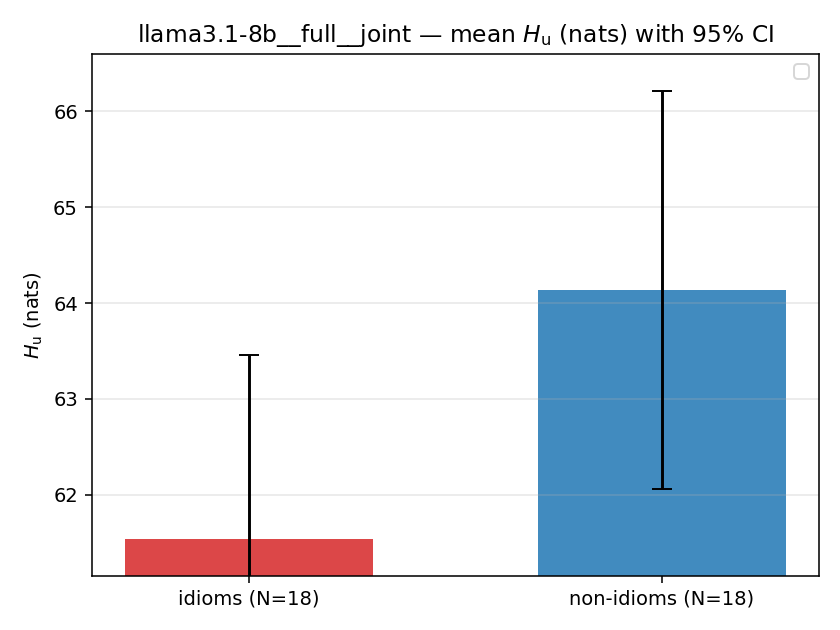 | 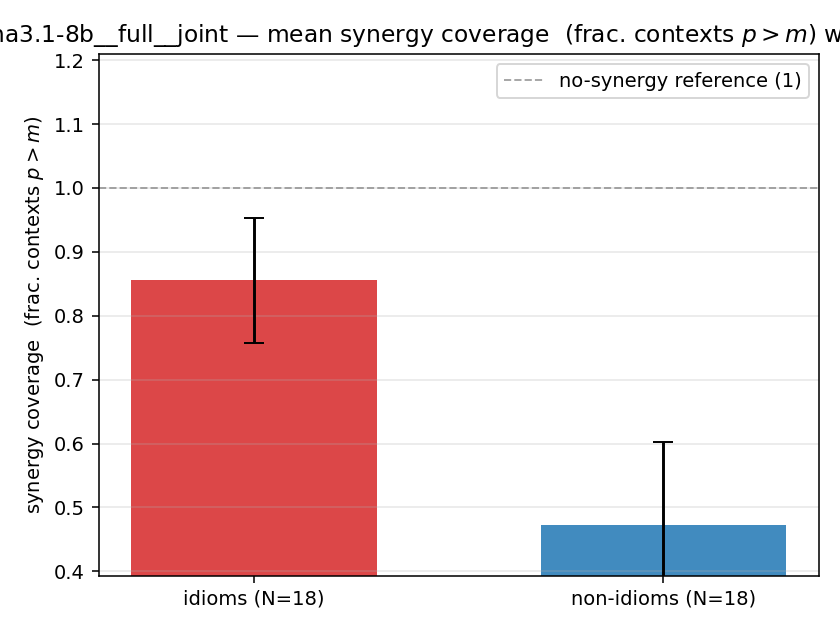 | 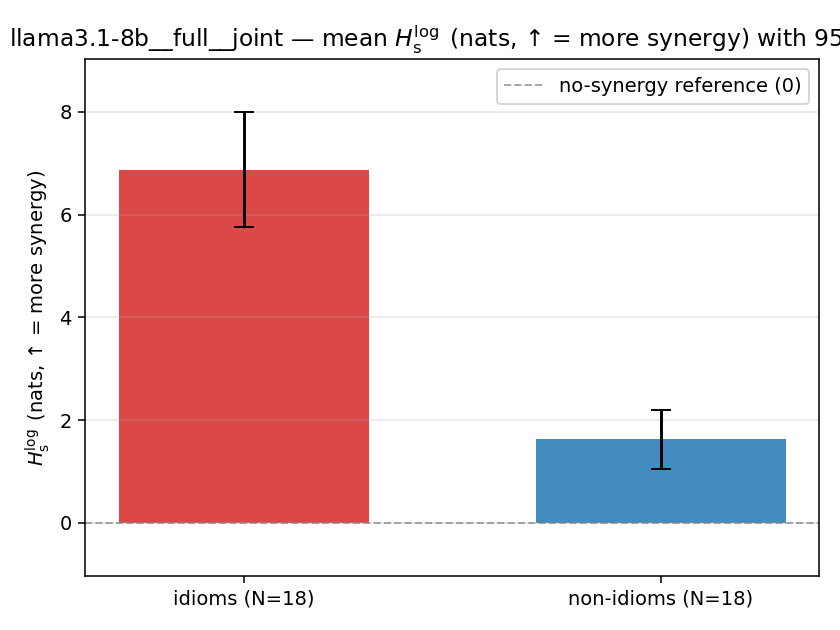 | 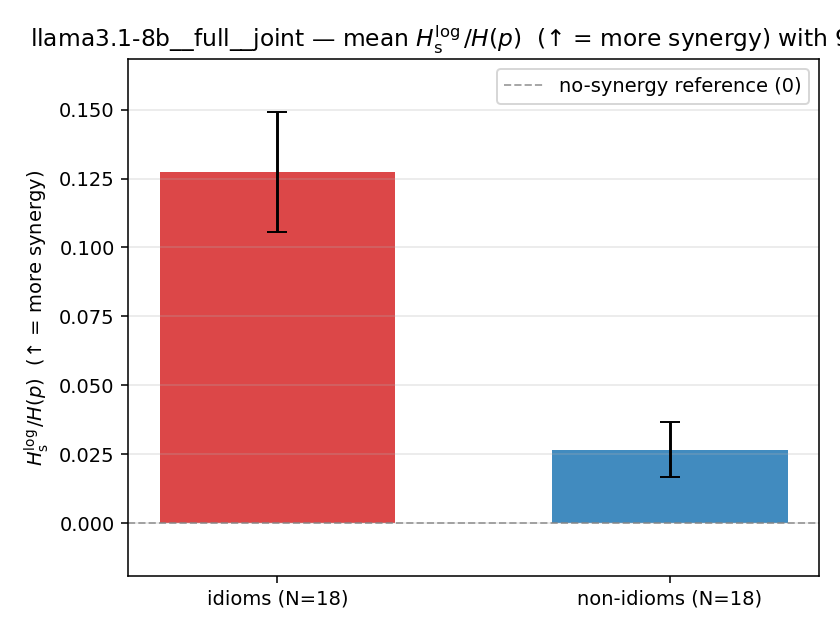 | 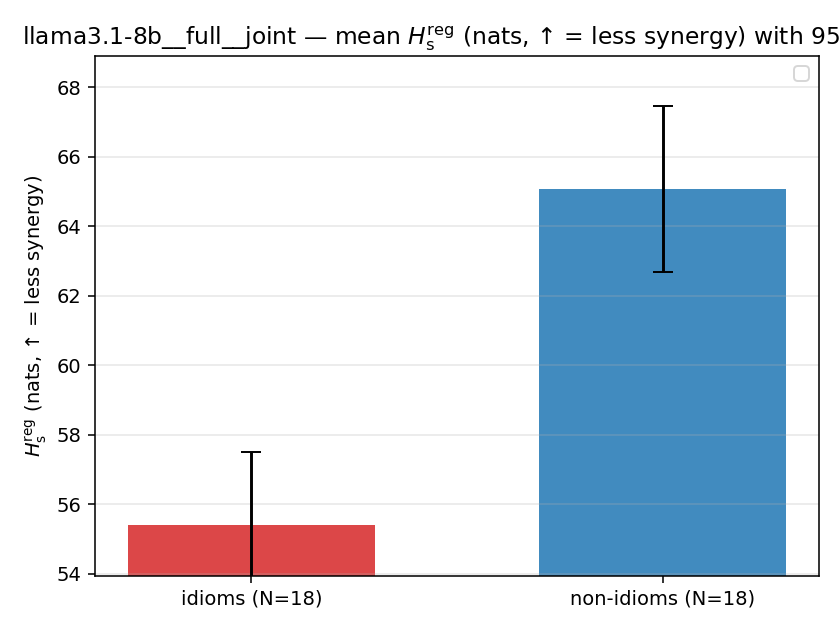 | 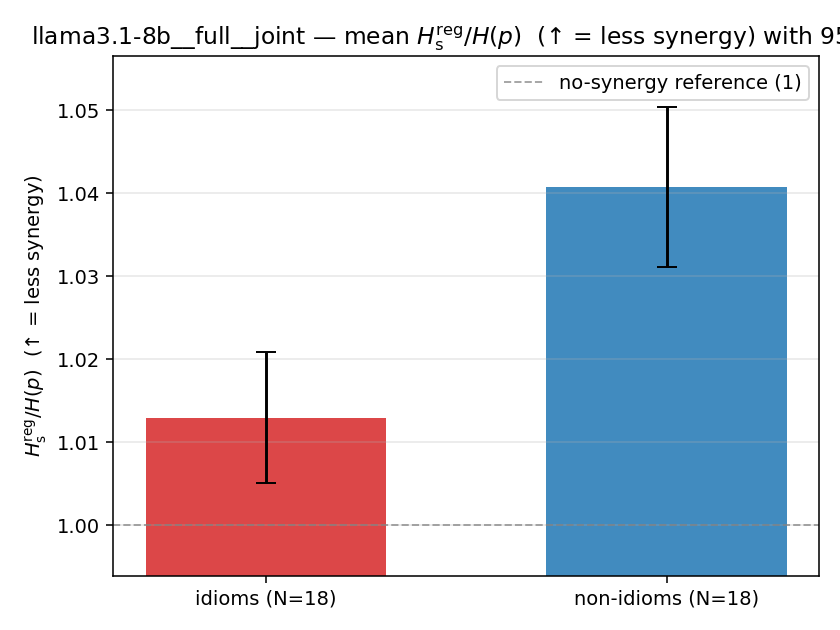 | 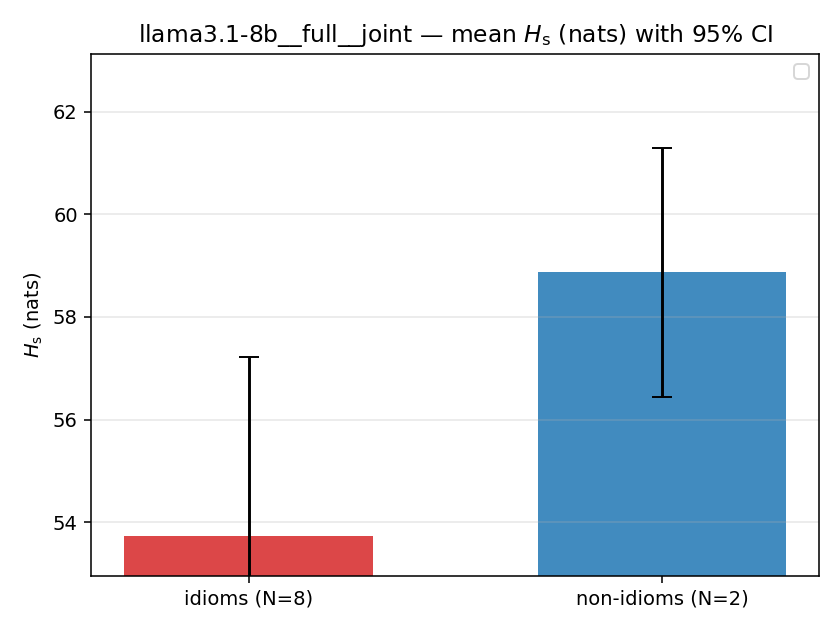 | 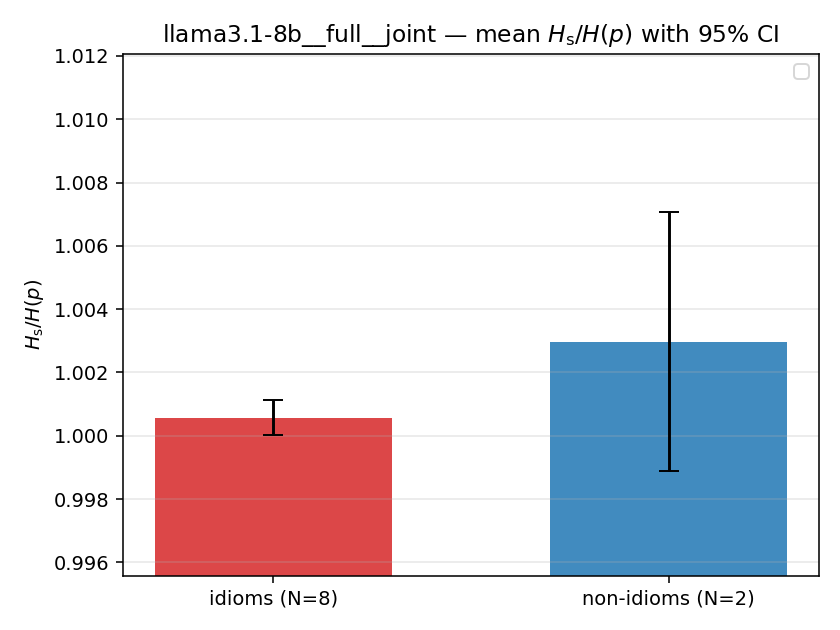 |
| per-idiom (sorted) | 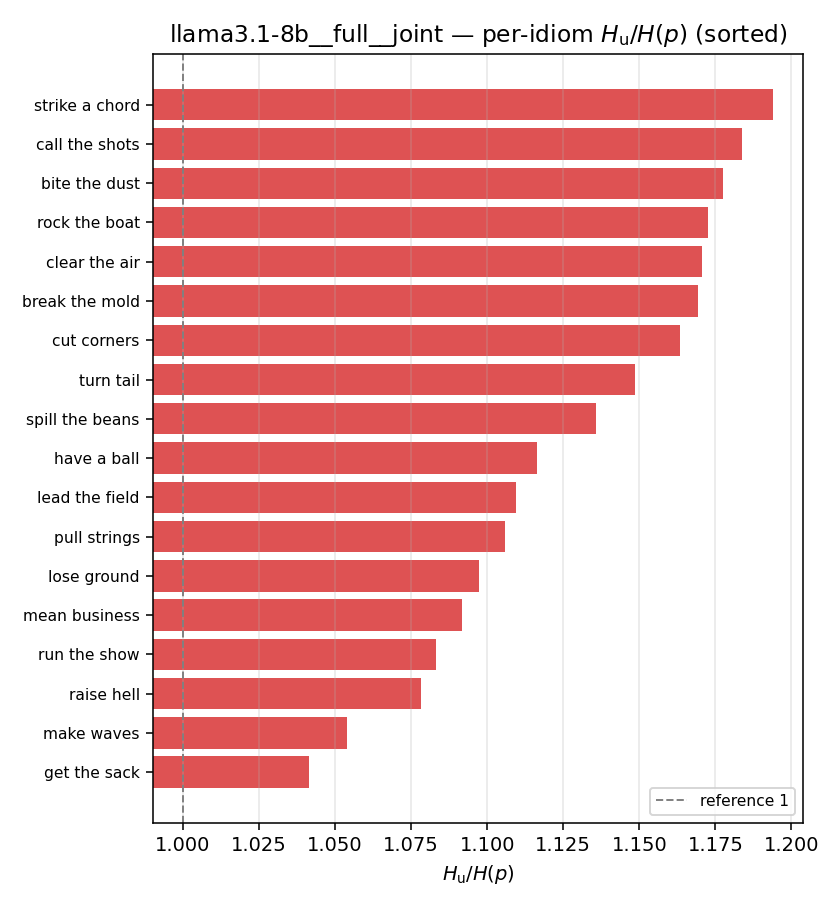 | 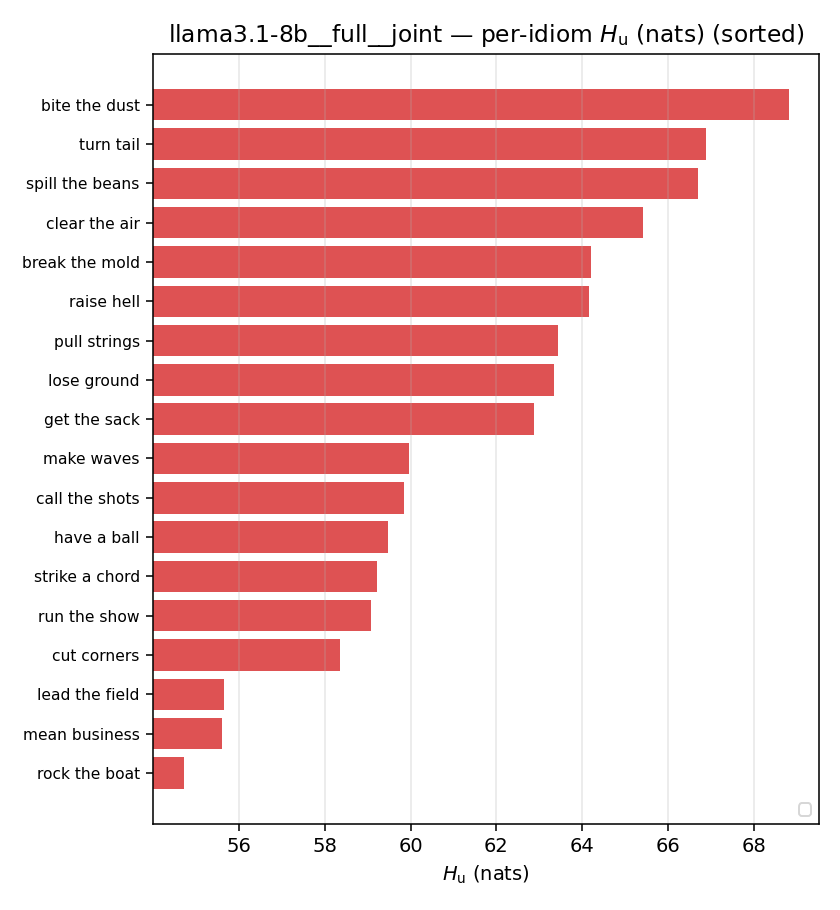 | 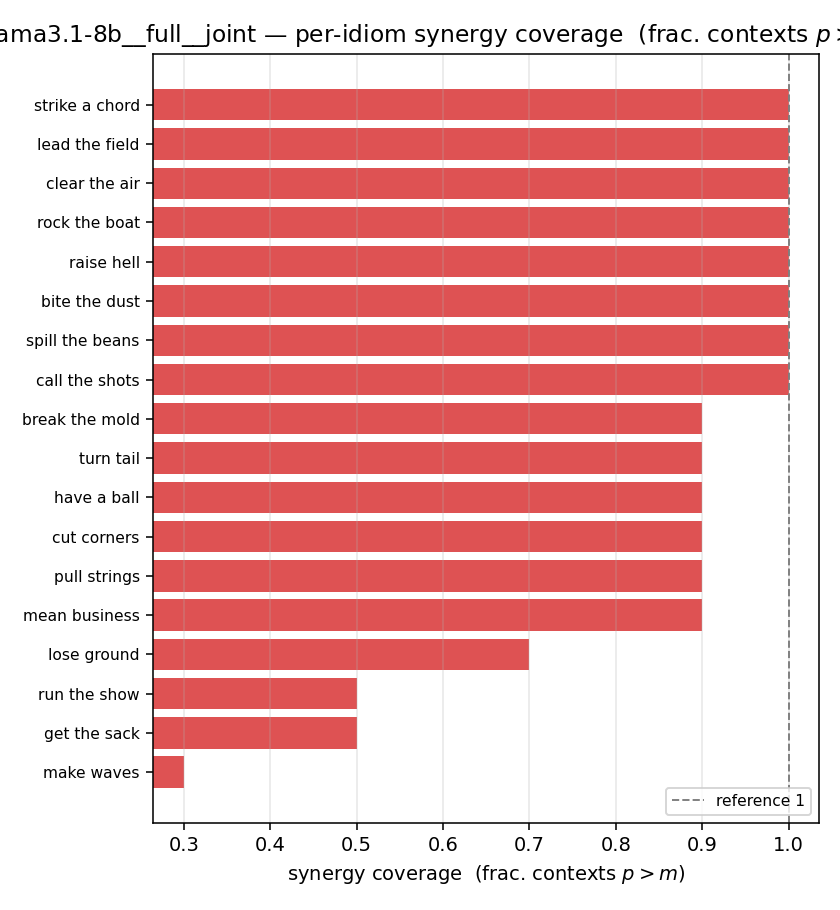 | 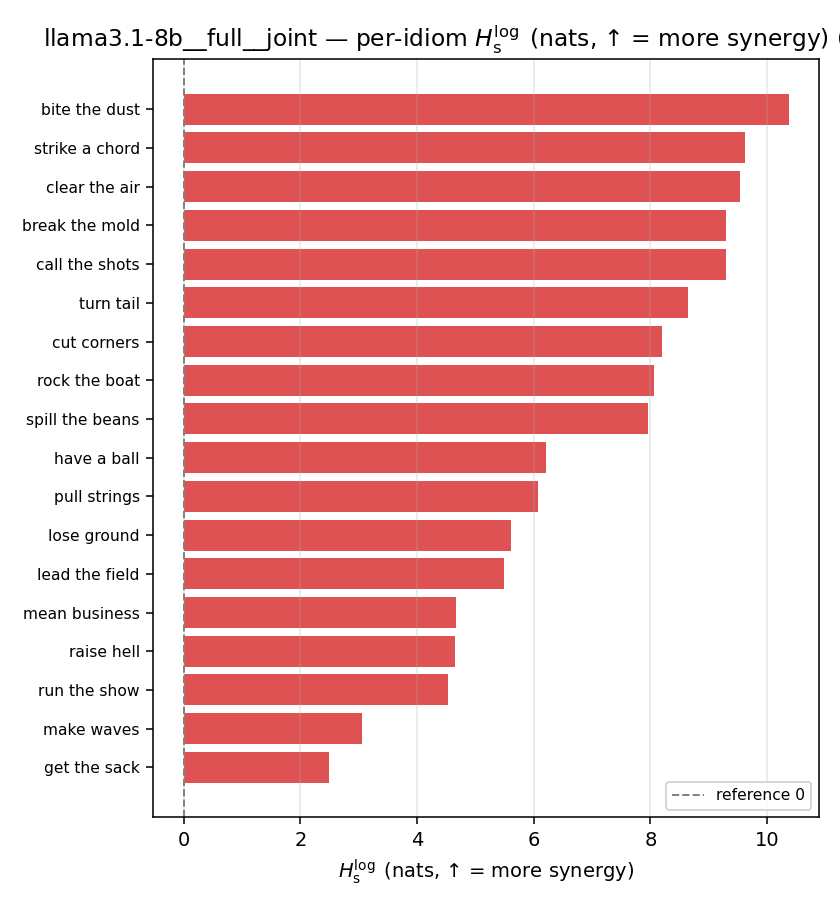 | 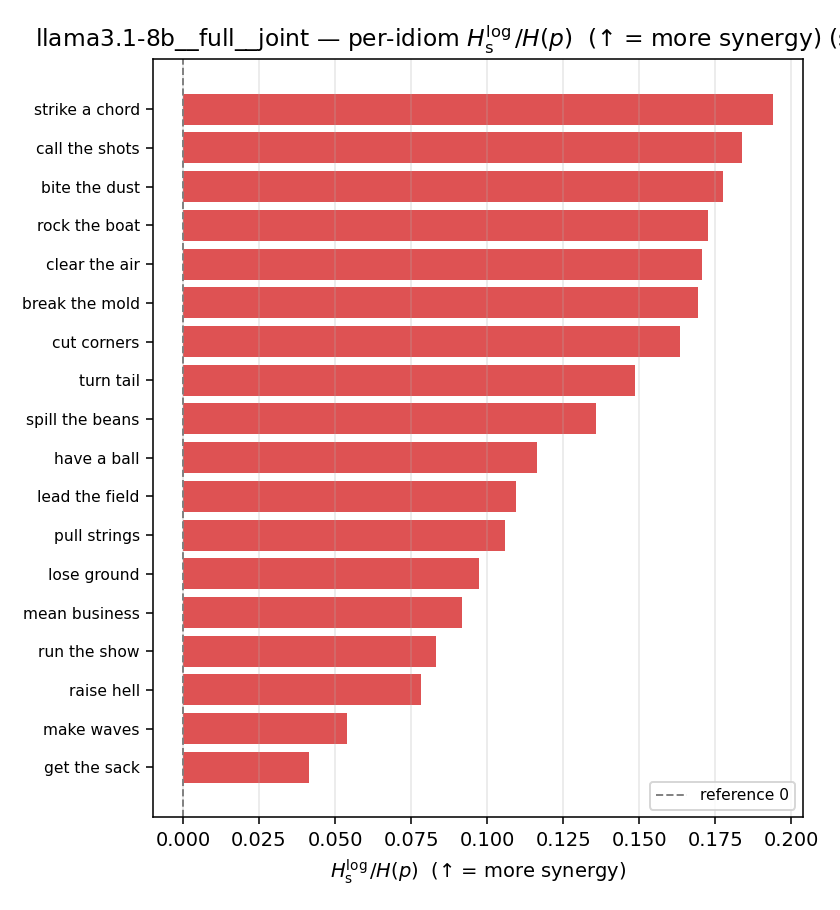 | 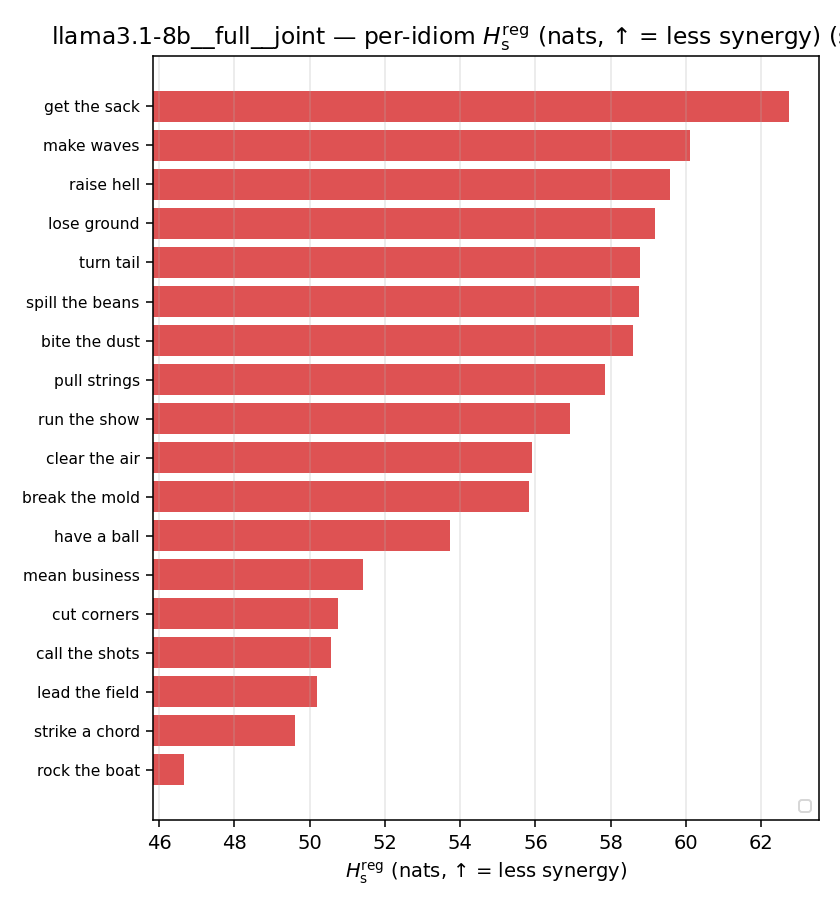 | 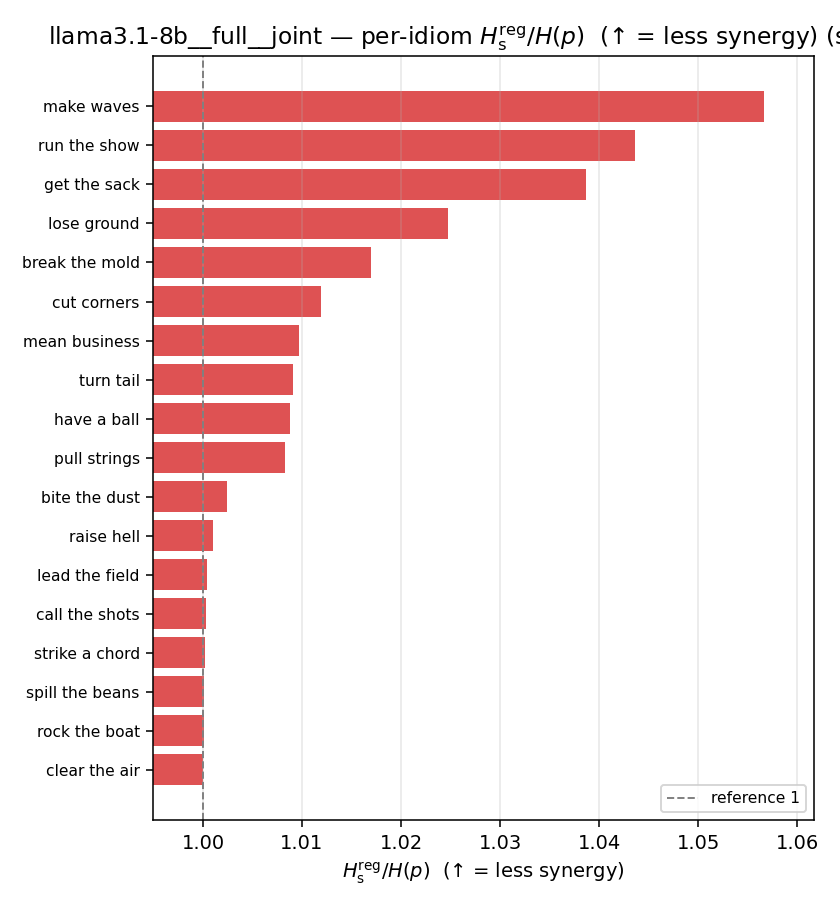 | 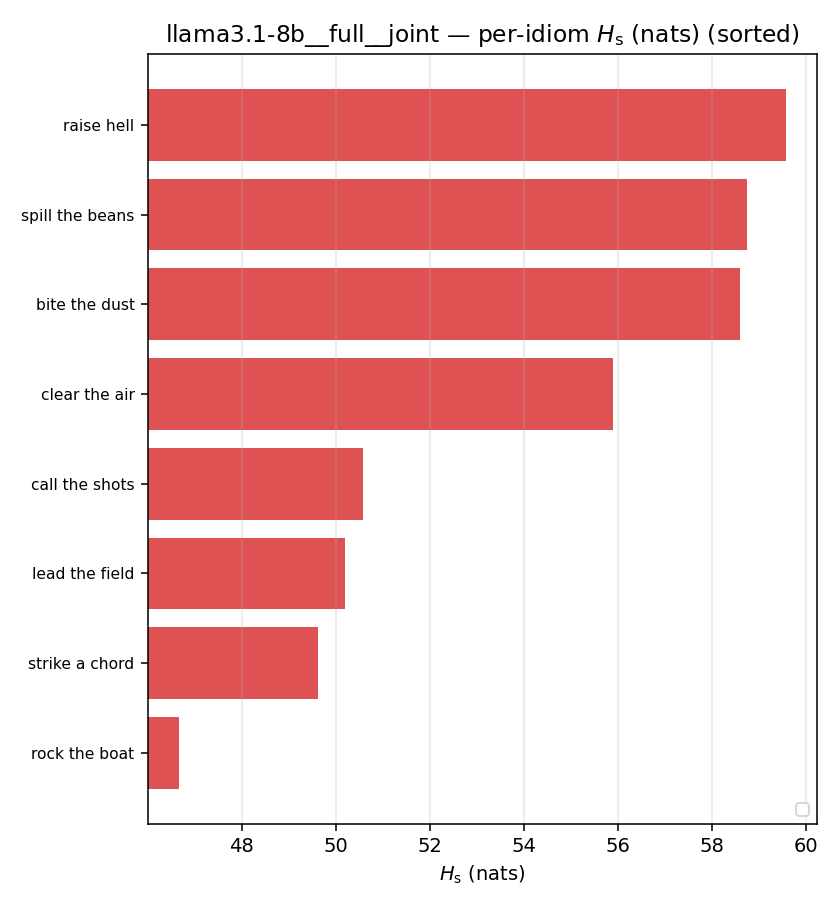 | 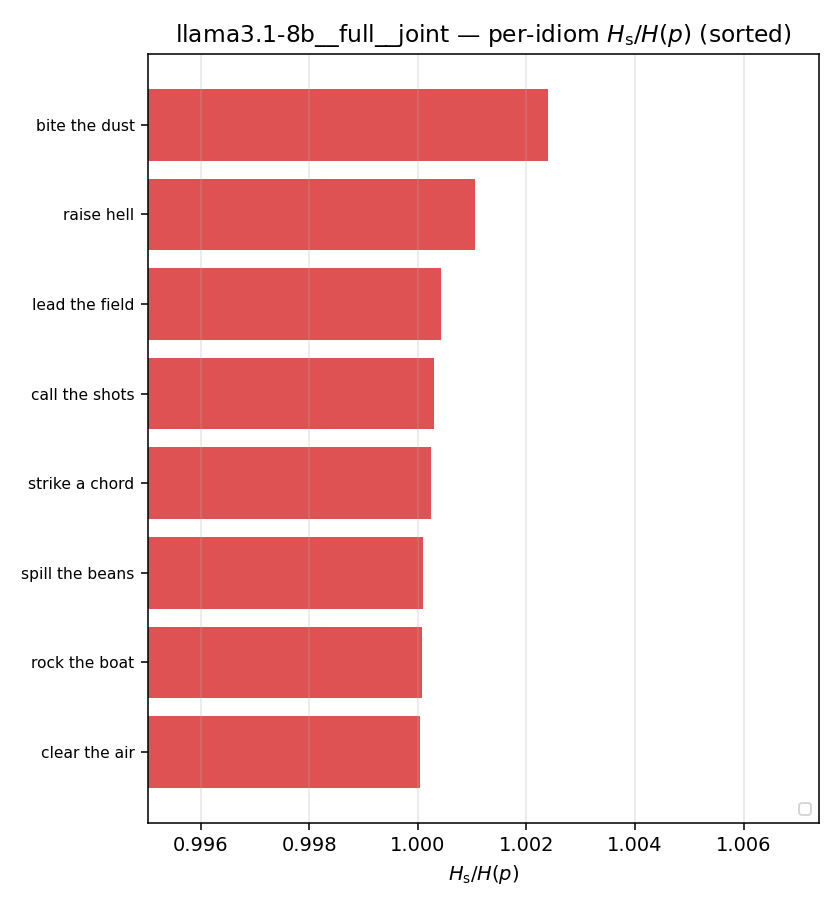 |